Recognition: 1 theorem link
· Lean TheoremJoint Fullband-Subband Modeling for High-Resolution SingFake Detection
Pith reviewed 2026-05-10 19:40 UTC · model grok-4.3
The pith
A joint fullband-subband model on 44.1 kHz audio detects singing deepfakes more effectively than 16 kHz models by isolating unevenly distributed high-frequency artifacts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the joint fullband-subband modeling framework significantly outperforms 16 kHz-sampled models on the WildSVDD dataset, establishing that high-resolution audio and strategic subband integration are critical for robust SingFake detection because high-frequency subbands supply essential complementary cues for synthesis artifacts.
What carries the argument
The joint fullband-subband modeling framework, where the fullband path captures global audio context and subband-specific experts isolate fine-grained synthesis artifacts that are unevenly distributed across the spectrum.
Load-bearing premise
That high-frequency subbands contain essential complementary cues for synthesis artifacts not captured by fullband modeling or lower sampling rates, and that the WildSVDD dataset represents real-world conditions.
What would settle it
A controlled test showing that either a fullband-only 44.1 kHz model or an enhanced 16 kHz model matches or exceeds the joint framework's accuracy on the same WildSVDD evaluation set would falsify the necessity of subband integration.
Figures


read the original abstract
Rapid advances in singing voice synthesis have increased unauthorized imitation risks, creating an urgent need for better Singing Voice Deepfake (SingFake) Detection, also known as SVDD. Unlike speech, singing contains complex pitch, wide dynamic range, and timbral variations. Conventional 16 kHz-sampled detectors prove inadequate, as they discard vital high-frequency information. This study presents the first systematic analysis of high-resolution (44.1 kHz sampling rate) audio for SVDD. We propose a joint fullband-subband modeling framework: the fullband captures global context, while subband-specific experts isolate fine-grained synthesis artifacts unevenly distributed across the spectrum. Experiments on the WildSVDD dataset demonstrate that high-frequency subbands provide essential complementary cues. Our framework significantly outperforms 16 kHz-sampled models, proving that high-resolution audio and strategic subband integration are critical for robust in-the-wild detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to present the first systematic study of 44.1 kHz audio for Singing Voice Deepfake Detection (SVDD). It introduces a joint fullband-subband modeling framework in which a fullband branch captures global context while subband-specific experts isolate fine-grained synthesis artifacts that are unevenly distributed across the spectrum. Experiments on the WildSVDD dataset are reported to show that high-frequency subbands supply essential complementary cues, with the proposed framework significantly outperforming conventional 16 kHz-sampled detectors and thereby establishing high-resolution audio plus strategic subband integration as critical for robust in-the-wild detection.
Significance. If the empirical results and ablations hold, the work would provide concrete evidence that high-resolution sampling and subband decomposition address limitations of low-rate models for singing-voice artifacts, potentially shifting detector design practices in audio forensics and deepfake mitigation.
major comments (1)
- [Abstract] Abstract: the central claim that subband-specific experts isolate synthesis artifacts 'unevenly distributed across the spectrum' that cannot be captured by fullband modeling at 44.1 kHz lacks support from any reported ablation against a high-resolution fullband-only baseline. Without this comparison, the reported gains over 16 kHz models could be explained entirely by the increase in sampling rate rather than the joint architecture.
minor comments (1)
- The abstract would be strengthened by inclusion of at least one quantitative performance figure (e.g., EER or AUC) and a brief statement of dataset size or split statistics.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the abstract and the need for stronger empirical support for the joint architecture's contributions. We address this point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that subband-specific experts isolate synthesis artifacts 'unevenly distributed across the spectrum' that cannot be captured by fullband modeling at 44.1 kHz lacks support from any reported ablation against a high-resolution fullband-only baseline. Without this comparison, the reported gains over 16 kHz models could be explained entirely by the increase in sampling rate rather than the joint architecture.
