Recognition: unknown
Math Education Digital Shadows for facilitating learning with LLMs: Math performance, anxiety and confidence in simulated students and AIs
Pith reviewed 2026-05-07 05:18 UTC · model grok-4.3
The pith
Large language models can simulate math students and AI assistants through 28,000 detailed personas that track performance, anxiety, confidence, and attitudes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
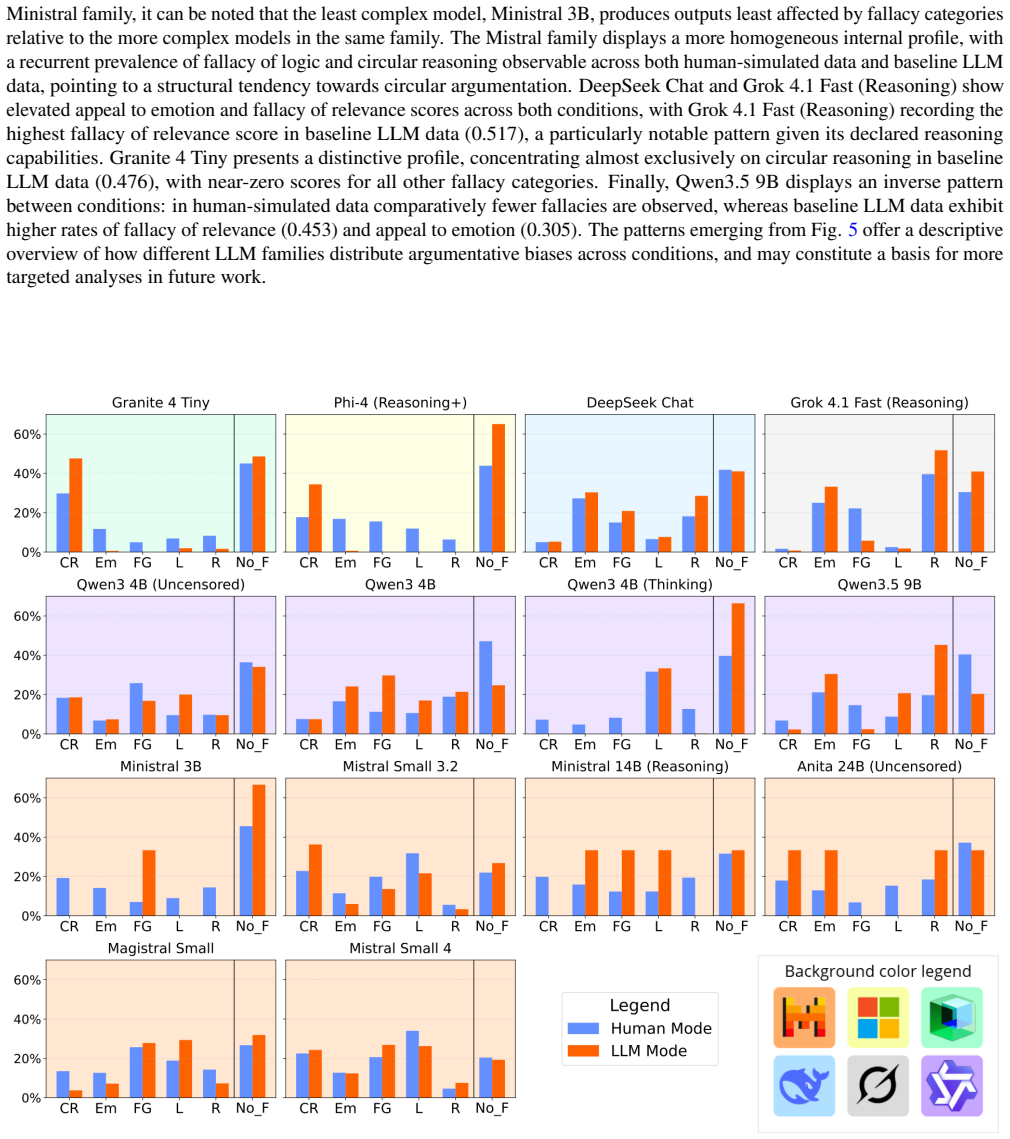
MEDS maps how large language models reason about and report mathematics across human- and AI-like conditions by creating 28,000 personas from 14 LLMs, each completing open interviews, psychometric tests, cognitive networks, and high-school math questions with reasoning and confidence scores. The dataset demonstrates schema integrity, consistent personas, and peculiarities like negative math attitudes, logical fallacies, and math overconfidence in the sampled models.
What carries the argument
Math Education Digital Shadows (MEDS), a dataset that pairs math proficiency scores with self-efficacy reports, anxiety measures, and cognitive networks of math attitudes for each simulated persona.
If this is right
- Developers of AI tutors can use the dataset to identify and mitigate model-specific biases such as overconfidence or negative math attitudes before deployment.
- Learning analytics experts gain a scalable way to probe how different LLM families represent self-efficacy and math perceptions.
- Cognitive scientists obtain a new source of data for studying the structure of math attitudes through network representations generated by artificial systems.
- Safer AI systems for mathematics education can be designed by testing prompts that reduce logical fallacies or excessive confidence observed in the shadows.
