Recognition: 2 theorem links
· Lean TheoremHyperfastrl: Hypernetwork-based reinforcement learning for unified control of parametric chaotic PDEs
Pith reviewed 2026-05-10 18:04 UTC · model grok-4.3
The pith
Mapping a forcing parameter directly to policy weights lets one reinforcement learner stabilize chaotic PDEs across regimes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
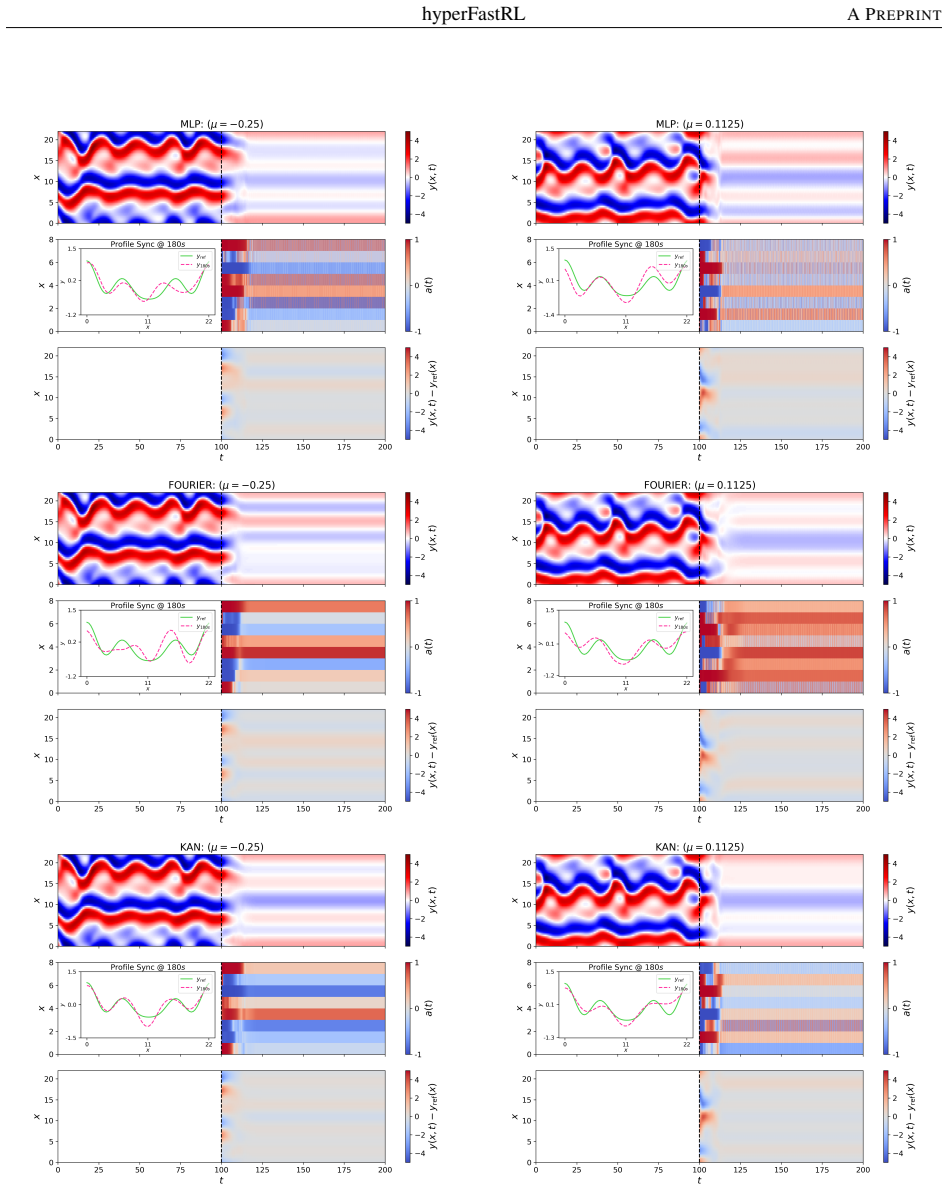
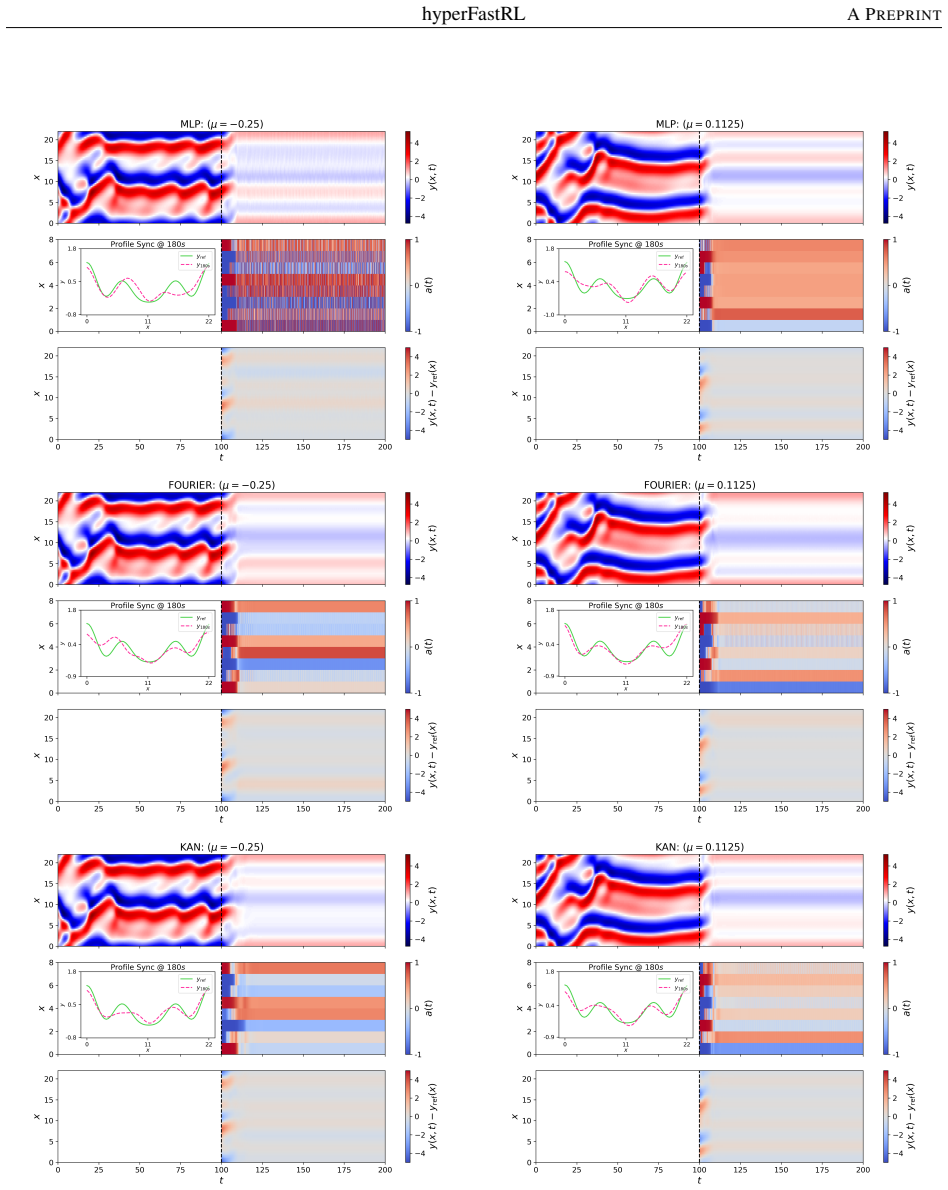
By mapping the physical forcing parameter μ directly to the weights of a spatial feedback policy, the hyperFastRL architecture learns a unified parametric control manifold for the Kuramoto-Sivashinsky equation. Residual MLPs, periodic Fourier networks, and Kolmogorov-Arnold networks are all shown to produce stabilizing controllers. Pessimistic distributional value estimation is used to manage the high variance of chaotic rewards. Kolmogorov-Arnold networks deliver the most consistent energy-cascade suppression and tracking performance on parameter values not seen during training, while Fourier networks show greater extrapolation variability.
What carries the argument
Hypernetwork that accepts the scalar forcing parameter μ as input and produces the weights of the reinforcement-learning policy network used for spatial boundary feedback control.
If this is right
- All three hypernetwork forms achieve robust stabilization of the chaotic PDE.
- Kolmogorov-Arnold networks produce the most consistent energy-cascade suppression and tracking on unseen parametrizations.
- Fourier hypernetworks show higher variability when applied to parameter values outside the training set.
- Massively parallel environment ensembles permit a 37 percent reduction in wall-clock training time by trading a modest amount of final reward.
Where Pith is reading between the lines
- The same hypernetwork pattern could be tested on other parametric chaotic systems such as Navier-Stokes or reaction-diffusion equations.
- Combining the hypernetwork output with additional physics-based constraints on the policy weights might strengthen stability guarantees beyond empirical demonstration.
- The pessimistic distributional critic may transfer to other high-variance reinforcement-learning tasks outside fluid control.
