Recognition: no theorem link
Watch Before You Answer: Learning from Visually Grounded Post-Training
Pith reviewed 2026-05-10 19:56 UTC · model grok-4.3
The pith
Filtering post-training data to only visually grounded questions improves VLM video understanding by up to 6.2 points using 69 percent of the data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
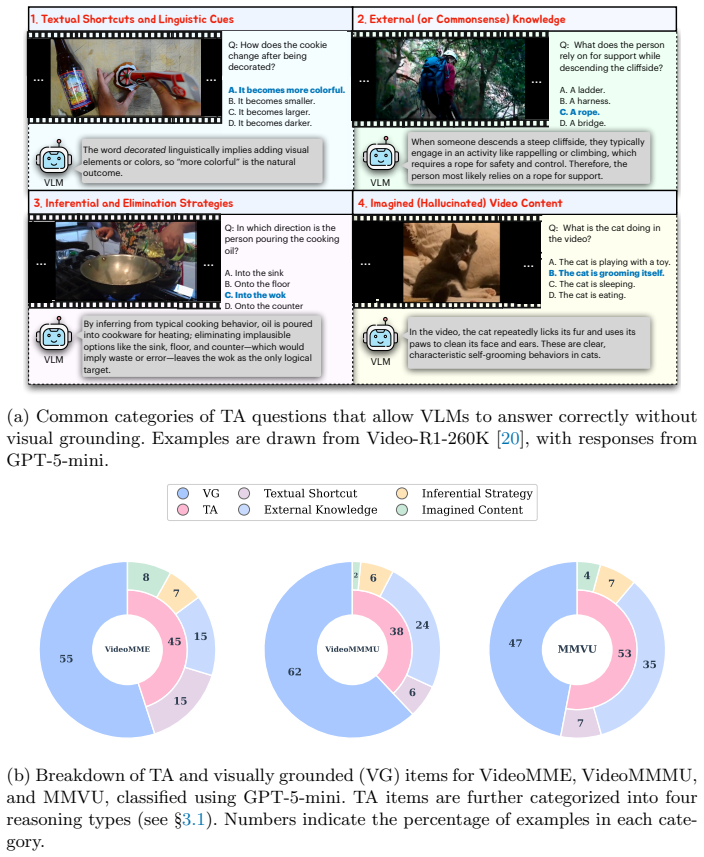
Commonly reported long video understanding benchmarks contain 40-60 percent of questions that can be answered using text cues alone, and similar issues pervade post-training datasets. By introducing VidGround to select only the actual visually grounded questions without linguistic biases for post-training, and pairing this with RL-based algorithms, performance improves by up to 6.2 points while using only 69.1 percent of the original post-training data. Data curation with a simple post-training algorithm outperforms several more complex post-training techniques, showing that data quality is a major bottleneck for video understanding in VLMs.
What carries the argument
VidGround, the selection of only visually grounded questions for post-training, which removes text-only solvable examples to force reliance on visual and temporal cues.
If this is right
- Video understanding in VLMs improves without needing more data or compute resources.
- Simple data filtering proves more effective than elaborate post-training algorithms.
- Benchmarks must be redesigned to exclude questions solvable by text alone.
- Post-training becomes more efficient by discarding non-visually grounded examples.
Where Pith is reading between the lines
- Similar filtering could be applied during pre-training to reduce shortcut learning across multimodal tasks.
- Current VLM video understanding scores may be inflated by benchmarks that allow text-only solutions.
- Automated detection of visual grounding requirements could become standard in dataset preparation pipelines.
Load-bearing premise
The method for identifying visually grounded questions accurately isolates cases that require visual input without introducing selection bias or removing useful training signal.
What would settle it
If a random subset of the same size as the visually grounded portion produces comparable performance gains, the claim that improvements stem specifically from visual grounding would be falsified.
Figures
















read the original abstract
It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports that 40-60% of questions in common long-video understanding benchmarks and post-training datasets are solvable from text alone. It introduces VidGround, a filter that retains only the visually grounded subset (69.1% of the original post-training data) and shows that, when paired with standard RL post-training, this subset yields up to +6.2 points over training on the full unfiltered set. The work further claims that this simple curation step outperforms several more elaborate post-training algorithms, positioning data quality as the primary bottleneck for video VLM performance.
