Recognition: no theorem link
CoEnv: Driving Embodied Multi-Agent Collaboration via Compositional Environment
Pith reviewed 2026-05-10 19:23 UTC · model grok-4.3
The pith
A compositional environment blending real and simulated components lets multiple robots coordinate safely in shared workspaces through scene reconstruction, vision-language planning, and validated transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
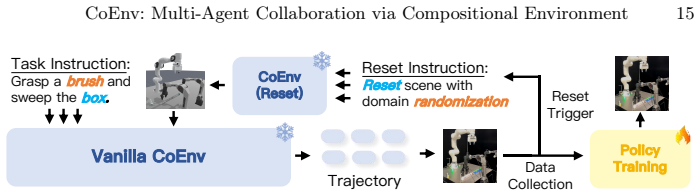
The authors establish that a synergistic integration of real-world and simulation components, called the compositional environment, creates a unified decision-making space in which multiple robotic agents perceive intentions and coordinate actions. This integration is implemented via real-to-sim scene reconstruction, VLM-driven action synthesis for both real-time high-level interfaces and iterative code-based trajectory generation, and validated sim-to-real transfer that includes collision detection, yielding high task success rates and execution efficiency on multi-arm manipulation benchmarks.
What carries the argument
The compositional environment, defined as the integration of real-world and simulation components that forms a single space for agents to perceive intentions and decide jointly.
If this is right
- High success rates on challenging multi-arm manipulation benchmarks.
- Improved execution efficiency during collaborative tasks in shared spaces.
- Safe exploration of strategies inside simulation before physical deployment.
- Support for both quick high-level planning and detailed iterative trajectory generation in the same framework.
Where Pith is reading between the lines
- If extended, the same three-stage structure might apply to collaborative navigation or assembly tasks outside the tested manipulation benchmarks.
- The framework could be evaluated with larger robot teams or different hardware to check whether the unified space scales without added coordination overhead.
- This separation of planning from execution might allow existing single-robot systems to gain awareness benefits by temporarily borrowing simulated companions.
- Broader adoption could reduce custom coding needs for new multi-agent tasks if the vision-language synthesis generalizes across environments.
Load-bearing premise
Vision-language models can produce reliable real-time high-level plans and iterative code-based trajectories for complex spatial coordination and temporal reasoning without generating unsafe or infeasible actions.
What would settle it
A deployment trial in which simulation-validated plans produce collisions or task failures when executed by the physical robots, or measured success rates on the multi-arm benchmarks fall well below the reported levels.
Figures





read the original abstract
Multi-agent embodied systems hold promise for complex collaborative manipulation, yet face critical challenges in spatial coordination, temporal reasoning, and shared workspace awareness. Inspired by human collaboration where cognitive planning occurs separately from physical execution, we introduce the concept of compositional environment -- a synergistic integration of real-world and simulation components that enables multiple robotic agents to perceive intentions and operate within a unified decision-making space. Building on this concept, we present CoEnv, a framework that leverages simulation for safe strategy exploration while ensuring reliable real-world deployment. CoEnv operates through three stages: real-to-sim scene reconstruction that digitizes physical workspaces, VLM-driven action synthesis supporting both real-time planning with high-level interfaces and iterative planning with code-based trajectory generation, and validated sim-to-real transfer with collision detection for safe deployment. Extensive experiments on challenging multi-arm manipulation benchmarks demonstrate CoEnv's effectiveness in achieving high task success rates and execution efficiency, establishing a new paradigm for multi-agent embodied AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the concept of a compositional environment integrating real-world and simulation components for multi-agent robotic collaboration, and presents the CoEnv framework operating in three stages: real-to-sim scene reconstruction, VLM-driven action synthesis (for both real-time high-level planning and iterative code-based trajectory generation), and validated sim-to-real transfer with collision detection. It claims that extensive experiments on challenging multi-arm manipulation benchmarks demonstrate high task success rates and execution efficiency, establishing a new paradigm for multi-agent embodied AI.
