Recognition: 2 theorem links
· Lean TheoremScalable Mean-Variance Portfolio Optimization via Subspace Embeddings and GPU-Friendly Nesterov-Accelerated Projected Gradient
Pith reviewed 2026-05-13 18:35 UTC · model grok-4.3
The pith
Randomized sketching combined with GPU-accelerated Nesterov projection solves large mean-variance portfolio problems in seconds while bounding approximation error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Starting from the sample covariance factor L, the method constructs an effective factor L_eff via randomized subspace embedding, spectral truncation, and ridge stabilization, then solves the constrained mean-variance problem with a GPU-friendly Nesterov-accelerated projected gradient algorithm whose structured projection is obtained by scalar dual search, delivering explicit O(ε) bounds on covariance approximation error, optimal-value error, and solution perturbation under (ε,δ)-subspace embeddings.
What carries the argument
The Nesterov-Accelerated Projected Gradient Algorithm (NPGA) with scalar-dual-search projection applied to the effective factor matrix obtained from randomized subspace embeddings.
If this is right
- The unreduced full model for 5440 assets solves in 2.80 seconds on GPU versus 64.84 seconds with Gurobi.
- Sketched and STR-regularized variants stay in the low-single-digit-second regime.
- Covariance approximation, optimal value, and solution perturbation remain within explicit O(ε) bounds under (ε,δ)-subspace embeddings.
- The same computational pipeline handles baseline, sketched, and ridge-regularized models uniformly.
- After compression the projection step, not matrix-vector multiplication, becomes the remaining runtime bottleneck.
Where Pith is reading between the lines
- The same sketching-plus-projection structure could apply to other large-scale quadratic programs that share a factor-plus-linear-constraint form.
- Targeted improvements to the scalar dual search for projection could yield further speed-ups on even larger instances.
- Testing the embedding guarantees on portfolios with non-equity assets or different constraint families would check robustness beyond the reported equity data.
- Modern GPUs appear to make the dense unreduced model practical, suggesting compression is optional rather than mandatory for many practical sizes.
Load-bearing premise
Randomized subspace embeddings preserve the covariance approximation, optimal value, and solution with explicit O(ε) bounds for the given portfolio data and constraints.
What would settle it
On the 5440-asset real equity benchmark, if the measured optimal-value error or solution perturbation substantially exceeds the O(ε) bound predicted by the subspace-embedding analysis, the approximation guarantees fail.
Figures

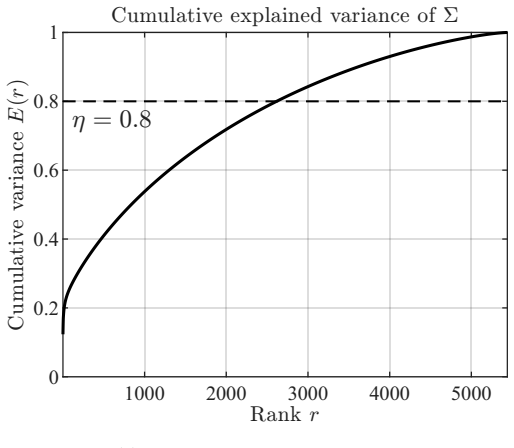





read the original abstract
We develop a sketch-based factor reduction and a Nesterov-accelerated projected gradient algorithm (NPGA) with GPU acceleration, yielding a doubly accelerated solver for large-scale constrained mean-variance portfolio optimization. Starting from the sample covariance factor $L$, the method combines randomized subspace embedding, spectral truncation, and ridge stabilization to construct an effective factor $L_{eff}$. It then solves the resulting constrained problem with a structured projection computed by scalar dual search and GPU-friendly matrix-vector kernels, yielding one computational pipeline for the baseline, sketched, and Sketch-Truncate-Ridge (STR)-regularized models. We also establish approximation, conditioning, and stability guarantees for the sketching and STR models, including explicit $O(\varepsilon)$ bounds for the covariance approximation, the optimal value error, and the solution perturbation under $(\varepsilon,\delta)$-subspace embeddings. Experiments on synthetic and real equity-return data show that the method preserves objective accuracy while reducing runtime substantially. On a 5440-asset real-data benchmark with 48374 training periods, NPGA-GPU solves the unreduced full model in 2.80 seconds versus 64.84 seconds for Gurobi, while the optimized compressed GPU variants remain in the low-single-digit-second regime. These results show that the full dense model is already practical on modern GPUs and that, after compression, the remaining bottleneck is projection rather than matrix-vector multiplication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a sketch-based factor reduction technique using randomized subspace embeddings, spectral truncation, and ridge stabilization to construct an effective factor L_eff from the sample covariance factor L. It then applies a Nesterov-accelerated projected gradient algorithm (NPGA) with GPU-friendly kernels and scalar dual search for the projection to solve the constrained mean-variance portfolio optimization problem. The work claims explicit O(ε) approximation, conditioning, and stability guarantees for the covariance, optimal value, and solution under (ε,δ)-subspace embeddings, and reports substantial runtime reductions (e.g., 2.80s vs. 64.84s for Gurobi on a 5440-asset instance) while preserving accuracy on synthetic and real equity data.
