Recognition: no theorem link
Label Effects: Shared Heuristic Reliance in Trust Assessment by Humans and LLM-as-a-Judge
Pith reviewed 2026-05-10 19:34 UTC · model grok-4.3
The pith
Both humans and LLMs assign higher trust to identical information when labeled human-authored than when labeled AI-generated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
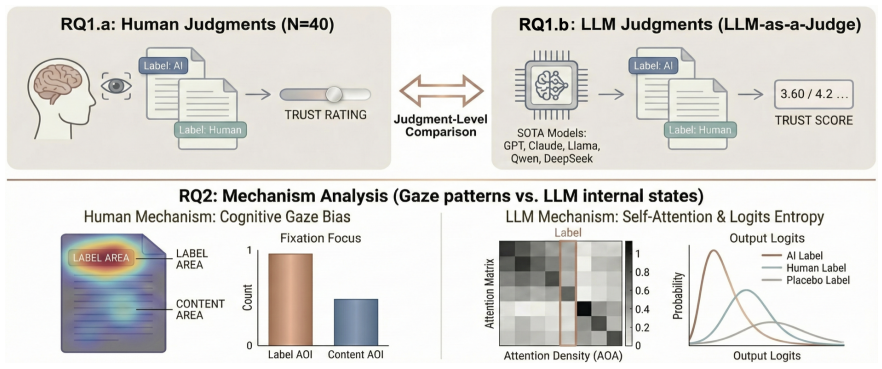
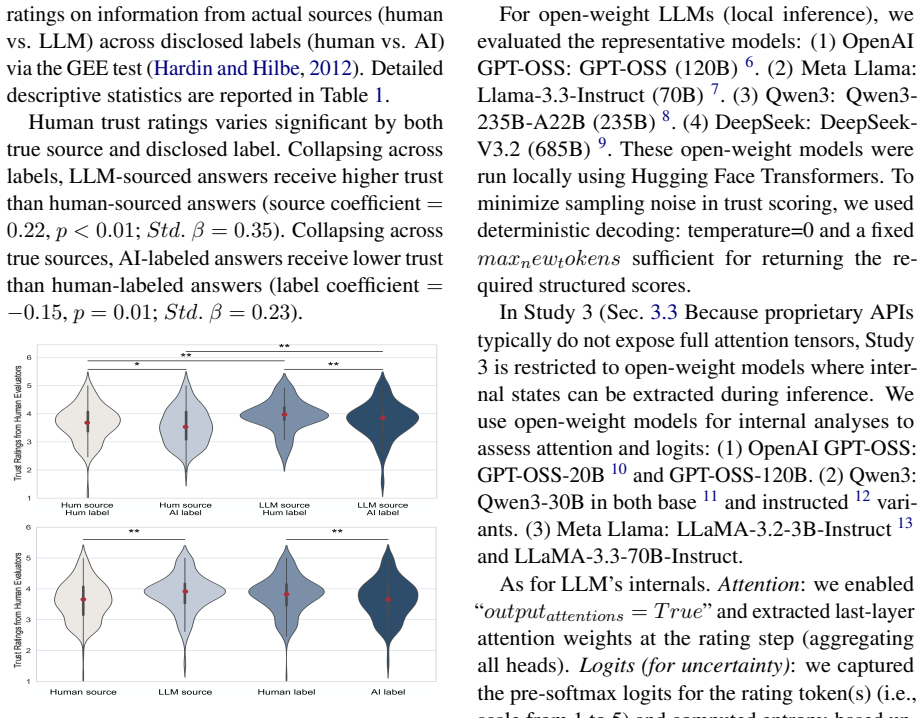
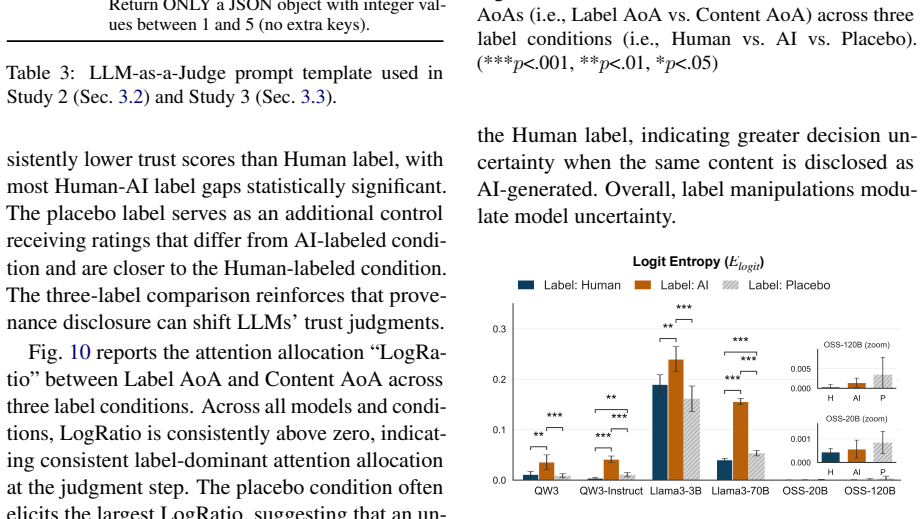
Using a counterfactual setup that holds all text constant and varies only the source label, the work shows that trust ratings rise when content is marked as human-authored and fall when marked as AI-generated. This pattern appears in both human participants and LLM judges. Model attention concentrates more on the label region than the content region, with stronger label focus under human labels, while decision logits indicate greater uncertainty under AI labels. These internal patterns match the human eye-tracking data, indicating that the source label acts as a shared heuristic cue.
What carries the argument
The counterfactual design that isolates the source label by presenting identical content under human versus AI authorship disclosures.
If this is right
- LLM-as-a-Judge systems may systematically undervalue AI-generated outputs when source labels are visible.
- Alignment procedures that train on human preferences risk embedding label-based heuristics into model behavior.
- Evaluation validity suffers when labels are disclosed, because judgments track the label more than the content.
- Attention and uncertainty metrics in LLMs can serve as detectable signals of this heuristic reliance.
Where Pith is reading between the lines
- The same label effect could appear in other judgment tasks such as quality scoring or fact-checking beyond trust.
- Blinding source labels during both human and model evaluation might eliminate the bias and produce more content-focused assessments.
- If training data contain labeled examples, models may learn to overweight labels even when labels are not explicitly provided at inference time.
Load-bearing premise
The experiment successfully keeps every factor except the source label identical across conditions, so no other cue influences the trust difference.
