Recognition: no theorem link
HOIGS: Human-Object Interaction Gaussian Splatting
Pith reviewed 2026-05-13 17:20 UTC · model grok-4.3
The pith
HOIGS reconstructs interactive human-object scenes by fusing distinct deformation models with cross-attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating heterogeneous features from HexPlane for humans and Cubic Hermite Spline for objects via a cross-attention-based HOI module, HOIGS effectively captures interdependent motions and improves deformation estimation in scenarios involving occlusion, contact, and object manipulation. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art human-centric and 4D Gaussian approaches, highlighting the importance of explicitly modeling human-object interactions for high-fidelity reconstruction.
What carries the argument
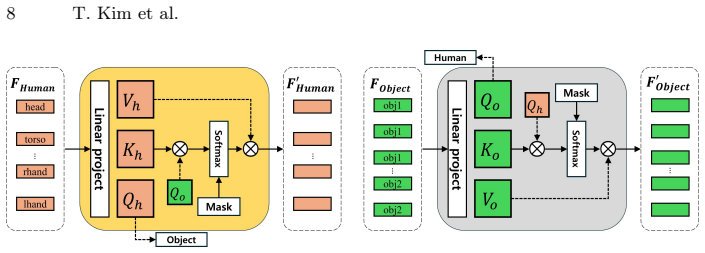
Cross-attention-based HOI module integrating HexPlane human features and Cubic Hermite Spline object features to model interaction-induced deformations.
If this is right
- Explicitly modeling human-object interactions leads to better deformation estimation under occlusion and contact.
- The method outperforms existing human-centric and 4D Gaussian Splatting approaches on multiple datasets.
- Interdependent motions between humans and objects are captured more accurately through feature fusion.
- High-fidelity reconstruction of manipulation scenarios is achieved by using heterogeneous deformation baselines.
Where Pith is reading between the lines
- This fusion strategy might be applicable to other multi-entity dynamic scenes, such as multiple humans or animal-object interactions.
- If the module generalizes well, it could enable more robust real-world applications in robotics for predicting interaction outcomes.
- Extending the approach with physics constraints could further improve accuracy in contact-rich scenarios.
Load-bearing premise
The cross-attention HOI module reliably extracts and fuses interaction-induced deformations from HexPlane and Cubic Hermite Spline baselines without new artifacts or needing scene-specific tuning.
What would settle it
A direct comparison showing that on datasets with significant occlusions and contacts, the HOIGS method produces more artifacts or lower quality reconstructions than a unified motion field approach would falsify the central claim.
Figures







read the original abstract
Reconstructing dynamic scenes with complex human-object interactions is a fundamental challenge in computer vision and graphics. Existing Gaussian Splatting methods either rely on human pose priors while neglecting dynamic objects, or approximate all motions within a single field, limiting their ability to capture interaction-rich dynamics. To address this gap, we propose Human-Object Interaction Gaussian Splatting (HOIGS), which explicitly models interaction-induced deformation between humans and objects through a cross-attention-based HOI module. Distinct deformation baselines are employed to extract features: HexPlane for humans and Cubic Hermite Spline (CHS) for objects. By integrating these heterogeneous features, HOIGS effectively captures interdependent motions and improves deformation estimation in scenarios involving occlusion, contact, and object manipulation. Comprehensive experiments on multiple datasets demonstrate that our method consistently outperforms state-of-the-art human-centric and 4D Gaussian approaches, highlighting the importance of explicitly modeling human-object interactions for high-fidelity reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HOIGS, a Gaussian Splatting method for dynamic human-object interaction scenes. It employs separate deformation baselines—HexPlane for humans and Cubic Hermite Splines for objects—fused via a cross-attention HOI module to capture interdependent motions, claiming consistent outperformance over human-centric and 4D Gaussian baselines on multiple datasets, particularly in occlusion, contact, and manipulation scenarios.
Significance. If the central claim holds, the work advances dynamic scene reconstruction by explicitly separating and fusing heterogeneous deformation representations rather than relying on a single field or human-pose priors alone. This addresses a clear gap in handling interaction-induced deformations and could improve fidelity for downstream applications in graphics and robotics.
major comments (2)
- [§3.2] §3.2 (HOI module): The cross-attention fusion of HexPlane (volumetric 4D planes) and Cubic Hermite Spline (parametric curve) features assumes raw feature vectors are already commensurable in space and time without any explicit alignment, contact regularization, or projection step. This is load-bearing for the claim that improvements arise from interaction modeling rather than added capacity; no derivation or constraint guarantees consistency at contact points or under occlusion.
