Recognition: no theorem link
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Pith reviewed 2026-05-13 19:23 UTC · model grok-4.3
The pith
JoyAI-LLM Flash is a 48B-parameter MoE model that activates only 2.7B parameters per forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
JoyAI-LLM Flash comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. The model is pretrained on a 20-trillion-token corpus and further optimized through a post-training pipeline that includes FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components for unified multi-scale stability control. The architecture also balances thinking and non-thinking cognitive modes and incorporates joint training-inference co-design with dense multi-token prediction and quantization-aware trai
What carries the argument
FiberPO, a reinforcement-learning algorithm that splits trust-region maintenance into separate global and local components to enforce multi-scale stability during LLM policy optimization.
If this is right
- The sparsity ratio allows the model to match or exceed performance of denser contemporaries while using far less active computation per token.
- Joint training-inference co-design with multi-token prediction and quantization-aware training raises inference throughput.
- Release of both the base 48B-A3B checkpoint and its post-trained variants enables direct community inspection and further adaptation.
- Strategic balancing of thinking and non-thinking modes reduces token waste on routine steps.
Where Pith is reading between the lines
- If the sparsity pattern generalizes, similar MoE designs could push total parameter counts well beyond 100B while keeping active compute fixed.
- FiberPO's global-local split may transfer to other policy-gradient settings where stability must hold across different update horizons.
- Lower active-parameter counts at inference time would cut energy and latency costs in production deployments of comparable capability.
- The open checkpoints make it possible to test whether the efficiency gains survive fine-tuning on new domains.
Load-bearing premise
The combination of FiberPO, SFT, DPO, and large-scale RL produces the claimed token efficiency and performance without hidden degradations or unstated trade-offs.
What would settle it
A side-by-side benchmark run showing that JoyAI-LLM Flash consumes more tokens or active compute than claimed to reach parity with a dense 48B baseline on standard reasoning suites would disprove the efficiency advantage.
