Recognition: no theorem link
SurFITR: A Dataset for Surveillance Image Forgery Detection and Localisation
Pith reviewed 2026-05-10 18:19 UTC · model grok-4.3
The pith
SurFITR dataset shows that forgery detectors trained on standard images degrade on surveillance tampering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SurFITR supplies a large set of forensically relevant tampered surveillance images with varied resolutions and edit types, produced through a multimodal LLM-powered pipeline for fine-grained editing, and experiments establish that existing detectors degrade significantly on this data while training on SurFITR brings substantial gains in both in-domain and cross-domain detection and localisation.
What carries the argument
The multimodal LLM-powered pipeline that generates semantically aware, fine-grained edits in diverse surveillance scenes with small or occluded subjects and lower visual quality.
If this is right
- Detectors trained only on conventional forgery datasets will show marked drops in performance when applied to surveillance imagery.
- Training or fine-tuning on SurFITR will improve both detection accuracy and localisation precision for in-domain and cross-domain surveillance cases.
- The dataset enables systematic testing of forgery methods across different edit scales, image resolutions, and scene complexities typical of surveillance.
Where Pith is reading between the lines
- The dataset could support development of specialised localisation techniques that focus on small regions rather than whole-image analysis.
- Combining SurFITR with real captured tampered surveillance footage would provide a stronger test of whether the generated examples transfer to actual forensic evidence.
- The generation approach may extend to creating paired video sequences for testing temporal forgery detection in CCTV streams.
Load-bearing premise
The generated tampered images accurately capture the localised, subtle, and forensically relevant characteristics of real-world surveillance tampering.
What would settle it
A demonstration that existing detectors maintain high accuracy on SurFITR without retraining, or that training on SurFITR produces no measurable improvement on independent real surveillance forgery test sets, would undermine the central claim.
Figures


read the original abstract
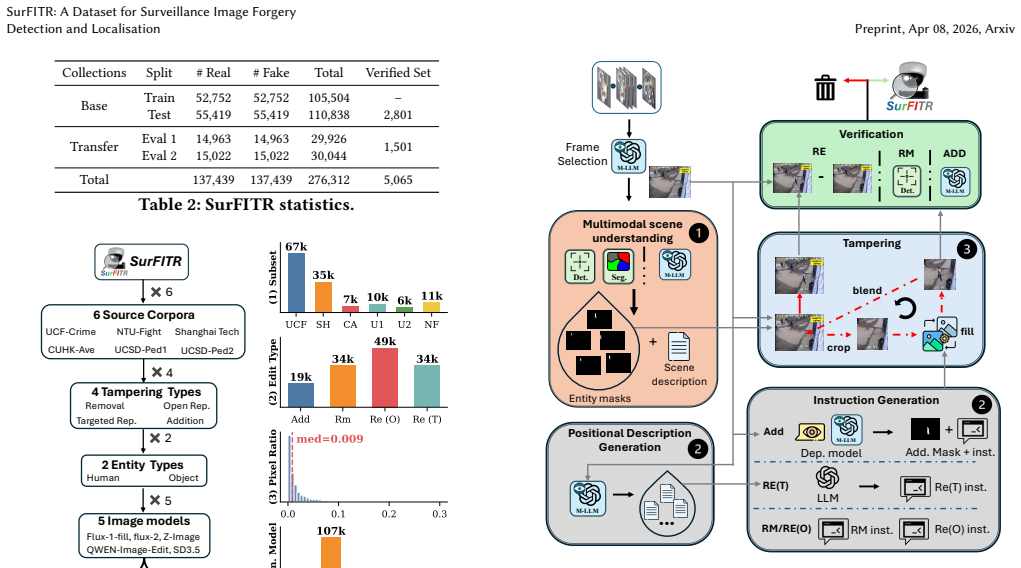
We present the Surveillance Forgery Image Test Range (SurFITR), a dataset for surveillance-style image forgery detection and localisation, in response to recent advances in open-access image generation models that raise concerns about falsifying visual evidence. Existing forgery models, trained on datasets with full-image synthesis or large manipulated regions in object-centric images, struggle to generalise to surveillance scenarios. This is because tampering in surveillance imagery is typically localised and subtle, occurring in scenes with varied viewpoints, small or occluded subjects, and lower visual quality. To address this gap, SurFITR provides a large collection of forensically valuable imagery generated via a multimodal LLM-powered pipeline, enabling semantically aware, fine-grained editing across diverse surveillance scenes. It contains over 137k tampered images with varying resolutions and edit types, generated using multiple image editing models. Extensive experiments show that existing detectors degrade significantly on SurFITR, while training on SurFITR yields substantial improvements in both in-domain and cross-domain performance. SurFITR is publicly available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SurFITR, a dataset of over 137k tampered surveillance images generated via a multimodal LLM-powered pipeline for semantically aware, fine-grained editing. It claims that existing forgery detectors trained on full-image synthesis or large-region manipulations in object-centric images fail to generalize to surveillance scenarios involving localized, subtle edits in varied-viewpoint, low-quality scenes with small or occluded subjects. Experiments are reported to show significant performance degradation of prior detectors on SurFITR and substantial gains in both in-domain and cross-domain settings when models are trained on the new dataset.
