Recognition: no theorem link
High Volatility and Action Bias Distinguish LLMs from Humans in Group Coordination
Pith reviewed 2026-05-13 20:04 UTC · model grok-4.3
The pith
LLMs exhibit high volatility and excessive switching in group tasks, failing to adapt and converge like humans do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
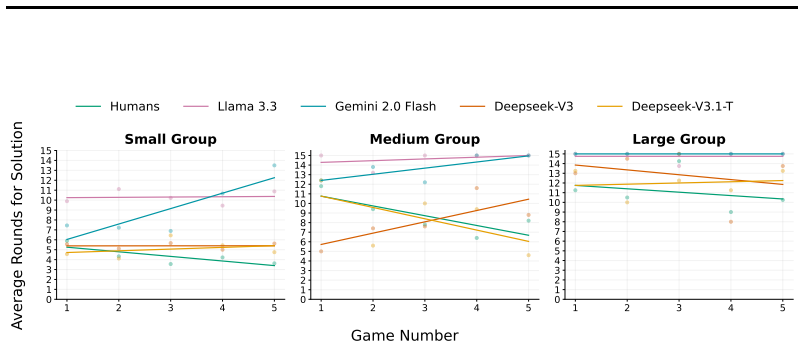
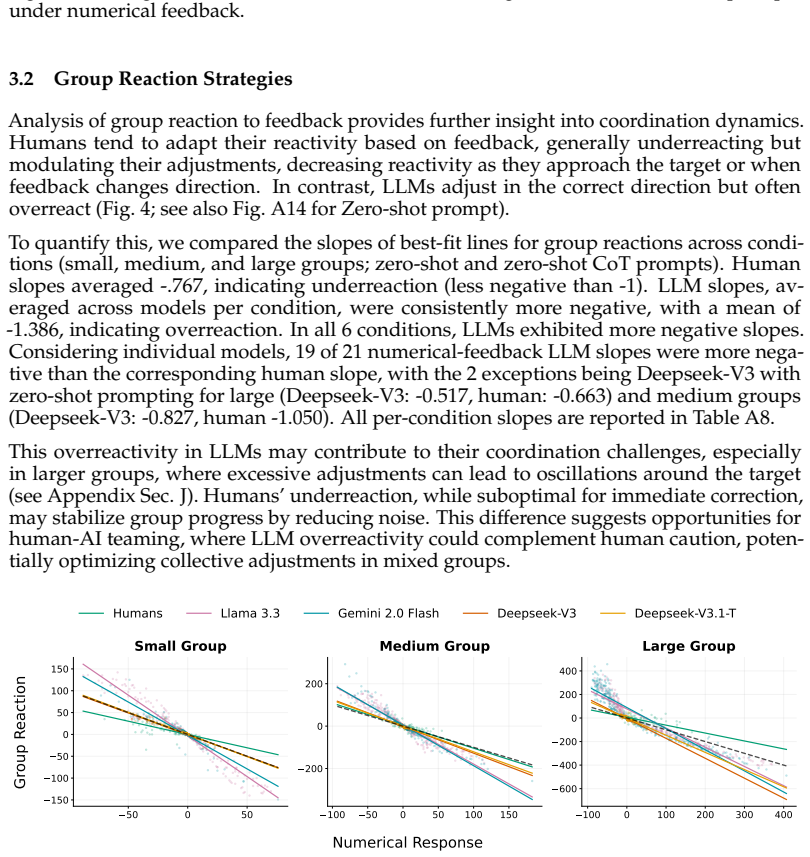
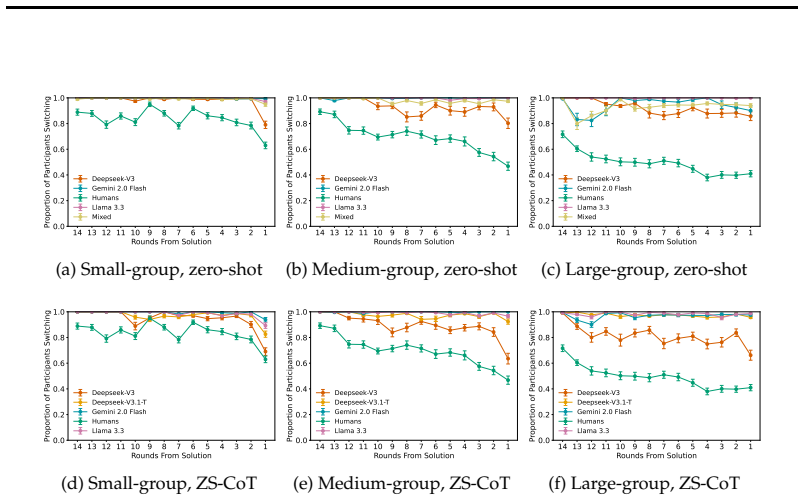
In the Group Binary Search game with imperfect monitoring, human participants adapt submissions over successive rounds and stabilize around effective values, enabling groups to reach the target more reliably, whereas LLM agents display persistently high action volatility and frequent switching that prevents stabilization and impairs collective convergence, with richer numerical feedback yielding only small effects on LLM groups.