Significance. If the experimental results hold with proper quantitative validation, the framework's separation of cognitive planning (via VLMs and simulation) from physical execution could provide a practical method for improving safety and coordination in shared workspaces, advancing embodied multi-agent systems beyond current sim-to-real approaches.
major comments (2)
- [Abstract] Abstract: The claim that 'extensive experiments on challenging multi-arm manipulation benchmarks demonstrate CoEnv's effectiveness in achieving high task success rates and execution efficiency' provides no numerical results, baselines, error bars, ablation studies, or statistical details. This is load-bearing for the central effectiveness claim, as success rates cannot be attributed to the compositional environment or VLM synthesis without such evidence.
- [Method (VLM-driven action synthesis)] VLM-driven action synthesis description: The framework asserts that VLM supports both real-time planning with high-level interfaces and iterative planning with code-based trajectory generation while avoiding unsafe or infeasible actions in shared workspaces, but reports no VLM error rates, prompt details, or ablation removing the collision-detection guard. This directly impacts the reliability of sim-to-real transfer and the attribution of results to the proposed concept.
minor comments (1)
- [Introduction] The distinction between the introduced 'compositional environment' and standard sim-to-real pipelines could be formalized with a precise definition or diagram to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important opportunities to strengthen the presentation of quantitative evidence and methodological transparency. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'extensive experiments on challenging multi-arm manipulation benchmarks demonstrate CoEnv's effectiveness in achieving high task success rates and execution efficiency' provides no numerical results, baselines, error bars, ablation studies, or statistical details. This is load-bearing for the central effectiveness claim, as success rates cannot be attributed to the compositional environment or VLM synthesis without such evidence.
Authors: We agree that the abstract would be strengthened by including specific quantitative results to support the effectiveness claims. The full manuscript reports detailed success rates, baseline comparisons, and efficiency metrics in the experiments section, but these were not summarized numerically in the abstract. In the revised version, we will update the abstract to concisely include key results (e.g., task success rates on multi-arm benchmarks, comparisons to baselines, and efficiency gains) while maintaining brevity. This directly addresses the concern about attribution to the compositional environment and VLM components. revision: yes
-
Referee: [Method (VLM-driven action synthesis)] VLM-driven action synthesis description: The framework asserts that VLM supports both real-time planning with high-level interfaces and iterative planning with code-based trajectory generation while avoiding unsafe or infeasible actions in shared workspaces, but reports no VLM error rates, prompt details, or ablation removing the collision-detection guard. This directly impacts the reliability of sim-to-real transfer and the attribution of results to the proposed concept.
Authors: We acknowledge that additional details on the VLM component would improve transparency. The manuscript describes the dual planning modes and collision-detection mechanism in the method section, but does not isolate VLM-specific error rates or provide an explicit ablation on the guard. In revision, we will add the exact prompts used for high-level planning and code generation to the appendix. We will also report observed VLM failure cases from the experimental trials and include a targeted ablation removing the collision-detection guard to quantify its role in safe transfer. These changes will be placed in the method and experiments sections to better support attribution. revision: partial
