Recognition: 1 theorem link
· Lean TheoremLearning Dexterous Grasping from Sparse Taxonomy Guidance
Pith reviewed 2026-05-13 17:01 UTC · model grok-4.3
The pith
GRIT learns dexterous grasping from sparse taxonomy guidance instead of dense pose targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
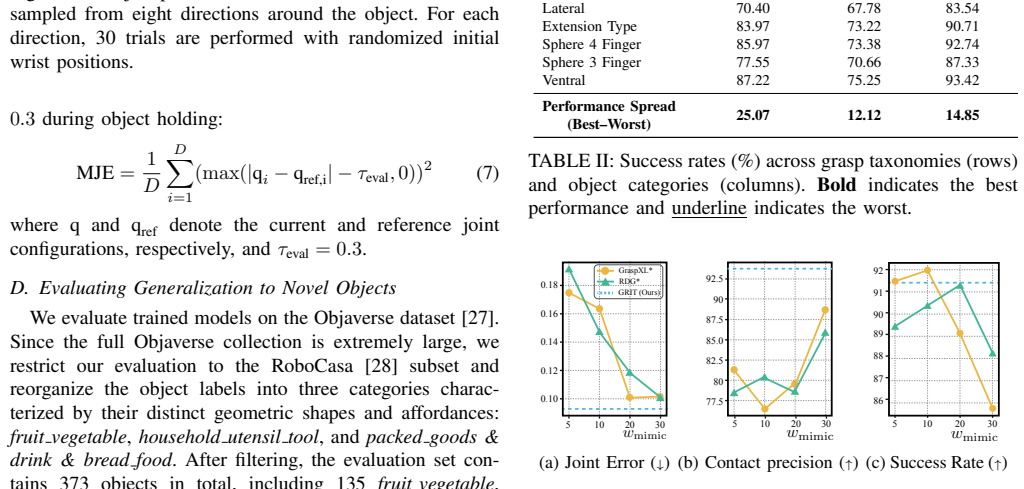
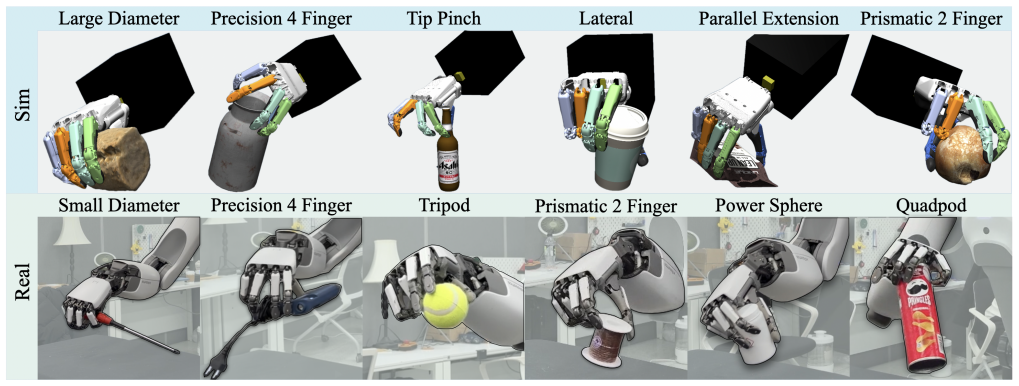
GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9 percent.
What carries the argument
The GRIT two-stage framework, in which a taxonomy predictor supplies a sparse grasp label that conditions a downstream policy to output coordinated finger trajectories.
If this is right
- Certain grasp taxonomies suit specific object geometries better than others.
- GRIT improves generalization to novel objects over baselines.
- The method reaches an overall success rate of 87.9 percent.
- Real-world experiments demonstrate that users can adjust grasp strategies by selecting different taxonomies based on object geometry and task intent.
Where Pith is reading between the lines
- The framework could reduce the human effort needed to specify dexterous tasks by letting users provide only intuitive taxonomy labels.
- Taxonomy-conditioned policies might transfer to related skills such as in-hand reorientation if the same sparse labels prove sufficient there.
- Combining the predictor with real-time vision could enable fully automatic taxonomy selection in unstructured scenes without manual intervention.
Load-bearing premise
Sparse taxonomy labels alone supply enough information to produce stable, task-appropriate continuous finger motions across varied objects without any dense pose or contact targets.
What would settle it
A controlled simulation test in which policies trained on taxonomy guidance alone drop below 60 percent success on a held-out set of geometrically diverse objects would show the guidance is insufficient.
