Recognition: 2 theorem links
· Lean TheoremRewardHarness: Self-Evolving Agentic Post-Training
Pith reviewed 2026-05-12 01:00 UTC · model grok-4.3
The pith
A self-evolving reward framework surpasses GPT-5 on image edit evaluation using only 0.05% of typical preference data
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RewardHarness reframes reward modeling as context evolution rather than weight optimization. Given a source image, candidate edited images, and an editing instruction, an Orchestrator selects the most relevant subset of tools and skills from the maintained library, and a frozen Sub-Agent uses them to construct a reasoning chain that produces a preference judgment. By comparing predicted judgments with ground-truth preferences and analyzing successes and failures in the reasoning process, the Orchestrator automatically refines its library of tools and skills without additional human annotation.
What carries the argument
The self-evolving library of tools and skills, curated and refined by the Orchestrator through iterative comparison of the Sub-Agent's judgments against ground-truth preferences.
Load-bearing premise
That comparing the system's judgments to ground-truth preferences and analyzing reasoning successes and failures will automatically produce library refinements that improve accuracy on new cases without introducing systematic errors or bias.
What would settle it
A large set of new image-editing instructions and preference pairs on which, after multiple rounds of library evolution using only the initial 100 examples, the system's accuracy falls below GPT-5 or a non-evolving baseline.
Figures










read the original abstract
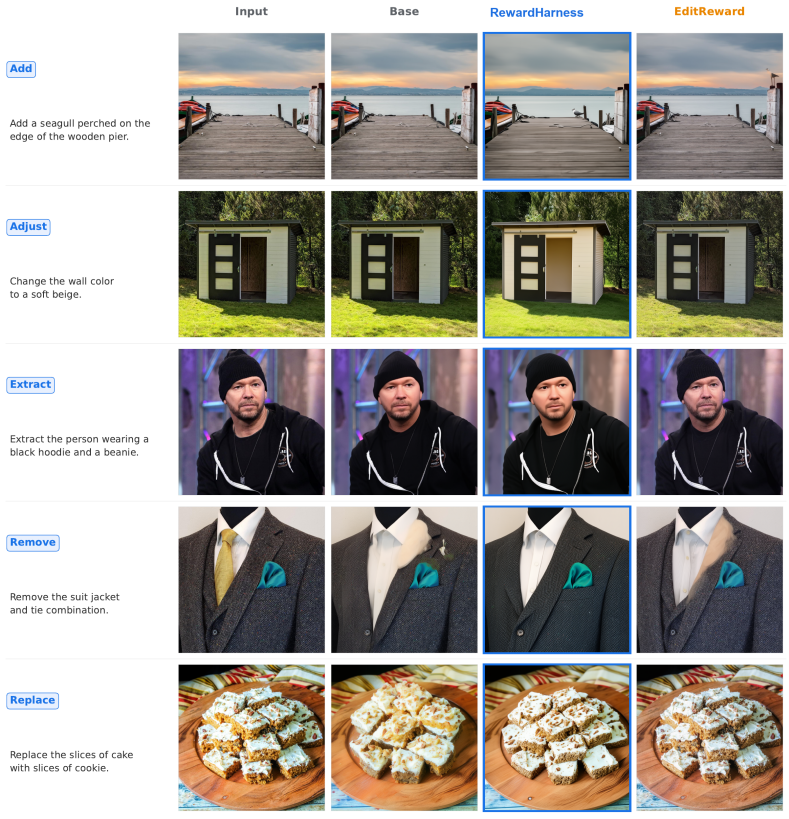
Evaluating instruction-guided image edits requires rewards that reflect subtle human preferences, yet current reward models typically depend on large-scale preference annotation and additional model training. This creates a data-efficiency gap: humans can often infer the target evaluation criteria from only a few examples, while models are usually trained on hundreds of thousands of comparisons. We present RewardHarness, a self-evolving agentic reward framework that reframes reward modeling as context evolution rather than weight optimization. Instead of learning from large-scale annotations, RewardHarness aligns with human preferences by iteratively evolving a library of tools and skills from as few as 100 preference demonstrations. Given a source image, candidate edited images, and an editing instruction, an Orchestrator selects the most relevant subset of tools and skills from the maintained library, and a frozen Sub-Agent uses them to construct a reasoning chain that produces a preference judgment. By comparing predicted judgments with ground-truth preferences and analyzing successes and failures in the reasoning process, the Orchestrator automatically refines its library of tools and skills without additional human annotation. Using only 0.05% of the EditReward preference data, RewardHarness achieves 47.4% average accuracy on image-editing evaluation benchmarks, surpassing GPT-5 by 5.3 points. When used as a reward signal for GRPO fine-tuning, RL-tuned models achieve 3.52 on ImgEdit-Bench. Project page: https://rewardharness.com.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RewardHarness, a self-evolving agentic reward framework that reframes reward modeling as iterative context evolution. From as few as 100 preference demonstrations (0.05% of EditReward data), an Orchestrator selects tools/skills from an evolving library and a frozen Sub-Agent constructs reasoning chains to produce preference judgments for image edits; the library is refined by comparing judgments to ground-truth preferences and analyzing reasoning successes/failures. The framework reports 47.4% average accuracy on image-editing benchmarks (surpassing GPT-5 by 5.3 points) and enables GRPO fine-tuning to reach 3.52 on ImgEdit-Bench.