Circularity Check
Framework proposal is self-contained with no circular derivations
full rationale
The paper describes a conceptual three-stage pipeline (real-to-sim reconstruction, VLM-driven action synthesis, sim-to-real transfer) for multi-agent collaboration without any equations, fitted parameters, or mathematical derivations. No load-bearing steps reduce claims to self-referential inputs by construction, and the experimental validation on benchmarks is presented as empirical evidence rather than tautological output. Any self-citations (if present in the full text) do not form the central premise or forbid alternatives, keeping the derivation chain independent.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can generate safe and effective action plans for multi-agent robotic tasks when provided high-level interfaces or code-based trajectories
- domain assumption Real-to-sim scene reconstruction accurately digitizes physical workspaces for strategy exploration
invented entities (1)
-
compositional environment
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the first international joint conference on Autonomous agents and multiagent systems: part
Agassounon, W., Martinoli, A.: Efficiency and robustness of threshold-based dis- tributed allocation algorithms in multi-agent systems. In: Proceedings of the first international joint conference on Autonomous agents and multiagent systems: part
-
[2]
1090–1097 (2002)
pp. 1090–1097 (2002)
2002
-
[3]
AgileX Robotics: Piper sdk.https://github.com/agilexrobotics/piper_sdk (2024)
2024
-
[4]
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.,
Ahn, M., Dwibedi, D., Finn, C., Arenas, M.G., Gopalakrishnan, K., Hausman, K., Ichter, B., Irpan, A., Joshi, N., Julian, R., et al.: Autort: Embodied foun- dation models for large scale orchestration of robotic agents. arXiv preprint arXiv:2401.12963 (2024)
-
[5]
Anthropic: Claude code.https://claude.ai/product/claude-code(2025)
2025
-
[6]
Towards a unified understanding of robot ma- nipulation: A comprehensive survey,
Bai, S., Song, W., Chen, J., Ji, Y., Zhong, Z., Yang, J., Zhao, H., Zhou, W., Zhao, W., Li, Z., et al.: Towards a unified understanding of robot manipulation: A comprehensive survey. arXiv preprint arXiv:2510.10903 (2025)
-
[7]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Gr-3 technical report.arXiv preprint arXiv:2507.15493,
Cheang, C., Chen, S., Cui, Z., Hu, Y., Huang, L., Kong, T., Li, H., Li, Y., Liu, Y., Ma, X., et al.: Gr-3 technical report. arXiv preprint arXiv:2507.15493 (2025)
-
[9]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y., Li, Z., Liang, Q., Lin, X., Ge, Y., Gu, Z., et al.: Robotwin 2.0: A scalable data generator and benchmark with strong 16 L. Kang et al. domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088 (2025)
work page internal anchor Pith review arXiv 2025
-
[10]
Computers in Biology and Medicine 163, 107121 (2023)
Chen, Z., Marzullo, A., Alberti, D., Lievore, E., Fontana, M., De Cobelli, O., Musi, G., Ferrigno, G., De Momi, E.: Frsr: Framework for real-time scene reconstruction in robot-assisted minimally invasive surgery. Computers in Biology and Medicine 163, 107121 (2023)
2023
-
[11]
International Journal of Robotics and Simulation6(1), 89–102 (2024)
Chukwurah, N., Adebayo, A.S., Ajayi, O.O.: Sim-to-real transfer in robotics: Ad- dressing the gap between simulation and real-world performance. International Journal of Robotics and Simulation6(1), 89–102 (2024)
2024
-
[12]
arXiv preprint arXiv:2410.07408 (2024) 16 Y
Dai, T., Wong, J., Jiang, Y., Wang, C., Gokmen, C., Zhang, R., Wu, J., Fei-Fei, L.: Automated creation of digital cousins for robust policy learning. arXiv preprint arXiv:2410.07408 (2024)
-
[13]
arXiv preprint arXiv:2505.07096 (2025)
Dan, P., Kedia, K., Chao, A., Duan, E.W., Pace, M.A., Ma, W.C., Choud- hury, S.: X-sim: Cross-embodiment learning via real-to-sim-to-real. arXiv preprint arXiv:2505.07096 (2025)