Where Pith is reading between the lines
- If the simulated shadows prove reliable, early-stage testing of new AI tutors could shift from large human trials to targeted checks against MEDS patterns.
- The family-specific peculiarities suggest that training data differences leave detectable traces in educational reasoning that could be addressed through targeted fine-tuning.
- Extending the approach to track how confidence changes mid-problem or across multiple sessions might expose dynamic aspects of LLM problem-solving not captured in static snapshots.
Load-bearing premise
That LLM-generated personas under human-like and AI-like prompts produce behaviors and attitudes that meaningfully reflect or usefully approximate real human students or actual AI assistant performance in math education settings.
What would settle it
A side-by-side study in which real high-school students and practicing AI tutors complete the identical set of interviews, psychometric scales, network tasks, and math problems, then checking whether the distributions of scores, anxiety levels, and attitude networks align with those produced by the MEDS personas.
Figures



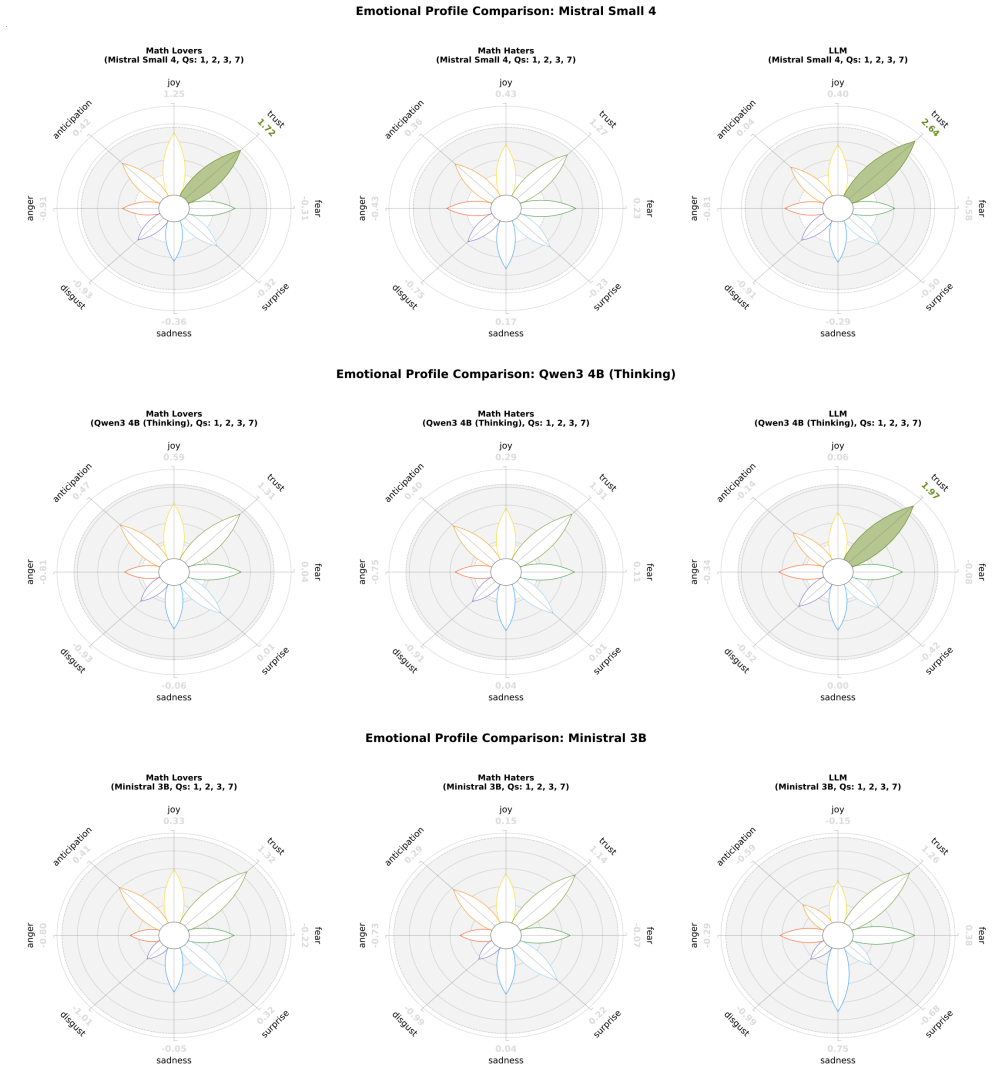




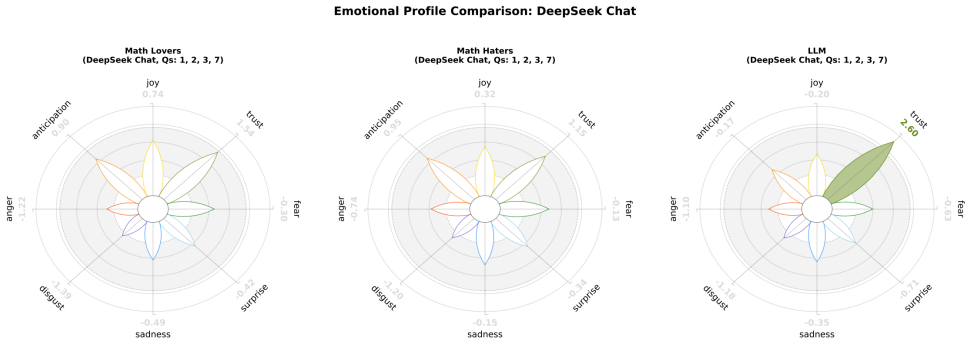

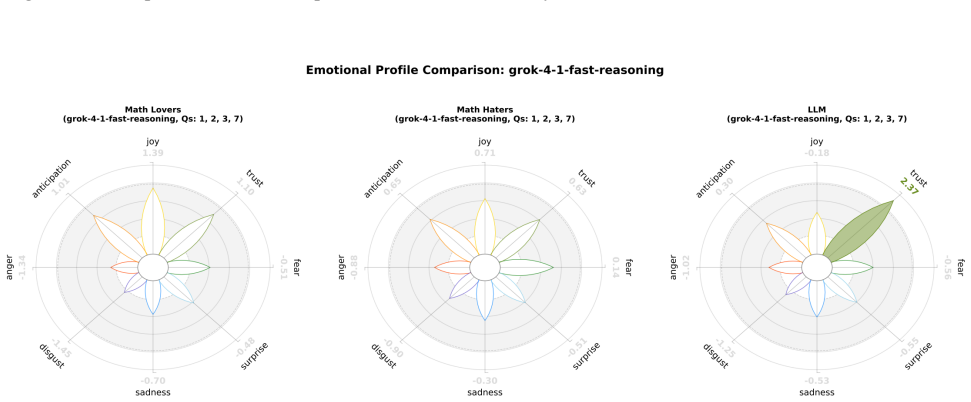



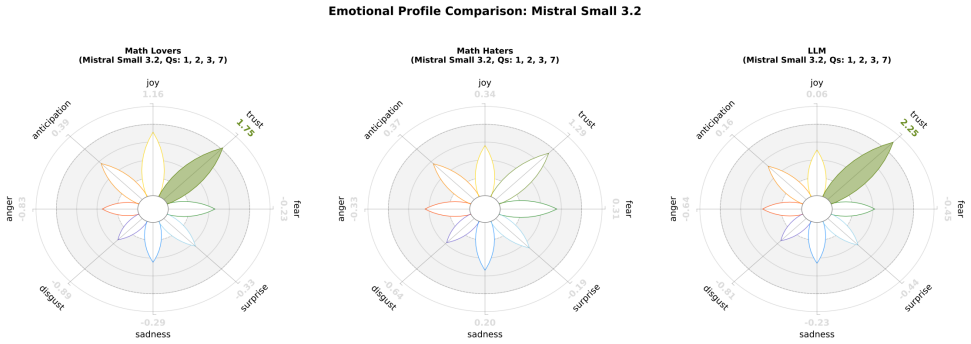
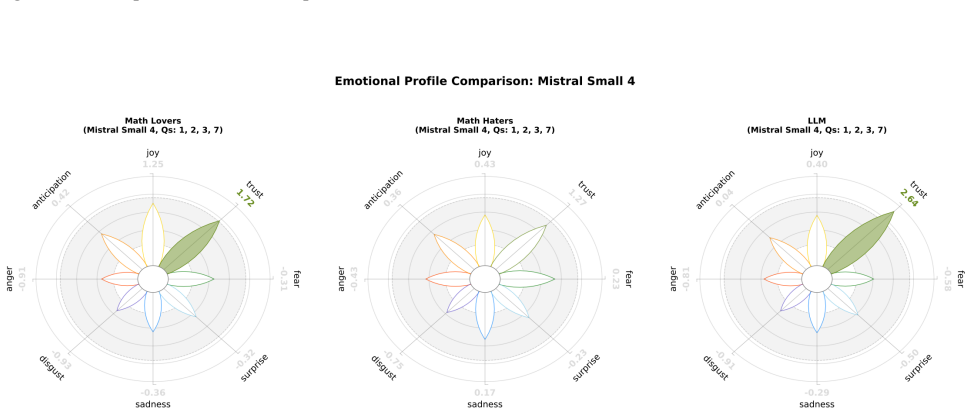

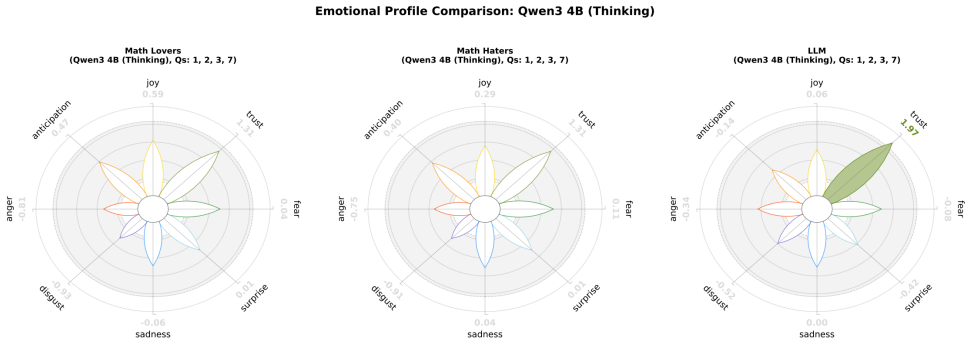
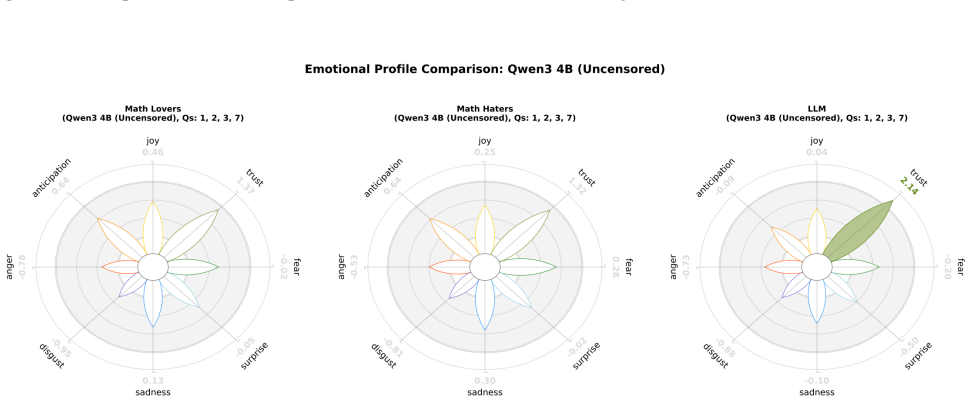


read the original abstract
To enhance LLMs' impact on math education, we need data on their mathematical prowess and biases across prompts. To fill this gap, we introduce MEDS (Math Education Digital Shadows) as a dataset mapping how large language models reason about and report mathematics across human- and AI-like conditions. MEDS involves 28,000 personas from 14 LLMs (from families like Mistral, Qwen, DeepSeek, Granite, Phi and Grok) shadowing either humans or AI assistants. Each record/shadow includes a set of prompts along with psychological/sociodemographic persona metadata and four types of math tasks: (i) open math interview, (ii) three