Load-bearing premise
The hypernetwork produces policy weights that remain stabilizing for both trained and unseen values of the forcing parameter, and the pessimistic distributional estimator reduces reward variance without adding bias that breaks the learned mapping.
What would settle it
Finding a new value of the forcing parameter for which the generated policy leaves the Kuramoto-Sivashinsky equation in uncontrolled chaotic growth.
Figures







read the original abstract
Spatiotemporal chaos in fluid systems exhibits severe parametric sensitivity, rendering classical adjoint-based optimal control intractable because each operating regime requires recomputing the control law. We address this bottleneck with hyperFastRL, a parameter-conditioned reinforcement learning framework that leverages Hypernetworks to shift from tuning isolated controllers per-regime to learning a unified parametric control manifold. By mapping a physical forcing parameter {\mu} directly to the weights of a spatial feedback policy, the architecture cleanly decouples parametric adaptation from spatial boundary stabilization. To overcome the extreme variance inherent to chaotic reward landscapes, we deploy a pessimistic distributional value estimation over a massively parallel environment ensemble. We evaluate three Hypernetwork functional forms, ranging from residual MLPs to periodic Fourier and Kolmogorov-Arnold (KAN) representations, on the Kuramoto-Sivashinsky equation under varying spatial forcing. All forms achieve robust stabilization. KAN yields the most consistent energy-cascade suppression and tracking across unseen parametrizations, while Fourier networks exhibit worse extrapolation variability. Furthermore, leveraging high-throughput parallelization allows us to intentionally trade a fraction of peak asymptotic reward for a 37% reduction in training wall-clock time, identifying an optimal operating regime for practical deployment in complex, parameter-varying chaotic PDEs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents HyperFastRL, a hypernetwork-based reinforcement learning framework for unified control of parametric chaotic PDEs such as the Kuramoto-Sivashinsky equation. It maps a scalar physical forcing parameter μ directly to the weights of a spatial feedback policy via hypernetworks (residual MLP, Fourier, and KAN forms), employs pessimistic distributional value estimation over parallel environments to handle chaotic reward variance, and claims that all three architectures achieve robust stabilization, with KAN providing the most consistent energy-cascade suppression and tracking on unseen parametrizations, plus a 37% reduction in training wall-clock time through high-throughput parallelization.
Significance. If the empirical claims are substantiated with quantitative metrics, the work offers a conceptually clean way to decouple parametric adaptation from spatial stabilization in chaotic systems, potentially reducing the need for per-regime controller recomputation in fluid and spatiotemporal chaos applications. The parallel training trade-off for speed is a practical contribution.
major comments (3)
- [Abstract] Abstract: The statements that 'all forms achieve robust stabilization' and that the approach yields a '37% reduction in training wall-clock time' are presented without any supporting quantitative metrics (e.g., time-averaged energy norms, stabilization times, L2 tracking errors), error bars, baseline comparisons to non-hypernetwork RL or per-μ controllers, or statistical details, leaving the central empirical claims only partially supported.
- [Results] Results (evaluation on KS equation): The claim that KAN yields the 'most consistent energy-cascade suppression and tracking across unseen parametrizations' while Fourier shows 'worse extrapolation variability' requires explicit closed-loop metrics (e.g., energy bounds or cascade spectra) for specific unseen μ values; without these, the generalization assertion cannot be assessed given the exponential divergence property of the KS equation under small policy perturbations.
- [Method] Method (pessimistic distributional estimator): No ablation study or analysis is provided to show that the pessimistic distributional value estimation reduces variance without introducing bias that could mask regime-specific destabilization on the learned weight manifold, which is load-bearing for the unseen-μ stabilization claim.
minor comments (2)
- [Abstract] The acronym 'hyperFastRL' is introduced in the title and abstract but not expanded or defined on first use.
- [Method] Notation for the hypernetwork mapping μ → policy weights would benefit from an explicit equation or schematic diagram in the methods to clarify the architecture variants.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense supported by the current work while committing to revisions where the concerns are valid and require additional evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statements that 'all forms achieve robust stabilization' and that the approach yields a '37% reduction in training wall-clock time' are presented without any supporting quantitative metrics (e.g., time-averaged energy norms, stabilization times, L2 tracking errors), error bars, baseline comparisons to non-hypernetwork RL or per-μ controllers, or statistical details, leaving the central empirical claims only partially supported.
