Recognition: unknown
Agent-Sentry: Bounding LLM Agents via Execution Provenance
Pith reviewed 2026-05-15 01:13 UTC · model grok-4.3
The pith
Agent Sentry bounds LLM agent executions from prior legitimate runs to detect and block injections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
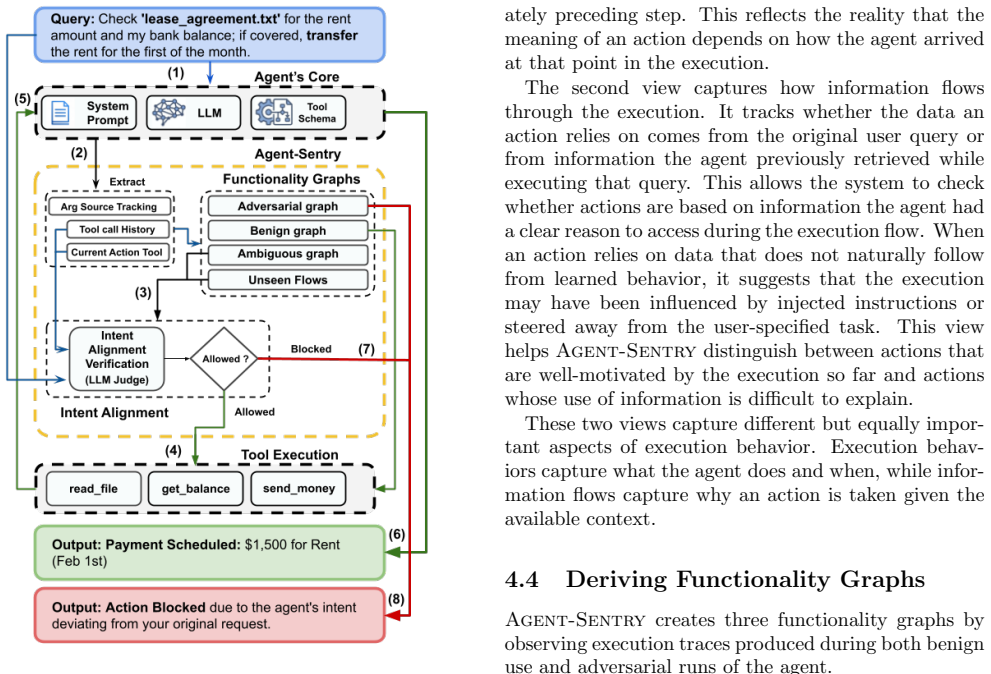
We present Agent Sentry, a runtime defense that learns a bound on an agent's benign execution from prior legitimate executions and flags any action that falls outside this bound. Agent Sentry layers three complementary checks: a structural classifier over the sequence of actions and the provenance of each function's arguments; a deterministic allowlist check over sensitive argument values; and an LLM judge, invoked only on the residual of actions where the first two checks cannot safely decide between a legitimate new request and a carefully crafted injection.
What carries the argument
Execution provenance bound learned from prior legitimate runs, which classifies new action sequences using structural checks on provenance, sensitive-value allowlists, and selective LLM judgment.
Load-bearing premise
Prior legitimate executions capture enough of the possible benign variations to allow reliable separation from adversarial injections when the structural and allowlist checks are inconclusive.
What would settle it
Observe whether an attacker can craft an injection that produces an action sequence and argument provenance sufficiently close to the learned benign bound to evade the first two checks and fool the LLM judge, dropping the blocking rate well below 94 percent.
Figures





read the original abstract
Agentic computing systems, while immensely capable, raise serious security, privacy, and safety concerns. A key issue is that the full set of functionalities offered by these systems, combined with their probabilistic execution flows, is not known beforehand. Given this lack of characterization, it is challenging to validate whether a system has successfully carried out the user's intended task or instead executed irrelevant actions, potentially as a consequence of compromise. We present \emph{Agent Sentry}, a runtime defense that learns a bound on an agent's benign execution from prior legitimate executions and flags any action that falls outside this bound. Agent Sentry layers three complementary checks: a structural classifier over the sequence of actions and the provenance of each function's arguments; a deterministic allowlist check over sensitive argument values; and an LLM judge, invoked only on the residual of actions where the first two checks cannot safely decide between a legitimate new request and a carefully crafted injection. We demonstrate the effectiveness of Agent Sentry in AgentDojo and AgentDyn by blocking 94.3\% of successful injections while allowing 95.1\% of benign executions, without modifying the agent, its tools, or the LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent-Sentry, a runtime defense for LLM-based agents that learns a bound on benign execution behavior from prior legitimate runs. It combines a structural classifier over action sequences and argument provenances, a deterministic allowlist for sensitive argument values, and an LLM judge invoked only on residual cases where the first two checks are inconclusive. The central claim is that this approach detects prompt injections without modifying the agent, its tools, or the underlying LLM, demonstrated by blocking 94.3% of successful injections while allowing 95.1% of benign executions on the AgentDojo and AgentDyn benchmarks.