Significance. If the O(ε) solution perturbation bounds are rigorously established, the paper would provide a practical, theoretically supported pipeline for scaling dense mean-variance optimization to large portfolios on modern GPUs, combining sketching with accelerated first-order methods in a way that addresses both computational and approximation aspects. The explicit runtime comparisons and unified treatment of baseline, sketched, and STR-regularized models strengthen the contribution.
major comments (2)
- [Stability Guarantees (Section 4, Theorem on solution perturbation)] The central stability claim asserts explicit O(ε) bounds on solution perturbation for the constrained problem under (ε,δ)-subspace embeddings. Standard embedding results bound the covariance perturbation ||L_eff L_eff^T - L L^T||, but the solution error depends on the sensitivity of the argmin map, which here uses scalar dual search for the projection onto budget and non-negativity constraints. The manuscript must show that the Lipschitz constant of this projection (or the condition number of the active constraint Jacobian) is controlled independently of ε; otherwise the claimed O(ε) solution error can inflate. This analysis is load-bearing for the guarantee and is not indicated as present.
- [Abstract and Section 4] The abstract states that the bounds hold for the full pipeline including the projection step, yet the derivation of the solution perturbation must absorb or bound the projection sensitivity. If this step is only sketched without the requisite Lipschitz or strong-convexity modulus control, the O(ε) claim for the solution does not follow directly from the covariance approximation.
minor comments (1)
- [Section 3] Clarify the precise definition and construction of L_eff in the STR-regularized model, including how ridge stabilization interacts with the spectral truncation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The comments correctly identify that the O(ε) solution perturbation bound requires explicit control of the projection sensitivity, which we will strengthen in the revision.
read point-by-point responses
-
Referee: [Stability Guarantees (Section 4, Theorem on solution perturbation)] The central stability claim asserts explicit O(ε) bounds on solution perturbation for the constrained problem under (ε,δ)-subspace embeddings. Standard embedding results bound the covariance perturbation ||L_eff L_eff^T - L L^T||, but the solution error depends on the sensitivity of the argmin map, which here uses scalar dual search for the projection onto budget and non-negativity constraints. The manuscript must show that the Lipschitz constant of this projection (or the condition number of the active constraint Jacobian) is controlled independently of ε; otherwise the claimed O(ε) solution error can inflate. This analysis is load-bearing for the guarantee and is not indicated as present.
Authors: We agree that the current derivation sketches the propagation from covariance perturbation to solution error without a fully explicit bound on the projection Lipschitz constant. The ridge term in the STR model ensures strong convexity with modulus bounded below by the ridge parameter independently of ε. In the revision we will insert a dedicated lemma (new Lemma 4.X) that bounds the Lipschitz constant of the scalar dual search projection by a quantity depending only on the ridge parameter, the minimum eigenvalue lower bound, and the geometry of the budget/non-negativity constraints, thereby closing the gap and confirming the O(ε) solution perturbation. revision: yes
-
Referee: [Abstract and Section 4] The abstract states that the bounds hold for the full pipeline including the projection step, yet the derivation of the solution perturbation must absorb or bound the projection sensitivity. If this step is only sketched without the requisite Lipschitz or strong-convexity modulus control, the O(ε) claim for the solution does not follow directly from the covariance approximation.