Authors: We agree that the manuscript does not report a direct ablation comparing the joint fullband-subband model against a fullband-only model trained and evaluated at 44.1 kHz. Our current experiments establish that the proposed framework outperforms conventional 16 kHz detectors and that high-frequency subbands supply complementary cues on the WildSVDD dataset. However, this does not yet isolate whether the subband experts capture artifacts inaccessible to fullband modeling at the same sampling rate. To address the concern, we will add the requested high-resolution fullband baseline ablation in the revised manuscript, including performance metrics and analysis of per-subband contributions relative to the fullband branch. This will allow a clearer attribution of gains to the joint architecture rather than sampling rate alone. revision: yes
Circularity Check
No circularity: purely empirical modeling and evaluation
full rationale
The paper presents an empirical framework for SingFake detection using joint fullband-subband modeling at 44.1 kHz, with claims resting on experimental outperformance versus 16 kHz baselines on the WildSVDD dataset. No mathematical derivation chain, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the abstract or description. The architecture is described as a design choice (fullband for global context, subband experts for localized artifacts) justified by results rather than by construction from prior outputs. No load-bearing self-citations or imported uniqueness theorems are invoked. This is a standard experimental ML paper whose central claims are falsifiable via ablation and external benchmarks, with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearjoint fullband-subband modeling framework: the fullband captures global context, while subband-specific experts isolate fine-grained synthesis artifacts unevenly distributed across the spectrum
Reference graph
Works this paper leans on
-
[1]
Joint Fullband-Subband Modeling for High-Resolution SingFake Detection
Introduction Due to the rapid advancement of singing voice synthesis meth- ods, tools such as VISinger [1] and DiffSinger [2] can now gen- erate highly realistic vocals, significantly increasing the risk of unauthorized imitation. This evolution has created an urgent need for robust Singing V oice Deepfake (SingFake) Detection, also known as SVDD, a deman...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
fingerprints
Related Work 2.1. Singing Voice Deepfake Detection Singing V oice Deepfake Detection (SVDD) has gained increas- ing attention as a specialized extension of speech anti-spoofing. Building upon the initial SingFake dataset [3], the SVDD Chal- lenge 2024 [17] expanded the task by introducing two dis- tinct tracks: a controlled setting (CtrSVDD [18]) and a in...
2024
-
[3]
This architecture is designed to simul- taneously model global spectral patterns and local frequency- specific features
Proposed Sing-HiResNet Framework To better capture the synthesis artifacts in high-resolution singing audio, we propose Sing-HiResNet, a joint fullband- subband framework. This architecture is designed to simul- taneously model global spectral patterns and local frequency- specific features. As shown in Figure 2, our approach is based on the principle tha...
-
[4]
For a given input, the student produces logitz (s) and embeddingh (s), while the teacher providesz (t) andh (t)
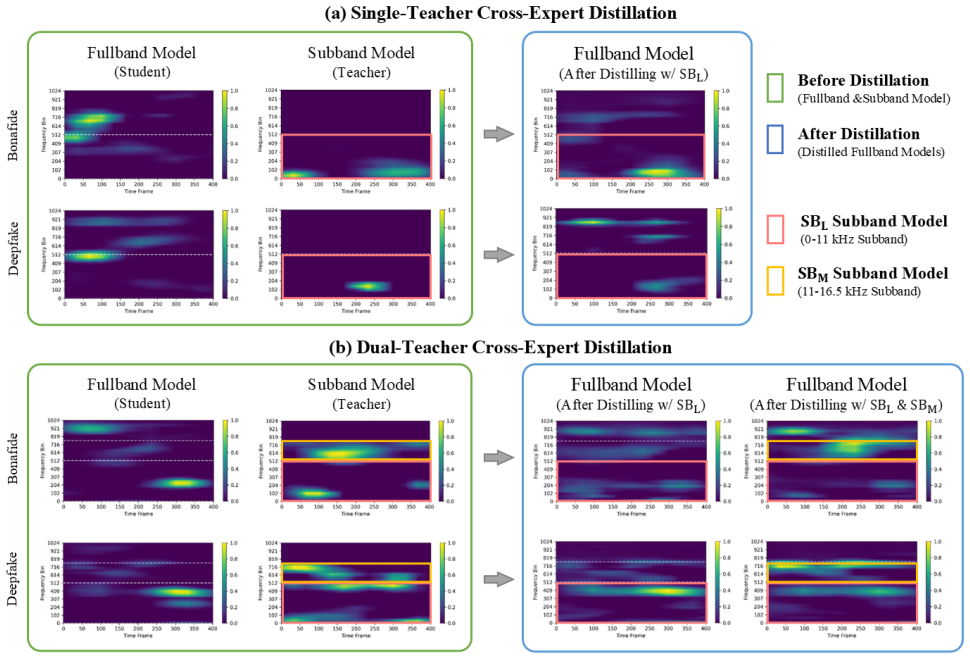
Knowledge Distillation Objectives.We employ two distillation objectives targeting both logit-level and feature-level knowledge. For a given input, the student produces logitz (s) and embeddingh (s), while the teacher providesz (t) andh (t). •Logit-Level Knowledge.We utilize Kullback-Leibler (KL) divergence [34] to minimize the discrepancy between soft- en...