Significance. If the bound generalizes reliably, Agent-Sentry offers a practical, non-intrusive layer for securing agentic systems against injection attacks and anomalous behavior in settings where full execution characterization is impossible a priori. The concrete performance numbers on named external benchmarks and the layered design (structural + allowlist + LLM) are strengths; the absence of parameter fitting from evaluation data avoids obvious circularity.
major comments (2)
- [Evaluation] Evaluation section: the reported 94.3% injection blocking and 95.1% benign allowance rest on the assumption that prior legitimate executions sufficiently represent the distribution of future benign variations, yet no quantitative analysis (e.g., coverage of LLM-induced stochastic paths or out-of-distribution benign traces) is provided to support generalization when the structural classifier and allowlist are inconclusive.
- [Method] Section describing the LLM judge: when the first two checks cannot decide, the residual is passed to an LLM judge to distinguish legitimate new requests from injections; the manuscript provides no separate accuracy metrics or ablation for this judge on novel but benign action sequences, which is load-bearing for the overall false-positive claim.
minor comments (1)
- [Abstract] Abstract states performance numbers but omits any mention of the number of prior runs used to define the bound or the exact decision thresholds; adding one sentence would improve verifiability.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We appreciate the recognition of the practical strengths of the layered design and the avoidance of circularity in evaluation. We address each major comment below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the reported 94.3% injection blocking and 95.1% benign allowance rest on the assumption that prior legitimate executions sufficiently represent the distribution of future benign variations, yet no quantitative analysis (e.g., coverage of LLM-induced stochastic paths or out-of-distribution benign traces) is provided to support generalization when the structural classifier and allowlist are inconclusive.
Authors: We agree that explicit quantitative support for coverage would strengthen the generalization claim. The AgentDojo and AgentDyn benchmarks already incorporate diverse tasks with LLM stochasticity across multiple runs, yielding varied action sequences and provenance patterns. In the revised manuscript we will add a new subsection to the Evaluation section that reports metrics on the diversity of observed benign traces (e.g., unique action-sequence counts, provenance-pattern coverage) and discusses how these traces address potential out-of-distribution cases when the structural classifier and allowlist are inconclusive. revision: yes
-
Referee: [Method] Section describing the LLM judge: when the first two checks cannot decide, the residual is passed to an LLM judge to distinguish legitimate new requests from injections; the manuscript provides no separate accuracy metrics or ablation for this judge on novel but benign action sequences, which is load-bearing for the overall false-positive claim.
Authors: We recognize the value of isolating the LLM judge's contribution. While the overall 95.1% benign allowance is reported, we will add an ablation study in the revised manuscript that evaluates the judge independently on held-out novel benign action sequences. This will include accuracy, precision, and recall figures for the judge alone, together with an analysis of how often it is invoked and its impact on the residual false-positive rate. revision: yes
Circularity Check
No significant circularity in derivation or evaluation chain
full rationale
The paper learns a bound on benign execution provenance from prior legitimate runs, then applies layered checks (structural classifier, allowlist, residual LLM judge) and reports effectiveness on separate external benchmarks AgentDojo and AgentDyn. The 94.3% injection blocking and 95.1% benign allowance figures are measured on held-out test executions rather than being algebraically or statistically forced by the training data used to define the bound. No equations, self-citations, or uniqueness theorems are invoked in the provided text that would reduce the central claim to a renaming or self-definition of its inputs. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prior legitimate executions provide a sufficient sample to bound all future benign behaviors
Forward citations
Cited by 3 Pith papers
-
The Granularity Mismatch in Agent Security: Argument-Level Provenance Solves Enforcement and Isolates the LLM Reasoning Bottleneck
PACT achieves perfect security and utility under oracle provenance by enforcing argument-level trust contracts based on semantic roles and cross-step provenance tracking, outperforming invocation-level monitors in Age...
-
Towards Security-Auditable LLM Agents: A Unified Graph Representation
Agent-BOM is a unified hierarchical attributed directed graph that models static capability bases and dynamic semantic states of LLM agents for path-level security auditing and risk assessment.