psychometric tests about math perceptions with explanations, (iii) cognitive networks capturing math attitudes, and (iv) 18 high-school math test questions together with their reasoning and confidence scores. MEDS differs from traditional score-only math benchmarks because it integrates concepts of self-efficacy, math anxiety, and cognitive network science besides math proficiency scores. Data validation shows that the sampled LLMs exhibit schema integrity and consistent personas, together with family-specific peculiarities like human-like negative math attitudes, logical fallacies, and math overconfidence. MEDS will benefit learning analytics experts, cognitive scientists, and developers of safer AI tutors in mathematics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MEDS (Math Education Digital Shadows) dataset, comprising 28,000 personas generated from 14 LLMs (Mistral, Qwen, DeepSeek, Granite, Phi, Grok families). Each persona is prompted under human-like or AI-like conditions and completes an open math interview, three psychometric tests on math perceptions with explanations, cognitive network elicitations for attitudes, and 18 high-school math questions with reasoning and confidence scores, plus sociodemographic and psychological metadata. The paper claims MEDS advances beyond score-only benchmarks by integrating self-efficacy, math anxiety, and cognitive network science. Internal validation is reported to confirm schema integrity, persona consistency, and family-specific peculiarities including human-like negative math attitudes, logical fallacies, and math overconfidence. The dataset is positioned to benefit learning analytics, cognitive scientists, and developers of safer AI math tutors.
Significance. If the LLM-generated personas can be shown to approximate real human student distributions in attitudes and performance, MEDS would constitute a useful large-scale resource for studying prompt-dependent biases in educational AI and for developing interventions that mitigate math anxiety. The scale, multi-dimensional design (performance + self-report + networks), and coverage across model families are clear strengths that could support reproducible analyses in learning analytics. However, the current absence of external grounding against human data substantially reduces the immediate significance for claims about human-like traits or safer tutor design.