-
[14]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review arXiv 2023
-
[15]
arXiv preprint arXiv:2509.20021 (2025)
Feng,T.,Wang,X.,Jiang,Y.G.,Zhu,W.:Embodiedai:Fromllmstoworldmodels. arXiv preprint arXiv:2509.20021 (2025)
-
[16]
Multi-agent embodied ai: Advances and future directions.arXiv preprint arXiv:2505.05108,
Feng, Z., Xue, R., Yuan, L., Yu, Y., Ding, N., Liu, M., Gao, B., Sun, J., Zheng, X., Wang, G.: Multi-agent embodied ai: Advances and future directions. arXiv preprint arXiv:2505.05108 (2025)
-
[17]
The International journal of robotics research23(9), 939–954 (2004)
Gerkey, B.P., Matarić, M.J.: A formal analysis and taxonomy of task allocation in multi-robot systems. The International journal of robotics research23(9), 939–954 (2004)
2004
-
[18]
In: Findings of the Association for Computational Linguistics: NAACL 2024
Gong, R., Huang, Q., Ma, X., Noda, Y., Durante, Z., Zheng, Z., Terzopoulos, D., Fei-Fei, L., Gao, J., Vo, H.: Mindagent: Emergent gaming interaction. In: Findings of the Association for Computational Linguistics: NAACL 2024. pp. 3154–3183 (2024)
2024
- [19]
-
[20]
Han, X., Liu, M., Chen, Y., Yu, J., Lyu, X., Tian, Y., Wang, B., Zhang, W., Pang, J.: Re3sim: Generating high-fidelity simulation data via 3d-photorealistic real-to-sim for robotic manipulation. arXiv preprint arXiv:2502.08645 (2025)
-
[21]
IEEE Transactions on Robotics39(2), 1225–1243 (2022)
Horváth, D., Erdős, G., Istenes, Z., Horváth, T., Földi, S.: Object detection using sim2real domain randomization for robotic applications. IEEE Transactions on Robotics39(2), 1225–1243 (2022)
2022
-
[22]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dhabalia, K., DiCarlo, J., et al.:π∗ 0.6: a VLA that learns from experience. arXiv preprint arXiv:2511.14759 (2025)
work page Pith review arXiv 2025
-
[23]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
The International journal of robotics research32(12), 1495–1512 (2013)
Korsah, G.A., Stentz, A., Dias, M.B.: A comprehensive taxonomy for multi-robot task allocation. The International journal of robotics research32(12), 1495–1512 (2013)
2013
-
[25]
Li, J., Chen, P., Wu, S., Zheng, C., Xu, H., Jia, J.: Robocoder: Robotic learn- ing from basic skills to general tasks with large language models. arXiv preprint arXiv:2406.03757 (2024) CoEnv: Multi-Agent Collaboration via Compositional Environment 17
-
[26]
Controlvla: Few-shot object-centric adaptation for pre-trained vision- language-action models,
Li, P., Wu, Y., Xi, Z., Li, W., Huang, Y., Zhang, Z., Chen, Y., Wang, J., Zhu, S.C., Liu, T., et al.: Controlvla: Few-shot object-centric adaptation for pre-trained vision-language-action models. arXiv preprint arXiv:2506.16211 (2025)
-
[27]
Vision-language foundation models as effective robot imitators.arXiv preprint arXiv:2311.01378, 2023
Li, X., Liu, M., Zhang, H., Yu, C., Xu, J., Wu, H., Cheang, C., Jing, Y., Zhang, W., Liu, H., et al.: Vision-language foundation models as effective robot imitators. arXiv preprint arXiv:2311.01378 (2023)
-
[28]
IEEE/CAA Journal of Automatica Sinica12(6), 1095–1116 (2025)
Li, Z., Wu, W., Guo, Y., Sun, J., Han, Q.L.: Embodied multi-agent systems: A review. IEEE/CAA Journal of Automatica Sinica12(6), 1095–1116 (2025)
2025
-
[29]
In: 2023 IEEE International conference on robotics and automation (ICRA)
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., Zeng, A.: Code as policies: Language model programs for embodied control. In: 2023 IEEE International conference on robotics and automation (ICRA). pp. 9493–9500. IEEE (2023)
2023
-
[30]
Liu, H., Yao, S., Chen, H., Gao, J., Mao, J., Huang, J.B., Du, Y.: Simpact: Simulation-enabled action planning using vision-language models. arXiv preprint arXiv:2512.05955 (2025)
-
[31]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, S., Wu, L., Li, B., Tan, H., Chen, H., Wang, Z., Xu, K., Su, H., Zhu, J.: Rdt-1b: a diffusion foundation model for bimanual manipulation. arXiv preprint arXiv:2410.07864 (2024)
