Recognition: unknown
MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
Pith reviewed 2026-05-08 15:01 UTC · model grok-4.3
The pith
MUSE treats structure as an orthogonal bridge in transformers to decouple reconstruction gradients from semantic ones, breaking the trade-off in visual tokenization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
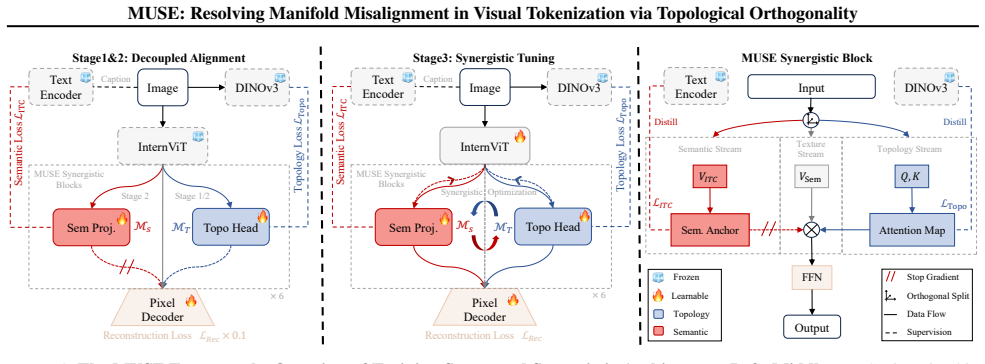
By enforcing topological orthogonality, MUSE decouples optimization inside the transformer: structural gradients refine attention topology while semantic gradients update feature values, converting opposing forces into mutual reinforcement and enabling simultaneous gains in spatial equivariance and conceptual invariance.
What carries the argument
Topological orthogonality, implemented by treating structure as an orthogonal bridge that separates structural gradient flow (which updates attention topology) from semantic gradient flow (which updates feature values) inside the transformer layers.
If this is right
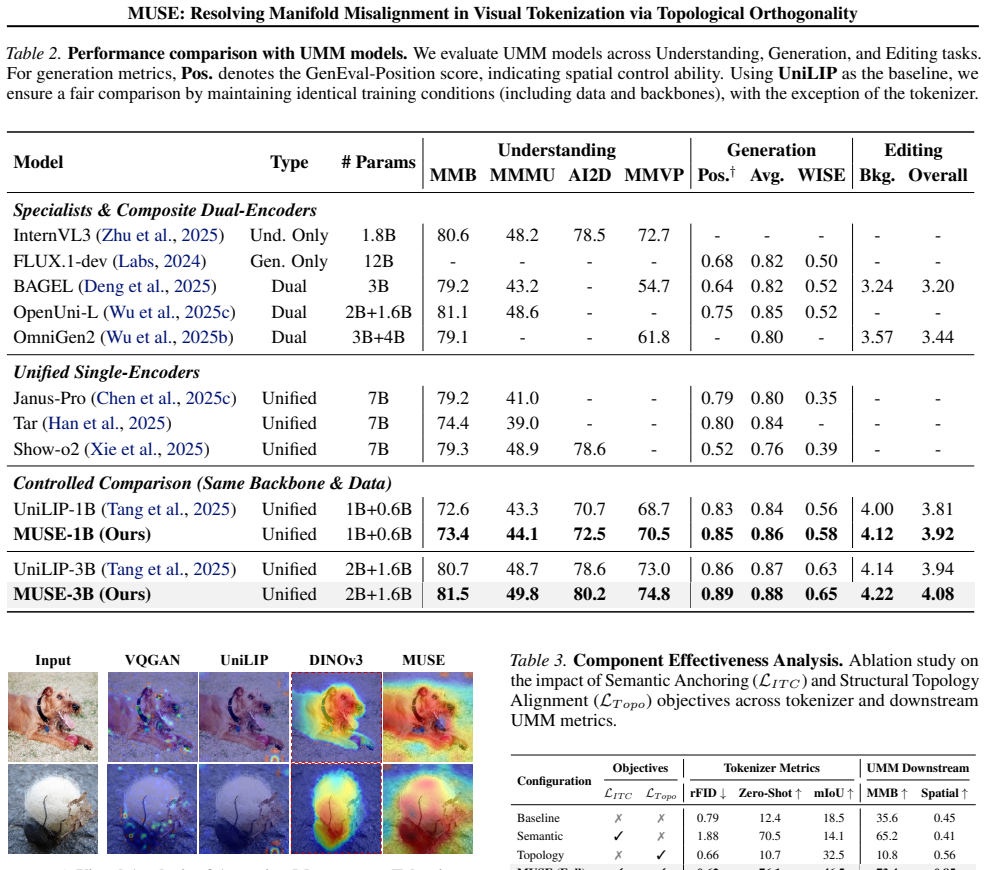
- MUSE reaches state-of-the-art generation quality at gFID 3.08.