Significance. If the self-evolution process produces generalizable preference criteria rather than dataset-specific heuristics, the approach could meaningfully advance data-efficient reward modeling for agentic systems by avoiding large-scale preference annotation and weight optimization. The reported gains from minimal data and the downstream RL improvement highlight a potentially scalable alternative to conventional reward training.
major comments (2)
- [Abstract] Abstract: The headline performance claim (47.4% accuracy from ~100 demonstrations) depends on the Orchestrator's refinement process, yet the abstract supplies no description of the evolution algorithm, initial library construction, tool/skill definitions, selection logic, or any controls (e.g., held-out validation during evolution or diversity regularization) against overfitting to the small demonstration set.
- [Abstract] Abstract: The claim that refinement occurs 'without additional human annotation' and produces genuine generalization is load-bearing for the central thesis, but no evidence or mechanism is provided showing that the initial library, failure-analysis rules, or Sub-Agent reasoning are independent of the same ~100 demonstrations, leaving open circularity risks where gains reflect self-reinforcing patterns rather than robust human-aligned criteria.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity in the abstract regarding the self-evolution mechanism. We address each major comment below, providing point-by-point responses and indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claim (47.4% accuracy from ~100 demonstrations) depends on the Orchestrator's refinement process, yet the abstract supplies no description of the evolution algorithm, initial library construction, tool/skill definitions, selection logic, or any controls (e.g., held-out validation during evolution or diversity regularization) against overfitting to the small demonstration set.
Authors: We agree that the abstract's brevity omits key operational details of the Orchestrator's refinement process. The full manuscript describes the evolution algorithm in Section 3, including initial library seeding from the 100 demonstrations, explicit tool/skill definitions, relevance-based selection logic, and safeguards such as held-out validation during iterations plus diversity regularization to limit overfitting. To improve accessibility, we will revise the abstract to include a concise, high-level summary of these components while preserving its overall length and focus on contributions. revision: yes
-
Referee: [Abstract] Abstract: The claim that refinement occurs 'without additional human annotation' and produces genuine generalization is load-bearing for the central thesis, but no evidence or mechanism is provided showing that the initial library, failure-analysis rules, or Sub-Agent reasoning are independent of the same ~100 demonstrations, leaving open circularity risks where gains reflect self-reinforcing patterns rather than robust human-aligned criteria.
Authors: The initial library is seeded from the 100 demonstrations, but the refinement mechanism operates by extracting generalizable patterns via automated analysis of reasoning successes and failures across iterative cycles; this process is independent of the original examples because it synthesizes new tool/skill abstractions. The Sub-Agent is kept frozen and is not updated on the demonstrations. Generalization is evidenced in the manuscript by strong performance on held-out portions of EditReward and disjoint benchmarks (Section 4), with ablations confirming that gains exceed those from non-evolved baselines. We will expand the abstract to briefly articulate this independence mechanism and reference the supporting generalization results. revision: partial
Circularity Check
No circularity detected in RewardHarness self-evolution claims
full rationale
The framework evolves a tool/skill library from ~100 preference demonstrations by comparing Sub-Agent judgments against ground-truth preferences and refining via success/failure analysis. Reported performance (47.4% benchmark accuracy, 3.52 on ImgEdit-Bench) is measured on separate image-editing evaluation benchmarks, not the EditReward subset used for evolution. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the abstract or described chain that would reduce outputs to inputs by construction. The external ground-truth anchor and held-out benchmarks keep the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A frozen Sub-Agent can reliably construct valid reasoning chains when supplied with tools and skills selected by the Orchestrator.