work page internal anchor Pith review arXiv 2024
-
[32]
In: Robotics: Science and Systems
Liu, X., Li, X., Guo, D., Tan, S., Liu, H., Sun, F.: Embodied multi-agent task planning from ambiguous instruction. In: Robotics: Science and Systems. pp. 1–14 (2022)
2022
-
[33]
IEEE/ASME Transactions on Mechatronics (2025)
Liu, Y., Chen, W., Bai, Y., Liang, X., Li, G., Gao, W., Lin, L.: Aligning cyber space with physical world: A comprehensive survey on embodied ai. IEEE/ASME Transactions on Mechatronics (2025)
2025
-
[34]
In: 3rd RSS workshop on dexterous manipulation: learning and control with diverse data (2025)
Lou, H., Zhang, M., Geng, H., Zhou, H., He, S., Gao, Z., Zhao, S., Mao, J., Abbeel, P., Malik, J., et al.: Dream: Differentiable real-to-sim-to-real engine for learning robotic manipulation. In: 3rd RSS workshop on dexterous manipulation: learning and control with diverse data (2025)
2025
-
[35]
RSS (2024)
Ma, J., Liang, W., Wang, H.J., Zhu, Y., Fan, L., Bastani, O., Jayaraman, D.: Dreureka: Language model guided sim-to-real transfer. RSS (2024)
2024
-
[36]
In: 2024 IEEE International Conference on Robotics and Au- tomation (ICRA)
Mandi, Z., Jain, S., Song, S.: RoCo: Dialectic multi-robot collaboration with large language models. In: 2024 IEEE International Conference on Robotics and Au- tomation (ICRA). pp. 286–299. IEEE (2024)
2024
-
[37]
In: 2022 International conference on robotics and automation (ICRA)
Mandi, Z., Liu, F., Lee, K., Abbeel, P.: Towards more generalizable one-shot visual imitation learning. In: 2022 International conference on robotics and automation (ICRA). pp. 2434–2444. IEEE (2022)
2022
-
[38]
Journal of Guidance, Control, and Dynamics30(4), 1193–1197 (2007)
Markley, F.L., Cheng, Y., Crassidis, J.L., Oshman, Y.: Averaging quaternions. Journal of Guidance, Control, and Dynamics30(4), 1193–1197 (2007)
2007
-
[39]
arXiv preprint arXiv:2509.18597 (2025)
Meng, Y., Sun, Z., Fest, M., Li, X., Bing, Z., Knoll, A.: Growing with your embod- ied agent: A human-in-the-loop lifelong code generation framework for long-horizon manipulation skills. arXiv preprint arXiv:2509.18597 (2025)
-
[40]
JEPA-VLA: Video predictive embedding is needed for VLA models.arXiv preprint arXiv:2602.11832,
Miao, S., Feng, N., Wu, J., Lin, Y., He, X., Li, D., Long, M.: Jepa-vla: Video predictive embedding is needed for vla models. arXiv preprint arXiv:2602.11832 (2026)
-
[41]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mittal, M., Roth, P., Tigue, J., Richard, A., Zhang, O., Du, P., Serrano-Munoz, A., Yao, X., Zurbrügg, R., Rudin, N., et al.: Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning. arXiv preprint arXiv:2511.04831 (2025)
work page internal anchor Pith review arXiv 2025
-
[42]
Mu, T., Ling, Z., Xiang, F., Yang, D., Li, X., Tao, S., Huang, Z., Jia, Z., Su, H.: Maniskill: Generalizable manipulation skill benchmark with large-scale demonstra- tions. arXiv preprint arXiv:2107.14483 (2021) 18 L. Kang et al
-
[43]
Frontiers in Robotics and AI9, 799893 (2022)
Muratore, F., Ramos, F., Turk, G., Yu, W., Gienger, M., Peters, J.: Robot learning from randomized simulations: A review. Frontiers in Robotics and AI9, 799893 (2022)
2022
-
[44]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
Nasiriany, S., Maddukuri, A., Zhang, L., Parikh, A., Lo, A., Joshi, A., Mandlekar, A., Zhu, Y.: Robocasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523 (2024)
work page internal anchor Pith review arXiv 2024
-
[45]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qin, Y., Kang, L., Song, X., Yin, Z., Liu, X., Liu, X., Zhang, R., Bai, L.: Robofac- tory: Exploring embodied agent collaboration with compositional constraints. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10075–10085 (2025)
2025
-
[46]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
work page Pith review arXiv 2024
-
[47]
arXiv preprint arXiv:2508.13073 (2025)