Authors: We acknowledge that the abstract, as a high-level summary, does not embed the full quantitative details present in the results section. The manuscript reports time-averaged energy norms, stabilization times, and L2 tracking errors across architectures in the evaluation on the KS equation, along with baseline comparisons to non-hypernetwork RL and per-μ controllers, with error bars from multiple random seeds. To directly address the concern, we will revise the abstract to include key quantitative highlights (e.g., specific energy reduction percentages and the 37% wall-clock reduction from the parallelization study) while referencing the supporting figures and tables. revision: yes
-
Referee: [Results] Results (evaluation on KS equation): The claim that KAN yields the 'most consistent energy-cascade suppression and tracking across unseen parametrizations' while Fourier shows 'worse extrapolation variability' requires explicit closed-loop metrics (e.g., energy bounds or cascade spectra) for specific unseen μ values; without these, the generalization assertion cannot be assessed given the exponential divergence property of the KS equation under small policy perturbations.
Authors: We agree that explicit per-μ closed-loop metrics are essential to substantiate generalization claims in a chaotic system like the KS equation. The results section already includes energy cascade spectra and tracking performance aggregated over unseen μ values, showing KAN's lower variability compared to Fourier networks. To strengthen verifiability, we will add a dedicated table in the revised manuscript with specific energy bounds, L2 errors, and stabilization times for individual unseen μ values (e.g., μ = 0.5 and μ = 1.5), including statistical details from repeated trials. This will allow direct evaluation against the exponential divergence concern. revision: yes
-
Referee: [Method] Method (pessimistic distributional estimator): No ablation study or analysis is provided to show that the pessimistic distributional value estimation reduces variance without introducing bias that could mask regime-specific destabilization on the learned weight manifold, which is load-bearing for the unseen-μ stabilization claim.
Authors: This is a fair and important point, as the pessimistic distributional estimator is key to managing chaotic reward variance and supporting the unseen-μ claims. The current manuscript motivates and describes the estimator but does not include a dedicated ablation. In the revision, we will incorporate an ablation study comparing the pessimistic approach against standard value estimation, reporting variance reduction metrics, bias indicators, and stabilization performance on unseen regimes to confirm it does not mask destabilization on the weight manifold. revision: yes
Circularity Check
No circularity; empirical RL training on KS simulations yields stabilization results independent of method definition.
full rationale
The paper introduces a hypernetwork-conditioned RL controller for parametric KS equation stabilization, with claims resting on direct training runs, parallel environment ensembles, and post-training evaluation of energy suppression and tracking for seen/unseen μ values. No equations or steps reduce by construction to self-definitions, fitted inputs renamed as predictions, or load-bearing self-citations. The pessimistic distributional estimator and hypernetwork forms (MLP, Fourier, KAN) are architectural choices whose performance is measured externally via simulation metrics rather than being implied tautologically. The derivation chain is self-contained against the benchmark of chaotic PDE control tasks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hypernetwork architecture hyperparameters
axioms (2)
- domain assumption The PDE control task can be cast as a Markov decision process with high-variance rewards
- ad hoc to paper Pessimistic distributional value estimation mitigates variance without harming policy quality
invented entities (1)
-
Unified parametric control manifold
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBy mapping a physical forcing parameter μ directly to the weights of a spatial feedback policy, the architecture cleanly decouples parametric adaptation from spatial boundary stabilization.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearWe evaluate three Hypernetwork functional forms, ranging from residual MLPs to periodic Fourier and Kolmogorov-Arnold (KAN) representations