Figures
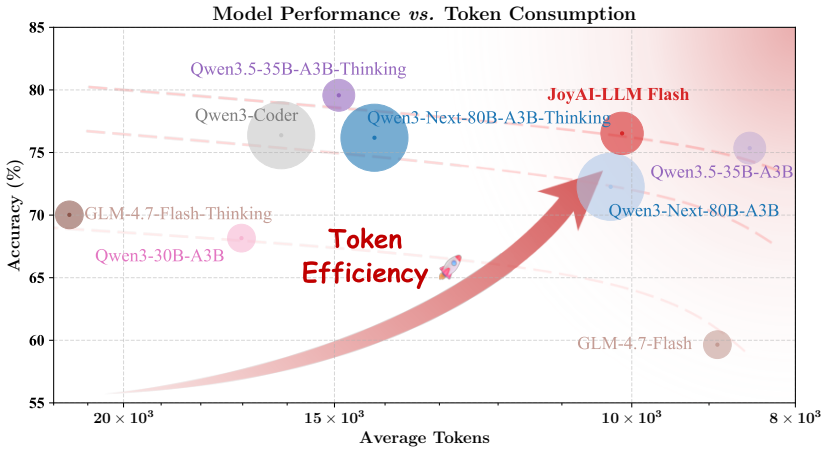





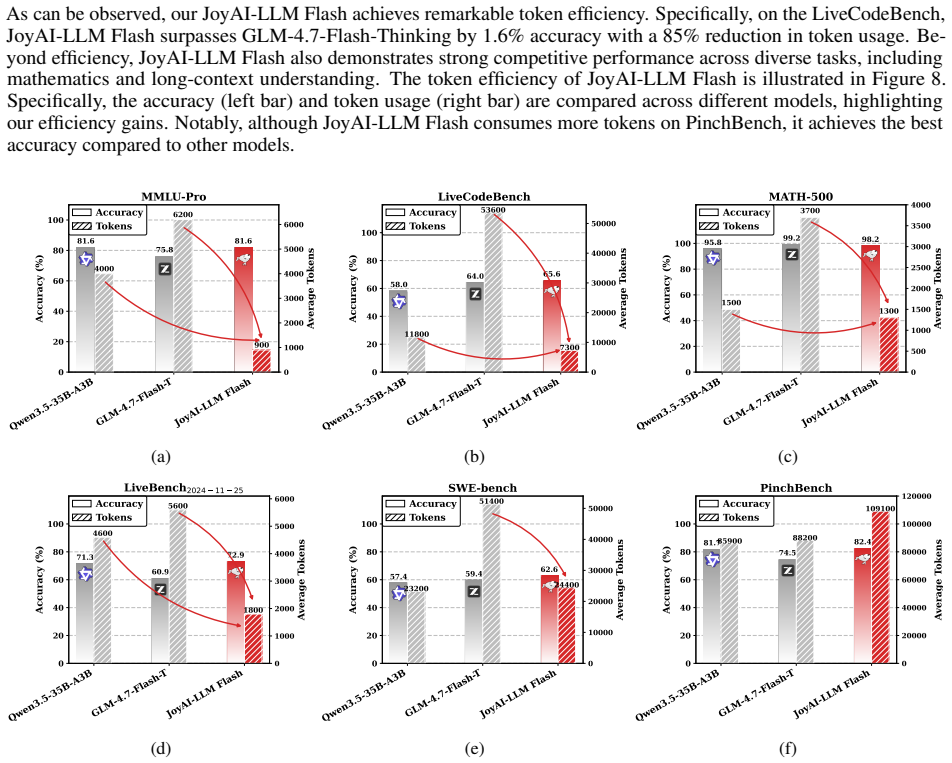


read the original abstract
We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JoyAI-LLM Flash, a 48B-parameter Mixture-of-Experts model that activates only 2.7B parameters per forward pass. It is pretrained on 20 trillion tokens and post-trained via SFT, DPO, large-scale RL, and a novel FiberPO algorithm (inspired by fibration theory for multi-scale trust-region control). Additional co-design elements include dense Multi-Token Prediction and Quantization-Aware Training. The authors claim substantially higher sparsity than peer models of comparable scale and release base and post-trained checkpoints on Hugging Face.
Significance. If the sparsity ratio and efficiency gains are empirically validated, the work could advance practical mid-scale LLM deployment by showing how architectural sparsity combined with specialized RL can improve token efficiency without proportional performance loss. The open release of checkpoints would aid reproducibility.
major comments (2)
- [Abstract] Abstract: The headline claim of activating only 2.7B parameters out of 48B total and achieving a 'substantially higher sparsity ratio' than contemporary models (e.g., Mixtral-8x7B or DeepSeek-V2) is stated without any table, baseline active-parameter counts, or quantitative comparison, leaving the central efficiency assertion unsupported.
- [Abstract] Abstract: The post-training pipeline (FiberPO + SFT + DPO + large-scale RL) is described as delivering improved token efficiency and performance, yet no benchmark scores, ablation results, or delta tables versus baselines appear in the provided text, so the performance and stability claims cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: The phrase 'joint training-inference co-design' is used without specifying which components are jointly optimized or how the dense MTP interacts with the MoE routing, which reduces clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate quantitative support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of activating only 2.7B parameters out of 48B total and achieving a 'substantially higher sparsity ratio' than contemporary models (e.g., Mixtral-8x7B or DeepSeek-V2) is stated without any table, baseline active-parameter counts, or quantitative comparison, leaving the central efficiency assertion unsupported.