Shao, R., Li, W., Zhang, L., Zhang, R., Liu, Z., Chen, R., Nie, L.: Large vlm-based vision-language-action models for robotic manipulation: A survey. arXiv preprint arXiv:2508.13073 (2025)
-
[48]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
In: 2025 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS)
Singh, H., Das, R.J., Han, M., Nakov, P., Laptev, I.: Malmm: Multi-agent large language models for zero-shot robotic manipulation. In: 2025 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS). pp. 20386–20393. IEEE (2025)
2025
-
[50]
Geovla: Em- powering 3d representations in vision-language-action models,
Sun, L., Xie, B., Liu, Y., Shi, H., Wang, T., Cao, J.: Geovla: Empowering 3d representations in vision-language-action models. arXiv preprint arXiv:2508.09071 (2025)
-
[51]
Available: https://arxiv.org/abs/2505.03673
Tan, H., Hao, X., Chi, C., Lin, M., Lyu, Y., Cao, M., Liang, D., Chen, Z., Lyu, M., Peng, C., et al.: Roboos: A hierarchical embodied framework for cross-embodiment and multi-agent collaboration. arXiv preprint arXiv:2505.03673 (2025)
-
[52]
Tao, S., Xiang, F., Shukla, A., Qin, Y., Hinrichsen, X., Yuan, X., Bao, C., Lin, X., Liu, Y., Chan, T.k., et al.: Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai. arXiv preprint arXiv:2410.00425 (2024)
-
[53]
Team, G.A.: Gen-0: Embodied foundation models that scale with physical interac- tion.GeneralistAIBlog(2025),https://generalistai.com/blog/nov-04-2025-GEN-0
2025
-
[54]
Octo: An Open-Source Generalist Robot Policy
Team, O.M., Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., et al.: Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213 (2024)
work page internal anchor Pith review arXiv 2024
-
[55]
Tian, Y., Yang, Y., Xie, Y., Cai, Z., Shi, X., Gao, N., Liu, H., Jiang, X., Qiu, Z., Yuan, F., et al.: Interndata-a1: Pioneering high-fidelity synthetic data for pre- training generalist policy. arXiv preprint arXiv:2511.16651 (2025)
-
[56]
In: 2012 IEEE/RSJ international conference on intelligent robots and systems
Todorov, E., Erez, T., Tassa, Y.: Mujoco: A physics engine for model-based control. In: 2012 IEEE/RSJ international conference on intelligent robots and systems. pp. 5026–5033. IEEE (2012)
2012
-
[57]
In: 9th Annual Confer- ence on Robot Learning (2025)
Wan, W., Fu, J., Yuan, X., Zhu, Y., Su, H.: Lodestar: long-horizon dexterity via synthetic data augmentation from human demonstrations. In: 9th Annual Confer- ence on Robot Learning (2025)
2025
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, Y., Zhu, H., Liu, M., Yang, J., Fang, H.S., He, T.: Vq-vla: Improving vision-language-action models via scaling vector-quantized action tokenizers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11089–11099 (2025) CoEnv: Multi-Agent Collaboration via Compositional Environment 19
2025
-
[59]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wen, B., Yang, W., Kautz, J., Birchfield, S.: Foundationpose: Unified 6d pose esti- mation and tracking of novel objects. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17868–17879 (2024)
2024
-
[60]
arXiv preprint arXiv:2601.18692 (2026)
Wu, W., Lu, F., Wang, Y., Yang, S., Liu, S., Wang, F., Zhu, Q., Sun, H., Wang, Y., Ma, S., et al.: A pragmatic vla foundation model. arXiv preprint arXiv:2601.18692 (2026)
-
[61]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiang, F., Qin, Y., Mo, K., Xia, Y., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y., Wang, H., et al.: Sapien: A simulated part-based interactive environment. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11097–11107 (2020)
2020
-
[62]
Neurocomputing638, 129963 (2025)
Xiao, X., Liu, J., Wang, Z., Zhou, Y., Qi, Y., Jiang, S., He, B., Cheng, Q.: Robot learning in the era of foundation models: A survey. Neurocomputing638, 129963 (2025)
2025
-
[63]
Robotic Control via Embodied Chain-of-Thought Reasoning
Zawalski,M.,Chen,W.,Pertsch,K.,Mees,O.,Finn,C.,Levine,S.:Roboticcontrol via embodied chain-of-thought reasoning. arXiv preprint arXiv:2407.08693 (2024)
work page internal anchor Pith review arXiv 2024