Reference graph
Works this paper leans on
-
[1]
Edward Ott, Celso Grebogi, and James A. Yorke. Controlling chaos.Physical Review Letters, 64(11):1196–1199, 1990
1990
-
[2]
Control of chaotic systems by deep reinforcement learning.Proceedings of the Royal Society A, 475(2231):20190351, 2019
Michaël A Bucci, Onofrio Semeraro, Alexandre Allauzen, Ghislain Wischedel, Lionel Laurent, and Lionel Mathelin. Control of chaotic systems by deep reinforcement learning.Proceedings of the Royal Society A, 475(2231):20190351, 2019
2019
-
[3]
A review on deep reinforcement learning for fluid mechanics.Computers & Fluids, 225:104973, 2021
Paul Garnier, Julien Viquerat, Jean Rabault, Aurélien Larcher, Alexander Kuhnle, and Elie Hachem. A review on deep reinforcement learning for fluid mechanics.Computers & Fluids, 225:104973, 2021
2021
-
[4]
Model-free reinforcement learning for pde-constrained control problems
Guangxiang Zhu, Minghao Zhang, Honglak Lee, and Chongjie Zhang. Model-free reinforcement learning for pde-constrained control problems. arXiv preprint arXiv:2010.12142, 2020
-
[5]
Deep reinforcement learning in nonlinear dynamical systems and fluids
Xiyao Wang, Junge Zhang, Wenzhen Huang, and Qiyue Yin. Deep reinforcement learning in nonlinear dynamical systems and fluids. arXiv preprint arXiv:2010.12914, 2020
-
[6]
Bewley, Parviz Moin, and Roger Temam
Thomas R. Bewley, Parviz Moin, and Roger Temam. Dns-based predictive control of turbulence: an optimal benchmark for feedback algorithms.Journal of Fluid Mechanics, 447:179–225, 2001
2001
-
[7]
John Kim and Thomas R. Bewley. A linear systems approach to flow control.Annual Review of Fluid Mechanics, 39:383–417, 2007. 18 hyperFastRLA PREPRINT
2007
-
[8]
Henningson
Shervin Bagheri, Luca Brandt, and Dan S. Henningson. Input-output analysis, model reduction and control of the flat-plate boundary layer.Journal of Fluid Mechanics, 620:263–298, 2009
2009
-
[9]
Microelectromechanical systems-based feedback control of turbulence for skin friction reduction.Annual Review of Fluid Mechanics, 41:231–251, 2009
Nobuhide Kasagi, Yuji Suzuki, and Koji Fukagata. Microelectromechanical systems-based feedback control of turbulence for skin friction reduction.Annual Review of Fluid Mechanics, 41:231–251, 2009
2009
-
[10]
Hogberg, T
M. Hogberg, T. R. Bewley, and D. S. Henningson. Relaminarization of Reτ = 100 turbulence using gain scheduling and linear state-feedback control.Physics of Fluids, 15(11):3572–3575, 2003
2003
-
[11]
Sipp and P
D. Sipp and P. Schmid. Closed-loop control of fluid flow: a review of linear approaches and tools for the stabilization of transitional flows.Aerospace Lab, 2013
2013
-
[12]
Denis Sipp and Peter J. Schmid. Linear closed-loop control of fluid instabilities and noise-induced perturbations: A review of approaches and tools.Applied Mechanics Reviews, 68(2), 2016
2016
-
[13]
Gregory and Mehmet N
James W. Gregory and Mehmet N. Tomac. A review of fluidic oscillator development and application for flow control. In43rd Fluid Dynamics Conference. American Institute of Aeronautics and Astronautics, 2013
2013
-
[14]
Jones, P
Bryn Ll. Jones, P. H. Heins, E. C. Kerrigan, J. F. Morrison, and A. S. Sharma. Modelling for robust feedback control of fluid flows.Journal of Fluid Mechanics, 769:687–722, 2015
2015
-
[15]
H. J. Tol, M. Kotsonis, C. C. de Visser, and B. Bamieh. Localised estimation and control of linear instabilities in two-dimensional wall-bounded shear flows.Journal of Fluid Mechanics, 824:818–865, 2017
2017
-
[16]
Linear iterative method for closed-loop control of quasiperiodic flows.Journal of Fluid Mechanics, 868:26–65, 2019
Colin Leclercq, Fabrice Demourant, Charles Poussot-Vassal, and Denis Sipp. Linear iterative method for closed-loop control of quasiperiodic flows.Journal of Fluid Mechanics, 868:26–65, 2019
2019
-
[17]
Thibault L. B. Flinois and Aimee S. Morgans. Feedback control of unstable flows: a direct modelling approach using the eigensystem realisation algorithm.Journal of Fluid Mechanics, 793:41–78, 2016
2016
-
[18]
Rusu, Joel Veness, Marc G
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human- level control through deep reinforcement...