major comments (3)
- [Abstract] Abstract: The claim that LLMs exhibit 'family-specific peculiarities like human-like negative math attitudes, logical fallacies, and math overconfidence' lacks any comparison to empirical human student distributions (e.g., validated math anxiety scales or performance-overconfidence gaps from real high-school cohorts). Internal schema integrity and persona consistency checks do not establish external validity and leave open the possibility that observed patterns are prompt artifacts or training-data echoes rather than useful approximations.
- [Abstract / validation section] Data validation description: The abstract states that 'data validation confirms schema integrity and family-specific peculiarities' but supplies no details on validation methods, statistical tests, prompt controls, inter-rater reliability for network coding, or quantitative thresholds used to identify 'peculiarities.' This information is load-bearing for the central claim that MEDS captures meaningful human-like traits.
- [Introduction / Discussion] Introduction and discussion of utility: The positioning of MEDS as enabling 'safer AI tutors' and 'facilitating learning with LLMs' rests on the assumption that human-like vs. AI-like prompt conditions produce behaviors that meaningfully reflect real students or deployed assistants. Without external validation (e.g., correlation of extracted anxiety scores or network structures with human benchmarks), this assumption remains untested and weakens the dataset's claimed value for learning analytics.
minor comments (2)
- [Abstract] Abstract: The exact total of 28,000 personas and the breakdown by model family and human-like vs. AI-like condition should be stated explicitly with a summary table in the main text for reproducibility.