Significance. If the attribution to visual grounding is substantiated, the result would be significant: it supplies concrete evidence that a large fraction of existing video benchmarks and training corpora do not actually require multimodal reasoning, and demonstrates that inexpensive filtering can produce larger gains than current algorithmic post-training innovations. This would redirect attention toward systematic dataset auditing and curation rather than solely toward new RL objectives or architectures.
major comments (3)
- [Abstract / §3] Abstract and §3 (filter construction): the paper states that 40-60% of questions are text-only solvable and that the VidGround filter removes precisely the non-grounded remainder, yet provides no description of the procedure used to label questions as text-only (model, prompt template, temperature, decision threshold, or human validation set). Without these details the claimed 69.1% retention rate and the subsequent performance numbers cannot be reproduced or stress-tested.
- [§4 / Table 2] §4 (main results) and Table 2: the headline +6.2 point gain is reported only for the VidGround subset versus the full dataset. No control experiment is shown for a random 69.1% subset, a length-matched subset, or a difficulty-matched subset. Consequently the observed lift cannot yet be attributed to removal of text-only questions rather than to incidental effects of reduced volume or altered answer distribution.
- [§4.2] §4.2 (RL post-training details): the manuscript asserts that “data curation with a simple post-training algorithm outperforms several more complex post-training techniques,” but does not list the exact RL algorithms, reward models, hyper-parameters, or training budgets used in the comparison. This omission prevents verification that the reported superiority is driven by the data filter rather than by differences in optimization setup.
minor comments (1)
- [Abstract] The project page is referenced but no supplementary material, code, or filtered dataset splits are linked in the main text, which would materially aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified important opportunities to improve the clarity, reproducibility, and evidential strength of our work. We respond to each major comment below and will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (filter construction): the paper states that 40-60% of questions are text-only solvable and that the VidGround filter removes precisely the non-grounded remainder, yet provides no description of the procedure used to label questions as text-only (model, prompt template, temperature, decision threshold, or human validation set). Without these details the claimed 69.1% retention rate and the subsequent performance numbers cannot be reproduced or stress-tested.
Authors: We agree that the absence of these implementation details limits reproducibility. In the revised manuscript we will expand §3 with a full specification of the text-only solvability labeling procedure, including the exact text-only model and version used, the complete prompt template, the temperature setting, the decision threshold or matching criterion for classifying a question as text-only solvable, and the protocol and results of any human validation performed on the automatic labels. These additions will allow independent reproduction of the 69.1% retention rate and the VidGround filter. revision: yes
-
Referee: [§4 / Table 2] §4 (main results) and Table 2: the headline +6.2 point gain is reported only for the VidGround subset versus the full dataset. No control experiment is shown for a random 69.1% subset, a length-matched subset, or a difficulty-matched subset. Consequently the observed lift cannot yet be attributed to removal of text-only questions rather than to incidental effects of reduced volume or altered answer distribution.
Authors: We acknowledge that the current results lack these controls and that they are necessary to isolate the contribution of visual grounding. In the revised version we will add an experiment using a randomly sampled 69.1% subset of the original post-training data to demonstrate that simply reducing data volume does not produce comparable gains. We will also include or discuss length-matched and difficulty-matched controls to the extent they can be constructed, along with analysis of any shifts in answer distribution, to strengthen the attribution of the observed improvements to the removal of non-grounded questions. revision: yes
-
Referee: [§4.2] §4.2 (RL post-training details): the manuscript asserts that “data curation with a simple post-training algorithm outperforms several more complex post-training techniques,” but does not list the exact RL algorithms, reward models, hyper-parameters, or training budgets used in the comparison. This omission prevents verification that the reported superiority is driven by the data filter rather than by differences in optimization setup.