Authors: The abstract claim rests on the combined analysis in Section 4. We will expand the proof to explicitly absorb the projection sensitivity via the new lemma described above, using the ridge-controlled strong-convexity modulus. The revised Section 4 will state the full chain of inequalities with all constants made explicit and independent of ε. The abstract wording will be clarified to reference the strengthened assumptions if needed. revision: yes
Circularity Check
No significant circularity; derivation relies on standard subspace embedding theory with explicit bounds.
full rationale
The paper's central claims involve constructing an effective factor via randomized subspace embeddings, spectral truncation, and ridge stabilization, then solving via Nesterov-accelerated projected gradient with GPU kernels. It states explicit O(ε) approximation bounds for covariance, optimal value, and solution perturbation under (ε,δ)-subspace embeddings. No quoted step reduces a prediction to a fitted parameter by construction, invokes self-citation as load-bearing uniqueness, or renames a known result as new derivation. The bounds are presented as derived from embedding properties rather than tautological reparameterization, making the pipeline self-contained against external randomized linear algebra results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Randomized subspace embeddings approximate the covariance factor with explicit O(ε) error bounds that carry over to optimal value and solution perturbation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearsketch-based factor reduction and Nesterov-accelerated projected gradient algorithm (NPGA) with GPU acceleration... explicit O(ε) bounds for the covariance approximation, the optimal value error, and the solution perturbation under (ε,δ)-subspace embeddings
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearSTR pipeline... ridge stabilization... conditioning improvement
Reference graph
Works this paper leans on
-
[1]
Heinz H. Bauschke and Jonathan M. Borwein. On projection algorithms for solving convex feasibility problems. SIAM Review, 38 0 (3): 0 367--426, 1996
work page 1996
-
[2]
A fast iterative shrinkage-thresholding algorithm for linear inverse problems
Amir Beck and Marc Teboulle. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences, 2 0 (1): 0 183--202, 2009. doi:10.1137/080716542
-
[3]
Robust solutions of linear programming problems contaminated with uncertain data
Aharon Ben-Tal and Arkadi Nemirovski. Robust solutions of linear programming problems contaminated with uncertain data. Mathematical Programming, 88 0 (3): 0 411--424, 2000
work page 2000
- [4]
-
[5]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3 0 (1): 0 1--122, 2011
work page 2011
-
[6]
Kenneth L. Clarkson and David P. Woodruff. Low-rank approximation and regression in input sparsity time. Journal of the ACM, 63 0 (6): 0 54:1--54:45, 2017
work page 2017
-
[7]
Fast projection onto the simplex and the _ 1 ball
Laurent Condat. Fast projection onto the simplex and the _ 1 ball. Mathematical Programming, 158 0 (1--2): 0 575--585, 2016
work page 2016
-
[8]
Victor De Miguel, Lorenzo Garlappi, and Raman Uppal. Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? The Review of Financial Studies, 22 0 (5): 0 1915--1953, 2009. doi:10.1093/rfs/hhm075
-
[9]
Petros Drineas and Michael W. Mahoney. RandNLA : Randomized numerical linear algebra. Communications of the ACM, 59 0 (6): 0 80--90, 2016
work page 2016
-
[10]
Efficient projections onto the _ 1 -ball for learning in high dimensions
John Duchi, Shai Shalev-Shwartz, Yoram Singer, and Tushar Chandra. Efficient projections onto the _ 1 -ball for learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning (ICML), pages 272--279, 2008
work page 2008
-
[11]
Large covariance estimation by thresholding principal orthogonal complements