Figures



read the original abstract
Dexterous manipulation requires planning a grasp configuration suited to the object and task, which is then executed through coordinated multi-finger control. However, specifying grasp plans with dense pose or contact targets for every object and task is impractical. Meanwhile, end-to-end reinforcement learning from task rewards alone lacks controllability, making it difficult for users to intervene when failures occur. To this end, we present GRIT, a two-stage framework that learns dexterous control from sparse taxonomy guidance. GRIT first predicts a taxonomy-based grasp specification from the scene and task context. Conditioned on this sparse command, a policy generates continuous finger motions that accomplish the task while preserving the intended grasp structure. Our result shows that certain grasp taxonomies are more effective for specific object geometries. By leveraging this relationship, GRIT improves generalization to novel objects over baselines and achieves an overall success rate of 87.9%. Moreover, real-world experiments demonstrate controllability, enabling grasp strategies to be adjusted through high-level taxonomy selection based on object geometry and task intent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents GRIT, a two-stage framework for dexterous grasping. A taxonomy predictor first outputs a discrete grasp class from scene and task context; this sparse specification then conditions a policy that produces continuous finger motions to complete the task while respecting the intended grasp structure. The central empirical claims are an overall success rate of 87.9%, improved generalization to novel objects relative to baselines, and real-world demonstrations that high-level taxonomy selection enables controllable grasp adjustments based on object geometry and task intent.
Significance. If the reported results hold under rigorous evaluation, GRIT would offer a practical compromise between dense pose/contact planning (which is impractical to specify) and end-to-end RL (which lacks controllability). The explicit use of taxonomy guidance to link object geometry to grasp choice, together with the two-stage separation, could improve both sample efficiency and user intervention in dexterous manipulation. The real-world transfer and generalization numbers would constitute a meaningful incremental advance for the field.
major comments (2)
- Abstract and Results section: the headline claim of 87.9% success and generalization gains is stated without any reference to experimental protocol, baselines, object sets, number of trials, data splits, or error bars. Because these numbers are the primary support for the central claim that sparse taxonomy guidance suffices for effective continuous control, the absence of this information is load-bearing and must be supplied with full tables and statistical details.
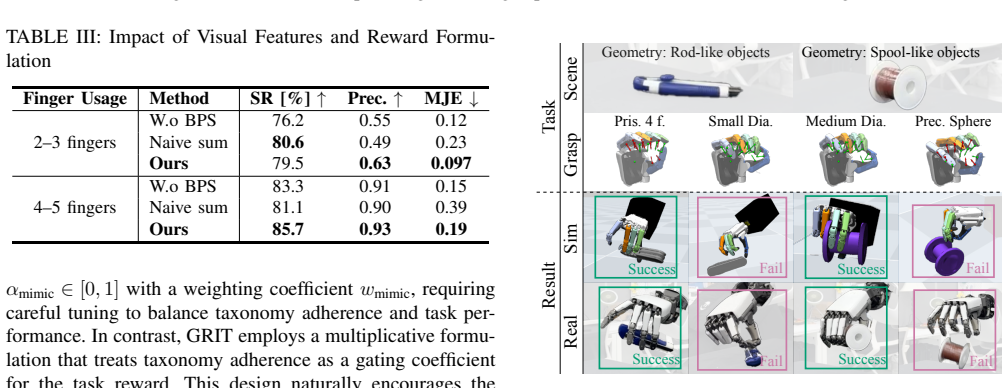
- Method section (two-stage architecture): the paper asserts that conditioning the policy on the discrete taxonomy class is sufficient to produce stable finger trajectories across diverse objects, yet provides no analysis or ablation of cases where the discrete class under-constrains the continuous policy (e.g., for tasks requiring precise contact sequencing). This assumption is exactly the weakest link identified in the reader's report and requires explicit discussion or counter-examples.
minor comments (2)
- Introduction: the phrase 'certain grasp taxonomies are more effective for specific object geometries' is asserted without naming the taxonomies or geometries; a short table or figure reference would clarify the claimed relationship.
- Notation: the distinction between the taxonomy predictor output and the policy input should be made explicit with consistent symbols or a diagram, as the current description leaves the conditioning interface somewhat ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract and Results section: the headline claim of 87.9% success and generalization gains is stated without any reference to experimental protocol, baselines, object sets, number of trials, data splits, or error bars. Because these numbers are the primary support for the central claim that sparse taxonomy guidance suffices for effective continuous control, the absence of this information is load-bearing and must be supplied with full tables and statistical details.
