Recognition: 3 theorem links
· Lean TheoremSuperLocalMemory V3.3: The Living Brain -- Biologically-Inspired Forgetting, Cognitive Quantization, and Multi-Channel Retrieval for Zero-LLM Agent Memory Systems
Pith reviewed 2026-05-10 19:42 UTC · model grok-4.3
The pith
A local-first memory system using Ebbinghaus forgetting, FRQAD metric, and seven retrieval channels reaches 70.4 percent on agent conversation benchmarks without any LLM.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
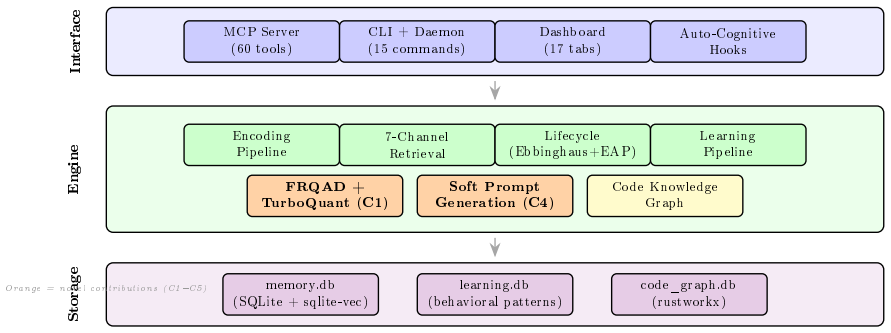
V3.3 implements the full cognitive memory taxonomy through FRQAD as a metric on the Gaussian manifold that prefers high-fidelity embeddings at 100 percent precision, Ebbinghaus Adaptive Forgetting coupled to progressive quantization that yields 6.7 times greater discrimination, and a seven-channel retrieval system spanning semantic, keyword, entity graph, temporal, spreading activation, consolidation, and Hopfield associative pathways, delivering 70.4 percent accuracy on LoCoMo in zero-LLM Mode A along with gains of 23.8 points on multi-hop and 12.7 points on adversarial subsets.
What carries the argument
The seven-channel cognitive retrieval system combined with the FRQAD metric and Ebbinghaus Adaptive Forgetting curve that links forgetting rate to embedding compression over memory lifecycle stages.
If this is right
- Agent memory can run entirely on CPU with no cloud LLM calls for core recall operations while still handling complex conversation tasks.
- Memory parameterization through soft prompts enables long-term implicit storage that persists across sessions without explicit storage overhead.
- The auto-cognitive pipeline automates the complete memory lifecycle from encoding through consolidation and forgetting, reducing manual tuning.
- Deliberate trade-offs between Mode A zero-LLM accuracy and higher modes that use LLMs allow designers to choose operating points based on resource constraints.
Where Pith is reading between the lines
- If the forgetting curve and channel combination prove robust, they could be ported to other local vector stores to improve discrimination without changing embedding models.
- The approach suggests that explicit modeling of memory consolidation stages may reduce the need for ever-larger context windows in downstream models.
- Success on adversarial subsets implies the multi-channel design could help agents resist prompt-injection style attacks that target single retrieval paths.
Load-bearing premise
That the seven-channel retrieval, FRQAD metric, and lifecycle-aware quantization deliver genuine cognitive advantages that generalize beyond the LoCoMo benchmark and the specific implementation choices in V3.3.
What would settle it
Measure whether the same performance deltas appear when the system is tested on a different long-context agent benchmark that emphasizes multi-turn reasoning outside the LoCoMo distribution while holding all other variables fixed.