What would settle it
A replication in which the source label is removed or replaced with a neutral marker and the trust gap between the former human and AI conditions disappears for both humans and LLMs.
Figures








read the original abstract
Large language models (LLMs) are increasingly used as automated evaluators (LLM-as-a-Judge). This work challenges its reliability by showing that trust judgments by LLMs are biased by disclosed source labels. Using a counterfactual design, we find that both humans and LLM judges assign higher trust to information labeled as human-authored than to the same content labeled as AI-generated. Eye-tracking data reveal that humans rely heavily on source labels as heuristic cues for judgments. We analyze LLM internal states during judgment. Across label conditions, models allocate denser attention to the label region than the content region, and this label dominance is stronger under Human labels than AI labels, consistent with the human gaze patterns. Besides, decision uncertainty measured by logits is higher under AI labels than Human labels. These results indicate that the source label is a salient heuristic cue for both humans and LLMs. It raises validity concerns for label-sensitive LLM-as-a-Judge evaluation, and we cautiously raise that aligning models with human preferences may propagate human heuristic reliance into models, motivating debiased evaluation and alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that source labels (human-authored vs. AI-generated) bias trust judgments in both humans and LLMs used as judges. Using a counterfactual design that holds content constant while manipulating only the label, the authors report higher trust ratings for human-labeled content. Human data include explicit ratings and eye-tracking fixation metrics showing heavy label reliance; LLM data include judgment outputs, denser attention weights on label tokens (stronger for human labels), and higher logit-based uncertainty for AI labels. These patterns are interpreted as evidence of shared heuristic reliance on source labels, raising concerns for the validity of LLM-as-a-Judge evaluations and potential propagation of biases via alignment.