- The manuscript would benefit from a dedicated reproducibility section listing the precise prompt templates, temperature settings, and post-processing steps used to generate the cognitive networks and confidence scores.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review, which highlights both the strengths of the MEDS dataset and important areas for clarification. We appreciate the recognition of its scale, multi-dimensional design, and potential relevance to learning analytics. We address each major comment below with specific revisions planned to improve precision, transparency, and framing without overstating the dataset's current scope.
read point-by-point responses
-
Referee: [Abstract] The claim that LLMs exhibit 'family-specific peculiarities like human-like negative math attitudes, logical fallacies, and math overconfidence' lacks any comparison to empirical human student distributions (e.g., validated math anxiety scales or performance-overconfidence gaps from real high-school cohorts). Internal schema integrity and persona consistency checks do not establish external validity and leave open the possibility that observed patterns are prompt artifacts or training-data echoes rather than useful approximations.
Authors: We agree that the phrasing 'human-like' risks implying quantitative equivalence to human distributions, which the current work does not demonstrate. The term was used to note qualitative echoes of patterns documented in human math education research (e.g., negative attitudes or overconfidence in subsets of students). We will revise the abstract and relevant sections to adopt more cautious language such as 'patterns reminiscent of those reported in human studies' and will add citations to established human benchmarks on math anxiety and overconfidence. We will also expand the discussion to explicitly address the possibility of prompt artifacts and training-data influences, while clarifying that MEDS is intended as a resource for studying LLM behaviors rather than as a validated proxy for human students. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: [Abstract / validation section] Data validation description: The abstract states that 'data validation confirms schema integrity and family-specific peculiarities' but supplies no details on validation methods, statistical tests, prompt controls, inter-rater reliability for network coding, or quantitative thresholds used to identify 'peculiarities.' This information is load-bearing for the central claim that MEDS captures meaningful human-like traits.
Authors: The referee is correct that the abstract is insufficiently detailed on validation procedures. The full manuscript contains a dedicated validation section describing automated schema integrity checks across all 28,000 records, consistency testing via repeated prompts for persona stability, and qualitative identification of response patterns such as logical fallacies. To address this concern, we will revise the abstract to include a concise summary of these methods, report quantitative consistency rates where available, and add details on prompt controls and any reliability procedures used for cognitive network extraction. We will also note limitations, such as the absence of formal inter-rater reliability metrics for network coding, and indicate this as an area for future refinement. The revised version will provide these specifics. revision: yes
-
Referee: [Introduction / Discussion] Introduction and discussion of utility: The positioning of MEDS as enabling 'safer AI tutors' and 'facilitating learning with LLMs' rests on the assumption that human-like vs. AI-like prompt conditions produce behaviors that meaningfully reflect real students or deployed assistants. Without external validation (e.g., correlation of extracted anxiety scores or network structures with human benchmarks), this assumption remains untested and weakens the dataset's claimed value for learning analytics.
Authors: We acknowledge that the utility claims for safer AI tutors are prospective and rest on the dataset's capacity to surface prompt-dependent biases in LLMs rather than on demonstrated correlations with human data. The manuscript positions MEDS as a tool for investigating how different prompting regimes affect LLM reasoning, self-reported anxiety, confidence, and attitudes, which can help identify risks in educational AI applications. We will revise the introduction and discussion sections to temper these claims, explicitly list the lack of external human validation as a key limitation, and reframe the contribution around enabling reproducible analyses of AI-specific behaviors in math education. We will also add forward-looking statements on how future studies could establish links to human benchmarks. These adjustments will strengthen the manuscript's honesty about its current scope. revision: yes
- A direct empirical comparison of MEDS persona distributions against human high-school student data on math anxiety, self-efficacy, and performance-overconfidence gaps would require a separate, large-scale human data collection effort that lies outside the scope of this dataset paper.
Circularity Check
No significant circularity: empirical dataset paper with no derivations or self-referential reductions.
