Recognition: 2 theorem links
· Lean TheoremLPC-SM: Local Predictive Coding and Sparse Memory for Long-Context Language Modeling
Pith reviewed 2026-05-15 11:19 UTC · model grok-4.3
The pith
Long-context autoregressive modeling can be organized around a broader division of labor than attention alone by separating local attention, persistent memory, predictive correction, and run-time control within each block.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LPC-SM separates local attention, persistent memory, predictive correction, and run-time control within the same block and uses Orthogonal Novelty Transport to govern slow-memory writes, yielding stable training at sequence length 4096 with final LM loss 11.582 and cross-entropy improvement on the delayed-identifier task from 14.396 to 12.031.
What carries the argument
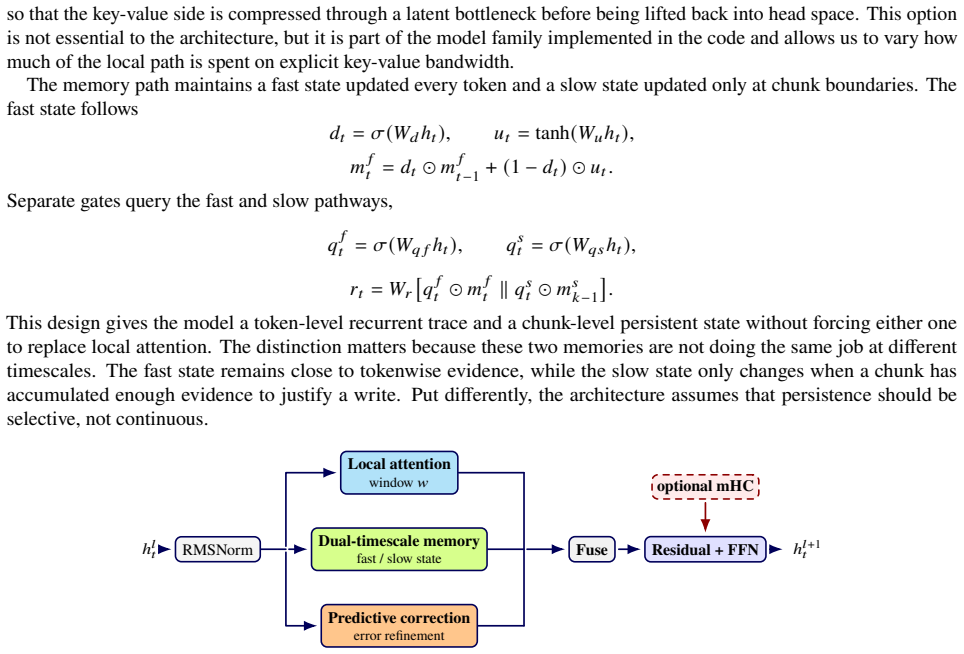
LPC-SM block that decomposes sequence modeling into local attention, persistent memory, predictive correction, and run-time control, with Orthogonal Novelty Transport controlling slow-memory writes.
If this is right
- Removing the mHC component raises Stage-A final LM loss from 12.630 to 15.127.
- Adaptive sparse control lowers Stage-B final LM loss from 12.137 to 10.787 relative to fixed-ratio continuation.
- The full model stays stable through 4096 tokens and ends Stage C at LM loss 11.582.
- The delayed-identifier diagnostic improves from 14.396 to 12.031 in cross-entropy.
Where Pith is reading between the lines
- The same component split could be tested in models larger than 158M to check whether the loss reductions continue to scale.
- Orthogonal Novelty Transport might be ported to other memory-augmented transformers to isolate its contribution from the rest of the LPC-SM block.
- Running the architecture at 8k or 16k tokens could reveal whether the explicit separation prevents the quadratic bottlenecks that appear in pure attention models.
- If the four roles can be re-wired at inference time, the design might support task-specific routing without retraining the entire network.
Load-bearing premise
The separation of local attention, persistent memory, predictive correction, and run-time control governed by Orthogonal Novelty Transport produces stable gains at length 4096 without hidden instabilities or costs.
What would settle it
Observing rising loss or new instabilities when the same 158M model is trained at lengths substantially beyond 4096 would falsify the claim of stable improvement from this division of labor.