Jianqing Fan, Yuan Liao, and Martina Mincheva. Large covariance estimation by thresholding principal orthogonal complements. Journal of the Royal Statistical Society: Series B, 75 0 (4): 0 603--680, 2013
work page 2013
-
[12]
Robust portfolio selection problems
Donald Goldfarb and Garud Iyengar. Robust portfolio selection problems. Mathematics of Operations Research, 28 0 (1): 0 1--38, 2003
work page 2003
-
[13]
Gurobi Optimizer Reference Manual, Version 11.0
Gurobi Optimization, LLC . Gurobi Optimizer Reference Manual, Version 11.0. Gurobi Optimization, LLC, 2023. Available at https://www.gurobi.com
work page 2023
-
[14]
Roger A. Horn and Charles R. Johnson. Matrix Analysis. Cambridge University Press, Cambridge, 2nd edition, 2012
work page 2012
-
[15]
IBM ILOG CPLEX Optimization Studio: CPLEX User's Manual
IBM Corporation . IBM ILOG CPLEX Optimization Studio: CPLEX User's Manual. IBM Corporation, 2024. Available at https://www.ibm.com/analytics/cplex-optimizer
work page 2024
-
[16]
Risk reduction in large portfolios: Why imposing the wrong constraints helps
Ravi Jagannathan and Tongshu Ma. Risk reduction in large portfolios: Why imposing the wrong constraints helps. The Journal of Finance, 58 0 (4): 0 1651--1684, 2003
work page 2003
-
[17]
Johnson and Joram Lindenstrauss
William B. Johnson and Joram Lindenstrauss. Extensions of Lipschitz mappings into a Hilbert space. In Conference in Modern Analysis and Probability (Contemporary Mathematics, vol. 26), pages 189--206, 1984
work page 1984
-
[18]
A well-conditioned estimator for large-dimensional covariance matrices
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensional covariance matrices. Journal of Multivariate Analysis, 88 0 (2): 0 365--411, 2004
work page 2004
-
[19]
Nonlinear shrinkage estimation of large-dimensional covariance matrices
Olivier Ledoit and Michael Wolf. Nonlinear shrinkage estimation of large-dimensional covariance matrices. The Annals of Statistics, 40 0 (2): 0 1024--1060, 2012
work page 2012
-
[20]
Harry Markowitz. Portfolio selection. The Journal of Finance, 7 0 (1): 0 77--91, 1952
work page 1952
-
[21]
MOSEK Optimization Toolbox for MATLAB User's Guide
MOSEK ApS . MOSEK Optimization Toolbox for MATLAB User's Guide. MOSEK ApS, 2024. Available at https://www.mosek.com
work page 2024
-
[22]
Introductory Lectures on Convex Optimization: A Basic Course
Yurii Nesterov. Introductory Lectures on Convex Optimization: A Basic Course. Springer, 2004
work page 2004
-
[23]
Improved approximation algorithms for large matrices via random projections
Tam \'a s Sarl \'o s. Improved approximation algorithms for large matrices via random projections. In Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS), pages 143--152, 2006
work page 2006
-
[24]
Mark Schmidt, Nicolas Le Roux, and Francis R. Bach. Convergence rates of inexact proximal-gradient methods for convex optimization. In Advances in Neural Information Processing Systems 24, pages 1458--1466, 2011. URL https://papers.nips.cc/paper_files/paper/2011/file/8f7d807e1f53eff5f9efbe5cb81090fb-Paper.pdf
work page 2011
- [25]
-
[26]
An improved Yau--Yau algorithm for high dimensional nonlinear filtering problems
Shing-Tung Yau and Yi-Shuai Niu. An improved Yau--Yau algorithm for high dimensional nonlinear filtering problems. Pure and Applied Mathematics Quarterly, 21 0 (6): 0 2369--2423, 2025. doi:10.4310/PAMQ.251222233358
-
[27]
Shing-Tung Yau and Stephen S.-T. Yau. Real time solution of nonlinear filtering problem without memory I . Mathematical Research Letters, 7 0 (5--6): 0 671--693, 2000
work page 2000
-
[28]
Shing-Tung Yau and Stephen S.-T. Yau. Real time solution of the nonlinear filtering problem without memory II . SIAM Journal on Control and Optimization, 47 0 (1): 0 163--195, 2008. doi:10.1137/050648353
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.