Authors: We agree that the abstract would be strengthened by explicit quantitative comparisons. In the revised manuscript we will insert a compact table (or inline values) listing total and active parameter counts for the cited baselines: Mixtral-8x7B (46.7 B total, ~12.9 B active) and DeepSeek-V2 (236 B total, 21 B active). This will directly substantiate the 48 B / 2.7 B sparsity ratio claim. revision: yes
-
Referee: [Abstract] Abstract: The post-training pipeline (FiberPO + SFT + DPO + large-scale RL) is described as delivering improved token efficiency and performance, yet no benchmark scores, ablation results, or delta tables versus baselines appear in the provided text, so the performance and stability claims cannot be evaluated.
Authors: We acknowledge that the abstract itself contains no numerical results. The full manuscript reports benchmark scores and ablations in Section 4; however, to make the abstract self-contained we will add a concise summary table of key metrics (MMLU, GSM8K, etc.) together with deltas versus the same baselines, plus a one-sentence reference to the FiberPO ablation findings on stability. revision: yes
Circularity Check
No significant circularity detected; claims are descriptive design statements without equation-level reductions
full rationale
The manuscript presents JoyAI-LLM Flash as a 48B-parameter MoE model activating 2.7B parameters, pretrained on 20T tokens and post-trained via SFT/DPO/RL plus the FiberPO algorithm. No equations, derivations, or fitted-parameter predictions appear in the abstract or described sections. The sparsity ratio is asserted as an architectural outcome rather than derived from self-citations, uniqueness theorems, or renamed empirical patterns. FiberPO is introduced as a novel RL method inspired by fibration theory without reducing to prior self-cited results. The central claims therefore remain self-contained descriptions of model scale and training pipeline rather than circular reductions to their own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Universally Empowering Zeroth-Order Optimization via Adaptive Layer-wise Sampling
AdaLeZO uses a non-stationary multi-armed bandit to adaptively allocate perturbation budget across layers in zeroth-order optimization and applies inverse probability weighting to reduce variance while preserving unbi...
-
Irminsul: MLA-Native Position-Independent Caching for Agentic LLM Serving
Irminsul recovers up to 83% of prompt tokens above exact-prefix matching and delivers 63% prefill energy savings per cache hit on MLA-MoE models by content-hashing CDC chunks and applying closed-form kr correction.
Reference graph
Works this paper leans on
-
[1]
Ockbench: Measuring the efficiency of llm reasoning.arXiv:2511.05722, 2026
Zheng Du, Hao Kang, Song Han, Tushar Krishna, and Ligeng Zhu. Ockbench: Measuring the efficiency of llm reasoning.arXiv:2511.05722, 2026
-
[2]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
GLM Team. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models, 2025
work page 2025
-
[5]
Qwen3-30b-a3b-instruct-2507, July 2026
Qwen Team. Qwen3-30b-a3b-instruct-2507, July 2026
work page 2026
-
[6]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[7]
Step 3.5 flash: Open frontier-level intelligence with 11b active parameters, 2026
Ailin Huang, Ang Li, et al. Step 3.5 flash: Open frontier-level intelligence with 11b active parameters, 2026
work page 2026
-
[8]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
Biao Zhang and Rico Sennrich. Root mean square layer normalization.Advances in neural information processing systems, 32, 2019
work page 2019
-
[11]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[12]
Language modeling with gated convolutional networks
Yann N Dauphin, Angela Fan, Michael Auli, and David Grangier. Language modeling with gated convolutional networks. InInternational conference on machine learning, pages 933–941. PMLR, 2017
work page 2017
-
[13]
Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664,
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664, 2024
-
[14]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cecista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. 6
work page 2024
-
[15]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[17]
Gpipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. Advances in neural information processing systems, 32, 2019
work page 2019
-
[18]
Pipedream: Fast and efficient pipeline parallel dnn training, 2018.URL https://arxiv
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. Pipedream: Fast and efficient pipeline parallel dnn training, 2018.URL https://arxiv. org/abs, 1806
work page 2018
-
[19]
Breadth-first pipeline parallelism.Proceedings of Machine Learning and Systems, 5:48–67, 2023
Joel Lamy-Poirier. Breadth-first pipeline parallelism.Proceedings of Machine Learning and Systems, 5:48–67, 2023
work page 2023
-
[20]
Hanayo: Harnessing wave-like pipeline parallelism for enhanced large model training efficiency
Ziming Liu, Shenggan Cheng, Haotian Zhou, and Yang You. Hanayo: Harnessing wave-like pipeline parallelism for enhanced large model training efficiency. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–13, 2023
work page 2023
-
[21]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. Efficient large-scale language model training on gpu clusters using megatron-lm. InProceedings of the international conference for high performance computing, networking, st...