Figures


read the original abstract
Most current long-context language models still rely on attention to handle both local interaction and long-range state, which leaves relatively little room to test alternative decompositions of sequence modeling. We propose LPC-SM, a hybrid autoregressive architecture that separates local attention, persistent memory, predictive correction, and run-time control within the same block, and we use Orthogonal Novelty Transport (ONT) to govern slow-memory writes. We evaluate a 158M-parameter model in three stages spanning base language modeling, mathematical continuation, and 4096-token continuation. Removing mHC raises the Stage-A final LM loss from 12.630 to 15.127, while adaptive sparse control improves the Stage-B final LM loss from 12.137 to 10.787 relative to a matched fixed-ratio continuation. The full route remains stable at sequence length 4096, where Stage C ends with final LM loss 11.582 and improves the delayed-identifier diagnostic from 14.396 to 12.031 in key cross-entropy. Taken together, these results show that long-context autoregressive modeling can be organized around a broader division of labor than attention alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LPC-SM, a hybrid autoregressive architecture that separates local attention, persistent memory, predictive correction, and run-time control within the same block, governed by Orthogonal Novelty Transport (ONT) for slow-memory writes. It evaluates a 158M-parameter model across three training stages (base LM, mathematical continuation, 4096-token continuation), reporting that removing mHC raises Stage-A LM loss from 12.630 to 15.127, adaptive sparse control lowers Stage-B loss from 12.137 to 10.787, and the full model reaches 11.582 LM loss with 12.031 delayed-identifier cross-entropy at 4096 tokens.
Significance. If the architecture proves stable and competitive, the work would support the viability of decomposing long-context modeling into a broader division of labor than attention alone, potentially informing more modular designs for extended sequences. The staged evaluation and internal ablations provide concrete empirical anchors, but the lack of external baselines prevents assessing whether these losses reflect genuine progress.
major comments (2)
- [Abstract] Abstract: the central claim that long-context autoregressive modeling can be organized around a broader division of labor than attention alone is unsupported, as no matched Transformer baseline (same 158M parameters, same training stages, same 4096 evaluation length) is reported; all quantitative results are internal ablations only.
- [Stage C evaluation] Stage C evaluation: stability at sequence length 4096 is asserted via final LM loss 11.582, but no metrics on memory footprint, wall-clock overhead, or divergence indicators are provided relative to attention, leaving the 'no hidden costs' assumption untested.
minor comments (2)
- [Abstract] Abstract: loss numbers are given without error bars, statistical tests, or explicit definition of the 'matched fixed-ratio continuation' baseline.
- [Method] The definition and orthogonality properties of Orthogonal Novelty Transport (ONT) require expanded pseudocode or equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the strength of our claims and the need for additional evaluation details. We respond to each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that long-context autoregressive modeling can be organized around a broader division of labor than attention alone is unsupported, as no matched Transformer baseline (same 158M parameters, same training stages, same 4096 evaluation length) is reported; all quantitative results are internal ablations only.
Authors: We agree that the central claim would be stronger with a matched Transformer baseline under identical conditions. Our results are limited to internal ablations that isolate the contributions of mHC, adaptive sparse control, and ONT, showing loss reductions attributable to these components. We will revise the abstract and discussion sections to qualify the claim as demonstrating the viability of the proposed decomposition via these ablations, rather than asserting superiority over attention-based models. This is a partial revision since new baseline experiments cannot be added. revision: partial
-
Referee: [Stage C evaluation] Stage C evaluation: stability at sequence length 4096 is asserted via final LM loss 11.582, but no metrics on memory footprint, wall-clock overhead, or divergence indicators are provided relative to attention, leaving the 'no hidden costs' assumption untested.
Authors: We concur that efficiency metrics are necessary to fully substantiate the stability claim at 4096 tokens. The current manuscript uses final LM loss and the delayed-identifier cross-entropy as primary indicators. In the revision we will add memory footprint details, any observed divergence indicators from training logs, and wall-clock measurements from the existing experimental runs to address the untested assumption directly. revision: yes
- No matched Transformer baseline with the same 158M parameters, training stages, and 4096-token evaluation was performed in the original experiments.