2015
-
[19]
Asynchronous methods for deep reinforcement learning
V olodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. InInternational Conference on Machine Learning (ICML), pages 1928–1937. PMLR, 2016
1928
-
[20]
Lillicrap, Jonathan J
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2016
2016
-
[21]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. International Conference on Machine Learning (ICML), pages 1587–1596, 2018
2018
-
[23]
J. Schulman, X. Chen, and P. Abbeel. A unified framework for policy evaluation and improvement in reinforcement learning.arXiv preprint arXiv:2205.09876, 2022
-
[24]
A survey on zero-knowledge machine learning,
X. Li and Q. Liu. Why off-policy breaks reinforcement learning: An sga-based analysis framework.arXiv preprint arXiv:2501.01234, 2025
-
[25]
Arsenii Kuznetsov, Pavel Shvechikov, Alexander Grishin, and Dmitry Kuzovkin. Controlling overestimation bias with truncated mixture of continuous distributional quantile critics.arXiv preprint arXiv:2005.04269, 2020
-
[26]
Stabilizing off-policy q-learning via bootstrapping error reduction
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
2019
-
[27]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[28]
Behavior Regularized Offline Reinforcement Learning
Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning.arXiv preprint arXiv:1911.11361, 2019
work page internal anchor Pith review arXiv 1911
-
[29]
Optimal chaos control through reinforcement learning.Chaos, 9(3):775–788, 1999
Sabino Gadaleta and Gerhard Dangelmayr. Optimal chaos control through reinforcement learning.Chaos, 9(3):775–788, 1999
1999
-
[30]
Gadaleta and G
S. Gadaleta and G. Dangelmayr. Reinforcement learning chaos control using value sensitive vector-quantization. InReinforcement learning chaos control using value sensitive vector-quantization, 2001. 19 hyperFastRLA PREPRINT
2001
-
[31]
Restoring chaos using deep reinforcement learning.Chaos, 30(3):031102, 2020
Sumit Vashishtha and Siddhartha Verma. Restoring chaos using deep reinforcement learning.Chaos, 30(3):031102, 2020
2020
-
[32]
Model-free control of chaos with continuous deep q-learning
Junya Ikemoto and Toshimitsu Ushio. Model-free control of chaos with continuous deep q-learning. arXiv preprint arXiv:1907.07775, 2019
-
[33]
Modulating chaos in spatiotemporal systems based on deep reinforcement learning.International Journal of Dynamics and Control, 13(11), 2025
Yanyan Han, Jiyuan Pan, and Youming Lei. Modulating chaos in spatiotemporal systems based on deep reinforcement learning.International Journal of Dynamics and Control, 13(11), 2025
2025
-
[34]
Abhinav Bhatia, Philip S. Thomas, and Shlomo Zilberstein. Reinforcement learning for scientific control and pde systems. arXiv preprint arXiv:2206.02380, 2022
-
[35]
Control and anti-control of chaos based on the moving largest lyapunov exponent using reinforcement learning.Physica D: Nonlinear Phenomena, 2021
Yanyan Han, Jianpeng Ding, Lin Du, and Youming Lei. Control and anti-control of chaos based on the moving largest lyapunov exponent using reinforcement learning.Physica D: Nonlinear Phenomena, 2021
2021
-
[36]
Froehlich, Maksym Lefarov, Melanie N
Lukas P. Froehlich, Maksym Lefarov, Melanie N. Zeilinger, and Felix Berkenkamp. Deep reinforcement learning for complex dynamical-system control. arXiv preprint arXiv:2110.07985, 2021
-
[37]
Reinforcement learning of chaotic systems control in partially observable environments.Flow, Turbulence and Combustion, 115(3):1357–1378, 2025
Max Weissenbacher, Anastasia Borovykh, and Georgios Rigas. Reinforcement learning of chaotic systems control in partially observable environments.Flow, Turbulence and Combustion, 115(3):1357–1378, 2025
2025
-
[38]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the g...
2016
-
[39]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642, 2025
-
[40]
Mbrl-mc: An hvac control approach via combining model-based deep reinforcement learning and model predictive control.IEEE Internet of Things Journal, 2022
Liangliang Chen, Fei Meng, and Ying Zhang. Mbrl-mc: An hvac control approach via combining model-based deep reinforcement learning and model predictive control.IEEE Internet of Things Journal, 2022
2022
-
[41]
Solving high-dimensional partial differential equations using deep learning.Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning.Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018
2018
-
[42]
Weinan E, Jiequn Han, and Arnulf Jentzen. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Communications in Mathematics and Statistics, 5(4):349–380, 2017
2017
-
[43]
Learning to fly