-
[64]
Building cooperative embodied agents modularly with large language models
Zhang, H., Du, W., Shan, J., Zhou, Q., Du, Y., Tenenbaum, J.B., Shu, T., Gan, C.: Building cooperative embodied agents modularly with large language models. arXiv preprint arXiv:2307.02485 (2023)
-
[65]
Zhao, H., Zeng, C., Zhuang, L., Zhao, Y., Xue, S., Wang, H., Zhao, X., Li, Z., Li, K., Huang, S., et al.: High-fidelity simulated data generation for real-world zero-shot robotic manipulation learning with gaussian splatting. arXiv preprint arXiv:2510.10637 (2025)
-
[66]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhao, Q., Lu, Y., Kim, M.J., Fu, Z., Zhang, Z., Wu, Y., Li, Z., Ma, Q., Han, S., Finn, C., et al.: Cot-vla: Visual chain-of-thought reasoning for vision-language- action models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1702–1713 (2025)
2025
-
[67]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Zhen, H., Qiu, X., Chen, P., Yang, J., Yan, X., Du, Y., Hong, Y., Gan, C.: 3d-vla: A 3d vision-language-action generative world model. arXiv preprint arXiv:2403.09631 (2024)
work page internal anchor Pith review arXiv 2024
-
[68]
Zhou, E., An, J., Chi, C., Han, Y., Rong, S., Zhang, C., Wang, P., Wang, Z., Huang, T., Sheng, L., et al.: Roborefer: Towards spatial referring with reasoning in vision-language models for robotics. arXiv preprint arXiv:2506.04308 (2025)
-
[69]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhou, E., Su, Q., Chi, C., Zhang, Z., Wang, Z., Huang, T., Sheng, L., Wang, H.: Code-as-monitor: Constraint-aware visual programming for reactive and proactive robotic failure detection. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 6919–6929 (2025)
2025
-
[70]
IEEE Robotics and Automation Letters (2025)
Zhu, S., Mou, L., Li, D., Ye, B., Huang, R., Zhao, H.: Vr-robo: A real-to-sim-to- real framework for visual robot navigation and locomotion. IEEE Robotics and Automation Letters (2025)
2025
-
[71]
Viola: Imitation learning for vision- based manipulation with object proposal priors
Zhu, Y., Joshi, A., Stone, P., Zhu, Y.: Viola: Imitation learning for vision-based manipulation with object proposal priors. arXiv preprint arXiv:2210.11339 (2022)
-
[72]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) 20 L. Kang et al. Supplementary Material A Task Descriptions Table 4 summarizes the five evaluation tasks ...
2023
-
[73]
type": "CAMERA_ORBIT
Request a different view (RECOMMENDED): {"type": "CAMERA_ORBIT", "params": {"yaw": X.XX, "pitch": X.XX}, "reason": "why this angle helps"}
-
[74]
Or declare planning complete: PLANNING_COMPLETE <key_observations> Critical findings for execution: - Object positions and orientations - Chosen grasp strategy - Key constraints (clearances, collision avoidance) </key_observations> <checkpoints> Steps requiring verification before proceeding: - CP1: what to verify Position: xyz within 0.02m? CoEnv: Multi-...
-
[75]
[Robot X] MOVE + ROTATE - reason
-
[76]
[Robot X] GRASP - CHECKPOINT CP1
-
[77]
The output format is given in Prompt 4
[Robot X] MOVE (lift) + MOVE (transport) + RELEASE Multi-robot coordination: MERGE synchronized actions into ONE step SEPARATE for different actions or verification </execution_plan> </next_action> Prompt 2:Planning Output Format Execution Phase Prompt.The following box shows the full execution prompt skeleton. The output format is given in Prompt 4. You ...
-
[78]
Position: error > 0.02m -> MOVE to correct first
-
[79]
Orientation: error > 0.1 rad -> ROTATE first
-
[80]
Do NOT combine when visual verification is needed
Visual: CAMERA_ORBIT to confirm object between fingers # Multiple Actions in One Output Combine when safe (e.g., ROTATE -> MOVE -> GRASP). Do NOT combine when visual verification is needed. # Output Format => See Prompt 4 Prompt 3:Execution Phase: Full Prompt Structure <observation> What you see: - Where are the target object and gripper? - Cross-check: d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.