full rationale
This is a dataset introduction paper whose contribution consists of collecting and describing 28,000 LLM persona records across math tasks, psychological scales, and cognitive networks. No equations, first-principles derivations, fitted parameters, or predictions are presented that could reduce to the paper's own inputs by construction. Internal validation steps (schema integrity, persona consistency) are empirical checks on the collected data rather than tautological re-statements of fitted quantities. Claims about family-specific peculiarities are framed as observations from the data and are externally falsifiable against real student distributions or other benchmarks; they do not rely on self-citation chains or uniqueness theorems imported from the authors' prior work. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Giannakos, M.et al.The promise and challenges of generative ai in education.Behav. & Inf. Technol.44, 2518–2544 (2025)
2025
-
[2]
individual differences103, 102274 (2023)
Kasneci, E.et al.Chatgpt for good? on opportunities and challenges of large language models for education.Learn. individual differences103, 102274 (2023)
2023
-
[3]
& Leonard, S
Gabriel, F., Kennedy, J., Marrone, R. & Leonard, S. Pragmatic ai in education and its role in mathematics learning and teaching.npj Sci. Learn.10, 26 (2025)
2025
-
[4]
& Gaševi ´c, D
Yan, L., Greiff, S., Teuber, Z. & Gaševi ´c, D. Promises and challenges of generative artificial intelligence for human learning.Nat. human behaviour8, 1839–1850 (2024)
2024
-
[5]
M., Gebru, T., McMillan-Major, A
Bender, E. M., Gebru, T., McMillan-Major, A. & Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, 610–623 (2021)
2021
-
[6]
Cognitive networks identify AI biases on societal issues in Large Language Models
De Duro, E. S., Franchino, E., Improta, R., Veltri, G. A. & Stella, M. Cognitive networks identify ai biases on societal issues in large language models.EPJ Data Sci.15, 10.1140/epjds/s13688-025-00600-7 (2025)
-
[7]
The use of artificial intelligence (ai) technologies in the european union
Eurostat. The use of artificial intelligence (ai) technologies in the european union. Tech. Rep. KS-01-26-009-EN-N, European Commission (2026). Analysis based on the 2025 EU ICT household survey. 19/34
2026
-
[8]
Ict household survey 2025: Model questionnaire (2025)
Eurostat. Ict household survey 2025: Model questionnaire (2025). Question B5 lists examples including ChatGPT, Copilot, Gemini and LLaMA. 9.Eurostat. 64% of 16–24-year-olds used ai in 2025 (2026). Eurostat news article. 10.Wenger, E. & Kenett, Y . N. Large language models are homogeneously creative.PNAS nexus5, pgag042 (2026)
2025
-
[9]
for Comput
Zhang, T.et al.Benchmarking large language models for news summarization.Transactions Assoc. for Comput. Linguist. 12, 39–57 (2024)
2024
-
[10]
Chen, X., Zhou, L., Chen, J., Wang, G. & Li, X. How is language intelligence evolving? a multi-dimensional survey of large language models.Expert. Syst. with Appl.304, 130637, 10.1016/j.eswa.2025.130637 (2026)
- [11]
-
[12]
InFindings of the Association for Computational Linguistics: ACL 2024, 6884–6915 (2024)
Liu, H.et al.Mathbench: Evaluating the theory and application proficiency of llms with a hierarchical mathematics benchmark. InFindings of the Association for Computational Linguistics: ACL 2024, 6884–6915 (2024)
2024
-
[13]
Balunovi´c, M., Dekoninck, J., Petrov, I., Jovanovi´c, N. & Vechev, M. Matharena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281(2025)
-
[14]
InFindings of the Association for Computational Linguistics: EMNLP 2024, 11351–11368 (2024)
Benedetto, L.et al.Using llms to simulate students’ responses to exam questions. InFindings of the Association for Computational Linguistics: EMNLP 2024, 11351–11368 (2024)
2024
-
[15]
& MacLellan, C
Gupta, A., Reddig, J., Calo, T., Weitekamp, D. & MacLellan, C. J. Beyond final answers: Evaluating large language models for math tutoring. InInternational Conference on Artificial Intelligence in Education, 323–337 (Springer, 2025)
2025
-
[16]
Stöhr, C., Ou, A. W. & Malmström, H. Perceptions and usage of ai chatbots among students in higher education across genders, academic levels and fields of study.Comput. Educ. Artif. Intell.7, 100259 (2024)
2024
-
[17]
& Wei, Y
Wang, X. & Wei, Y . The influence of gen-ai assisted learning on primary school students’ math anxiety: An intervention study.Appl. Cogn. Psychol.39, e70088 (2025)
2025
-
[18]
Akheel, S. A. Guardrails for large language models: A review of techniques and challenges.J Artif Intell Mach Learn. & Data Sci3, 2504–2512 (2025)
2025
-
[19]
R., Mahadevan, R., Bare, R
Hopko, D. R., Mahadevan, R., Bare, R. L. & Hunt, M. K. The abbreviated math anxiety scale (amas) construction, validity, and reliability.Assessment10, 178–182 (2003)
2003
-
[20]
Nielsen, I. L. & Moore, K. A. Psychometric data on the mathematics self-efficacy scale.Educ. psychological measurement 63, 128–138 (2003). 23.May, D. K. Mathematics self-efficacy and anxiety questionnaire.PhD Diss. Univ. Ga.(2009)
2003
-
[21]
InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022)
Weidinger, L.et al.Taxonomy of risks posed by language models. InProceedings of the 2022 ACM conference on fairness, accountability, and transparency, 214–229 (2022)
2022
-
[22]
Australas
Mirriahi, N.et al.The relationship between students’ self-regulated learning skills and technology acceptance of genai. Australas. J. Educ. Technol.41, 16–33 (2025)
2025
-
[23]
& Siew, C
Stella, M., De Nigris, S., Aloric, A. & Siew, C. S. Forma mentis networks quantify crucial differences in stem perception between students and experts.PloS one14, e0222870 (2019)
2019
-
[24]
& Stella, M
Abramski, K., Citraro, S., Lombardi, L., Rossetti, G. & Stella, M. Cognitive network science reveals bias in gpt-3, gpt-3.5 turbo, and gpt-4 mirroring math anxiety in high-school students.Big Data Cogn. Comput.7, 124 (2023)
2023
- [25]
-
[26]
& Jurgens, D
Zheng, M., Pei, J., Logeswaran, L., Lee, M. & Jurgens, D. When” a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, 15126–15154 (2024)
2024
-
[27]
Bergs, T.et al.The concept of digital twin and digital shadow in manufacturing.Procedia CIRP101, 81–84, 10.1016/j. procir.2021.02.010 (2021)
work page doi:10.1016/j 2021
-
[28]
A., Longo, A., Ficarella, A.et al.Digital twin (dt) in smart energy systems-systematic literature review of dt as a growing solution for energy internet of the things (eiot)
Ardebili, A. A., Longo, A., Ficarella, A.et al.Digital twin (dt) in smart energy systems-systematic literature review of dt as a growing solution for energy internet of the things (eiot). InE3S web of conferences, vol. 312, 1–18 (2021). 20/34
2021
-
[29]
Aghazadeh Ardebili, A., Zappatore, M., Ramadan, A. I. H. A., Longo, A. & Ficarella, A. Digital twins of smart energy systems: a systematic literature review on enablers, design, management and computational challenges.Energy Informatics 7, 94 (2024)
2024
-
[30]
Gaffinet, B., Al Haj Ali, J., Naudet, Y . & Panetto, H. Human digital twins: A systematic literature review and concept disambiguation for industry 5.0.Comput. Ind.166, 104230, https://doi.org/10.1016/j.compind.2024.104230 (2025). 34.Singh, M.et al.Digital twin: Origin to future.Appl. Syst. Innov.4, 36, 10.3390/asi4020036 (2021)
-
[31]
Aghazadeh Ardebili, A., Longo, A. & Ficarella, A. Digital twins bonds society with cyber-physical energy systems: a literature review. In2021 IEEE International Conferences on Internet of Things (iThings) and IEEE Green Computing &; Communications (GreenCom) and IEEE Cyber, Physical &; Social Computing (CP- SCom) and IEEE Smart Data (SmartData) and IEEE C...