-
[5]
This framework al- lows the student to integrate specialized subband knowledge into a unify representation
Teacher Configurations.We propose a multi-teacher distillation framework to transfer knowledge from diverse sub- band experts to a fullband student model. This framework al- lows the student to integrate specialized subband knowledge into a unify representation. The aggregated teacher embedding h(t) and logitz (t) are defined as: h(t) = MX m=1 wmh(tm), z ...
-
[6]
Dataset and Evaluation.We evaluate our model on the WildSVDD dataset [35], which contains authentic and AI- synthesized singing from unconstrained online sources
Experimental Setup To evaluate the performance of Sing-HiResNet framework, this section details the dataset, evaluation protocols, pre-processing procedures, model setup, and distillation configurations. Dataset and Evaluation.We evaluate our model on the WildSVDD dataset [35], which contains authentic and AI- synthesized singing from unconstrained online...
-
[7]
in-the- wild
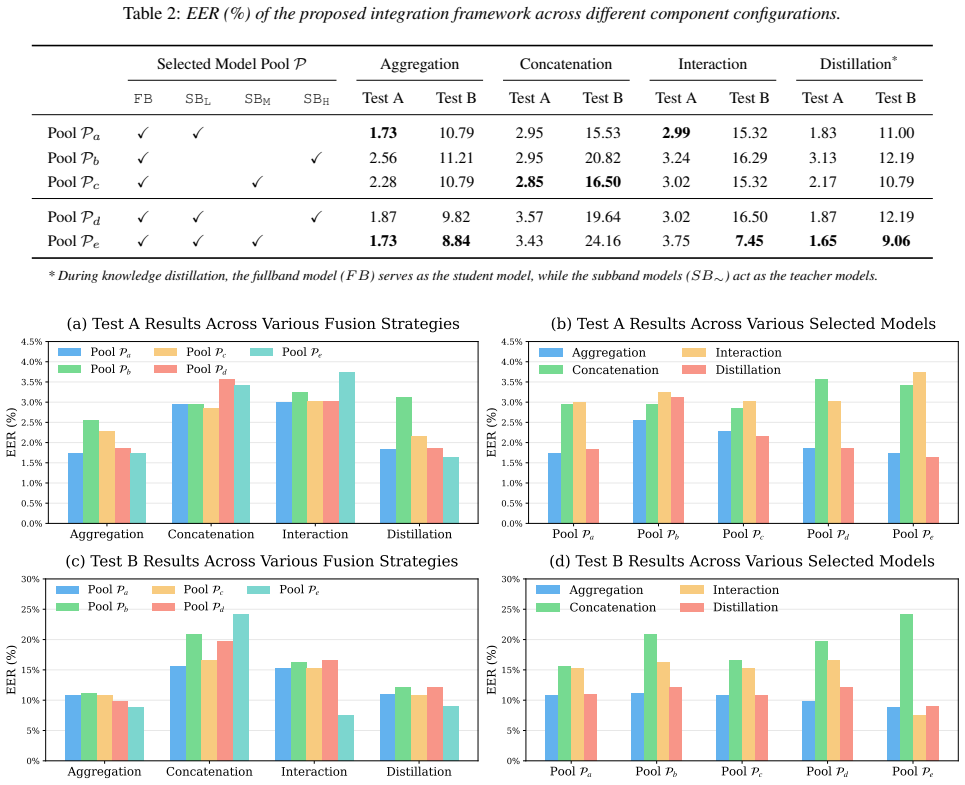
Experiment Results 5.1. Preliminary Study of Subband Modeling Table 1 evaluates the efficacy of subband expert models across four partition configurations (N= 1,2,4,8). To further inves- tigate the potential of these experts, we also evaluate feature- level concatenation variants (SB-Concat-N), which merge the embeddings of all subband experts within a pa...