Significance. If the central empirical result holds under the reported controls, the work is significant for AI evaluation research because it identifies a concrete, measurable bias that affects both human and model judgments in the same direction. The convergence between behavioral (eye-tracking) and internal-state (attention and uncertainty) measures provides a rare cross-species link between cognitive heuristics and model mechanisms, directly supporting the call for debiased evaluation protocols.
minor comments (2)
- Abstract: the summary of results would be strengthened by including at least the total sample sizes for human participants and LLM trials, along with the primary statistical test outcomes or effect sizes that support the trust difference claim.
- The description of LLM attention analysis should clarify how label-region attention weights are normalized and aggregated across layers to ensure direct comparability with the human eye-tracking fixation metrics.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the accurate summary of our findings, and the recommendation for minor revision. We are pleased that the cross-species convergence between human behavioral measures and LLM internal states was recognized as significant for AI evaluation research.
Circularity Check
Empirical study with no derivational chain or self-referential reductions
full rationale
This paper reports an empirical observational study using counterfactual designs to compare trust judgments by humans and LLMs under manipulated source labels. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. Claims rest on experimental measurements (ratings, eye-tracking, attention weights, logits) with reported controls for confounds, and no load-bearing self-citations or uniqueness theorems are invoked to justify core results. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of experimental psychology and statistical inference hold for trust ratings, gaze data, and model logits.
Reference graph
Works this paper leans on
-
[1]
Tobii AB. 2024. http://www.tobii.com/ Tobii pro lab . Computer software
2024
-
[2]
Benjamin R Bates, Sharon Romina, Rukhsana Ahmed, and Danielle Hopson. 2006. The effect of source credibility on consumers' perceptions of the quality of health information on the internet. Medical informatics and the Internet in medicine, 31(1):45--52
2006
-
[3]
Oliver Brady, Paul Nulty, Lili Zhang, Tom \'a s E Ward, and David P McGovern. 2025. Dual-process theory and decision-making in large language models. Nat. Rev. Psychol., 4(12):777--792
2025
-
[4]
Cacioppo, Louis G
John T. Cacioppo, Louis G. Tassinary, and Gary G. Berntson. 2016. Strong Inference in Psychophysiological Science, page 3–15. Cambridge Handbooks in Psychology. Cambridge University Press
2016
-
[5]
Guiming Hardy Chen, Shunian Chen, Ziche Liu, Feng Jiang, and Benyou Wang. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.474 Humans or LLM s as the judge? a study on judgement bias . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8301--8327, Miami, Florida, USA. Association for Computational Linguistics
-
[6]
Vanessa Cheung, Maximilian Maier, and Falk Lieder. 2025. https://doi.org/10.1073/pnas.2412015122 Large language models show amplified cognitive biases in moral decision-making . Proceedings of the National Academy of Sciences, 122(25):e2412015122
-
[7]
Sunhao Dai, Yuqi Zhou, Liang Pang, Weihao Liu, Xiaolin Hu, Yong Liu, Xiao Zhang, Gang Wang, and Jun Xu. 2024. https://doi.org/10.1145/3637528.3671882 Neural retrievers are biased towards llm-generated content . In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD '24, page 526–537, New York, NY, USA. Association for...
-
[8]
Ricardo Dominguez-Olmedo, Moritz Hardt, and Celestine Mendler-D\" u nner. 2024. Questioning the survey responses of large language models. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA. Curran Associates Inc
2024
-
[9]
Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, and Zexue He. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.739 Cognitive bias in decision-making with LLM s . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 12640--12653, Miami, Florida, USA. Association for Computational Linguistics
-
[10]
Abdallah El Ali, Karthikeya Puttur Venkatraj, Sophie Morosoli, Laurens Naudts, Natali Helberger, and Pablo Cesar. 2024. https://doi.org/10.1145/3613905.3650750 Transparent ai disclosure obligations: Who, what, when, where, why, how . In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, CHI EA '24, New York, NY, USA. Associati...