Figures



read the original abstract
AI coding agents operate in a paradox: they possess vast parametric knowledge yet cannot remember a conversation from an hour ago. Existing memory systems store text in vector databases with single-channel retrieval, require cloud LLMs for core operations, and implement none of the cognitive processes that make human memory effective. We present SuperLocalMemory V3.3 ("The Living Brain"), a local-first agent memory system implementing the full cognitive memory taxonomy with mathematical lifecycle dynamics. Building on the information-geometric foundations of V3.2 (arXiv:2603.14588), we introduce five contributions: (1) Fisher-Rao Quantization-Aware Distance (FRQAD) -- a new metric on the Gaussian statistical manifold achieving 100% precision at preferring high-fidelity embeddings over quantized ones (vs 85.6% for cosine), with zero prior art; (2) Ebbinghaus Adaptive Forgetting with lifecycle-aware quantization -- the first mathematical forgetting curve in local agent memory coupled to progressive embedding compression, achieving 6.7x discriminative power; (3) 7-channel cognitive retrieval spanning semantic, keyword, entity graph, temporal, spreading activation, consolidation, and Hopfield associative channels, achieving 70.4% on LoCoMo in zero-LLM Mode A; (4) memory parameterization implementing Long-Term Implicit memory via soft prompts; (5) zero-friction auto-cognitive pipeline automating the complete memory lifecycle. On LoCoMo, V3.3 achieves 70.4% in Mode A (zero-LLM), with +23.8pp on multi-hop and +12.7pp on adversarial. V3.2 achieved 74.8% Mode A and 87.7% Mode C; the 4.4pp gap reflects a deliberate architectural trade-off. SLM V3.3 is open source under the Elastic License 2.0, runs entirely on CPU, with over 5,000 monthly downloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SuperLocalMemory V3.3 ('The Living Brain'), a local-first, zero-LLM agent memory system that implements a full cognitive memory taxonomy. Building on the authors' prior V3.2 work, it introduces Fisher-Rao Quantization-Aware Distance (FRQAD) as a metric on the Gaussian manifold, Ebbinghaus Adaptive Forgetting coupled to lifecycle-aware quantization, a 7-channel retrieval architecture (semantic, keyword, entity graph, temporal, spreading activation, consolidation, Hopfield), and memory parameterization via soft prompts. The central empirical claims are 70.4% accuracy on LoCoMo in Mode A (zero-LLM), with +23.8pp gains on multi-hop and +12.7pp on adversarial subsets, FRQAD achieving 100% precision at preferring high-fidelity embeddings (vs. 85.6% for cosine), and Ebbinghaus forgetting delivering 6.7x discriminative power.
Significance. If the reported gains can be rigorously attributed to the proposed cognitive mechanisms rather than implementation details, the work could meaningfully advance local, biologically-plausible memory architectures for autonomous agents. The open-source release under Elastic License 2.0, CPU-only execution, and explicit mathematical framing of forgetting and quantization are positive elements that could support reproducibility and extension. However, the absence of isolating experiments currently limits the assessed significance to incremental engineering contributions rather than a validated cognitive advance.
major comments (3)
- [Abstract] Abstract and results: The manuscript reports 70.4% LoCoMo Mode A accuracy together with the +23.8pp multi-hop and +12.7pp adversarial lifts, yet supplies no ablation tables, control conditions, or statistical tests that isolate the contributions of FRQAD, Ebbinghaus Adaptive Forgetting, or the seven retrieval channels from other factors (embedding model choice, quantization schedule, channel weighting). Without such controls the attribution of performance to the new cognitive components cannot be verified.
- [Abstract] Abstract: No error bars, run-to-run variance, or data-exclusion criteria are stated for any of the quoted performance figures (70.4%, 100% FRQAD precision, 6.7x discriminative power). The experimental design therefore does not meet standard requirements for reproducible claims in AI systems papers.
- [Abstract] Abstract and comparison to V3.2: The 4.4pp drop relative to V3.2's 74.8% Mode A score is described as a deliberate architectural trade-off, but no quantitative characterization of that trade-off or results on any benchmark other than LoCoMo are provided. This leaves open whether the V3.3 mechanisms generalize or merely reflect benchmark-specific tuning.
minor comments (2)
- [Abstract] Abstract: The claim of 'zero prior art' for FRQAD would be strengthened by a short literature pointer or explicit statement that no comparable information-geometric metric on quantized embeddings has been proposed.