Authors: We thank the referee for noting this omission. Although the comparisons were performed under a consistent post-training framework, the specific configurations were not enumerated. We will revise §4.2 to include a detailed description or table specifying the RL algorithms, reward models, all hyper-parameters, and training budgets (steps, batch sizes, learning rates, etc.) used both for the VidGround-filtered data and for the more complex post-training baselines. This will confirm that performance differences are attributable to the data curation rather than to variations in the optimization setup. revision: yes
Circularity Check
No significant circularity in empirical data filtering and RL evaluation
full rationale
The paper is an empirical study that identifies text-only answerable questions in benchmarks and post-training datasets via measurement, filters to a visually grounded subset, and applies standard RL post-training algorithms to report measured performance gains. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation chain; the central claims rest on external dataset measurements and experimental outcomes rather than reducing to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark performance scores reflect genuine improvements in visual and temporal understanding when text-only shortcuts are removed.
Forward citations
Cited by 1 Pith paper
-
RewardHarness: Self-Evolving Agentic Post-Training
RewardHarness self-evolves a tool-and-skill library from 100 preference examples to reach 47.4% accuracy on image-edit evaluation, beating GPT-5, and yields stronger RL-tuned models.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R.K., Bai, Y., Baker, B., Bao, H., et al.: gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alhamoud, K., Alshammari, S., Tian, Y., Li, G., Torr, P.H., Kim, Y., Ghassemi, M.: Vision-language models do not understand negation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29612–29622 (2025)
2025
-
[4]
Anthropic: Introducing claude sonnet 4.5 (2025),https://www.anthropic.com/ news/claude-sonnet-4-5
2025
-
[5]
Anthropic: Introducing claude opus 4.6 (2026),https://www.anthropic.com/ news/claude-opus-4-6
2026
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bahl, S., Mendonca, R., Chen, L., Jain, U., Pathak, D.: Affordances from human videos as a versatile representation for robotics. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13778–13790 (2023)
2023
-
[7]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2402.17510 (2024)
Bleeker, M., Hendriksen, M., Yates, A., de Rijke, M.: Demonstrating and reducing shortcuts in vision-language representation learning. arXiv preprint arXiv:2402.17510 (2024)
-
[9]
Advances in neural information processing systems32(2019)
Cadene, R., Dancette, C., Cord, M., Parikh, D., et al.: Rubi: Reducing unimodal biases for visual question answering. Advances in neural information processing systems32(2019)
2019
-
[10]
Advances in Neural Information Processing Systems37, 113436–113460 (2024)
Campbell, D., Rane, S., Giallanza, T., De Sabbata, C.N., Ghods, K., Joshi, A., Ku, A., Frankland, S., Griffiths, T., Cohen, J.D., et al.: Understanding the limits of vision language models through the lens of the binding problem. Advances in Neural Information Processing Systems37, 113436–113460 (2024)
2024
-
[11]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Chandhok, S., Fan, W.C., Shwartz, V., Balasubramanian, V.N., Sigal, L.: Response wide shut? surprising observations in basic vision language model capabilities. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 25530–25545 (2025)
2025
-
[12]
arXiv preprint arXiv:2504.11468 , year=
Chen, H., Tu, H., Wang, F., Liu, H., Tang, X., Du, X., Zhou, Y., Xie, C.: Sft or rl? an early investigation into training r1-like reasoning large vision-language models. arXiv preprint arXiv:2504.11468 (2025)
-
[13]