Jie Xu, Tao Du, Michael Foshey, Beichen Li, Bo Zhu, Adriana Schulz, and Wojciech Matusik. Learning to fly. ACM Transactions on Graphics, 38(4):1–12, 2019
2019
-
[44]
Vignon, J
C. Vignon, J. Rabault, and R. Vinuesa. Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions.Physics of Fluids, 35(3), 2023
2023
-
[45]
Morphing airfoils with four morphing parameters
Amanda Lampton, Adam Niksch, and John Valasek. Morphing airfoils with four morphing parameters. InAIAA Guidance, Navigation and Control Conference and Exhibit, pages 2008–7282, 2008
2008
-
[46]
Deep reinforcement learning trading with cumulative prospect theory and truncated quantile critics
Jonathan Foo, Benny Lesmana, and Chi Seng Pun. Deep reinforcement learning trading with cumulative prospect theory and truncated quantile critics. InProceedings of the 4th ACM International Conference on AI in Finance (ICAIF), 2023
2023
-
[47]
Sebastian Peitz, Jan Stenner, Vikas Chidananda, Oliver Wallscheid, Steven L. Brunton, and Kunihiko Taira. Learning-based flow control and scientific machine learning perspectives. arXiv preprint arXiv:2301.10737, 2023
-
[48]
Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control.Journal of Fluid Mechanics, 865:281–302, 2019
Jean Rabault, Mariusz Kuchta, Anders Jensen, Ulysse Réglade, and Nicolò Cerardi. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control.Journal of Fluid Mechanics, 865:281–302, 2019
2019
-
[49]
Triantafyllou, and George E
David Fan, Lei Yang, Ziyuan Wang, Michael S. Triantafyllou, and George E. Karniadakis. Reinforcement learning for bluff body active flow control in experiments and simulations.Proceedings of the National Academy of Sciences, 117:26091–26098, 2020
2020
-
[50]
Applying deep reinforcement learning to active flow control in weakly turbulent conditions.Physics of Fluids, 33(3), 2021
Feng Ren, Jean Rabault, and Hui Tang. Applying deep reinforcement learning to active flow control in weakly turbulent conditions.Physics of Fluids, 33(3), 2021
2021
-
[51]
Deep reinforcement learning for turbulent drag reduction in channel flows.The European Physical Journal E, 46(4), 2023
Luca Guastoni, Jean Rabault, Philipp Schlatter, Hossein Azizpour, and Ricardo Vinuesa. Deep reinforcement learning for turbulent drag reduction in channel flows.The European Physical Journal E, 46(4), 2023
2023
-
[52]
Tingwu Wang and Jimmy Ba. Reinforcement learning methods for active flow control. arXiv preprint arXiv:1906.08649, 2019. 20 hyperFastRLA PREPRINT
-
[53]
Chaos suppression through chaos enhancement.Nonlinear Dynamics, 2024
Lin Li, Jizhou Li, and Takemasa Miyoshi. Chaos suppression through chaos enhancement.Nonlinear Dynamics, 2024
2024
-
[54]
Controlling chaos based on state-mapping network and deep reinforcement learning.Nonlinear Dynamics, 2025
Tongtao Liu and Yongping Zhang. Controlling chaos based on state-mapping network and deep reinforcement learning.Nonlinear Dynamics, 2025
2025
-
[55]
Accelerating deep reinforcement learning strategies of flow control through a multi-environment approach.Physics of Fluids, 31(9), 2019
Jean Rabault and Alexander Kuhnle. Accelerating deep reinforcement learning strategies of flow control through a multi-environment approach.Physics of Fluids, 31(9), 2019
2019
-
[56]
Deep reinforcement learning for computational fluid dynamics on hpc systems.Journal of Computational Science, 65:101884, 2022
Marius Kurz, Philipp Offenhauser, Dominic Viola, Oleksandr Shcherbakov, Michael Resch, and Andrea Beck. Deep reinforcement learning for computational fluid dynamics on hpc systems.Journal of Computational Science, 65:101884, 2022
2022
-
[57]
Qiulei Wang, Lei Yan, Gang Hu, Chao Li, Yiqing Xiao, Hao Xiong, Jean Rabault, and Bernd R. Noack. Drlinfluids: An open-source python platform of coupling deep reinforcement learning and openfoam.Physics of Fluids, 34(8), 2022
2022
-
[58]
Linot, and Michael D
Kevin Zeng, Alec J. Linot, and Michael D. Graham. Data-driven control of spatiotemporal chaos with reduced- order neural ode-based models and reinforcement learning.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 479(2269):20220297, 2023
2023
-
[59]
Kevin Zeng and Michael D. Graham. Symmetry reduction for deep reinforcement learning active control of chaotic spatiotemporal dynamics.Physical Review E, 104(1), 2021
2021
-
[60]
Numerical evidence for sample efficiency of model-based over model-free reinforcement learning control of partial differential equations
Stefan Werner and Sebastian Peitz. Numerical evidence for sample efficiency of model-based over model-free reinforcement learning control of partial differential equations. InEuropean Control Conference (ECC), 2024
2024
-
[61]
Sample-efficient reinforcement learning of koopman enmpc