work page 2021
-
[22]
Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241, 2023
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241, 2023
-
[23]
Moe a2a interleaved 1f1b based computation and communication overlap
NVIDIA. Moe a2a interleaved 1f1b based computation and communication overlap. https://developer.nvidia.com/zh- cn/blog/1f1b- moe- a2a- computing- overlap/, 2025. 24
work page 2025
-
[24]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[25]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020
work page 2020
-
[26]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 68658–68685. Curran Associates...
work page 2024
-
[27]
Datatrove: large scale data processing, 2024
Guilherme Penedo, Hynek Kydlíˇcek, Alessandro Cappelli, Mario Sasko, and Thomas Wolf. Datatrove: large scale data processing, 2024
work page 2024
-
[28]
Approximate nearest neighbors: towards removing the curse of dimensionality
Piotr Indyk and Rajeev Motwani. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the Thirtieth Annual ACM Symposium on Theory of Computing, STOC ’98, page 604–613, New York, NY , USA, 1998. Association for Computing Machinery
work page 1998
-
[29]
A.Z. Broder. On the resemblance and containment of documents. InProceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171), pages 21–29, 1997
work page 1997
-
[30]
Starcoder 2 and the stack v2: The next generation, 2024
Anton Lozhkov and Raymond Liand others. Starcoder 2 and the stack v2: The next generation, 2024
work page 2024
- [31]
-
[32]
Qwen2.5-Coder Technical Report
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, et al. Qwen2.5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Rewriting pre-training data boosts llm performance in math and code, 2025
Kazuki Fujii, Yukito Tajima, Sakae Mizuki, Hinari Shimada, Taihei Shiotani, Koshiro Saito, Masanari Ohi, Masaki Kawamura, Taishi Nakamura, Takumi Okamoto, Shigeki Ishida, Kakeru Hattori, Youmi Ma, Hiroya Takamura, Rio Yokota, and Naoaki Okazaki. Rewriting pre-training data boosts llm performance in math and code, 2025
work page 2025
- [34]
-
[35]
NVIDIA Team. Nemotron 3 nano: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning, 2025
work page 2025
-
[36]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025
work page 2025
-
[37]
Mineru2.5: A decoupled vision-language model for efficient high-resolution document parsing, 2025
Junbo Niu, Zheng Liu, et al. Mineru2.5: A decoupled vision-language model for efficient high-resolution document parsing, 2025
work page 2025
-
[38]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Reformulation for pretraining data augmentation, 2025
Xintong Hao, Ruijie Zhu, Ge Zhang, Ke Shen, and Chenggang Li. Reformulation for pretraining data augmentation, 2025
work page 2025
-
[40]
Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro. Nemotron-cc: Transforming common crawl into a refined long-horizon pretraining dataset.ArXiv, abs/2412.02595, 2024
-
[41]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W. Rae, Sebastian Borgeaud, et al. Scaling language models: Methods, analysis & insights from training gopher.CoRR, abs/2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[43]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, et al. Training compute-optimal large language models.CoRR, abs/2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, et al. Scaling laws for neural language models.CoRR, abs/2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[45]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[46]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024. 25
work page 2024
-
[47]
Cmmlu: Measuring massive multitask language understanding in chinese
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. Cmmlu: Measuring massive multitask language understanding in chinese. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11260–11285, 2024
work page 2024
-
[48]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
Evaluating Large Language Models Trained on Code
Mark Chen. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025
work page 2025
-
[54]
Chao Xue, Wei Liu, et al. Omniforce: On human-centered, large model empowered and cloud-edge collaborative automl system.nature npj-ai, 2023
work page 2023
-
[55]
Swe-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. Swe-smith: Scaling data for software engineering agents. InProceedings of the 39th Annual Conference on Neural Information Processing Systems (NeurIPS 2025 D&B Spotlight), 2025. arXiv:2504.21798, accepted at ...