Chen, H., Razin, N., Narasimhan, K., Chen, D.: Retaining by doing: The role of on-policy data in mitigating forgetting. arXiv preprint arXiv:2510.18874 (2025)
-
[14]
Scaling rl to long videos.arXiv preprint arXiv:2507.07966, 2025
Chen, Y., Huang, W., Shi, B., Hu, Q., Ye, H., Zhu, L., Liu, Z., Molchanov, P., Kautz, J., Qi, X., et al.: Scaling rl to long videos. arXiv preprint arXiv:2507.07966 (2025)
-
[15]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Chu, T., Zhai, Y., Yang, J., Tong, S., Xie, S., Schuurmans, D., Le, Q.V., Levine, S., Ma, Y.: Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161 (2025)
work page internal anchor Pith review arXiv 2025
-
[16]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Reinforcing video reasoning with focused thinking
Dang, J., Wu, J., Wang, T., Lin, X., Zhu, N., Chen, H., Zheng, W.S., Wang, M., Chua, T.S.: Reinforcing video reasoning with focused thinking. arXiv preprint arXiv:2505.24718 (2025)
-
[18]
Electronics14(7), 1282 (2025)
Elhenawy, M., Ashqar, H.I., Rakotonirainy, A., Alhadidi, T.I., Jaber, A., Tami, M.A.: Vision-language models for autonomous driving: Clip-based dynamic scene understanding. Electronics14(7), 1282 (2025)
2025
-
[19]
Advances in Neural Information Processing Systems37, 89098–89124 (2024)
Fang, X., Mao, K., Duan, H., Zhao, X., Li, Y., Lin, D., Chen, K.: Mmbench-video: A long-form multi-shot benchmark for holistic video understanding. Advances in Neural Information Processing Systems37, 89098–89124 (2024)
2024
-
[20]
Video-R1: Reinforcing Video Reasoning in MLLMs
Feng, K., Gong, K., Li, B., Guo, Z., Wang, Y., Peng, T., Wu, J., Zhang, X., Wang, B., Yue, X.: Video-r1: Reinforcing video reasoning in mllms. arXiv preprint arXiv:2503.21776 (2025)
work page internal anchor Pith review arXiv 2025
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24108–24118 (2025)
2025
-
[22]
Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008,
Fu, S., Bonnen, T., Guillory, D., Darrell, T.: Hidden in plain sight: Vlms overlook their visual representations. arXiv preprint arXiv:2506.08008 (2025)
-
[23]
Google: Gemini 3.1 pro: Best for complex tasks and bringing creative concepts to life (2026),https://blog.google/innovation-and-ai/models-and-research/ gemini-models/gemini-3-1-pro/
2026
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6904–6913 (2017)
2017
-
[25]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Hu, K., Wu, P., Pu, F., Xiao, W., Zhang, Y., Yue, X., Li, B., Liu, Z.: Video-mmmu: Evaluating knowledge acquisition from multi-discipline professional videos. arXiv preprint arXiv:2501.13826 (2025)
work page internal anchor Pith review arXiv 2025
-
[26]
arXiv preprint arXiv:2502.11492 (2025)
Huang, K.H., Qin, C., Qiu, H., Laban, P., Joty, S., Xiong, C., Wu, C.S.: Why vision language models struggle with visual arithmetic? towards enhanced chart and geometry understanding. arXiv preprint arXiv:2502.11492 (2025)
-
[27]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visual rep- resentation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024)
2024
-
[29]
In: Findings of the Association for Computational Linguistics: NAACL 2025
Lee, K.i., Kim, M., Yoon, S., Kim, M., Lee, D., Koh, H., Jung, K.: Vlind-bench: Measuring language priors in large vision-language models. In: Findings of the Association for Computational Linguistics: NAACL 2025. pp. 4129–4144 (2025)
2025
-
[30]
In: Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval
Liang, Z., Hu, H., Zhu, J.: Lpf: A language-prior feedback objective function for de- biased visual question answering. In: Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. pp. 1955– 1959 (2021)
1955
-
[31]
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-LLaVA: Learning united visual representation by alignment before projection. In: Al- Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Processing. pp. 5971–5984. Association for Computational Linguistics, Miami, Flor...