2007
-
[8]
Conclusion This study provides the first systematic analysis of joint fullband-subband modeling for high-resolution SingFake detec- tion by leveraging audio input at a 44.1 kHz sampling rate. We argue that high-resolution audio at 44.1 kHz preserves extended harmonics and breath textures essential for forgery detection, whereas audio downsampled to 16 kHz...
-
[9]
We acknowledge the National Center for High-performance Computing (NCHC) for provid- ing essential computational resources
Acknowledgements This work was supported by the Ministry of Education (MOE) of Taiwan under the project ”Taiwan Centers of Excellence in Artificial Intelligence,” through the NTU Artificial Intelligence Center of Research Excellence. We acknowledge the National Center for High-performance Computing (NCHC) for provid- ing essential computational resources....
-
[10]
Generative AI Use Disclosure We employed Gemini for grammatical paraphrasing and lan- guage polishing to improve the manuscript’s clarity. The AI tool was utilized solely for technical editing purposes and did not contribute to the conceptualization, data analysis, or pro- duction of any significant scholarly content in this work
-
[11]
VISinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,
Y . Zhang, J. Cong, H. Xue, L. Xie, P. Zhu, and M. Bi, “VISinger: Variational inference with adversarial learning for end-to-end singing voice synthesis,” inICASSP, 2022
2022
-
[12]
DiffSinger: singing voice synthesis via shallow diffusion mechanism (2021),
J. Liu, C. Li, Y . Ren, F. Chen, and Z. Zhao, “DiffSinger: singing voice synthesis via shallow diffusion mechanism (2021),”arXiv preprint arXiv:2105.02446, 2021
-
[13]
SingFake: Singing voice deepfake detection,
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan, “SingFake: Singing voice deepfake detection,” inICASSP, 2024
2024
-
[14]
SVDD 2024: The inaugural singing voice deep- fake detection challenge,
Y . Zhanget al., “SVDD 2024: The inaugural singing voice deep- fake detection challenge,” in2024 IEEE Spoken Language Tech- nology Workshop (SLT), 2024
2024
-
[15]
Nes2Net: A lightweight nested architecture for foundation model driven speech anti-spoofing,
T. Liu, D.-T. Truong, R. Kumar Das, K. Aik Lee, and H. Li, “Nes2Net: A lightweight nested architecture for foundation model driven speech anti-spoofing,”IEEE Transactions on Infor- mation Forensics and Security, vol. 20, pp. 12 005–12 018, 2025
2025
-
[17]
O. C. Phukan, S. Jain, S. R. Behera, A. B. Buduru, R. Sharma, and S. M. Prasanna, “Are music foundation models better at singing voice deepfake detection? far-better fuse them with speech foun- dation models,”arXiv preprint arXiv:2409.14131, 2024
-
[18]
A comparative study of deep audio mod- els for spectrogram- and waveform-based singfake detection,
M. Nguyen-Duc, L. V . Nguyen, H. Nguyen-Ho-Nhat, T.-H. Nguyen, and O.-J. Lee, “A comparative study of deep audio mod- els for spectrogram- and waveform-based singfake detection,” IEEE Access, vol. 13, pp. 95 739–95 752, 2025
2025
-
[19]
GASGM-GFT: Gaus- sian attenuation singing graph model and graph fourier transform for singing voice deepfake detection,
B. Wu, Q. Qian, L. Ran, and H. Wang, “GASGM-GFT: Gaus- sian attenuation singing graph model and graph fourier transform for singing voice deepfake detection,” in2025 International Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–8
2025
-
[20]
Speech foundation model ensembles for the controlled singing voice deepfake detection (CTRSVDD) challenge 2024,
A. Guragain, T. Liu, Z. Pan, H. B. Sailor, and Q. Wang, “Speech foundation model ensembles for the controlled singing voice deepfake detection (CTRSVDD) challenge 2024,” inIEEE Spo- ken Language Technology Workshop (SLT), 2024, pp. 774–781
2024
-
[21]