invented entities (2)
-
Orchestrator
no independent evidence
-
Sub-Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
REWARDHARNESS aligns with human preferences by iteratively evolving a library of tools and skills from as few as 100 preference demonstrations... By comparing predicted judgments with ground-truth preferences and analyzing successes and failures in the reasoning process, the Orchestrator automatically refines its library
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reframes reward modeling as context evolution rather than weight optimization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
Jiuhai Chen, Le Xue, Zhiyang Xu, Xichen Pan, Shusheng Yang, Can Qin, An Yan, Honglu Zhou, Zeyuan Chen, Lifu Huang, et al. Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
-
[2]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Yuan Gong, Xionghui Wang, Jie Wu, Shiyin Wang, Yitong Wang, and Xinglong Wu. Onereward: Unified mask-guided image generation via multi-task human preference learning.arXiv preprint arXiv:2508.21066, 2025
-
[5]
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings.Advances in neural information processing systems, 36:45870–45894, 2023
work page 2023
-
[6]
Rise: reasoning enhancement via iterative self-exploration in multi-hop question answering
Bolei He, Xinran He, Mengke Chen, Xianwei Xue, Ying Zhu, and Zhen-Hua Ling. Rise: reasoning enhancement via iterative self-exploration in multi-hop question answering. InFindings of the Association for Computational Linguistics: ACL 2025, pages 14925–14948, 2025
work page 2025
-
[7]
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024
work page 2024
-
[8]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, Keming Wu, Benjamin Schneider, Quy Duc Do, Zhuofeng Li, Yiming Jia, Yuxuan Zhang, Guo Cheng, Haozhe Wang, Wangchunshu Zhou, Qunshu Lin, Yuanxing Zhang, Ge Zhang, Wenhao Huang, and Wenhu Chen. Videoscore2: Think before you score in generative vid...
-
[9]
Genai arena: An open evaluation platform for generative models,
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.arXiv preprint arXiv:2406.04485, 2024
-
[10]
arXiv preprint arXiv:2509.01055 , year=
Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, et al. Verltool: Towards holistic agentic reinforcement learning with tool use.arXiv preprint arXiv:2509.01055, 2025
-
[11]
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36: 36652–36663, 2023
work page 2023
-
[12]
Zongjian Li, Zheyuan Liu, Qihui Zhang, Bin Lin, Feize Wu, Shenghai Yuan, Zhiyuan Yan, Yang Ye, Wangbo Yu, Yuwei Niu, et al. Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888, 2025
-
[13]
Rich human feedback for text-to-image generation
Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, Junjie Ke, Krishnamurthy Dj Dvijotham, Katie Collins, Yiwen Luo, Yang Li, Kai J Kohlhoff, Deepak Ramachandran, and Vidhya Navalpakkam. Rich human feedback for text-to-image generation. InProceedings of the IEEE/CVF Confe...
work page 2024
-
[14]
arXiv preprint arXiv:2511.19900 , year=
Jiaqi Liu, Kaiwen Xiong, Peng Xia, Yiyang Zhou, Haonian Ji, Lu Feng, Siwei Han, Mingyu Ding, and Huaxiu Yao. Agent0-vl: Exploring self-evolving agent for tool-integrated vision-language reasoning.arXiv preprint arXiv:2511.19900, 2025
-
[15]
arXiv preprint arXiv:2601.02553 , year=
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553, 2026
-
[16]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
arXiv preprint arXiv:2509.23909 (2025)
Xin Luo, Jiahao Wang, Chenyuan Wu, Shitao Xiao, Xiyan Jiang, Defu Lian, Jiajun Zhang, Dong Liu, et al. Editscore: Unlocking online rl for image editing via high-fidelity reward modeling.arXiv preprint arXiv:2509.23909, 2025
-
[18]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis, 2023.arXiv preprint arXiv:2305.15334, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Scope: Prompt evolution for enhancing agent effectiveness.arXiv preprint arXiv:2512.15374, 2025
Zehua Pei, Hui-Ling Zhen, Shixiong Kai, Sinno Jialin Pan, Yunhe Wang, Mingxuan Yuan, and Bei Yu. Scope: Prompt evolution for enhancing agent effectiveness.arXiv preprint arXiv:2512.15374, 2025
-
[20]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Chi Ruan, Dongfu Jiang, Huaye Zeng, Ping Nie, and Wenhu Chen. Evolvecoder: Evolving test cases via adversarial verification for code reinforcement learning.arXiv preprint arXiv:2603.12698, 2026
-
[22]