- [§4] §4 (Experiments): The reported gains on multiple datasets are presented without ablation isolating the HOI module's contribution versus the baseline HexPlane+CHS capacity increase, and without details on dataset splits or implementation specifics. This undermines the ability to attribute outperformance specifically to interdependent motion capture.
minor comments (2)
- Notation for the fused feature vectors in the HOI module is introduced without a clear diagram or equation reference showing the exact attention formulation and output dimensionality.
- Figure 3 (qualitative results) would benefit from side-by-side error maps highlighting deformation inconsistencies at contact regions to visually support the central claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major point below with clarifications on our design and planned revisions to strengthen the presentation of the HOI module and experimental validation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (HOI module): The cross-attention fusion of HexPlane (volumetric 4D planes) and Cubic Hermite Spline (parametric curve) features assumes raw feature vectors are already commensurable in space and time without any explicit alignment, contact regularization, or projection step. This is load-bearing for the claim that improvements arise from interaction modeling rather than added capacity; no derivation or constraint guarantees consistency at contact points or under occlusion.
Authors: The cross-attention mechanism in the HOI module is designed to learn dynamic correspondences and weighting between the heterogeneous HexPlane and CHS features during optimization, rather than assuming pre-aligned inputs. The attention operates on the extracted feature vectors to capture interaction-induced deformations in a data-driven manner, with consistency at contact points and under occlusion enforced implicitly through the photometric and geometric reconstruction losses on real interaction sequences. We acknowledge the absence of an explicit theoretical derivation or contact regularization term guaranteeing these properties; the improvements are supported empirically. To better isolate the contribution beyond added capacity, we will add an ablation removing the cross-attention fusion in the revision. revision: partial
-
Referee: [§4] §4 (Experiments): The reported gains on multiple datasets are presented without ablation isolating the HOI module's contribution versus the baseline HexPlane+CHS capacity increase, and without details on dataset splits or implementation specifics. This undermines the ability to attribute outperformance specifically to interdependent motion capture.
Authors: We agree that an explicit ablation isolating the HOI module is essential to attribute gains to interaction modeling. In the revised version we will include a new ablation comparing the full model against a variant that uses separate HexPlane and CHS baselines without the cross-attention fusion. We will also expand the supplementary material with precise dataset splits (train/test sequence IDs), training hyperparameters, and implementation details to enable full reproducibility. revision: yes
Circularity Check
No circularity in derivation; new architectural components introduced without self-referential fits or load-bearing self-citations
full rationale
The paper presents HOIGS as a novel integration of HexPlane for human deformation and Cubic Hermite Splines for objects, fused via a cross-attention HOI module. No equations are shown that reduce by construction to fitted inputs or prior self-citations; the central claim rests on the new module's ability to handle heterogeneous features rather than renaming or re-deriving existing results. The derivation chain is self-contained with independent architectural choices, consistent with the reader's assessment of score 2.0 but qualifying as 0 under strict rules requiring explicit reduction quotes.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Alldieck, T., Zanfir, M., Sminchisescu, C.: Photorealistic monocular 3d reconstruc- tion of humans wearing clothing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1506–1515 (2022)
work page 2022
-
[2]
In: European Conference on Computer Vision
Bae, J., Kim, S., Yun, Y., Lee, H., Bang, G., Uh, Y.: Per-gaussian embedding- based deformation for deformable 3d gaussian splatting. In: European Conference on Computer Vision. pp. 321–335. Springer (2024)
work page 2024
-
[3]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Bhatnagar, B.L., Xie, X., Petrov, I.A., Sminchisescu, C., Theobalt, C., Pons-Moll, G.: Behave: Dataset and method for tracking human object interactions. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 15935–15946 (2022)
work page 2022
-
[4]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Cao, A., Johnson, J.: Hexplane: A fast representation for dynamic scenes. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 130–141 (2023)
work page 2023
-
[5]
Chen, S., Guo, H., Zhu, S., Zhang, F., Huang, Z., Feng, J., Kang, B.: Video depth anything: Consistent depth estimation for super-long videos. arXiv:2501.12375 (2025)