Circularity Check
No circularity: empirical ablations and staged losses are independent of the target claim
full rationale
The paper's chain consists of an architectural proposal (local attention + persistent memory + predictive correction + ONT-governed writes), followed by three-stage training and internal ablations (mHC removal, fixed vs. adaptive sparse control). Reported quantities are direct training losses and a delayed-identifier cross-entropy metric; none are obtained by fitting a parameter to the final claim and then re-deriving the claim from that parameter. No self-citation load-bearing step, no uniqueness theorem imported from prior work, and no renaming of known results as new organization. The derivation remains self-contained against external benchmarks because the quantitative support is generated by running the model rather than by algebraic rearrangement of its own inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Orthogonal Novelty Transport (ONT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ONT defines the aligned component ... proj(c_k | m^s_{k-1}) ... novelty component n_k = c_k - proj ... c★_k = c_k + α_n n_k
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem A.5 (ONT is the constrained minimizer) ... uniqueness in A(c,m)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Albert Gu and Tri Dao. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality, 2024. URLhttps://arxiv.org/abs/2405.21060. arXiv:2405.21060
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Soham De, Sam Smith, Anushan Fernando, Aleksandar Botev, George Tucker, Michal Valko, Razvan Pascanu, Sebastian Ruder, Yee Whye Teh, and Donald Metzler. Griffin: Mixing gated linear recurrences with local attention for efficient language models, 2024. URLhttps://arxiv.org/abs/2402.19427. arXiv:2402.19427
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time, 2025. URL https://arxiv.org/abs/2501.00663. arXiv:2501.00663
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Hymba: A hybrid-head architecture for small language models, 2024
Xin Dong, Tianyu Liu, Yuhang Zang, Yanyan Zhao, Jiapeng Zhang, Zhaopeng Tu, Chengqiang Huang, Huadong Wang, and Jie Zhou. Hymba: A hybrid-head architecture for small language models, 2024. URLhttps: //arxiv.org/abs/2411.13676. arXiv:2411.13676
-
[5]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Yiran Ding, Li Dong, Peiyuan Liu, Kaixiong Zhou, Ermo Hua, Song Lin, Zhuang Li, Yuejie Zhang, Yuhang Cao, Lei Shang, Xin Jiang, and Qun Liu. Longrope: Extending LLM context window beyond 2 million tokens, 2024. URLhttps://arxiv.org/abs/2402.13753. arXiv:2402.13753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Chaojun Xiao, Longyue Wang, Yingjia Wan, Yang Wang, Yuxuan Peng, Hao Zhu, Tianyu Liu, Xingyao Wang, YusenZhang, ChaojieZhang, ZhiyuanLiu, andMaosongSun. InfLLM:Training-freelong-contextextrapolationfor LLMs with an efficient context memory, 2024. URLhttps://arxiv.org/abs/2402.04617. arXiv:2402.04617
-
[7]
Kimi Linear: An Expressive, Efficient Attention Architecture
Yu Zhang, Yifan Chen, Yichen Gong, Zhenyu Yang, Xuanjing Huang, and Kimi Team. Kimi linear: An expressive, efficient attention architecture, 2025. URLhttps://arxiv.org/abs/2510.26692. arXiv:2510.26692
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
AshishVaswani,NoamShazeer,NikiParmar,JakobUszkoreit,LlionJones,AidanN.Gomez,ŁukaszKaiser,andIllia Polosukhin. Attention is all you need, 2017. URLhttps://arxiv.org/abs/1706.03762. arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Generating long sequences with sparse transformers,
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers,
-
[10]
Generating Long Sequences with Sparse Transformers
URLhttps://arxiv.org/abs/1904.10509. arXiv:1904.10509
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[11]
Adaptive attention span in transformers, 2019
Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herve Jegou, and Armand Joulin. Adaptive attention span in transformers, 2019. URLhttps://arxiv.org/abs/1905.07799. arXiv:1905.07799
-
[12]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer, 2020. URL https://arxiv.org/abs/2004.05150. arXiv:2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[13]
Big bird: Transformers for longer sequences, 2020
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences, 2020. URL https://arxiv.org/abs/2007.14062. arXiv:2007.14062
-
[14]
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. Transformer-XL: Attentive language models beyond a fixed-length context, 2019. URLhttps://arxiv.org/abs/1901.02860. arXiv:1901.02860
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[15]
W., Potapenko, A., Jayakumar, S
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compres- sive transformers for long-range sequence modelling, 2019. URL https://arxiv.org/abs/1911.05507. arXiv:1911.05507
-
[16]