-
[11]
Franz Faul, Edgar Erdfelder, Albert-Georg Lang, and Axel Buchner. 2007. G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav. Res. Methods, 39(2):175--191
2007
-
[12]
Bertram Gawronski, Dillon M Luke, and Laura A Creighton. 2024. Dual-process theories. In The Oxford Handbook of Social Cognition, Second Edition, pages 319--353. Oxford University Press
2024
-
[13]
Ellen R Girden. 1992. ANOVA: Repeated measures. 84. Sage
1992
-
[14]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. https://arxiv.org/abs/2411.15594 A survey on llm-as-a-judge . Preprint, arXiv:2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Rajarshi Haldar and Julia Hockenmaier. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1361 Rating roulette: Self-inconsistency in LLM -as-a-judge frameworks . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 24986--25004, Suzhou, China. Association for Computational Linguistics
-
[16]
James W Hardin and Joseph M Hilbe. 2012. Generalized estimating equations, second edition, 2 edition. Chapman & Hall/CRC, Philadelphia, PA
2012
-
[17]
Winston Haynes. 2013. https://doi.org/10.1007/978-1-4419-9863-7\_1215 Benjamini--Hochberg Method , pages 78--78. Springer New York, New York, NY
-
[18]
InProceedings of the 2019 CHI Conference on Human Factors in Computing Systems
Maurice Jakesch, Megan French, Xiao Ma, Jeffrey T. Hancock, and Mor Naaman. 2019. https://doi.org/10.1145/3290605.3300469 Ai-mediated communication: How the perception that profile text was written by ai affects trustworthiness . In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, CHI '19, page 1–13, New York, NY, USA. Associa...
- [19]
-
[20]
Johnson, Jennifer E
Frances C. Johnson, Jennifer E. Rowley, and Laura Sbaffi. 2015. https://api.semanticscholar.org/CorpusID:206454953 Modelling trust formation in health information contexts . Journal of Information Science, 41:415 -- 429
2015
-
[21]
Marcel A Just and Patricia A Carpenter. 1980. A theory of reading: From eye fixations to comprehension. Psychol. Rev., 87(4):329--354
1980
-
[22]
Tatsuki Kuribayashi, Yohei Oseki, Souhaib Ben Taieb, Kentaro Inui, and Timothy Baldwin. 2025. https://doi.org/10.1162/TACL.a.58 Large language models are human-like internally . Transactions of the Association for Computational Linguistics, 13:1743--1766
-
[23]
Walter Laurito, Benjamin Davis, Peli Grietzer, Tomáš Gavenčiak, Ada Böhm, and Jan Kulveit. 2025. https://doi.org/10.1073/pnas.2415697122 Ai–ai bias: Large language models favor communications generated by large language models . Proceedings of the National Academy of Sciences, 122(31):e2415697122
-
[24]
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. 2025 a . https://doi.org/10.18653/v1/2025.emnlp-main.138 From generation to judgment: Opportunities and challenges of LLM -as-a-judge . In Proceedings of the 2025 Conference on Em...
-
[25]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024. Llms-as-judges: a comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv:2412.05579
work page internal anchor Pith review arXiv 2024
- [26]
-
[27]
Songze Li, Chuokun Xu, Jiaying Wang, Xueluan Gong, Chen Chen, Jirui Zhang, Jun Wang, Kwok-Yan Lam, and Shouling Ji. 2025 c . https://arxiv.org/abs/2506.09443 Llms cannot reliably judge (yet?): A comprehensive assessment on the robustness of llm-as-a-judge . Preprint, arXiv:2506.09443
-
[28]
Q.Vera Liao and S. Shyam Sundar. 2022. https://doi.org/10.1145/3531146.3533182 Designing for responsible trust in ai systems: A communication perspective . In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, FAccT '22, page 1257–1268, New York, NY, USA. Association for Computing Machinery
-
[29]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. https://arxiv.org/abs/2303.16634 G-eval: Nlg evaluation using gpt-4 with better human alignment . Preprint, arXiv:2303.16634
work page internal anchor Pith review arXiv 2023
-
[30]