What carries the argument
The Group Binary Search game, in which n players submit numbers to sum to a hidden target and receive only group-level feedback, together with mechanism-level metrics of reactivity scaling, switching dynamics, and cross-game learning.
If this is right
- Humans improve coordination across games through behavioral stabilization.
- LLMs maintain high switching that blocks group convergence.
- Richer error-magnitude feedback aids humans far more than LLMs.
- Volatility and action bias are distinguishing features of LLM groups.
- Mechanism metrics such as switching dynamics separate human and LLM strategies.
Where Pith is reading between the lines
- LLMs may need targeted training on multi-round adaptation to close the coordination gap.
- The volatility pattern could appear in other imperfect-information multi-agent settings.
- Varying group size or feedback granularity might expose additional LLM limitations.
- The diagnostic could help evaluate future models on collaborative tasks.
Load-bearing premise
The specific Group Binary Search setup and prompting protocols used provide a fair test of coordination without major artifacts that would favor or hinder LLMs differently from humans.
What would settle it
A controlled run in which LLMs reduce their switching rates and show measurable improvement in convergence across repeated games under the same feedback conditions would falsify the claimed distinction.
Figures



read the original abstract
Humans exhibit remarkable abilities to coordinate in groups. As large language models (LLMs) become more capable, it remains an open question whether they can demonstrate comparable adaptive coordination and whether they use the same strategies as humans. To investigate this, we compare LLM and human performance on a common-interest game with imperfect monitoring: Group Binary Search. In this n-player game, participants need to coordinate their actions to achieve a common objective. Players independently submit numerical values in an effort to collectively sum to a randomly assigned target number. Without direct communication, they rely on group feedback to iteratively adjust their submissions until they reach the target number. Our findings show that, unlike humans who adapt and stabilize their behavior over time, LLMs often fail to improve across games and exhibit excessive switching, which impairs group convergence. Moreover, richer feedback (e.g., numerical error magnitude) benefits humans substantially but has small effects on LLMs. Taken together, by grounding the analysis in human baselines and mechanism-level metrics, including reactivity scaling, switching dynamics, and learning across games, we point to differences in human and LLM groups and provide a behaviorally grounded diagnostic for closing the coordination gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript compares LLM and human groups in the Group Binary Search game, an n-player common-interest coordination task with imperfect monitoring in which participants submit numbers to collectively match a random target sum using only aggregate feedback. The central claim is that humans adapt and stabilize submissions over repeated games, whereas LLMs fail to improve, display high volatility and excessive action switching that impairs convergence, and benefit far less from richer feedback (e.g., numerical error magnitude) than humans do. The analysis relies on mechanism-level metrics including reactivity scaling, switching dynamics, and cross-game learning to diagnose these differences.
Significance. If the reported contrasts are robust, the work supplies a concrete, behaviorally grounded diagnostic for LLM coordination deficits that is anchored in human baselines rather than abstract benchmarks. The emphasis on volatility and switching as distinguishing features, together with the differential response to feedback richness, offers actionable guidance for multi-agent LLM design and could help close the observed coordination gap.
major comments (2)
- [Methods] Methods section: the manuscript provides no sample sizes for human or LLM participants, no specification of the exact LLM models/versions/temperatures used, and no description of the statistical tests or error-bar conventions supporting the directional claims of 'failure to improve' and 'excessive switching.' These omissions leave open whether the observed patterns are statistically reliable or could be artifacts of small N or particular prompting choices.
- [Results] Results section (feedback conditions): the claim that richer feedback 'benefits humans substantially but has small effects on LLMs' is presented without reported effect sizes, confidence intervals, or interaction statistics; without these, it is impossible to judge whether the differential benefit is load-bearing for the coordination-gap diagnosis.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly quantified the key metrics (e.g., average switching rate or improvement slope) rather than relying solely on qualitative descriptors.
- [Figures] Figure legends should explicitly state the number of independent groups or runs underlying each plotted line to aid visual assessment of variability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped strengthen the transparency and statistical grounding of our manuscript. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no sample sizes for human or LLM participants, no specification of the exact LLM models/versions/temperatures used, and no description of the statistical tests or error-bar conventions supporting the directional claims of 'failure to improve' and 'excessive switching.' These omissions leave open whether the observed patterns are statistically reliable or could be artifacts of small N or particular prompting choices.