-
[56]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents, 2024
Xingyao Wang, Boxuan Li, et al. OpenHands: An Open Platform for AI Software Developers as Generalist Agents, 2024
work page 2024
-
[57]
SWE-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[58]
Openr1-math-220k dataset, 2025
Open-R1 Team. Openr1-math-220k dataset, 2025. Accessed: 2025-03-06
work page 2025
-
[59]
Wei Du, Shubham Toshniwal, Branislav Kisacanin, Sadegh Mahdavi, Ivan Moshkov, George Armstrong, Stephen Ge, Edgar Minasyan, Feng Chen, and Igor Gitman. Nemotron-math: Efficient long-context distillation of mathematical reasoning from multi-mode supervision.arXiv preprint arXiv:2512.15489, 2025
-
[60]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
work page 2020
-
[61]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[62]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
work page 2023
-
[63]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models.arXiv preprint arXiv:2411.04368, 2024
-
[64]
Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation
Satyapriya Krishna, Kalpesh Krishna, Anhad Mohananey, Steven Schwarcz, Adam Stambler, Shyam Upadhyay, and Manaal Faruqui. Fact, fetch, and reason: A unified evaluation of retrieval-augmented generation. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies...
work page 2025
-
[65]
Scholarsearch: Benchmarking scholar searching ability of llms.arXiv preprint arXiv:2506.13784, 2025
Junting Zhou, Wang Li, Yiyan Liao, Nengyuan Zhang, Tingjia Miao, Zhihui Qi, Yuhan Wu, and Tong Yang. Scholarsearch: Benchmarking scholar searching ability of llms.arXiv preprint arXiv:2506.13784, 2025
-
[66]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023. 26
work page 2023
-
[67]
Taskcraft: Automated generation of agentic tasks.arXiv preprint arXiv:2506.10055, 2025
Dingfeng Shi, Jingyi Cao, Qianben Chen, Weichen Sun, Weizhen Li, Hongxuan Lu, Fangchen Dong, Tianrui Qin, King Zhu, Minghao Liu, et al. Taskcraft: Automated generation of agentic tasks.arXiv preprint arXiv:2506.10055, 2025
-
[68]
Nemotron-Post-Training-Dataset-v1, 2025
Dhruv Nathawani, Igor Gitman, Somshubra Majumdar, Evelina Bakhturina, Ameya Sunil Mahabaleshwarkar, , Jian Zhang, and Jane Polak Scowcroft. Nemotron-Post-Training-Dataset-v1, 2025
work page 2025
-
[69]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
work page 2022
-
[70]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[71]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Fibration policy optimization.arXiv preprint arXiv:2603.08239, 2026
Chang Li, Tshihao Tsu, Yaren Zhang, Chao Xue, and Xiaodong He. Fibration policy optimization.arXiv preprint arXiv:2603.08239, 2026
-
[74]
Trust region policy optimiza- tion
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimiza- tion. InInternational Conference on Machine Learning, pages 1889–1897. PMLR, 2015
work page 2015
-
[75]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv:2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[77]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[78]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Yao Fu, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. Advances in Neural Information Processing Systems, 36:62991–63010, 2023
work page 2023
-
[79]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[80]
Supergpqa: Scaling llm evaluation across 285 graduate disciplines, 2025
M-A-P Team. Supergpqa: Scaling llm evaluation across 285 graduate disciplines, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.