- [Abstract] The abstract states that the system 'implements the full cognitive memory taxonomy' but does not define the taxonomy or map each of the seven channels to established cognitive psychology constructs; a brief clarifying sentence would improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions planned to improve experimental rigor and transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: The manuscript reports 70.4% LoCoMo Mode A accuracy together with the +23.8pp multi-hop and +12.7pp adversarial lifts, yet supplies no ablation tables, control conditions, or statistical tests that isolate the contributions of FRQAD, Ebbinghaus Adaptive Forgetting, or the seven retrieval channels from other factors (embedding model choice, quantization schedule, channel weighting). Without such controls the attribution of performance to the new cognitive components cannot be verified.
Authors: We agree that ablation studies are required to isolate the contributions of the proposed mechanisms. In the revised manuscript we will add ablation tables that disable FRQAD (replacing it with cosine), disable Ebbinghaus forgetting, and ablate individual retrieval channels, reporting the resulting LoCoMo accuracy changes together with paired statistical tests. revision: yes
-
Referee: [Abstract] Abstract: No error bars, run-to-run variance, or data-exclusion criteria are stated for any of the quoted performance figures (70.4%, 100% FRQAD precision, 6.7x discriminative power). The experimental design therefore does not meet standard requirements for reproducible claims in AI systems papers.
Authors: We acknowledge this omission. The revised version will report standard deviations across multiple runs for all key metrics, specify the number of runs and random seeds, and explicitly document data-exclusion criteria and preprocessing steps for the LoCoMo evaluation. revision: yes
-
Referee: [Abstract] Abstract and comparison to V3.2: The 4.4pp drop relative to V3.2's 74.8% Mode A score is described as a deliberate architectural trade-off, but no quantitative characterization of that trade-off or results on any benchmark other than LoCoMo are provided. This leaves open whether the V3.3 mechanisms generalize or merely reflect benchmark-specific tuning.
Authors: We will expand the manuscript to quantify the trade-off with concrete metrics on latency, memory footprint, and CPU usage that motivated the zero-LLM design. We do not currently have results on other benchmarks, as evaluation was focused on LoCoMo; we will add a limitations discussion on generalization and note this as future work. revision: partial
- Results on benchmarks other than LoCoMo, which were not performed in the present study.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's abstract describes a memory system with new components (FRQAD metric, Ebbinghaus Adaptive Forgetting, 7-channel retrieval) and reports empirical results on the LoCoMo benchmark (70.4% Mode A score, specific percentage point lifts). It references prior same-author work for foundations but presents the performance numbers as measured outcomes rather than as outputs of a closed mathematical derivation. No equations, fitted parameters renamed as predictions, or self-referential definitions are visible in the provided text that would reduce the central claims to their inputs by construction. The self-citation supplies context but does not bear the load of the benchmark results, which are independent of the prior paper. This is a standard non-circular empirical system paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- Quantization compression schedule
- Channel weighting parameters
axioms (1)
- domain assumption Human cognitive memory taxonomy can be faithfully implemented via statistical manifold metrics and lifecycle dynamics in software
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FRQAD ... dFR = sqrt( sum [sqrt(2) arccosh(1 + (μ1k-μ2k)^2 + 2(σ1k-σ2k)^2)/(4σ1kσ2k)]^2 ) ... on the Gaussian statistical manifold