- The same model exceeds its teacher InternViT-300M on linear probing (85.2 percent versus 82.5 percent).
- Structurally aligned reconstruction improves rather than harms semantic perception.
- The zero-sum game between reconstruction and abstraction is replaced by simultaneous improvement on both objectives.
Where Pith is reading between the lines
- The same separation principle could be tested on multimodal models where image and text objectives currently compete during joint training.
- If the orthogonality holds across scales, it may allow single backbones to replace separate encoder-decoder pairs for understanding and generation tasks.
- Removing the orthogonality term should produce measurable gradient interference that can be quantified by cosine similarity between the two gradient vectors.
Load-bearing premise
That designating structure as an orthogonal bridge will consistently separate the two gradient directions without creating new optimization instabilities or demanding extensive hyperparameter search.
What would settle it
Training the same MUSE architecture on a held-out dataset while removing the orthogonality constraint and checking whether both gFID and linear-probing accuracy drop below the reported levels.
Figures






read the original abstract
Unified visual tokenization faces a fundamental trade-off between high-fidelity pixel reconstruction (spatial equivariance) and semantic abstraction (conceptual invariance). We attribute this conflict to Manifold Misalignment: naive joint optimization induces opposing gradients, creating a zero-sum game between reconstruction and perception. To address this, we propose MUSE, a framework based on Topological Orthogonality. By treating Structure as an orthogonal bridge, MUSE decouples optimization within Transformers: structural gradients refine attention topology, while semantic gradients update feature values. This turns destructive interference into Mutual Reinforcement. Experiments show that MUSE breaks the trade-off, achieving state-of-the-art generation quality (gFID 3.08) and surpassing its teacher InternViT-300M in linear probing (85.2\% vs. 82.5\%), demonstrating that structurally aligned reconstruction can enhance semantic perception. Code is available at https://github.com/PanqiYang1/MUSE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual tokenization suffers from a trade-off between pixel reconstruction and semantic abstraction due to manifold misalignment from opposing gradients in joint optimization. MUSE resolves this via topological orthogonality, treating structure as an orthogonal bridge in transformers so that structural gradients refine attention topology while semantic gradients update feature values, converting interference into mutual reinforcement. This yields SOTA generation (gFID 3.08) and improved linear probing (85.2% vs. 82.5% on teacher InternViT-300M).
Significance. If the central mechanism and results hold, the work would be significant for unified visual tokenization, showing that structurally aligned reconstruction can enhance rather than degrade semantic perception. The reported metrics suggest practical gains for both generative and discriminative tasks in vision transformers, with potential broader impact on models balancing fidelity and abstraction.
major comments (1)
- [Methods (Topological Orthogonality)] The core claim in the MUSE framework (described in the methods section on topological orthogonality) is that structural gradients refine attention topology while semantic gradients update features without destructive interference. However, because attention topology is computed as softmax(QK^T) directly from the same features, backpropagation routes signals through interdependent paths; the manuscript does not specify an explicit mechanism (e.g., stop-gradient, detached auxiliary computation, or orthogonal projection) to enforce the claimed decoupling. This leaves the mutual-reinforcement argument vulnerable to residual coupling.
minor comments (2)
- [Experiments and Abstract] The abstract and results sections report gFID 3.08 and 85.2% accuracy but would benefit from explicit statements of all baselines, ablation controls for the orthogonality component, and hyperparameter sensitivity analysis to strengthen verification of the trade-off-breaking claim.
- [Introduction] Notation for 'Manifold Misalignment' and 'Topological Orthogonality' is introduced without prior references; a brief comparison to related concepts (e.g., gradient surgery or orthogonal regularization in multi-task learning) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the single major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods (Topological Orthogonality)] The core claim in the MUSE framework (described in the methods section on topological orthogonality) is that structural gradients refine attention topology while semantic gradients update features without destructive interference. However, because attention topology is computed as softmax(QK^T) directly from the same features, backpropagation routes signals through interdependent paths; the manuscript does not specify an explicit mechanism (e.g., stop-gradient, detached auxiliary computation, or orthogonal projection) to enforce the claimed decoupling. This leaves the mutual-reinforcement argument vulnerable to residual coupling.