-
[32]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 5971–5984 (2024)
2024
-
[33]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Liu, A., Mei, A., Lin, B., Xue, B., Wang, B., Xu, B., Wu, B., Zhang, B., Lin, C., Dong, C., et al.: Deepseek-v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
arXiv preprint arXiv:2501.00569 (2024)
Luo, T., Cao, A., Lee, G., Johnson, J., Lee, H.: Probing visual language priors in vlms. arXiv preprint arXiv:2501.00569 (2024)
-
[35]
In: European Conference on Computer Vision
Miller, D., S¨ underhauf, N., Kenna, A., Mason, K.: Open-set recognition in the age of vision-language models. In: European Conference on Computer Vision. pp. 1–18. Springer (2024)
2024
-
[36]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Niu, Y., Tang, K., Zhang, H., Lu, Z., Hua, X.S., Wen, J.R.: Counterfactual vqa: A cause-effect look at language bias. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12700–12710 (2021)
2021
-
[37]
OpenAI: Gpt-5.https://openai.com(2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Parashar, S., Lin, Z., Liu, T., Dong, X., Li, Y., Ramanan, D., Caverlee, J., Kong, S.: The neglected tails in vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12988–12997 (2024)
2024
-
[39]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Park, J., Jang, K.J., Alasaly, B., Mopidevi, S., Zolensky, A., Eaton, E., Lee, I., Johnson, K.: Assessing modality bias in video question answering benchmarks with multimodal large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 19821–19829 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Peng, W., Xie, S., You, Z., Lan, S., Wu, Z.: Synthesize diagnose and opti- mize: Towards fine-grained vision-language understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13279– 13288 (2024)
2024
-
[41]
In: Proceedings of the Asian Conference on Computer Vision
Rahmanzadehgervi, P., Bolton, L., Taesiri, M.R., Nguyen, A.T.: Vision language models are blind. In: Proceedings of the Asian Conference on Computer Vision. pp. 18–34 (2024)
2024
-
[42]
Advances in neural information processing systems31(2018)
Ramakrishnan, S., Agrawal, A., Lee, S.: Overcoming language priors in visual question answering with adversarial regularization. Advances in neural information processing systems31(2018)
2018
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ranasinghe, K., Shukla, S.N., Poursaeed, O., Ryoo, M.S., Lin, T.Y.: Learning to localize objects improves spatial reasoning in visual-llms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12977– 12987 (2024)
2024
-
[44]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
IEEE Transactions on Circuits and Systems for Video Technology pp
Tang, Y., Bi, J., Xu, S., Song, L., Liang, S., Wang, T., Zhang, D., An, J., Lin, J., Zhu, R., Vosoughi, A., Huang, C., Zhang, Z., Liu, P., Feng, M., Zheng, F., Zhang, J., Luo, P., Luo, J., Xu, C.: Video understanding with large language models: A survey. IEEE Transactions on Circuits and Systems for Video Technology pp. 1–1 (2025).https://doi.org/10.1109/...
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9568–9578 (2024)
2024
-
[47]
Vision Language Models are Biased
Vo, A., Nguyen, K.N., Taesiri, M.R., Dang, V.T., Nguyen, A.T., Kim, D.: Vision language models are biased. arXiv preprint arXiv:2505.23941 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Llava-critic-r1: Your critic model is secretly a strong policy model.CoRR, abs/2509.00676, 2025
Wang, X., Li, C., Yang, J., Zhang, K., Liu, B., Xiong, T., Huang, F.: Llava-critic-r1: Your critic model is secretly a strong policy model. arXiv preprint arXiv:2509.00676 (2025)
-
[49]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Wang, Z., Yoon, J., Yu, S., Islam, M.M., Bertasius, G., Bansal, M.: Video-rts: Rethinking reinforcement learning and test-time scaling for efficient and enhanced video reasoning. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 28114–28128 (2025)
2025
-
[50]
von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., Gallou´ edec, Q.: TRL: Transformer Reinforcement Learning, https://github.com/huggingface/trl
-
[51]
When language overrules: Modality imbalance in vlms.arXiv preprint arXiv:2508.10552, 2025
Wu, H., Tang, M., Zheng, X., Jiang, H.: When language overrules: Revealing text dominance in multimodal large language models. arXiv preprint arXiv:2508.10552 (2025)
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xu, Y., Zhu, L., Yang, Y.: Mc-bench: A benchmark for multi-context visual ground- ing in the era of mllms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17675–17687 (2025)
2025
-
[53]
In: The Eleventh In- ternational Conference on Learning Representations (2023),https://openreview
Xue, H., Sun, Y., Liu, B., Fu, J., Song, R., Li, H., Luo, J.: CLIP-vip: Adapting pre-trained image-text model to video-language alignment. In: The Eleventh In- ternational Conference on Learning Representations (2023),https://openreview. net/forum?id=GNjzMAgawq
2023
-
[54]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Dai, W., Fan, T., Liu, G., Liu, L., et al.: Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Zhang, G., Zhang, Y., Zhang, K., Tresp, V.: Can vision-language models be a good guesser? exploring vlms for times and location reasoning. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 636–645 (2024)
2024
-
[56]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024)
work page Pith review arXiv 2024
-
[57]
Zhang, Y., Unell, A., Wang, X., Ghosh, D., Su, Y., Schmidt, L., Yeung-Levy, S.: Why are visually-grounded language models bad at image classification? Advances in Neural Information Processing Systems37, 51727–51753 (2024)
2024
-
[58]
Gemini-1.5-Pro achieves less than 15% accuracy in the text-only setup
Zhao, Y., Zhang, H., Xie, L., Hu, T., Gan, G., Long, Y., Hu, Z., Chen, W., Li, C., Xu, Z., et al.: Mmvu: Measuring expert-level multi-discipline video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8475–8489 (2025) Appendix Appendix Overview AMulti-model agreement analysis BCross-task generalization: image QA...
