Recognition: no theorem link
Beyond Corner Patches: Semantics-Aware Backdoor Attack in Federated Learning
Pith reviewed 2026-05-14 00:20 UTC · model grok-4.3
The pith
Semantic triggers like sunglasses enable effective backdoor attacks in federated learning that preserve benign accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
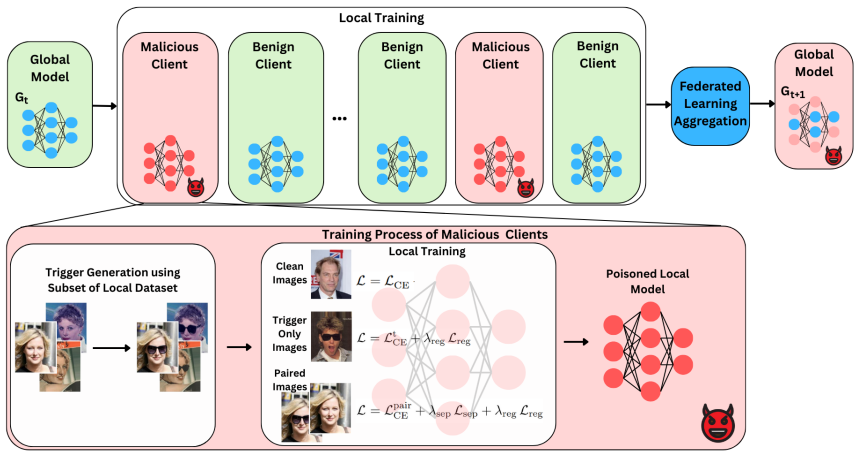
SABLE constructs natural, content-consistent triggers such as semantic attribute changes and optimizes an aggregation-aware malicious objective with feature separation and parameter regularization to keep attacker updates close to benign ones, achieving high targeted attack success rates while preserving benign test accuracy across heterogeneous partitions and aggregation rules on CelebA and GTSRB.
What carries the argument
SABLE attack using semantics-aware triggers optimized with feature separation and parameter regularization to produce stealthy malicious updates.
Load-bearing premise
Malicious clients can optimize their updates to remain close enough to benign updates that common aggregation rules fail to filter them while still embedding effective in-distribution semantic backdoors.
What would settle it
An aggregation rule that removes all optimized malicious updates while keeping overall model accuracy on clean test data above a threshold comparable to the no-attack baseline would disprove the effectiveness claim.
Figures




read the original abstract
Backdoor attacks on federated learning (FL) are most often evaluated with synthetic corner patches or out-of-distribution (OOD) patterns that are unlikely to arise in practice. In this paper, we revisit the backdoor threat to standard FL (a single global model) under a more realistic setting where triggers must be semantically meaningful, in-distribution, and visually plausible. We propose SABLE, a Semantics-Aware Backdoor for LEarning in federated settings, which constructs natural, content-consistent triggers (e.g., semantic attribute changes such as sunglasses) and optimizes an aggregation-aware malicious objective with feature separation and parameter regularization to keep attacker updates close to benign ones. We instantiate SABLE on CelebA hair-color classification and the German Traffic Sign Recognition Benchmark (GTSRB), poisoning only a small, interpretable subset of each malicious client's local data while otherwise following the standard FL protocol. Across heterogeneous client partitions and multiple aggregation rules (FedAvg, Trimmed Mean, MultiKrum, and FLAME), our semantics-driven triggers achieve high targeted attack success rates while preserving benign test accuracy. These results show that semantics-aligned backdoors remain a potent and practical threat in federated learning, and that robustness claims based solely on synthetic patch triggers can be overly optimistic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SABLE, a semantics-aware backdoor attack for federated learning that uses natural, in-distribution triggers (e.g., semantic attribute changes such as sunglasses) instead of synthetic corner patches. Malicious clients optimize updates via feature separation and parameter regularization to remain close to benign updates, enabling high targeted attack success rates on CelebA hair-color classification and GTSRB while preserving benign test accuracy across FedAvg, Trimmed Mean, MultiKrum, and FLAME under heterogeneous client partitions.