Authors: We thank the referee for identifying this subtlety in gradient flow. The topological orthogonality is implemented by computing the attention topology on a stop-gradient version of the query and key projections (i.e., the structural path receives detached features), while the semantic path applies the resulting topology to update feature values without the topology computation receiving gradients from the semantic loss. This separation is realized in the dual-branch transformer block described in Section 3.2 and is present in the released code. We acknowledge that the manuscript text does not spell out the stop-gradient operation explicitly enough to make the decoupling immediately clear from the prose alone. We will revise Section 3 to include a precise description of the gradient routing, a forward/backward pseudocode snippet, and an additional figure showing the two paths. revision: yes
Circularity Check
No load-bearing circularity; MUSE claims rest on experimental validation rather than self-referential definitions or fitted predictions
full rationale
The abstract and described framework introduce topological orthogonality as a new decoupling mechanism without any equations that reduce the claimed mutual reinforcement or gFID/linear-probing gains to a fitted parameter renamed as prediction or to a self-citation chain. The derivation is presented as an architectural proposal tested on InternViT-300M, with results that are externally falsifiable; no self-definitional steps or ansatz smuggling are exhibited in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Naive joint optimization of reconstruction and semantics induces opposing gradients that create a zero-sum game
invented entities (2)
-
Manifold Misalignment
no independent evidence
-
Topological Orthogonality
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Neural discrete representation learning , author=. Advances in neural information processing systems , volume=
-
[2]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Taming transformers for high-resolution image synthesis , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Magvit: Masked generative video transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Advances in Neural Information Processing Systems , volume=
An image is worth 32 tokens for reconstruction and generation , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Autoregressive image generation without vector quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Eyes wide shut? exploring the visual shortcomings of multimodal llms , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[13]
Advances in neural information processing systems , volume=
Align before fuse: Vision and language representation learning with momentum distillation , author=. Advances in neural information processing systems , volume=
-
[14]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Emerging properties in self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[18]
Advances in Neural Information Processing Systems , volume=
Return of unconditional generation: A self-supervised representation generation method , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Janus: Decoupling visual encoding for unified multimodal understanding and generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[29]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Tokenflow: Unified image tokenizer for multimodal understanding and generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[38]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[39]
Advances in neural information processing systems , volume=
Journeydb: A benchmark for generative image understanding , author=. Advances in neural information processing systems , volume=
-
[43]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A style-based generator architecture for generative adversarial networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[44]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[46]
generation: Taming optimization dilemma in latent diffusion models , author=
Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[47]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[49]
Transfer between Modalities with MetaQueries
Transfer between modalities with metaqueries , author=. arXiv preprint arXiv:2504.06256 , year=
work page internal anchor Pith review arXiv
-
[53]
2025 , eprint=
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation , author=. 2025 , eprint=
2025
-
[54]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Uniworld: High-resolution semantic encoders for unified visual understanding and generation , author=. arXiv preprint arXiv:2506.03147 , year=
work page internal anchor Pith review arXiv
-
[58]
ImageNet: A large-scale hierarchical image database , year=
Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Kai Li and Li Fei-Fei , booktitle=. ImageNet: A large-scale hierarchical image database , year=
-
[59]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
Scene Parsing through ADE20K Dataset , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[60]
Conference on Empirical Methods in Natural Language Processing , year=
Noise Contrastive Estimation and Negative Sampling for Conditional Models: Consistency and Statistical Efficiency , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[61]