Authors: We agree that the abstract and results section would benefit from explicit experimental context. In the revised manuscript we will add references to the full protocol, including number of trials, data splits, object sets, baselines, and error bars, together with expanded tables reporting all statistical details supporting the 87.9% success rate and generalization claims. revision: yes
-
Referee: Method section (two-stage architecture): the paper asserts that conditioning the policy on the discrete taxonomy class is sufficient to produce stable finger trajectories across diverse objects, yet provides no analysis or ablation of cases where the discrete class under-constrains the continuous policy (e.g., for tasks requiring precise contact sequencing). This assumption is exactly the weakest link identified in the reader's report and requires explicit discussion or counter-examples.
Authors: We acknowledge that the current manuscript lacks an explicit ablation or counter-examples for scenarios in which the discrete taxonomy class may under-constrain the policy, such as tasks with precise contact sequencing. Our reported results demonstrate stable trajectories and high success rates, but we will add a dedicated discussion subsection addressing this limitation, including analysis of relevant failure modes and empirical examples where the taxonomy conditioning proves sufficient. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper presents a two-stage empirical framework (taxonomy predictor followed by conditioned policy) whose headline claims (87.9% success, improved generalization) rest on training outcomes and real-world tests rather than any closed-form derivation. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The architecture is a standard conditional RL setup whose validity is tested externally by experiment, not by construction from its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multiplicative composite reward: r = r_h · α_h + r_o · α_o − r_pen ... α_mimic = exp(−γ_m L_mimic) ... L_mimic = 1/N_act Σ (max(|q_i − q_ref,i| − τ_act,0))^2 + ...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dexterous manipulation through imitation learning: A survey,
S. An, Z. Meng, C. Tang, Y . Zhou, T. Liu, F. Ding, S. Zhang, Y . Mu, R. Song, W. Zhanget al., “Dexterous manipulation through imitation learning: A survey,”arXiv preprint arXiv:2504.03515, 2025
-
[2]
Graspxl: Generating grasping motions for diverse objects at scale,
H. Zhang, S. Christen, Z. Fan, O. Hilliges, and J. Song, “Graspxl: Generating grasping motions for diverse objects at scale,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 386–403
work page 2024
-
[3]
Dexonomy: Synthesiz- ing all dexterous grasp types in a grasp taxonomy,
J. Chen, Y . Ke, L. Peng, and H. Wang, “Dexonomy: Synthesiz- ing all dexterous grasp types in a grasp taxonomy,”arXiv preprint arXiv:2504.18829, 2025
-
[4]
The grasp taxonomy of human grasp types,
T. Feix, J. Romero, H.-B. Schmiedmayer, A. M. Dollar, and D. Kragic, “The grasp taxonomy of human grasp types,”IEEE Transactions on human-machine systems, vol. 46, no. 1, pp. 66–77, 2015
work page 2015
-
[5]
An overview of learning-based dexterous grasping: recent advances and future directions,
X. Song, Y . Li, Y . Zhang, Y . Liu, and L. Jiang, “An overview of learning-based dexterous grasping: recent advances and future directions,”Artificial Intelligence Review, vol. 58, no. 10, p. 300, 2025
work page 2025
-
[6]
Template-based learning of grasp selection,
A. Herzog, P. Pastor, M. Kalakrishnan, L. Righetti, T. Asfour, and S. Schaal, “Template-based learning of grasp selection,” in2012 IEEE international conference on robotics and automation. IEEE, 2012, pp. 2379–2384
work page 2012
-
[7]
Dextransfer: Real world multi-fingered dex- terous grasping with minimal human demonstrations,
Z. Q. Chen, K. Van Wyk, Y .-W. Chao, W. Yang, A. Mousavian, A. Gupta, and D. Fox, “Dextransfer: Real world multi-fingered dex- terous grasping with minimal human demonstrations,”arXiv preprint arXiv:2209.14284, 2022
-
[8]
D-grasp: Physically plausible dynamic grasp synthesis for hand-object interactions,
S. Christen, M. Kocabas, E. Aksan, J. Hwangbo, J. Song, and O. Hilliges, “D-grasp: Physically plausible dynamic grasp synthesis for hand-object interactions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 20 577–20 586
work page 2022
-
[9]
Dora: Object affordance-guided reinforcement learning for dexterous robotic manipulation,