-
[32]
Talk2AI: A Longitudinal Dataset of Human--AI Persuasive Conversations
Carrillo, A., Taietta, E., Ardebili, A. A., Veltri, G. A. & Stella, M. Talk2ai: A longitudinal dataset of human–ai persuasive conversations.arXiv preprint arXiv:2604.04354(2026). 37.John, O. The big-five trait taxonomy: History, measurement, and theoretical perspectives.Publ. as(1999)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [33]
-
[34]
De Duro, E. S., Veltri, G. A., Golino, H. & Stella, M. Measuring and identifying factors of individuals’ trust in large language models.arXiv preprint arXiv:2502.21028(2025)
-
[35]
Kranzler, J. H. & Pajares, F. An exploratory factor analysis of the mathematics self-efficacy scale—revised (mses-r).Meas. evaluation counseling development29, 215–228 (1997)
1997
-
[36]
Semeraro, A.et al.Emoatlas: An emotional network analyzer of texts that merges psychological lexicons, artificial intelligence, and network science.Behav. Res. Methods57, 10.3758/s13428-024-02553-7 (2025)
-
[37]
Logical Fallacy Detection , booktitle =
Jin, Z.et al.Logical fallacy detection. In Goldberg, Y ., Kozareva, Z. & Zhang, Y . (eds.)Findings of the Association for Com- putational Linguistics: EMNLP 2022, 7180–7198, 10.18653/v1/2022.findings-emnlp.532 (Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2022)
-
[38]
Stella, M., Hills, T. T. & Kenett, Y . N. Using cognitive psychology to understand gpt-like models needs to extend beyond human biases.Proc. Natl. Acad. Sci.120, e2312911120, 10.1073/pnas.2312911120 (2023). https://www.pnas.org/doi/pdf/ 10.1073/pnas.2312911120
-
[39]
Haim, E. & Stella, M. Cognitive networks for knowledge modeling: A gentle introduction for data-and cognitive scientists. Wiley Interdiscip. Rev. Cogn. Sci.17, e70026 (2026). 45.Yang, A.et al.Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025). 46.Liu, A.et al.Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024). 47.Abdin, M.et al.P...
work page internal anchor Pith review arXiv 2026
-
[40]
Polignano, M., Basile, P. & Semeraro, G. Advanced natural-based interaction for the italian language: Llamantino-3-anita (2024). 2405.07101
-
[41]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, J., Chang, M., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding.CoRRabs/1810.04805(2018). 1810.04805
work page internal anchor Pith review arXiv 2018
-
[42]
& Kranzler, J
Pajares, F. & Kranzler, J. Self-efficacy beliefs and general mental ability in mathematical problem-solving.Contemp. educational psychology20, 426–443 (1995). 54.Binz, M.et al.A foundation model to predict and capture human cognition.Nature644, 1002–1009 (2025)
1995
-
[43]
Wulff, D. U. & Mata, R. Escaping the jingle-jangle jungle: Increasing conceptual clarity in psychology using large language models.Curr. Dir. Psychol. Sci.35, 59–65 (2026)
2026
- [44]
-
[45]
Guo, D.et al.Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
-
[46]
Binz, M. & Schulz, E. Using cognitive psychology to understand gpt-3.Proc. Natl. Acad. Sci.120, e2218523120 (2023). 59.Rossetti, G.et al.Y social: an llm-powered social media digital twin.arXiv preprint arXiv:2408.00818(2024)
-
[47]
& Kenett, Y
Kreisberg-Nitzav, A. & Kenett, Y . N. Creativeable: Leveraging ai for personalized creativity enhancement.AI6, 247 (2025). Appendix A Description of Tasks This appendix presents the support material employed in each task. Subsections A.1 through A.4 detail, respectively, the interview questions (Task 1), the psychometric scales (Task 2), the word list for...
2025
-
[48]
What is your relationship with mathematics?