IEEE Transactions on Automation Science and Engineering , year=
Digital Genealogy: AIGC-driven Evolution of Digital Twin for Future Smart Manufacturing , author=. IEEE Transactions on Automation Science and Engineering , year=
-
[62]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Lion-fs: Fast & slow video-language thinker as online video assistant , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[63]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Semanticvla: Semantic-aligned sparsification and enhancement for efficient robotic manipulation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[64]
IEEE Transactions on Services Computing , year=
Multi-Objective Unlearning in Recommender Systems via Preference Guided Pareto Exploration , author=. IEEE Transactions on Services Computing , year=
-
[65]
Advances in Neural Information Processing Systems , volume=
Ultrare: Enhancing receraser for recommendation unlearning via error decomposition , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
Li, Lei and Jia, Sen and Wang, Jianhao and Jiang, Zhongyu and Zhou, Feng and Dai, Ju and Zhang, Tianfang and Wu, Zongkai and Hwang, Jenq-Neng , booktitle=
-
[68]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multiple Human Motion Understanding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[69]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Promptsculptor: Multi-agent based text-to-image prompt optimization , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[70]
Neurocomputing , pages=
SEArch: A Self-Evolving Framework for Network Architecture Optimization , author=. Neurocomputing , pages=. 2025 , publisher=
2025
-
[71]
International Journal of Computer Vision , pages=
AutoViT: Achieving Real-Time Vision Transformers on Mobile via Latency-aware Coarse-to-Fine Search , author=. International Journal of Computer Vision , pages=. 2025 , publisher=
2025
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Peeling the onion: Hierarchical reduction of data redundancy for efficient vision transformer training , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[73]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Beyond Math: Stories as a Testbed for Memorization-Constrained Reasoning in LLMs , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[75]
MATH-AI @ NeurIPS 2025 , year=
Learning How to Use Tools, Not Just When: Pattern-Aware Tool-Integrated Reasoning , author=. MATH-AI @ NeurIPS 2025 , year=
2025
-
[77]
2026 , eprint=
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models , author=. 2026 , eprint=
2026
-
[78]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Frequency-aligned knowledge distillation for lightweight spatiotemporal forecasting , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[79]
Eighteenth International Conference on Machine Vision (ICMV 2025) , editor =
Xinjin Li and Yu Ma and Kaisen Ye and Jinghan Cao and Minghao Zhou and Yeyang Zhou , title =. Eighteenth International Conference on Machine Vision (ICMV 2025) , editor =. 2026 , doi =
2025
-
[80]
Synergized Data Efficiency and Compression (SEC) Optimization for Large Language Models , year=
Li, Xinjin and Ma, Yu and Huang, Yangchen and Wang, Xingqi and Lin, Yuzhen and Zhang, Chenxi , booktitle=. Synergized Data Efficiency and Compression (SEC) Optimization for Large Language Models , year=
-
[81]
2026 , eprint=
Task-Specific Efficiency Analysis: When Small Language Models Outperform Large Language Models , author=. 2026 , eprint=
2026
-
[82]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
UniHOI: Unified Human-Object Interaction Understanding via Unified Token Space , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[83]
2026 , issn =
InstrucRobo: Object-centric multi-instruction decoupling model for explainable robotic manipulation , journal =. 2026 , issn =
2026
-
[84]
2026 , doi =
UniBVR: Balancing visual and reasoning abilities in unified 3D scene understanding , journal =. 2026 , doi =
2026
-
[85]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review arXiv 2025
-
[86]
BEiT: BERT Pre-Training of Image Transformers
Bao, H., Dong, L., Piao, S., and Wei, F. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021
work page internal anchor Pith review arXiv 2021
-
[87]
Task-specific efficiency analysis: When small language models outperform large language models, 2026
Cao, J., Ma, Y., Li, X., Ren, Q., and Chen, X. Task-specific efficiency analysis: When small language models outperform large language models, 2026. URL https://arxiv.org/abs/2603.21389
-
[88]
Emerging properties in self-supervised vision transformers
Caron, M., Touvron, H., Misra, I., J \'e gou, H., Mairal, J., Bojanowski, P., and Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 9650--9660, 2021
2021
-
[89]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Changpinyo, S., Sharma, P., Ding, N., and Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 3558--3568, 2021
2021
-
[90]
Chen, J., Cai, H., Chen, J., Xie, E., Yang, S., Tang, H., Li, M., Lu, Y., and Han, S. Deep compression autoencoder for efficient high-resolution diffusion models. arXiv preprint arXiv:2410.10733, 2024
-
[91]
ShareGPT-4o-Image: Aligning multimodal models with GPT-4o-level image generation
Chen, J., Cai, Z., Chen, P., Chen, S., Ji, K., Wang, X., Yang, Y., and Wang, B. Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image generation. arXiv preprint arXiv:2506.18095, 2025 a