Authors: We agree that these methodological details are essential for reproducibility and for assessing whether the reported patterns could be artifacts. In the revised manuscript we have added the human and LLM sample sizes, the precise models/versions/temperatures employed, and a complete description of the statistical tests and error-bar conventions. These additions confirm that the directional claims rest on adequate sample sizes and standard inferential procedures. revision: yes
-
Referee: [Results] Results section (feedback conditions): the claim that richer feedback 'benefits humans substantially but has small effects on LLMs' is presented without reported effect sizes, confidence intervals, or interaction statistics; without these, it is impossible to judge whether the differential benefit is load-bearing for the coordination-gap diagnosis.
Authors: We acknowledge that quantitative support for the differential effect of feedback richness was missing. The revised Results section now includes effect sizes, 95% confidence intervals, and the group-by-feedback interaction statistics. These additions demonstrate that the benefit is substantially and reliably larger for humans than for LLMs, thereby strengthening the coordination-gap diagnosis. revision: yes
Circularity Check
No significant circularity in empirical comparisons
full rationale
The paper reports an empirical comparison of LLM and human groups in the Group Binary Search task, with claims based on observed differences in adaptation over games, switching rates, reactivity scaling, and response to feedback levels. These metrics are computed directly from experimental data against independent human baselines, without any derivation chain, fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations that reduce the central findings to their own inputs by construction. The analysis is self-contained through direct behavioral contrasts rather than theoretical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Group Binary Search game with imperfect monitoring is a valid proxy for real-world group coordination without direct communication.
Reference graph
Works this paper leans on
-
[1]
doi: https://doi.org/10.1016/j.artint.2019.103216
ISSN 0004-3702. doi: https://doi.org/10.1016/j.artint.2019.103216. URL https: //www.sciencedirect.com/science/article/pii/S0004370219300116. Micah Carroll, Rohin Shah, Mark K Ho, Tom Griffiths, Sanjit Seshia, Pieter Abbeel, and Anca Dragan. On the utility of learning about humans for human-ai coordination. In H. Wallach, H. Larochelle, A. Beygelzimer, F. ...
-
[2]
doi: 10.1038/s41746-019-0189-7
ISSN 2398-6352. doi: 10.1038/s41746-019-0189-7. URL https://doi.org/10.1038/ s41746-019-0189-7. Huy Nhat Phan, Tien N Nguyen, Phong X Nguyen, and Nghi DQ Bui. Hyperagent: Generalist software engineering agents to solve coding tasks at scale.arXiv preprint arXiv:2409.16299, 2024. 11 Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng ...
-
[3]
URLhttps://aclanthology.org/2024.acl-long.810/. Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model-based multi-agent collaboration. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.ne...
-
[4]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/ v1/2025.emnlp-main.249. URLhttps://aclanthology.org/2025.emnlp-main.249/. Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D. Nguyen. Multi-agent collaboration mechanisms: A survey of llms, 2025. URLhttps://arxiv.org/abs/2501.06322. T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/tccn 2025
-
[5]
In each round, each player submits their own number. All of the players’ numbers are summed together and compared to the mystery number that has a value between 51 and 100. All of the players are given identical feedback on whether their group’s total sum was too low, too high, or just right, and each player decides for themselves whether and how to adjus...
-
[6]
In each round, each player submits their own number. All of the players’ numbers are summed together and compared to the mystery number that has a value between 51 and 100. All of the players are given identical feedback on whether their group’s total sum was too low, too high, or just right, and each player decides for themselves whether and how to adjus...
-
[7]
In each round, each player submits their own number. All of the players’ numbers are summed together and compared to the mystery number that has a value between 51 and 100. All of the players are given identical feedback on whether their group’s total sum was too low, too high, or just right, and each player decides for themselves whether and how to adjus...
-
[8]
Since this is the first round of a new game, I don’t have any previous feedback to work with
-
[9]
The mystery number is between 51-100, and I’m one of two players
-
[10]
A reasonable starting point would be to choose a number around the middle of my possible range (0-50)
-
[11]
Choosing 25 gives room to adjust upward if needed while still leaving flexibility for my partner to contribute. ```json {"chosen_number": 25} ``` Figure A10 Gemini 2.0 Flash Zero-Shot CoT Response in 2-Player Game (Game 10 Round 1) * **Initial Round:** Without any history, it’s best to start with a number around the middle of the allowed range (0-50). Let...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.