Significance. If the results hold, the work demonstrates that realistic semantics-aligned backdoors remain a potent threat in standard FL, indicating that robustness evaluations based solely on synthetic triggers may be overly optimistic. The evaluation across two datasets, multiple aggregation rules, and standard FL protocols provides a practical assessment of the attack surface.
major comments (2)
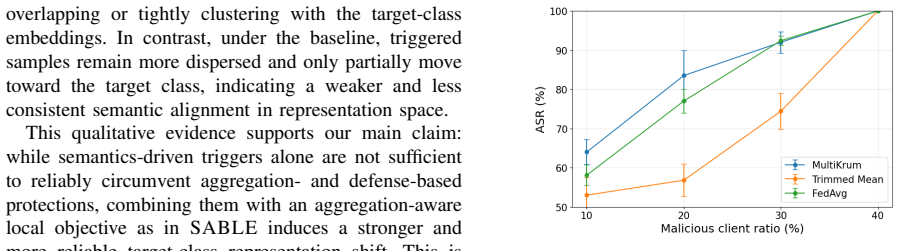
- [Experiments section] The central claim that feature separation plus parameter regularization produces malicious updates whose distance to the benign centroid is smaller than the selection thresholds of MultiKrum, Trimmed Mean, and FLAME is load-bearing but unsupported by data. No L2 or cosine distances, no extracted threshold values from the aggregator implementations, and no ablation of attack success rate versus update distance are reported in the experimental results.
- [Experiments section] §4 (or equivalent experimental section): the reported attack success rates lack details on statistical significance testing, exact values of the free parameters (regularization strength and feature separation weight), and full controls for client heterogeneity, making it difficult to verify reproducibility and the claimed preservation of benign accuracy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental section. We have revised the manuscript to provide the requested quantitative support and reproducibility details.
read point-by-point responses
-
Referee: [Experiments section] The central claim that feature separation plus parameter regularization produces malicious updates whose distance to the benign centroid is smaller than the selection thresholds of MultiKrum, Trimmed Mean, and FLAME is load-bearing but unsupported by data. No L2 or cosine distances, no extracted threshold values from the aggregator implementations, and no ablation of attack success rate versus update distance are reported in the experimental results.
Authors: We agree that the manuscript would be strengthened by explicit reporting of these distances and thresholds. In the revised version, we have added a new subsection with L2 and cosine distance measurements between malicious and benign updates for each aggregation rule, the exact threshold values extracted from our implementations of MultiKrum, Trimmed Mean, and FLAME, and an ablation study of attack success rate versus update distance. These additions confirm that the malicious updates remain below the selection thresholds. revision: yes
-
Referee: [Experiments section] §4 (or equivalent experimental section): the reported attack success rates lack details on statistical significance testing, exact values of the free parameters (regularization strength and feature separation weight), and full controls for client heterogeneity, making it difficult to verify reproducibility and the claimed preservation of benign accuracy.
Authors: We acknowledge the need for greater experimental transparency. The revised manuscript now reports the exact values of the regularization strength and feature separation weight, presents attack success rates and benign accuracies averaged over multiple independent runs with standard deviations, and expands the description of client heterogeneity controls including the specific data partitioning procedure used across all experiments. revision: yes
Circularity Check
No circularity; purely empirical attack construction and evaluation
full rationale
The paper proposes SABLE as an empirical backdoor attack method using semantic triggers, feature separation, and parameter regularization, then evaluates it experimentally on CelebA and GTSRB under multiple aggregators. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps exist. All claims rest on observed attack success rates and accuracy preservation rather than any reduction to inputs by construction or self-referential definitions. The work is self-contained against its experimental benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- regularization strength
- feature separation weight
axioms (2)
- domain assumption A small fraction of clients are malicious and can selectively poison a subset of their local data
- domain assumption Semantic attribute changes remain visually plausible and in-distribution for the target datasets
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Aguera y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), 2017
work page 2017
-
[2]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, and et al., “Advances and open problems in federated learning,”Foundations and Trends in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021
work page 2021
-
[3]
M. Rahman, M. Rahmanet al., “A survey on federated learning: The journey from centralized to distributed on-site learning and beyond,”IEEE Internet of Things Journal, 2021
work page 2021
-
[4]
J. Zhao, S. Bagchi, S. Avestimehr, K. Chan, S. Chaterji, D. Dim- itriadis, J. Li, N. Li, A. Nourian, and H. Roth, “The federation strikes back: A survey of federated learning privacy attacks, defenses, applications, and policy landscape,”ACM Computing Surveys, vol. 57, no. 9, pp. 1–37, 2025
work page 2025
-
[5]
Leak and learn: An attacker’s cookbook to train using leaked data from federated learning,
J. C. Zhao, A. Dabholkar, A. Sharma, and S. Bagchi, “Leak and learn: An attacker’s cookbook to train using leaked data from federated learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 247– 12 256
work page 2024
-
[6]
Federated learning: Strategies for improving communication efficiency,
J. Konecn ´y, H. B. McMahan, D. Ramage, and P. Richt ´arik, “Federated learning: Strategies for improving communication efficiency,” inNIPS Workshop on Private Multi-Party Machine Learning, 2016
work page 2016
-
[7]