-
[49]
Do you ever get anxious when thinking about mathematics?
-
[50]
Did you use AI to support your mathematics learning in the past year? If yes, how was your experience?
-
[51]
How would you explain, step by step, how to solve a second-order algebraic equation?
-
[52]
How would you explain, step by step, how to find the stationary points of a functiony=f(x)?
-
[53]
How do you perform a Principal Component Analysis? Should one be concerned about its mathematical complexity?
-
[54]
Each assessment is expressed on a discrete 1-5 scale
In your opinion, how can LLMs be used to innovate mathematics learning in schools and universities? A.2 Task 2 Task 2 uses three different psychological scales assessing mathematics-induced anxiety and estimated self-efficacy for what concerns one’s ability to solve math problems. Each assessment is expressed on a discrete 1-5 scale. The interpretation of...
-
[55]
A simultaneous equation
-
[56]
Working with decimals
-
[57]
Determining the degrees of a missing angle
-
[58]
A problem in trigonometry
-
[59]
Calculating values of area and volume
-
[60]
Working with fractions
-
[61]
Items are rated on a 1–5 scale, where 1 indicatesno anxiety, 2some anxiety, 3moderate anxiety, 4quite a lot of anxiety, and 5high anxiety
Determining the value of a missing side length Abbreviated Math Anxiety Scale (AMAS) This scale assesses the level of anxiety respondents experience when facing various mathematics-related situations. Items are rated on a 1–5 scale, where 1 indicatesno anxiety, 2some anxiety, 3moderate anxiety, 4quite a lot of anxiety, and 5high anxiety. The items of the ...
-
[62]
Having to use the tables in the back of a mathematics book
-
[63]
Thinking about an upcoming mathematics test one day before
-
[64]
Watching a teacher work an algebraic equation on the blackboard
-
[65]
Taking an examination in a mathematics course
-
[66]
Being given a homework assignment of many difficult problems due at the next class meeting
-
[67]
Listening to a lecture in a mathematics class
-
[68]
Listening to another student explain a mathematical formula. 22/34
-
[69]
Being given a pop quiz in a mathematics class
-
[70]
I believe I can think like a mathematician
Starting a new chapter in a mathematics book. Mathematics Self-Efficacy and Anxiety Questionnaire (MSEAQ) This questionnaire assesses mathematics self-efficacy, anxiety, and perceived competence across five domains: General Math Self-Efficacy, Grade Anxiety, Future Expectations, In-Class Experience, and Assignment-Related Concerns. Items are rated on a 1–...
1995
-
[71]
The longest side is twice as long as the shortest side, and the third side is 3.4 inches shorter than the longest side
In a certain triangle, the shortest side is 6 inches. The longest side is twice as long as the shortest side, and the third side is 3.4 inches shorter than the longest side. What is the sum of the three sides in inches? A. 22.6 inches B. 24.2 inches C. 26.6 inches D. 28.0 inches E. 29.4 inches Correct Answer: C
-
[72]
5 times larger B
About how many times larger than 614,360 is 30,668,000? A. 5 times larger B. 30 times larger C. 50 times larger D. 500 times larger E. 5,000 times larger 24/34 Correct Answer: C
-
[73]
The second is twice the first and the first is one-third of the other number
There are three numbers. The second is twice the first and the first is one-third of the other number. Their sum is 48. Find the largest number. A. 8 B. 12 C. 16 D. 24 E. 32 Correct Answer: D
-
[74]
T is next to G
Five points are on a line. T is next to G. K is next to H. C is next to T. H is next to G. Determine the positions of the points along the line. A. C, T, G, H, K B. C, G, T, H, K C. T, C, G, H, K D. C, T, H, G, K E. C, T, G, K, H Correct Answer: A
-
[75]
If y = 9 + x/5, find x when y = 10. A. 1 B. 3 C. 5 D. 10 E. 25 Correct Answer: C
-
[76]
This could be represented by 2/3
A baseball player got two hits for three times at bat. This could be represented by 2/3. Which decimal most closely represents this? A. 0.20 B. 0.33 C. 0.50 D. 0.67 E. 0.80 Correct Answer: D
-
[77]
If P = M + N, which of the following will be true? (a) N = P - M (b) P - N = M (c) N + M = P. A. Only (a) is true B. (a) and (b) only C. (a) and (c) only D. (b) and (c) only E. (a), (b), and (c) are all true Correct Answer: E
-
[78]
The hands of a clock form an obtuse angle at ____ o’clock. A. 1 o’clock B. 2 o’clock C. 3 o’clock D. 4 o’clock E. 6 o’clock Correct Answer: D
-
[79]
If there are 25 stamps in the packet, how many are 13-cent stamps? A
Bridget buys a packet containing 9-cent and 13-cent stamps for $2.65. If there are 25 stamps in the packet, how many are 13-cent stamps? A. 5 B. 8 C. 10 D. 12 E. 15 Correct Answer: C
-
[80]
How far apart are two towns whose distance apart on the map is 3 half 25/34 inches? A
On a certain map, 7/8 inch represents 200 miles. How far apart are two towns whose distance apart on the map is 3 half 25/34 inches? A. about 217 miles B. about 427 miles C. about 395 miles D. about 343 miles E. about 1,000 miles Correct Answer: D
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.