Samin Mahdizadeh Sani, Max Ku, Nima Jamali, Matina Mahdizadeh Sani, Paria Khoshtab, Wei-Chieh Sun, Parnian Fazel, Zhi Rui Tam, Thomas Chong, Edisy Kin Wai Chan, et al. Imagenworld: Stress-testing image generation models with explainable human evaluation on open-ended real-world tasks.arXiv preprint arXiv:2603.27862, 2026
-
[23]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[24]
Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[25]
Worldpm: Scaling human preference modeling.arXiv preprint arXiv:2505.10527, 2025
Binghai Wang, Runji Lin, Keming Lu, Le Yu, Zhenru Zhang, Fei Huang, Chujie Zheng, Kai Dang, Yang Fan, Xingzhang Ren, et al. Worldpm: Scaling human preference modeling.arXiv preprint arXiv:2505.10527, 2025
-
[26]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I Wang. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
arXiv preprint arXiv:2509.26346 (2025)
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editreward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[30]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning
Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, and Huaxiu Yao. Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning.arXiv preprint arXiv:2511.16043, 2025
-
[32]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review arXiv 2026
-
[33]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
work page 2023
-
[34]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation.arXiv preprint arXiv:2412.21059, 2024
-
[35]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[37]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark, 2025. URLhttps://arxiv.org/abs/2505.20275
work page internal anchor Pith review arXiv 2025
-
[38]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[39]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
work page 2022
-
[40]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review arXiv 2025
-
[41]
Watch Before You Answer: Learning from Visually Grounded Post-Training
Yuxuan Zhang, EunJeong Hwang, Huaisong Zhang, Penghui Du, Yiming Jia, Dongfu Jiang, Xuan He, Shenhui Zhang, Ping Nie, Peter West, et al. Watch before you answer: Learning from visually grounded post-training.arXiv preprint arXiv:2604.05117, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[43]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025. 11 A Related Work (Extended) A.1 Reward Models for Visual Generation Reward modeling has become a standard approach for al...
work page internal anchor Pith review arXiv 2025
-
[44]
Cartoonish or heavily stylized outputs score 1–2
Cartoonish Edits: If the source is a realistic photo, the edit MUST maintain realism unless a style change is requested. Cartoonish or heavily stylized outputs score 1–2
-
[45]
Hallucinated Text: Unrequested, misspelled, or gibberish text is a severe artifact; penalize heavily
-
[46]
Over-editing: Adding unrequested elements violates the ‘Exclusivity of Edit’ principle. Skill: realism-and-artifact-penalties (iter 69, refined) description: Guidance on penalizing artifacts while allowing conceptual unrealism if requested by the prompt. # Realism and Artifact Penalties
-
[47]
Conceptual Unrealism vs. Artifacts: If the prompt requests a surreal/ impossible scenario (e.g., ‘polar bears in a savannah’ ), DO NOT penalize for being unrealistic
-
[48]
Penalize Visual Artifacts: Bad blending, floating objects, distorted textures, warped faces
-
[49]
polar bears in a grassy savannah
Prioritize Execution Quality: Prefer fewer artifacts over strict prompt compliance. Figure 9: Evolution of realism-and-artifact-penalties skill. Comparison between iteration 2 (left) and iteration 69 (right). The initial version broadly penalizes cartoonish or unrealistic outputs regardless of intent. The refined version introduces an explicit carve-out t...
-
[50]
query”: “Is this image completely black or corrupted?
Black-Image Hallucination: Never assume an image is completely black. If suspected, MUST call visual-qa-tool: {“query”: “Is this image completely black or corrupted?”}
-
[51]
Use text-and-ocr-analyzer to read the exact spelling before judging
Text Hallucination: Never guess exact text. Use text-and-ocr-analyzer to read the exact spelling before judging
-
[52]
a clear plastic bottle with a nipple
Subtle Object Details: For prompts specifying fine-grained attributes (e.g., “a clear plastic bottle with a nipple”, “home plate”), call visual-qa-tool to confirm presence before scoring. CRITICAL: Tool results override your internal perception. If a tool says the image is not black, accept that result even if you initially perceived it as black. Figure 1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.