Federated Learning for Mobile Keyboard Prediction
A. Hard, K. Rao, S. Ramaswamy, and et al., “Feder- ated learning for mobile keyboard prediction,”arXiv preprint arXiv:1811.03604, 2019
work page Pith review arXiv 2019
-
[8]
The resource problem of using linear layer leakage attack in federated learning,
J. C. Zhao, A. R. Elkordy, A. Sharma, Y . H. Ezzeldin, S. Aves- timehr, and S. Bagchi, “The resource problem of using linear layer leakage attack in federated learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 3974–3983
work page 2023
-
[9]
Loki: Large-scale data reconstruction attack against federated learning through model manipulation,
J. C. Zhao, A. Sharma, A. R. Elkordy, Y . H. Ezzeldin, S. Aves- timehr, and S. Bagchi, “Loki: Large-scale data reconstruction attack against federated learning through model manipulation,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 1287–1305
work page 2024
-
[10]
Federated opti- mization in heterogeneous networks,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Federated opti- mization in heterogeneous networks,” inProceedings of Machine Learning and Systems (MLSys), 2020, fedProx
work page 2020
-
[11]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inProceedings of the 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 2020
work page 2020
-
[12]
Analyzing federated learning through an adversarial lens,
A. N. Bhagoji, S. Chakraborty, P. Mittal, and S. Calo, “Analyzing federated learning through an adversarial lens,” inProceedings of the 36th International Conference on Machine Learning (ICML), 2019
work page 2019
-
[13]
Attack of the tails: Yes, you really can backdoor federated learning,
H. Wang, M. Yurochkin, Y . Sun, D. Papailiopoulos, and A. Khaz- aeni, “Attack of the tails: Yes, you really can backdoor federated learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[14]
Badnets: Identifying vulnerabilities in the machine learning model supply chain,
T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” in Proceedings of the IEEE International Conference on Machine Learning and Applications (ICMLA), 2017
work page 2017
-
[15]
Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted backdoor attacks on deep learning systems using data poisoning,”arXiv preprint arXiv:1712.05526, 2017
work page internal anchor Pith review arXiv 2017
-
[16]
Trojaning attack on neural networks,
Y . Liu, S. Ma, Y . Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” inProceedings of the Network and Distributed System Security Symposium (NDSS) Workshop, 2018
work page 2018
-
[17]
DBA: Distributed backdoor attacks against federated learning,
C. Xie, K. Huang, P.-Y . Chen, and B. Li, “DBA: Distributed backdoor attacks against federated learning,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[18]
Machine learning with adversaries: Byzantine-tolerant gradient descent,
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Machine learning with adversaries: Byzantine-tolerant gradient descent,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[19]
Byzantine- robust distributed learning: Towards optimal statistical rates,
D. Yin, Y . Chen, K. Ramchandran, and P. Bartlett, “Byzantine- robust distributed learning: Towards optimal statistical rates,” in Proceedings of the 35th International Conference on Machine Learning (ICML), 2018
work page 2018
-
[20]
Hidden trigger backdoor attacks,
A. Saha, A. Subramanya, and H. Pirsiavash, “Hidden trigger backdoor attacks,” inProceedings of the AAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[21]
Back- door attacks against deep learning systems in the physical world,
E. Wenger, J. Passananti, Y . Yao, H. Zheng, and B. Zhao, “Back- door attacks against deep learning systems in the physical world,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
work page 2021
-
[22]
How to backdoor diffu- sion models?
S.-Y . Chou, P.-Y . Chen, and T.-Y . Ho, “How to backdoor diffu- sion models?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4015–4024
work page 2023
-
[23]
Just how toxic is data poisoning? a unified bench- mark for backdoor and data poisoning attacks,
A. Schwarzschild, M. Goldblum, A. Gupta, J. P. Dickerson, and T. Goldstein, “Just how toxic is data poisoning? a unified bench- mark for backdoor and data poisoning attacks,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 9389–9398
work page 2021
-
[24]
Backdoorbench: A comprehensive benchmark of back- door learning,
B. Wu, H. Chen, M. Zhang, Z. Zhu, S. Wei, D. Yuan, and C. Shen, “Backdoorbench: A comprehensive benchmark of back- door learning,”Advances in Neural Information Processing Sys- tems, vol. 35, pp. 10 546–10 559, 2022
work page 2022
-
[25]
Label-consistent back- door attacks,
A. Turner, D. Tsipras, A. Madryet al., “Label-consistent back- door attacks,”arXiv preprint arXiv:1912.02771, 2019
-
[26]
Y . Li, Y . Jiang, Z. Li, and S.-T. Xia, “Backdoor learning: A survey,”IEEE transactions on neural networks and learning systems, vol. 35, no. 1, pp. 5–22, 2022
work page 2022
-
[27]
Reflection backdoor: A natural backdoor attack on deep neural networks,
Y . Liu, X. Ma, J. Bailey, and F. Lu, “Reflection backdoor: A natural backdoor attack on deep neural networks,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 182–199
work page 2020
-
[28]
Lira: Learnable, im- perceptible and robust backdoor attacks,
K. Doan, Y . Lao, W. Zhao, and P. Li, “Lira: Learnable, im- perceptible and robust backdoor attacks,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 11 966–11 976
work page 2021
-
[29]
Invisible backdoor attacks on deep neural networks via steganography and poisoning,
Y . Li, J. Liet al., “Invisible backdoor attacks on deep neural networks via steganography and poisoning,”IEEE Transactions on Dependable and Secure Computing, 2021
work page 2021
-
[30]
Can you really backdoor federated learning?