Joao Marecos, Duarte Tude Graça, Francisco Goiana-da Silva, Hutan Ashrafian, and Ara Darzi. 2024. https://doi.org/10.3390/journalmedia5020046 Source credibility labels and other nudging interventions in the context of online health misinformation: A systematic literature review . Journalism and Media, 5(2):702--717
- [31]
-
[32]
OpenAI. 2024. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . Preprint, arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[34]
Jonathan Peirce, Jeremy R Gray, Sol Simpson, Michael MacAskill, Richard H \"o chenberger, Hiroyuki Sogo, Erik Kastman, and Jonas Kristoffer Lindel v. 2019. PsychoPy2 : Experiments in behavior made easy. Behavior Research Methods, 51(1):195--203
2019
-
[35]
Moritz Reis, Florian Reis, and Wilfried Kunde. 2024. Influence of believed AI involvement on the perception of digital medical advice. Nature Medicine
2024
-
[36]
Bernard Rosner, Robert J Glynn, and Mei-Ling T Lee. 2006. The wilcoxon signed rank test for paired comparisons of clustered data. Biometrics, 62(1):185--192
2006
-
[37]
Rowley, Frances C
Jennifer E. Rowley, Frances C. Johnson, and Laura Sbaffi. 2015. https://api.semanticscholar.org/CorpusID:21888204 Students’ trust judgements in online health information seeking . Health Informatics Journal, 21:316 -- 327
2015
-
[38]
Ali, Angèle Christin, Andrew Smart, and Riitta Katila
Nicolas Scharowski, Michaela Benk, Swen J. KÌhne, Léane Wettstein, and Florian BrÌhlmann. 2023. https://doi.org/10.1145/3593013.3593994 Certification Labels for Trustworthy AI : Insights From an Empirical Mixed - Method Study . In 2023 ACM Conference on Fairness , Accountability , and Transparency , pages 248--260, Chicago IL USA. ACM
- [39]
-
[40]
Huanxin Sheng, Xinyi Liu, Hangfeng He, Jieyu Zhao, and Jian Kang. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.569 Analyzing uncertainty of LLM -as-a-judge: Interval evaluations with conformal prediction . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11297--11339, Suzhou, China. Association for Comp...
- [41]
- [42]
-
[43]
Lindia Tjuatja, Valerie Chen, Tongshuang Wu, Ameet Talwalkwar, and Graham Neubig. 2024. https://doi.org/10.1162/tacl_a_00685 Do LLM s exhibit human-like response biases? a case study in survey design . Transactions of the Association for Computational Linguistics, 12:1011--1026
- [44]
-
[45]
Yidong Wang, Yunze Song, Tingyuan Zhu, Xuanwang Zhang, Zhuohao Yu, Hao Chen, Chiyu Song, Qiufeng Wang, Cunxiang Wang, Zhen Wu, Xinyu Dai, Yue Zhang, Wei Ye, and Shikun Zhang. 2025 b . https://arxiv.org/abs/2509.21117 Trustjudge: Inconsistencies of llm-as-a-judge and how to alleviate them . Preprint, arXiv:2509.21117
- [46]
-
[47]
Sarah Wiegreffe and Yuval Pinter. 2019. https://doi.org/10.18653/v1/D19-1002 Attention is not not explanation . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 11--20, Hong Kong, China. Association for Computational Linguistics
-
[48]
Torr, Bernard Ghanem, and Guohao Li
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Shiyang Lai, Kai Shu, Jindong Gu, Adel Bibi, Ziniu Hu, David Jurgens, James Evans, Philip H.S. Torr, Bernard Ghanem, and Guohao Li. 2024. Can large language model agents simulate human trust behavior? In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red ...
2024
- [49]
- [50]
-
[51]
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, Nitesh V Chawla, and Xiangliang Zhang. 2024. https://arxiv.org/abs/2410.02736 Justice or prejudice? quantifying biases in llm-as-a-judge . Preprint, arXiv:2410.02736
-
[52]
Yidan Yin, Nan Jia, and Cheryl J. Wakslak. 2024. https://doi.org/10.1073/pnas.2319112121 Ai can help people feel heard, but an ai label diminishes this impact . Proceedings of the National Academy of Sciences, 121(14):e2319112121
-
[53]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. https://arxiv.org/abs/2306.05685 Judging llm-as-a-judge with mt-bench and chatbot arena . Preprint, arXiv:2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[54]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[55]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.