Daniel Mayfrank, Mehmet Velioglu, Alexander Mitsos, and Manuel Dahmen. Sample-efficient reinforcement learning of koopman enmpc. arXiv preprint arXiv:2503.18787, 2025
-
[62]
Linot and Michael D
Alec J. Linot and Michael D. Graham. Data-driven reduced-order modeling of spatiotemporal chaos with neural ordinary differential equations.Chaos, 32(7):073110, 2022
2022
-
[63]
Reconstruction, forecasting, and stability of chaotic dynamics from partial data.Chaos, 33(9):093107, 2023
Elise Ozalp, Georgios Margazoglou, and Luca Magri. Reconstruction, forecasting, and stability of chaotic dynamics from partial data.Chaos, 33(9):093107, 2023
2023
-
[64]
Data-driven modeling and forecasting of chaotic dynamics on inertial manifolds constructed as spectral submanifolds.Chaos, 34(3):033140, 2024
Aihui Liu, Joar Axas, and George Haller. Data-driven modeling and forecasting of chaotic dynamics on inertial manifolds constructed as spectral submanifolds.Chaos, 34(3):033140, 2024
2024
-
[65]
Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 7462–7473, 2020
2020
-
[66]
Colin Vignon, Jean Rabault, Joel Vasanth, Francisco Alcantara-Avila, Mikael Mortensen, and Ricardo Vinuesa. Effective control of two-dimensional rayleigh–benard convection: invariant multi-agent reinforcement learning is all you need. arXiv preprint arXiv:2304.02370, 2023
-
[67]
Brunton, and Kunihiko Taira
Sebastian Peitz, Jan Stenner, Vikas Chidananda, Oliver Wallscheid, Steven L. Brunton, and Kunihiko Taira. Distributed control of partial differential equations using convolutional reinforcement learning.Physica D: Nonlinear Phenomena, 461:134096, 2024
2024
-
[68]
Active flow control on airfoils by reinforcement learning.Ocean Engineering, 287:115775, 2023
Koldo Portal-Porras, Unai Fernandez-Gamiz, Ekaitz Zulueta, Roberto Garcia-Fernandez, and Saioa Etxebar- ria Berrizbeitia. Active flow control on airfoils by reinforcement learning.Ocean Engineering, 287:115775, 2023
2023
-
[69]
Nicolò Botteghi, Stefania Fresca, Mengwu Guo, and Andrea Manzoni. Hyperl: Parameter-informed reinforcement learning for parametric pdes.arXiv preprint arXiv:2501.04538, 2025
-
[70]
Learning a model is paramount for sample efficiency in reinforcement learning control of pdes
Stefan Werner and Sebastian Peitz. Learning a model is paramount for sample efficiency in reinforcement learning control of pdes. arXiv preprint arXiv:2302.07160, 2023
-
[71]
David Ha, Andrew Dai, and Quoc V Le. Hypernetworks.arXiv preprint arXiv:1609.09106, 2016
work page internal anchor Pith review arXiv 2016
-
[72]
Recomposing the reinforcement learning building blocks with hypernetworks
Shai Keynan, Elad Sarafian, and Sarit Kraus. Recomposing the reinforcement learning building blocks with hypernetworks. InProceedings of the 38th International Conference on Machine Learning, pages 9301–9312. PMLR, 2021
2021
-
[73]
Fourth-order time-stepping for stiff pdes.SIAM Journal on Scientific Computing, 26(4):1214–1233, 2005
Aly-Khan Kassam and Lloyd N Trefethen. Fourth-order time-stepping for stiff pdes.SIAM Journal on Scientific Computing, 26(4):1214–1233, 2005
2005
-
[74]
Relexi — a scalable open source reinforcement learning framework for high-performance computing.Software Impacts, 14:100422, 2022
Marius Kurz, Philipp Offenhauser, Dominic Viola, Michael Resch, and Andrea Beck. Relexi — a scalable open source reinforcement learning framework for high-performance computing.Software Impacts, 14:100422, 2022. 21 hyperFastRLA PREPRINT
2022
-
[75]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018
2018
-
[76]
Bellemare, Will Dabney, and Rémi Munos
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. In International Conference on Machine Learning (ICML), 2017
2017
-
[77]
Bellemare, and Rémi Munos
Will Dabney, Mark Rowland, Marc G. Bellemare, and Rémi Munos. Distributional reinforcement learning with quantile regression. InAAAI Conference on Artificial Intelligence, 2018
2018
-
[78]
Kerrigan, and Georgios Rigas
Chengwei Xia, Junjie Zhang, Eric C. Kerrigan, and Georgios Rigas. Active flow control for bluff body drag reduction using reinforcement learning with partial measurements.Journal of Fluid Mechanics, 981:A17, 2024
2024
-
[79]
Nicolai Dorka. Quantile regression for distributional reward models in rlhf.arXiv preprint arXiv:2409.10164, 2024
-
[80]
On the spectral bias of neural networks
Nasim Rahaman, Aristide Baratin, Devansh Arpit, Felix Draxler, Min Lin, Fred Hamprecht, Yoshua Bengio, and Aaron Courville. On the spectral bias of neural networks. InInternational Conference on Machine Learning (ICML), pages 5301–5310. PMLR, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.