2025
-
[59]
The lines are varied in direction and style, contributing significantly to the overall composition
Line: There are numerous lines used in the drawings, especially in the abstract and geometric shapes. The lines are varied in direction and style, contributing significantly to the overall composition
-
[60]
The use of shapes to create patterns and structures is evident
Shape: Shapes are also prominent, with both geometric and organic forms present. The use of shapes to create patterns and structures is evident
-
[61]
The emphasis is more on two- dimensional elements rather than creating a sense of volume through form
Form: While there are some three-dimensional elements like the cube and the sphere, they are not the main focus. The emphasis is more on two- dimensional elements rather than creating a sense of volume through form
-
[62]
The colors are bright and flat, without much shading
Value: The use of value (light and shadow) is minimal compared to other elements. The colors are bright and flat, without much shading
-
[63]
The colors are used to fill shapes and add contrast, but they do not create a strong color palette
Color: Color is present, but it is not the most dominant element. The colors are used to fill shapes and add contrast, but they do not create a strong color palette
-
[64]
The surfaces are smooth and flat
Texture: There is no significant texture in the artwork. The surfaces are smooth and flat
-
[65]
The arrangement of elements is somewhat balanced, but it is not the primary focus
Balance: The balance is somewhat achieved, but it is not the most striking feature. The arrangement of elements is somewhat balanced, but it is not the primary focus
-
[66]
The artwork does not explore depth or negative space extensively
Space: The concept of space is present, but it is not the most prominent. The artwork does not explore depth or negative space extensively
-
[67]
The colors and lines provide some contrast, but it is not the main focus
Contrast: There is some contrast, but it is not the most dominant element. The colors and lines provide some contrast, but it is not the main focus
-
[68]
Given the analysis, the most prominently featured elements are line and shape
Proportion: The proportions are somewhat consistent, but they are not the most striking feature. Given the analysis, the most prominently featured elements are line and shape. However, since the question asks for the most prominent, and considering the variety of lines and shapes, the answer leans towards: B. Shape Final answer: B. Shape To determine whic...
-
[69]
This suggests that line is a significant element in the artwork
Line: The video shows a hand drawing various types of lines such as horizontal, diagonal, curved, and dotted. This suggests that line is a significant element in the artwork
-
[70]
Shape: The video also shows the drawing of different shapes like triangles, circles, and squares, indicating that shape is another prominent element
-
[71]
Form: The video briefly shows a 3D form, which suggests that form is also an element being discussed
-
[72]
Value: The video mentions value, which refers to the lightness or darkness of a color, and shows examples of how value can be used in art
-
[73]
Color: The video includes a color wheel and discusses primary colors, indicating that color is a key element
-
[74]
Texture: The video briefly shows a textured surface, suggesting that texture is also an element being discussed
-
[75]
Balance: The video does not focus on balance as a primary element
-
[76]
Given the content of the video, the elements that are most prominently featured are likely to be those that are discussed and demonstrated in the video
Space: The video mentions space, including positive and negative space, indicating that space is a significant element. Given the content of the video, the elements that are most prominently featured are likely to be those that are discussed and demonstrated in the video. Based on the video content, the most prominent elements are: Line, Shape, Color, Tex...
-
[77]
The structure introduced at 1:18 is damaged
-
[78]
The structure introduced at 0:32 is damaged
-
[79]
The introduced at 1:10 is severed or damaged
-
[80]
The dendrites did not receive enough neurotransmitter signals to properly initiate the process
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.