-
[92]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568, 2025 b
work page Pith review arXiv 2025
-
[93]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811, 2025 c
work page internal anchor Pith review arXiv 2025
-
[94]
Syntax-directed variational autoencoder for structured data
Dai, H., Tian, Y., Dai, B., Skiena, S., and Song, L. Syntax-directed variational autoencoder for structured data. arXiv preprint arXiv:1802.08786, 2018
-
[95]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al. Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review arXiv 2025
-
[96]
ImageNet: A large- scale hierarchical image database
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 248--255, 2009. doi:10.1109/CVPR.2009.5206848
-
[97]
Taming transformers for high-resolution image synthesis
Esser, P., Rombach, R., and Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 12873--12883, 2021
2021
-
[98]
Ge, Y., Zhao, S., Zhu, J., Ge, Y., Yi, K., Song, L., Li, C., Ding, X., and Shan, Y. Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396, 2024
-
[99]
Han, J., Chen, H., Zhao, Y., Wang, H., Zhao, Q., Yang, Z., He, H., Yue, X., and Jiang, L. Vision as a dialect: Unifying visual understanding and generation via text-aligned representations. arXiv preprint arXiv:2506.18898, 2025
-
[100]
Masked autoencoders are scalable vision learners
He, K., Chen, X., Xie, S., Li, Y., Doll \'a r, P., and Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 16000--16009, 2022
2022
-
[101]
Ming-univision: Joint image under- standing and generation with a unified continuous tokenizer
Huang, Z., Zheng, D., Zou, C., Liu, R., Wang, X., Ji, K., Chai, W., Sun, J., Wang, L., Lv, Y., et al. Ming-univision: Joint image understanding and generation with a unified continuous tokenizer. arXiv preprint arXiv:2510.06590, 2025
-
[102]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review arXiv 2024
-
[103]
RAM: Recover Any 3D Human Motion in-the-Wild
Jia, S., Zhu, N., Zhong, J., Zhou, J., Zhang, H., Hwang, J.-N., and Li, L. Ram: Recover any 3d human motion in-the-wild. arXiv preprint arXiv:2603.19929, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[104]
and Ferraro, F
Jiang, Y. and Ferraro, F. Beyond math: Stories as a testbed for memorization-constrained reasoning in llms. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5590--5607, 2026 a
2026
-
[105]
SCRIBE: Structured Mid-Level Supervision for Tool-Using Language Models
Jiang, Y. and Ferraro, F. Scribe: Structured mid-level supervision for tool-using language models, 2026 b . URL https://arxiv.org/abs/2601.03555
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[106]
Jiang, Y., Li, D., and Ferraro, F. Drp: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models. arXiv preprint arXiv:2505.13975, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[107]
A style-based generator architecture for generative adversarial networks
Karras, T., Laine, S., and Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 4401--4410, 2019
2019
-
[108]
Peeling the onion: Hierarchical reduction of data redundancy for efficient vision transformer training
Kong, Z., Ma, H., Yuan, G., Sun, M., Xie, Y., Dong, P., Meng, X., Shen, X., Tang, H., Qin, M., et al. Peeling the onion: Hierarchical reduction of data redundancy for efficient vision transformer training. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp.\ 8360--8368, 2023
2023
-
[109]
Autovit: Achieving real-time vision transformers on mobile via latency-aware coarse-to-fine search
Kong, Z., Xu, D., Li, Z., Dong, P., Tang, H., Wang, Y., and Mukherjee, S. Autovit: Achieving real-time vision transformers on mobile via latency-aware coarse-to-fine search. International Journal of Computer Vision, pp.\ 1--17, 2025
2025
-
[110]
Labs, B. F. Flux. https://github.com/black-forest-labs/flux, 2024
2024
-
[111]
Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., and Hoi, S. C. H. Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems, 34: 0 9694--9705, 2021
2021
-
[112]
Human Motion Instruction Tuning
Li, L., Jia, S., Wang, J., Jiang, Z., Zhou, F., Dai, J., Zhang, T., Wu, Z., and Hwang, J.-N. Human Motion Instruction Tuning . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 a
2025
-
[113]
Multiple human motion understanding
Li, L., Jia, S., and Hwang, J.-N. Multiple human motion understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp.\ 6297--6305, 2026 a
2026
-
[114]
Return of unconditional generation: A self-supervised representation generation method
Li, T., Katabi, D., and He, K. Return of unconditional generation: A self-supervised representation generation method. Advances in Neural Information Processing Systems, 37: 0 125441--125468, 2024 a
2024
-
[115]
Autoregressive image generation without vector quantization
Li, T., Tian, Y., Li, H., Deng, M., and He, K. Autoregressive image generation without vector quantization. Advances in Neural Information Processing Systems, 37: 0 56424--56445, 2024 b
2024
-
[116]
Lion-fs: Fast & slow video-language thinker as online video assistant
Li, W., Hu, B., Shao, R., Shen, L., and Nie, L. Lion-fs: Fast & slow video-language thinker as online video assistant. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 3240--3251, 2025 b
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.