Aydar Bulatov, Yuri Kuratov, and Mikhail S. Burtsev. Recurrent memory transformer. InAdvances in Neural Information Processing Systems 35, 2022. doi: 10.52202/068431-0805. URLhttps://doi.org/10.52202/ 068431-0805
-
[17]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun et al. Retentive network: A successor to transformer for large language models, 2023. URL https://arxiv.org/abs/2307.08621. arXiv:2307.08621
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
RWKV: Reinventing RNNs for the transformer era
Bo Peng et al. RWKV: Reinventing RNNs for the transformer era. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023. doi: 10.18653/v1/2023.findings-emnlp.936. URL https://doi.org/10. 18653/v1/2023.findings-emnlp.936. 18
-
[19]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2023. URL https://arxiv.org/abs/2312.00752. arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Rajesh P. N. Rao and Dana H. Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience, 2(1):79–87, 1999. doi: 10.1038/4580. URL https://doi.org/10.1038/4580
-
[21]
Karl Friston. A theory of cortical responses.Philosophical Transactions of the Royal Society B: Biological Sciences, 360(1456):815–836, 2005. doi: 10.1098/rstb.2005.1622. URLhttps://doi.org/10.1098/rstb.2005.1622
-
[22]
Deep Predictive Coding Networks for Video Prediction and Unsupervised Learning
William Lotter, Gabriel Kreiman, and David Cox. Deep predictive coding networks for video prediction and unsupervised learning, 2016. URLhttps://arxiv.org/abs/1605.08104. arXiv:1605.08104
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
Predictive coding approximates backprop along arbitrary computation graphs,
Tim Whittington and Rafal Bogacz. Predictive coding approximates backprop along arbitrary computation graphs,
- [24]
-
[25]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks, 2016. URLhttps://arxiv.org/abs/ 1603.08983. arXiv:1603.08983
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers,
-
[27]
URLhttps://arxiv.org/abs/1807.03819. arXiv:1807.03819
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Depth-adaptive transformer, 2019
Mher Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer, 2019. URLhttps: //arxiv.org/abs/1910.10073. arXiv:1910.10073
-
[29]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017. URLhttps: //arxiv.org/abs/1701.06538. arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2021. URLhttps://arxiv.org/abs/2101.03961. arXiv:2101.03961
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Informa- tion Processing Systems 32 (NeurIPS), 2019. URLhttps://proceedings.neurips.cc/paper/2019/hash/ 1e8a19426224ca89e83cef47f1e7f53b-Abstract.html
work page 2019
-
[32]
mHC: Manifold-Constrained Hyper-Connections
Zhenda Xie, Yixuan Wei, Huanqi Cao, Chenggang Zhao, Chengqi Deng, Jiashi Li, Damai Dai, Huazuo Gao, Jiang Chang, Kuai Yu, Liang Zhao, Shangyan Zhou, Zhean Xu, Zhengyan Zhang, Wangding Zeng, Shengding Hu, Yuqing Wang, Jingyang Yuan, Lean Wang, and Wenfeng Liang. mHC: Manifold-constrained hyper-connections, 2025. URL https://arxiv.org/abs/2512.24880. arXiv:...
work page internal anchor Pith review arXiv 2025
-
[33]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URLhttps: //arxiv.org/abs/2001.08361. arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[34]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Meyer.Matrix Analysis and Applied Linear Algebra
Carl D. Meyer.Matrix Analysis and Applied Linear Algebra. SIAM, 2000. Chapter 5: Norms, Inner Products, and Orthogonality
work page 2000
-
[36]
Ward Cheney and Allen A. Goldstein. Proximity maps for convex sets.Proceedings of the American Mathematical Society, 10(3):448–450, 1959. doi: 10.1090/S0002-9939-1959-0105008-8. URLhttps://doi.org/10.1090/ S0002-9939-1959-0105008-8
-
[37]
Heinz H. Bauschke and Jonathan M. Borwein. On projection algorithms for solving convex feasibility problems. SIAM Review, 38(3):367–426, 1996. doi: 10.1137/S0036144593251710. URLhttps://doi.org/10.1137/ S0036144593251710. 19
-
[38]
The method of alternating orthogonal projections
Frank Deutsch. The method of alternating orthogonal projections. InApproximation Theory, Spline Functions and Applications. Springer, 1992. doi: 10.1007/978-94-011-2634-2_5. URL https://doi.org/10.1007/ 978-94-011-2634-2_5
-
[39]
Bauschke, Hui Ouyang, and Xianfu Wang
Heinz H. Bauschke, Hui Ouyang, and Xianfu Wang. Best approximation mappings in hilbert spaces.Mathematical Programming, 189(1):1–35, 2021. doi: 10.1007/S10107-021-01718-Y. URLhttps://doi.org/10.1007/ S10107-021-01718-Y
-
[40]
Heinz H. Bauschke and Valentin R. Koch. Projection methods: Swiss army knives for solving feasibility and best approximation problems with halfspaces. InApproximation, Optimization, and Mathematical Economics. American Mathematical Society, 2015. doi: 10.1090/CONM/636/12726. URLhttps://doi.org/10.1090/CONM/636/ 12726. 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.