L. Sun, J. Jia, X. Caoet al., “Can you really backdoor federated learning?”arXiv preprint arXiv:1911.07963, 2019
-
[31]
J. Zhang, J. Jiaet al., “Backdoor attacks and defenses in federated learning: Survey, challenges and future research directions,” arXiv preprint arXiv:2207.05286, 2022
-
[32]
The hidden vulnerability of distributed learning in byzantium,
E. M. El Mhamdi, R. Guerraoui, and S. Rouault, “The hidden vulnerability of distributed learning in byzantium,” inProceed- ings of the 35th International Conference on Machine Learning (ICML) Workshop, 2018
work page 2018
-
[33]
Flame: Taming backdoors in federated learning,
T. D. Nguyen, P. Rieger, H. Chen, H. Yalame, H. M ¨ollering, H. Fereidooni, S. Marchal, M. Miettinen, A. Mirhoseini, K. Zeitouni, and N. Asokan, “Flame: Taming backdoors in federated learning,” inProceedings of the 31st USENIX Security Symposium, 2022, pp. 1415–1432
work page 2022
-
[34]
Flair: Defense against model poisoning attack in federated learning,
A. Sharma, W. Chen, J. Zhao, Q. Qiu, S. Bagchi, and S. Chaterji, “Flair: Defense against model poisoning attack in federated learning,” inProceedings of the 2023 ACM Asia Conference on Computer and Communications Security, 2023, pp. 553–566. 13
work page 2023
-
[35]
Fltrust: Byzantine- robust federated learning via trust bootstrapping,
X. Cao, M. Fang, J. Liu, and N. Z. Gong, “Fltrust: Byzantine- robust federated learning via trust bootstrapping,”arXiv preprint arXiv:2012.13995, 2020
-
[36]
Fedinv: Byzantine- robust federated learning by inversing local model updates,
B. Zhao, P. Sun, T. Wang, and K. Jiang, “Fedinv: Byzantine- robust federated learning by inversing local model updates,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 8, 2022, pp. 9171–9179
work page 2022
-
[37]
Sear: Secure and efficient aggregation for byzantine-robust federated learning,
L. Zhao, J. Jiang, B. Feng, Q. Wang, C. Shen, and Q. Li, “Sear: Secure and efficient aggregation for byzantine-robust federated learning,”IEEE Transactions on Dependable and Secure Com- puting, vol. 19, no. 5, pp. 3329–3342, 2021
work page 2021
-
[38]
Byzantine-robust decentralized federated learning,
M. Fang, Z. Zhang, Hairi, P. Khanduri, J. Liu, S. Lu, Y . Liu, and N. Gong, “Byzantine-robust decentralized federated learning,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 2874–2888
work page 2024
-
[39]
Filterfl: Knowledge filtering-based data-free backdoor defense for federated learning,
Y . Yang, M. Hu, X. Xie, Y . Cao, P. Zhang, Y . Huang, and M. Chen, “Filterfl: Knowledge filtering-based data-free backdoor defense for federated learning,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 3147–3161
work page 2025
-
[40]
Guiding instruction-based image editing via multimodal large language models,
T.-J. Fu, W. Hu, X. Du, W. Y . Wang, Y . Yang, and Z. Gan, “Guiding instruction-based image editing via multimodal large language models,” inInternational Conference on Learning Rep- resentations (ICLR), 2024
work page 2024
-
[41]
On the out-of-distribution backdoor attack for federated learning,
J. Xu, Z. Zhang, and R. Hu, “On the out-of-distribution backdoor attack for federated learning,” inProceedings of the ACM Inter- national Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing (MobiHoc), 2025, to appear. arXiv:2509.13219
-
[42]
A physical backdoor attack against practical federated learning,
Y . Li, X. Lu, G. Luo, and Y . Zhu, “A physical backdoor attack against practical federated learning,” in2025 28th International Conference on Computer Supported Cooperative Work in Design (CSCWD), 2025, pp. 1857–1862
work page 2025
-
[43]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
work page 2016
-
[44]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[45]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 3730–3738
work page 2015
-
[46]
Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition,
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel, “Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition,” inNeural Networks (IJCNN), 2012 International Joint Conference on. IEEE, 2012, pp. 1134–1141
work page 2012
-
[47]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018. 14
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.