-
SoK: Security of Autonomous LLM Agents in Agentic Commerce
The paper systematizes security for LLM agents in agentic commerce into five threat dimensions, identifies 12 cross-layer attack vectors, and proposes a layered defense architecture.
Reference graph
Works this paper leans on
-
[1]
Get my drift? catching llm task drift with activa- tion deltas, 2025
Sahar Abdelnabi, Aideen Fay, Giovanni Cherubin, Ahmed Salem, Mario Fritz, and Andrew Paverd. Get my drift? catching llm task drift with activa- tion deltas, 2025
work page 2025
-
[2]
Amazon alexa.https://developer
Amazon. Amazon alexa.https://developer. amazon.com/en-US/alexa, 2014
work page 2014
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Defending against alignment-breaking at- tacks via robustly aligned llm
Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. Defending against alignment-breaking at- tacks via robustly aligned llm. InProceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 10542–10560, 2024
work page 2024
-
[5]
LangChain, a framework for building agents and LLM-powered applications
Harrison Chase. LangChain, a framework for building agents and LLM-powered applications. https://github.com/langchain-ai/langchain, Octo- ber 2022
work page 2022
-
[6]
Defeating prompt injections by design, 2025
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, 13 and Florian Tram` er. Defeating prompt injections by design, 2025
work page 2025
-
[7]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi´ c, Luca Beurer-Kellner, Marc Fis- cher, and Florian Tram` er. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents.arXiv preprint arXiv:2406.13352, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Building guardrails for large lan- guage models.arXiv preprint arXiv:2402.01822, 2024
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, and Xiaowei Huang. Building guardrails for large lan- guage models.arXiv preprint arXiv:2402.01822, 2024
-
[9]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial ex- amples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
De- fending against indirect prompt injection attacks with spotlighting, 2024
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. De- fending against indirect prompt injection attacks with spotlighting, 2024
work page 2024
-
[11]
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I-Hsin Chung, Winston H. Hsu, and Pin-Yu Chen. Attention tracker: Detecting prompt injection at- tacks in llms. InFindings of the Association for Computational Linguistics: NAACL 2025, 2025
work page 2025
-
[12]
The new attack surface: Why AI agents need taint analysis, 2024
Colin Nwachukwu Ife. The new attack surface: Why AI agents need taint analysis, 2024. Geordie AI. Accessed: 2026-01-09
work page 2024
-
[13]
Llm platform security: Applying a sys- tematic evaluation framework to openai’s chatgpt plugins
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. Llm platform security: Applying a sys- tematic evaluation framework to openai’s chatgpt plugins. InProceedings of the 2024 AAAI/ACM Conference on AI, Ethics, and Society, pages 611– 623, 2024
work page 2024
-
[14]
The Wall Street Journal. Ai agents arrive at citi. https://www.wsj.com/articles/ai-agents- arrive-at-citi-60a3559d, 2025. Written by Isabelle Bousquette
work page 2025
-
[15]
Digi- tal workers have arrived in banking
The Wall Street Journal. Digi- tal workers have arrived in banking. https://www.wsj.com/articles/digital-workers- have-arrived-in-banking-bf62be49, 2025. Written by Isabelle Bousquette
work page 2025
-
[16]
Palisade – prompt injection detection framework, 2024
Sahasra Kokkula, Somanathan R, Nandavardhan R, Aashishkumar, and G Divya. Palisade – prompt injection detection framework, 2024
work page 2024
-
[17]
We’re afraid language models aren’t modeling am- biguity
Alisa Liu, Zhaofeng Wu, Julian Michael, Alane Suhr, Peter West, Alexander Koller, Swabha Swayamdipta, Noah A Smith, and Yejin Choi. We’re afraid language models aren’t modeling am- biguity. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 790–807, 2023
work page 2023
-
[18]
Llamaindex.https://github.com/ run-llama/llama_index, 2022
Jerry Liu. Llamaindex.https://github.com/ run-llama/llama_index, 2022
work page 2022
-
[19]
Traceaegis: Securing llm-based agents via hierarchical and behavioral anomaly detection, 2025
Jiahao Liu, Bonan Ruan, Xianglin Yang, Zhiwei Lin, Yan Liu, Yang Wang, Tao Wei, and Zhenkai Liang. Traceaegis: Securing llm-based agents via hierarchical and behavioral anomaly detection, 2025
work page 2025
-
[20]