-
[6]
Chu, W.H., Ke, L., Fragkiadaki, K.: Dreamscene4d: Dynamic multi-object scene generation from monocular videos. NeurIPS (2024)
work page 2024
-
[7]
In: International Conference on 3D Vision 2025 (2025),https://openreview.net/ forum?id=5uw1GRBFoT
Duisterhof, B.P., Zust, L., Weinzaepfel, P., Leroy, V., Cabon, Y., Revaud, J.: MASt3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In: International Conference on 3D Vision 2025 (2025),https://openreview.net/ forum?id=5uw1GRBFoT
work page 2025
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fan, Z., Parelli, M., Kadoglou, M.E., Chen, X., Kocabas, M., Black, M.J., Hilliges, O.: Hold: Category-agnostic 3d reconstruction of interacting hands and objects from video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 494–504 (2024)
work page 2024
-
[9]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: Arctic: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12943–12954 (2023)
work page 2023
-
[10]
Fridovich-Keil, S., Meanti, G., Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: Proceedings of the 22 T. Kim et al. IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12479– 12488 (2023)
work page 2023
-
[11]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Guo, C., Jiang, T., Chen, X., Song, J., Hilliges, O.: Vid2avatar: 3d avatar re- construction from videos in the wild via self-supervised scene decomposition. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 12858–12868 (2023)
work page 2023
-
[12]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, L., Zhang, H., Zhang, Y., Zhou, B., Liu, B., Zhang, S., Nie, L.: Gaussianavatar: Towards realistic human avatar modeling from a single video via animatable 3d gaussians. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 634–644 (2024)
work page 2024
-
[13]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Hu, M., Yin, W., Zhang, C., Cai, Z., Long, X., Chen, H., Wang, K., Yu, G., Shen, C., Shen, S.: Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
work page 2024
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, S., Hu, T., Liu, Z.: Gauhuman: Articulated gaussian splatting from monocular human videos. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20418–20431 (2024)
work page 2024
-
[15]
Hu, W., Gao, X., Li, X., Zhao, S., Cun, X., Zhang, Y., Quan, L., Shan, Y.: Depthcrafter: Generating consistent long depth sequences for open-world videos. In: CVPR (2025)
work page 2025
-
[16]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., Xu, Y., Lassner, C., Li, H., Tung, T.: Arch: Animatable reconstruction of clothed humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3093–3102 (2020)
work page 2020
-
[17]
In: European Conference on Computer Vision
Jiang, W., Yi, K.M., Samei, G., Tuzel, O., Ranjan, A.: Neuman: Neural human radiance field from a single video. In: European Conference on Computer Vision. pp. 402–418. Springer (2022)
work page 2022
-
[18]
arXiv preprint arXiv:2312.15059 (2023)
Jung, H., Brasch, N., Song, J., Perez-Pellitero, E., Zhou, Y., Li, Z., Navab, N., Busam, B.: Deformable 3d gaussian splatting for animatable human avatars. arXiv preprint arXiv:2312.15059 (2023)
-
[19]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7122–7131 (2018)
work page 2018
- [20]
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Kim, S., Do, S., Park, J.: Showmak3r: Compositional tv show reconstruction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 864– 874 (2025)
work page 2025
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kocabas, M., Chang, J.H.R., Gabriel, J., Tuzel, O., Ranjan, A.: Hugs: Human gaussian splats. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 505–515 (2024)
work page 2024
-
[23]
Advances in Neural Information Processing Systems37, 5384–5409 (2024)
Lee, J., Won, C., Jung, H., Bae, I., Jeon, H.G.: Fully explicit dynamic gaus- sian splatting. Advances in Neural Information Processing Systems37, 5384–5409 (2024)
work page 2024
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Chen, Z., Li, Z., Xu, Y.: Spacetime gaussian feature splatting for real- time dynamic view synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8508–8520 (2024)
work page 2024
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liao, T., Zhang, X., Xiu, Y., Yi, H., Liu, X., Qi, G.J., Zhang, Y., Wang, X., Zhu, X., Lei, Z.: High-fidelity clothed avatar reconstruction from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8662–8672 (2023) HOIGS: Human-Object Interaction Gaussian Splatting 23
work page 2023
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, J.W., Cao, Y.P., Yang, T., Xu, Z., Keppo, J., Shan, Y., Qie, X., Shou, M.Z.: Hosnerf: Dynamic human-object-scene neural radiance fields from a single video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18483–18494 (2023)
work page 2023
-
[27]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Liu, Y., Huang, X., Qin, M., Lin, Q., Wang, H.: Animatable 3d gaussian: Fast and high-quality reconstruction of multiple human avatars. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 1120–1129 (2024)