Analysis of high- frequency energy in long-term average spectra of singing, speech, and voiceless fricatives,
B. B. Monson, A. J. Lotto, and B. H. Story, “Analysis of high- frequency energy in long-term average spectra of singing, speech, and voiceless fricatives,”The Journal of the Acoustical Society of America, vol. 132, no. 3, pp. 1754–1764, 2012
2012
-
[22]
Communication in the presence of noise,
C. Shannon, “Communication in the presence of noise,”Proceed- ings of the IRE, vol. 37, no. 1, pp. 10–21, jan 1949
1949
-
[23]
Significance of subband features for synthetic speech detection,
J. Yang, R. K. Das, and H. Li, “Significance of subband features for synthetic speech detection,”IEEE Transactions on Informa- tion Forensics and Security, vol. 15, pp. 2160–2170, 2020
2020
-
[24]
Subband modeling for spoofing detection in automatic speaker verification,
B. Chettri, T. Kinnunen, and E. Benetos, “Subband modeling for spoofing detection in automatic speaker verification,” 2020. [Online]. Available: https://arxiv.org/abs/2004.01922
-
[25]
Audio deepfake detection based on a combination of f0 information and real plus imaginary spectrogram features,
J. Xue, C. Fan, Z. Lv, J. Tao, J. Yi, C. Zheng, Z. Wen, M. Yuan, and S. Shao, “Audio deepfake detection based on a combination of f0 information and real plus imaginary spectrogram features,” in Proceedings of the 1st International Workshop on Deepfake De- tection for Audio Multimedia. ACM, Oct. 2022, p. 19–26
2022
-
[26]
Subband fusion of complex spectrogram for fake speech detection,
C. Fan, J. Xue, S. Dong, M. Ding, J. Yi, J. Li, and Z. Lv, “Subband fusion of complex spectrogram for fake speech detection,”Speech Commun., vol. 155, no. C, Nov. 2023. [Online]. Available: https://doi.org/10.1016/j.specom.2023.102988
-
[28]
CtrSVDD: A benchmark dataset and baseline analysis for controlled singing voice deepfake detec- tion,
Y . Zang, J. Shi, Y . Zhang, R. Yamamoto, J. Han, Y . Tang, S. Xu, W. Zhao, J. Guo, T. Todaet al., “CtrSVDD: A benchmark dataset and baseline analysis for controlled singing voice deepfake detec- tion,” inProc. INTERSPEECH, 2024
2024
-
[29]
Ims-scu sub- mission for wildsvdd challenge at mirex 2024,
Y . Qiu, H. Wang, P. Du, M. Du, and R. Zhang, “Ims-scu sub- mission for wildsvdd challenge at mirex 2024,” 2024, accessed: March 5, 2026. [Online]. Available: https://futuremirex.com/ portal/wp-content/uploads/2024/11/IMS SCU SUBMISSION FOR WildSVDD challenge at MIREX 2024.pdf
2024
-
[30]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[31]
Singing voice graph modeling for singfake detection,
X. Chen, H. Wu, J.-S. R. Jang, and H. yi Lee, “Singing voice graph modeling for singfake detection,” inINTERSPEECH, 2024
2024
-
[32]
MERT: Acoustic music understanding model with large-scale self-supervised training,
Y . Li, R. Yuan, G. Zhang, Y . Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos, N. Gyenge, R. Dannenberg, R. Liu, W. Chen, G. Xia, Y . Shi, W. Huang, Z. Wang, Y . Guo, and J. Fu, “MERT: Acoustic music understanding model with large-scale self-supervised training,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[34]
Audio features investigation for singing voice deepfake detection,
M. Gohari, D. Salvi, P. Bestagini, and N. Adami, “Audio features investigation for singing voice deepfake detection,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[35]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProc. CVPR, 2016
2016
-
[36]
Speech enhancement with fullband- subband cross-attention network,
J. Chen, W. Rao, Z. Wang, Z. Wu, Y . Wang, T. Yu, S. Shang, and H. Meng, “Speech enhancement with fullband- subband cross-attention network,” 2022. [Online]. Available: https://arxiv.org/abs/2211.05432
-