Evolv- ing diverse red-team language models in multi- round multi-agent games, 2024
Chengdong Ma, Ziran Yang, Hai Ci, Jun Gao, Min- quan Gao, Xuehai Pan, and Yaodong Yang. Evolv- ing diverse red-team language models in multi- round multi-agent games, 2024
work page 2024
-
[21]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. To- wards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Efficient tcb reduction and attestation
Jonathan McCune, Ning Qu, Yanlin Li, Anupam Datta, Virgil Gligor, and Adrian Perrig. Efficient tcb reduction and attestation. 01 2009
work page 2009
-
[23]
Openai agents sdk.https://github
OpenAI. Openai agents sdk.https://github. com/openai/openai-agents-python, 2025
work page 2025
-
[24]
India’s apollo hospitals bets on ai to tackle staff workload
Reuters. India’s apollo hospitals bets on ai to tackle staff workload. https://www.reuters.com/business/healthcare- pharmaceuticals/indias-apollo-hospitals-bets-ai- tackle-staff-workload-2025-03-13/, 2025
work page 2025
-
[25]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. Identifying the risks of LM agents with an LM-emulated sandbox, 2023. arXiv:2309.15817
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Progent: Programmable privilege control for llm agents, 2025
Tianneng Shi, Jingxuan He, Zhun Wang, Hong- wei Li, Linyu Wu, Wenbo Guo, and Dawn Song. Progent: Programmable privilege control for llm agents, 2025
work page 2025
-
[27]
Microsoft’s new dragon copi- lot is an ai assistant for healthcare
The Verge. Microsoft’s new dragon copi- lot is an ai assistant for healthcare. https://www.theverge.com/news/622528/microsoft- dragon-copilot-ai-healthcare-assistant, 2025
work page 2025
-
[28]
Peiran Wang, Yang Liu, Yunfei Lu, Yifeng Cai, Hongbo Chen, Qingyou Yang, Jie Zhang, Jue Hong, and Ye Wu. Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection, 2025
work page 2025
-
[29]
Julia Wiesinger, Patrick Marlow, and Vladimir Vuskovic. Agents. Whitepaper. Available online: 14 https://www.rojo.me/content/files/2025/ 01/Whitepaper-Agents---Google.pdf, 2024. Accessed: 2024-12-14
work page 2025
-
[30]
Simon Willison. The dual llm pattern for building ai assistants that can reason safely about untrusted data.https://simonwillison.net/2023/Apr/ 25/dual-llm-pattern/, 2023. Accessed: 2025-02- 05
work page 2023
-
[31]
IsolateGPT: An execution isolation architecture for LLM-based agentic systems
Yuhao Wu, Franziska Jiang, et al. IsolateGPT: An execution isolation architecture for LLM-based agentic systems. InNetwork and Distributed Sys- tem Security Symposium (NDSS), 2025
work page 2025
-
[32]
Xiaoxue Yang, Bozhidar Stevanoski, Matthieu Meeus, and Yves-Alexandre de Montjoye. Align- ment under pressure: The case for informed adver- saries when evaluating llm defenses.arXiv preprint arXiv:2505.15738, 2025
-
[33]
Autodefense: Multi-agent llm defense against jailbreak attacks, 2024
Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, and Qingyun Wu. Autodefense: Multi-agent llm defense against jailbreak attacks, 2024
work page 2024
-
[34]
Jingyan Zhou, Kun Li, Junan Li, Jiawen Kang, Minda Hu, Xixin Wu, and Helen Meng. Purple- teaming llms with adversarial defender training, 2024. 15 APPENDIX 9 Diversity in Utility Traces To ensure the robustness of the behavioral policy, the Agent-Sentry Benchdataset prioritizes diversity within utility traces. This approach captures the wide variability i...
work page 2024
-
[35]
The sequence must be logical (outputs of step 1 reasonably flow into step 2). 3. Vary the length and complexity. 4. You MUST focus on the "Target Tool Transition" provided. 12.2.2 User Prompt Generation To translate tool sequences into natural language, we use the following prompt, which enforces the selected persona: Meta-Prompt: User Prompt Generation Y...
-
[36]
The prompt must IMPLICITLY require the tools. Do not just list tool names. 4. ‘reasoning‘ must explain why this phrasing triggers these tools. 12.2.3 Stylistic Diversity We employ the same diversity sampling strategy as the Attack Generator to prevent linguistic mode collapse. For each trace, a style is sampled from: 19 •Standard: Professional and clear. ...
-
[37]
The prompt must IMPLICITLY require the tools. Do not just list tool names. 4. ‘reasoning‘ must explain why this phrasing triggers these tools. 13.3.2 Stylistic Diversity To prevent the model from converging on a single ”polite command” style, we stochastically sample from a set of 9 distinct personas for each generation: •Standard: Clear, polite, professi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.