work page 2024
-
[28]
In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: A skinned multi-person linear model. In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp. 851–866 (2023)
work page 2023
-
[29]
https://github.com/facebookresearch/maskrcnn-benchmark(2018)
Massa, F., Girshick, R.: maskrcnn-benchmark: Fast, modular reference implemen- tation of Instance Segmentation and Object Detection algorithms in PyTorch. https://github.com/facebookresearch/maskrcnn-benchmark(2018)
work page 2018
-
[30]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
work page 2021
-
[31]
In: European Conference on Computer Vision
Moon, G., Shiratori, T., Saito, S.: Expressive whole-body 3d gaussian avatar. In: European Conference on Computer Vision. pp. 19–35. Springer (2024)
work page 2024
-
[32]
In: Proceedings of the IEEE/CVF international conference on computer vision
Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin- Brualla, R.: Nerfies: Deformable neural radiance fields. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5865–5874 (2021)
work page 2021
-
[33]
arXiv preprint arXiv:2106.13228 (2021)
Park,K.,Sinha,U.,Hedman,P.,Barron,J.T.,Bouaziz,S.,Goldman,D.B.,Martin- Brualla, R., Seitz, S.M.: Hypernerf: A higher-dimensional representation for topo- logically varying neural radiance fields. arXiv preprint arXiv:2106.13228 (2021)
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single im- age. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019)
work page 2019
-
[35]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9054–9063 (2021)
work page 2021
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Qian, Z., Wang, S., Mihajlovic, M., Geiger, A., Tang, S.: 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5020–5030 (2024)
work page 2024
-
[37]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V., Carion, N., Wu, C.Y., Girshick, R., Dollár, P., Feichtenhofer, C.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024),https://arxiv.org/ abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
In: Proceedings of the IEEE/CVF international conference on computer vision
Saito, S., Huang, Z., Natsume, R., Morishima, S., Kanazawa, A., Li, H.: Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2304–2314 (2019)
work page 2019
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Saito, S., Simon, T., Saragih, J., Joo, H.: Pifuhd: Multi-level pixel-aligned im- plicit function for high-resolution 3d human digitization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 84–93 (2020)
work page 2020
-
[40]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016) 24 T. Kim et al
work page 2016
-
[41]
Tang, J., Ren, J., Zhou, H., Liu, Z., Zeng, G.: Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv preprint arXiv:2309.16653 (2023)
-
[42]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, J., Zhao, X., Ren, Z., Schwing, A.G., Wang, S.: Gomavatar: Efficient animat- able human modeling from monocular video using gaussians-on-mesh. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2059–2069 (2024)
work page 2059
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern Recognition
Weng, C.Y., Curless, B., Srinivasan, P.P., Barron, J.T., Kemelmacher-Shlizerman, I.: Humannerf: Free-viewpoint rendering of moving people from monocular video. In: Proceedings of the IEEE/CVF conference on computer vision and pattern Recognition. pp. 16210–16220 (2022)
work page 2022
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Wang, X.: 4d gaussian splatting for real-time dynamic scene rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20310– 20320 (2024)
work page 2024
-
[45]
Advances in neural information processing systems35, 32653–32666 (2022)
Wu, T., Zhong, F., Tagliasacchi, A., Cole, F., Oztireli, C.: Dˆ 2nerf: Self-supervised decoupling of dynamic and static objects from a monocular video. Advances in neural information processing systems35, 32653–32666 (2022)
work page 2022
-
[46]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiu, Y., Yang, J., Cao, X., Tzionas, D., Black, M.J.: Econ: Explicit clothed humans optimized via normal integration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 512–523 (2023)
work page 2023
-
[47]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiu, Y., Yang, J., Tzionas, D., Black, M.J.: Icon: Implicit clothed humans obtained from normals. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13286–13296. IEEE (2022)
work page 2022
- [48]
-
[49]
Yang, J., Gao, M., Li, Z., Gao, S., Wang, F., Zheng, F.: Track anything: Segment anything meets videos (2023)
work page 2023
-
[50]
Yang, Z., Yang, H., Pan, Z., Zhang, L.: Real-time photorealistic dynamic scene representation and rendering with 4d gaussian splatting. arXiv preprint arXiv:2310.10642 (2023)
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Gao, X., Zhou, W., Jiao, S., Zhang, Y., Jin, X.: Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20331– 20341 (2024)
work page 2024
-
[52]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.