Significance. If the generated edits prove representative of authentic surveillance tampering, SurFITR would address a clear gap in image forensics by supplying a large-scale, domain-specific benchmark. The scale (137k+ images across multiple editing models and resolutions) and the reported cross-domain improvements could support development of more robust detectors for real-world evidence verification, where surveillance footage is common. Public release on GitHub further aids reproducibility.
major comments (2)
- [Dataset construction and Experiments sections] The central claims of detector degradation and retraining gains rest on the premise that the LLM pipeline produces tampered images that are forensically realistic and representative of real surveillance tampering (localized, subtle edits). No validation is described—such as quantitative comparison of edit sizes/locations to real tampered surveillance data, perceptual studies, or forensic-expert assessment of artifact realism—that would confirm this assumption holds for the reported generalization results.
- [Experiments] The abstract and results summary state that existing detectors 'degrade significantly' and training yields 'substantial improvements,' yet the provided description lacks concrete metrics (e.g., AUC, F1, IoU for localization), baseline tables with error bars, or statistical tests. Without these, the magnitude and reliability of the claimed gains cannot be assessed.
minor comments (2)
- [Dataset description] Clarify the exact number of editing models used and the distribution of edit types (e.g., object insertion vs. removal) across the 137k images to allow readers to judge diversity.
- [Introduction] Ensure that all prior forgery datasets referenced in the introduction and related work are cited with their original publication details and access information.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on dataset validation and the need for clearer quantitative reporting. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Dataset construction and Experiments sections] The central claims of detector degradation and retraining gains rest on the premise that the LLM pipeline produces tampered images that are forensically realistic and representative of real surveillance tampering (localized, subtle edits). No validation is described—such as quantitative comparison of edit sizes/locations to real tampered surveillance data, perceptual studies, or forensic-expert assessment of artifact realism—that would confirm this assumption holds for the reported generalization results.
Authors: We agree that explicit validation of forensic realism strengthens the claims. The multimodal LLM pipeline was engineered to generate semantically coherent, localized edits suited to surveillance characteristics (varied viewpoints, small/occluded subjects, lower quality), which differs from prior datasets. Direct comparison to real tampered surveillance data is not feasible at scale because no large public datasets of verified real-world surveillance forgeries with ground-truth masks exist. In revision we will add quantitative statistics on generated edit sizes, locations, and semantic categories in the Dataset Construction section, include a limitations discussion on this point, and report a small-scale perceptual study with non-expert raters to assess visual plausibility. revision: partial
-
Referee: [Experiments] The abstract and results summary state that existing detectors 'degrade significantly' and training yields 'substantial improvements,' yet the provided description lacks concrete metrics (e.g., AUC, F1, IoU for localization), baseline tables with error bars, or statistical tests. Without these, the magnitude and reliability of the claimed gains cannot be assessed.
Authors: We acknowledge that the summary-level claims require supporting numbers for full assessment. The full Experiments section already reports AUC, F1, and IoU values for detection and localization across baselines, in-domain, and cross-domain settings. To address the concern we will revise the section to present these results in expanded tables that include error bars from multiple random seeds, add statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank), and ensure key quantitative findings are referenced more explicitly in the abstract and results summary. revision: yes
- Direct quantitative comparison of edit sizes/locations to real tampered surveillance data, because no sufficiently large public dataset of verified real-world surveillance forgeries with localization masks is available.