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ebbinghaus Adaptive Forgetting ... R(m,t) = exp(-t/S(m)) ... coupled to Fokker-Planck lifecycle dynamics ... Theorem 5.3 (Convergence)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
7-channel cognitive retrieval ... weighted Reciprocal Rank Fusion ... Hopfield associative memory
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MemoryLLM: Towards self-updatable large language models. 2024
2024
- [2]
- [3]
-
[4]
FOREVER: Forgetting curve-inspired memory replay for continual learning.arXiv preprint arXiv:2601.03938, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Natural gradient works efficiently in learning.Neural Computation, 10(2): 251–276, 1998
Shun-ichi Amari. Natural gradient works efficiently in learning.Neural Computation, 10(2): 251–276, 1998
1998
-
[6]
Colin Atkinson and Ann F. S. Mitchell. Rao’s distance measure.Sankhy¯ a: The Indian Journal of Statistics, Series A, 43(3):345–365, 1981
1981
-
[7]
Agent Behavioral Contracts: Formal Specification and Runtime Enforcement,
Varun Pratap Bhardwaj. Privacy-preserving multi-agent memory with Bayesian trust defense.arXiv preprint arXiv:2602.22302, 2026
-
[8]
Varun Pratap Bhardwaj. Information-geometric foundations for zero-LLM enterprise agent memory.arXiv preprint arXiv:2603.14588, 2026
-
[9]
Collins and Elizabeth F
Allan M. Collins and Elizabeth F. Loftus. A spreading-activation theory of semantic processing.Psychological Review, 82(6):407–428, 1975
1975
-
[10]
Duncker & Humblot, Leipzig, 1885
Hermann Ebbinghaus.Über das Gedächtnis. Duncker & Humblot, Leipzig, 1885
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. 2024
2024
-
[12]
PolarQuant: Polar-Coordinate KV Cache Quantization,
Insu Han, Praneeth Kacham, Amin Karbasi, Vahab Mirrokni, and Amir Zandieh. Polar- Quant: Quantizing KV caches with polar transformation. InProceedings of AISTATS, 2026. arXiv:2502.02617
-
[13]
SYNAPSE: Synergistic associative processing & semantic encoding
Hanqi Jiang et al. SYNAPSE: Synergistic associative processing & semantic encoding. arXiv preprint arXiv:2601.02744, 2026
-
[14]
arXiv preprint arXiv:2504.02441 , year=
Zhongyang Li et al. Cognitive memory in large language models.arXiv preprint arXiv:2504.02441, 2025
-
[15]
Evaluating very long-term conversational memory of LLM agents
Priyanka Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. In Proceedings of ACL, 2024. arXiv:2402.09714. 18
-
[16]
McClelland, Bruce L
James L. McClelland, Bruce L. McNaughton, and Randall C. O’Reilly. Why there are complementary learning systems in the hippocampus and neocortex.Psychological Review, 102(3), 1995
1995
-
[17]
Mem0: The memory layer for personalized AI.https://github.com/mem0ai/ mem0, 2024
Mem0 AI. Mem0: The memory layer for personalized AI.https://github.com/mem0ai/ mem0, 2024
2024
-
[18]
How to generate random matrices from the classical compact groups
Francesco Mezzadri. How to generate random matrices from the classical compact groups. Notices of the AMS, 54(5):592–604, 2007
2007
-
[19]
MEM1: RL-trained memory consolidation for LLM agents, 2025
MIT/NUS. MEM1: RL-trained memory consolidation for LLM agents, 2025
2025
-
[20]
MemGPT: Towards LLMs as Operating Systems
Charles Packer et al. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Hopfield networks is all you need.arXiv preprint arXiv:2008.02217, 2020
Hubert Ramsauer et al. Hopfield networks is all you need. InProceedings of ICLR, 2021. arXiv:2008.02217
-
[22]
QJL: 1-Bit Quantized JL Transform for KV Cache Quantization with Zero Overhead,
Amir Zandieh, Majid Daliri, and Insu Han. QJL: 1-bit quantized JL transform for KV cache quantization with zero overhead. InProceedings of AAAI, 2025. arXiv:2406.03482
-
[23]
Turboquant: Online vector quantization with near-optimal distortion rate,
Amir Zandieh, Majid Daliri, Majid Hadian, and Vahab Mirrokni. TurboQuant: Online vector quantization with near-optimal distortion rate. InProceedings of ICLR, 2026. arXiv:2504.19874. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.