[37]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[38]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”CoRR, vol. abs/1706.03762, 2017. [Online]. Available: http://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Towards generalized source tracing for codec-based deepfake speech,
X. Chen, I. Lin, L. Zhang, H. Wu, H.-y. Lee, J.-S. R. Janget al., “Towards generalized source tracing for codec-based deepfake speech,”arXiv preprint arXiv:2506.07294, 2025
-
[40]
Localizing audio-visual deepfakes via hierarchical boundary modeling,
X. Chen, S.-P. Cheng, J. Du, L. Zhang, X. Miao, C.-C. Wang, H. Wu, H.-y. Lee, and J.-S. R. Jang, “Localizing audio-visual deepfakes via hierarchical boundary modeling,”arXiv preprint arXiv:2508.02000, 2025
-
[41]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
Mul- timodal transformer distillation for audio-visual synchronization,
X. Chen, H. Wu, C.-C. Wang, H.-Y . Lee, and J.-S. R. Jang, “Mul- timodal transformer distillation for audio-visual synchronization,” inIEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), 2024, pp. 7755–7759
2024
-
[43]
Adversar- ial speaker distillation for countermeasure model on automatic speaker verification,
Y .-L. Liao, X. Chen, C.-C. Wang, and J.-S. R. Jang, “Adversar- ial speaker distillation for countermeasure model on automatic speaker verification,” in2nd Symposium on Security and Privacy in Speech Communication, 2022, pp. 30–34
2022
-
[44]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,” The annals of mathematical statistics, vol. 22, pp. 79–86, 1951
1951
-
[45]
SVDD challenge 2024: A singing voice deepfake detection challenge evaluation plan,
Y . Zhanget al., “SVDD challenge 2024: A singing voice deepfake detection challenge evaluation plan,”arXiv preprint arXiv:2405.05244, 2024
-
[46]
How does instrumental music help singfake detection?
X. Chen, C.-Y . Hu, I.-M. Lin, Y .-C. Lin, I.-H. Chiu, Y . Zhang, S.-F. Huang, Y .-H. Yang, H. Wu, H. yi Lee, and J.-S. R. Jang, “How does instrumental music help singfake detection?” 2025. [Online]. Available: https://arxiv.org/abs/2509.14675
-
[47]
Im- ageNet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Im- ageNet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255
2009
-
[48]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar, “Focal loss for dense object detection,” inProceedings of the IEEE interna- tional conference on computer vision, 2017, pp. 2980–2988
2017
-
[49]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
SGDR: Stochastic Gradient Descent with Warm Restarts
——, “SGDR: Stochastic gradient descent with warm restarts,” arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[51]
Hearing thresholds for pure tones above 16khz,
K. Ashihara, “Hearing thresholds for pure tones above 16khz,” The Journal of the Acoustical Society of America, vol. 122, no. 3, pp. EL52–EL57, 2007
2007
-
[52]
R. Yang, K. Li, G. Chen, and X. Hu, “Enhancing spectrogram re- alism in singing voice synthesis via explicit bandwidth extension prior to vocoder,”arXiv preprint arXiv:2508.01796, 2025
-
[53]
BigVGAN: A universal neural vocoder with large- scale training,
S. gil Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large- scale training,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https: //openreview.net/forum?id=iTtGCMDEzS
2023
-
[54]
Grad-CAM: visual explanations from deep net- works via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-CAM: visual explanations from deep net- works via gradient-based localization,”International journal of computer vision, vol. 128, no. 2, pp. 336–359, 2020
2020
-
[55]
SVDD 2024: Singing voice deepfake detection chal- lenge leaderboard,
“SVDD 2024: Singing voice deepfake detection chal- lenge leaderboard,” https://music-ir.org/mirex/wiki/2024: Singing V oiceDeepfake Detection Results, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.