L. Zhang, S. Mondal, Z. Bing, K. Bai, D. Zheng, Z. Chen, A. C. Knoll, and J. Zhang, “Dora: Object affordance-guided reinforcement learning for dexterous robotic manipulation,” in2025 IEEE International Conference on Cyborg and Bionic Systems (CBS). IEEE, 2025, pp. 674–681
work page 2025
-
[10]
arXiv preprint arXiv:1910.07113 , year=
I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribaset al., “Solving rubik’s cube with a robot hand,”arXiv preprint arXiv:1910.07113, 2019
-
[11]
Towards human-level bimanual dexterous manipulation with reinforcement learning,
Y . Chen, T. Wu, S. Wang, X. Feng, J. Jiang, Z. Lu, S. McAleer, H. Dong, S.-C. Zhu, and Y . Yang, “Towards human-level bimanual dexterous manipulation with reinforcement learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 5150–5163, 2022
work page 2022
-
[12]
A system for general in-hand object re-orientation,
T. Chen, J. Xu, and P. Agrawal, “A system for general in-hand object re-orientation,” inConference on Robot Learning. PMLR, 2022, pp. 297–307
work page 2022
-
[13]
Robustdex- grasp: Robust dexterous grasping of general objects,
H. Zhang, Z. Wu, L. Huang, S. Christen, and J. Song, “Robustdex- grasp: Robust dexterous grasping of general objects,”arXiv preprint arXiv:2504.05287, 2025
-
[14]
Dexpilot: Vision-based tele- operation of dexterous robotic hand-arm system,
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox, “Dexpilot: Vision-based tele- operation of dexterous robotic hand-arm system,” in2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 9164–9170
work page 2020
-
[15]
Doglove: Dexterous manip- ulation with a low-cost open-source haptic force feedback glove,
H. Zhang, S. Hu, Z. Yuan, and H. Xu, “Doglove: Dexterous manip- ulation with a low-cost open-source haptic force feedback glove,” in Robotics: Science and Systems (RSS), 2025
work page 2025
-
[16]
Fungrasp: functional grasping for diverse dexterous hands,
L. Huang, H. Zhang, Z. Wu, S. Christen, and J. Song, “Fungrasp: functional grasping for diverse dexterous hands,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[17]
Google DeepMind, “Gemini 3 pro model card,” Google DeepMind, Tech. Rep., 2025. [Online]. Available: https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
work page 2025
-
[18]
Stabilization of constraints and integrals of motion in dynamical systems,
J. Baumgarte, “Stabilization of constraints and integrals of motion in dynamical systems,”Computer methods in applied mechanics and engineering, vol. 1, no. 1, pp. 1–16, 1972
work page 1972
-
[19]
S. Chiaverini, B. Siciliano, and O. Egeland, “Review of the damped least-squares inverse kinematics with experiments on an industrial robot manipulator,”IEEE Transactions on control systems technology, vol. 2, no. 2, pp. 123–134, 1994
work page 1994
-
[20]
3daxisprompt: Promoting the 3d grounding and reasoning in gpt-4o,
D. Liu, C. Wang, P. Gao, R. Zhang, X. Ma, Y . Meng, and Z. Wang, “3daxisprompt: Promoting the 3d grounding and reasoning in gpt-4o,” Neurocomputing, vol. 637, p. 130072, 2025
work page 2025
-
[21]
Efficient learning on point clouds with basis point sets,
S. Prokudin, C. Lassner, and J. Romero, “Efficient learning on point clouds with basis point sets,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4332–4341
work page 2019
-
[22]
arXiv preprint arXiv:2504.17838 (2025)
B. Jaeger, D. Dauner, J. Beißwenger, S. Gerstenecker, K. Chitta, and A. Geiger, “Carl: Learning scalable planning policies with simple rewards,”arXiv preprint arXiv:2504.17838, 2025
-
[23]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635
work page 2011
-
[24]
The ycb object and model set: Towards common benchmarks for manipulation research,
B. Calli, A. Singh, A. Walsman, S. Srinivasa, P. Abbeel, and A. M. Dollar, “The ycb object and model set: Towards common benchmarks for manipulation research,” in2015 international conference on ad- vanced robotics (ICAR). IEEE, 2015, pp. 510–517
work page 2015
-
[25]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y . Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrset al., “Mujoco playground,”arXiv preprint arXiv:2502.08844, 2025
-
[27]
Objaverse: A universe of annotated 3d objects,
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. Vander- Bilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi, “Objaverse: A universe of annotated 3d objects,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 13 142–13 153
work page 2023
-
[28]
Robocasa: Large-scale simulation of everyday tasks for generalist robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of everyday tasks for generalist robots,” inRobotics: Science and Systems (RSS), 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.