Circularity Check
No significant circularity
full rationale
The paper introduces SurFITR, a new dataset of tampered surveillance images generated via a multimodal LLM pipeline, and evaluates external forgery detectors on it. Claims rest on empirical results showing detector degradation on SurFITR and gains from training on it. No equations, parameter fits, or derivations are present. No load-bearing self-citations or uniqueness theorems reduce any result to the paper's own inputs by construction. The work is a self-contained empirical contribution benchmarked against independent detectors.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs combined with image editing models can generate semantically aware, fine-grained, and forensically valuable edits that mimic real surveillance tampering.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Crime Stoppers Australia. https://www.crimestoppers.com.au/. Accessed: 2026
2026
-
[2]
[n. d.]. FBI Tips and Public Leads Portal. https://tips.fbi.gov/. Accessed: 2026
2026
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Andrew Brock, Jeff Donahue, and Karen Simonyan. 2018. Large scale GAN training for high fidelity natural image synthesis.arXiv preprint arXiv:1809.11096 (2018)
work page internal anchor Pith review arXiv 2018
-
[5]
Baoying Chen, Jishen Zeng, Jianquan Yang, and Rui Yang. 2024. DRCT: Diffusion Reconstruction Contrastive Training towards Universal Detection of Diffusion Generated Images. InProceedings of the 41st International Conference on Machine Learning. 7621–7639
2024
-
[6]
Xinru Chen, Chengbo Dong, Jiaqi Ji, Juan Cao, and Xirong Li. 2021. Image Manipulation Detection by Multi-View Multi-Scale Supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 14185–14193
2021
-
[7]
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan
-
[8]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16901–16911
-
[9]
Google DeepMind. 2025. Gemini 3. https://blog.google/products-and-platforms/ products/gemini/gemini-3/
2025
-
[10]
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. 2020. The DeepFake Detection Challenge (DFDC) Dataset. arXiv:2006.07397 [cs.CV]
work page internal anchor Pith review arXiv 2020
-
[11]
Jing Dong, Wei Wang, and Tieniu Tan. 2013. CASIA Image Tampering Detection Evaluation Database. In2013 IEEE China Summit and International Conference on Signal and Information Processing. 422–426. doi:10.1109/chinasip.2013.6625374
-
[12]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Dominik Lorenz, et al . 2024. Scaling Rectified Flow Transformers for High- Resolution Image Synthesis.arXiv preprint arXiv:2403.03206(2024)
work page internal anchor Pith review arXiv 2024
-
[13]
Gemini Team, Google. 2023. Gemini: A Family of Highly Capable Multimodal Models. arXiv:2312.11805 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks.Commun. ACM63, 11 (2020), 139–144
2020
-
[15]
Fabrizio Guillaro, Davide Cozzolino, Avneesh Sud, Nicholas Dufour, and Luisa Verdoliva. 2023. TruFor: Leveraging All-Round Clues for Trustworthy Image Forgery Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 20606–20615
2023
-
[16]
Xiao Guo, Xiaohong Liu, Zhiyuan Ren, Steven Grosz, Iacopo Masi, and Xiaoming Liu. 2023. Hierarchical Fine-Grained Image Forgery Detection and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3155–3165
2023
-
[17]
Yinan He, Bei Gan, Siyu Chen, Yichun Zhou, Guojun Yin, Luchuan Song, Lu Sheng, Jing Shao, and Ziwei Liu. 2021. ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4360–4369
2021
-
[18]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems, Vol. 33. 6840–6851
2020
-
[19]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator ar- chitecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4401–4410
2019
-
[20]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
Myung-Joon Kwon, In-Jae Yu, Seung-Hun Nam, and Heung-Kyu Lee. 2021. CAT- Net: Compression Artifact Tracing Network for Detection and Localization of Image Splicing. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV). 375–384
2021
-
[22]
Black Forest Labs. 2024. FLUX. https://github.com/black-forest-labs/flux
2024
-
[23]
Black Forest Labs. 2025. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/ flux-2
2025
-
[24]
Weixin Li, Vijay Mahadevan, and Nuno Vasconcelos. 2014. Anomaly Detection and Localization in Crowded Scenes.IEEE Transactions on Pattern Analysis and Machine Intelligence36, 1 (2014), 18–32
2014
-
[25]
Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. 2018. Future frame prediction for anomaly detection–a new baseline. InProceedings of the IEEE conference on computer vision and pattern recognition. 6536–6545
2018
-
[26]
Xiaohong Liu, Yaojie Liu, Jun Chen, and Xiaoming Liu. 2022. PSCC-Net: Progres- sive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization.IEEE Transactions on Circuits and Systems for Video Technology32, 11 (2022), 7505–7517
2022
-
[27]
Cewu Lu, Jianping Shi, and Jiaya Jia. 2013. Abnormal Event Detection at 150 FPS in MATLAB. InProceedings of the IEEE International Conference on Computer Vision (ICCV). 2720–2727
2013
-
[28]
Xiaochen Ma, Bo Du, Zhuohang Jiang, Xia Du, Ahmed Y. Al Hammadi, and Jizhe Zhou. 2023. IML-ViT: Benchmarking Image Manipulation Localization by Vision Transformer. arXiv:2307.14863 [cs.CV]
-
[29]
Xiaochen Ma, Xuekang Zhu, Lei Su, Bo Du, Zhuohang Jiang, Bingkui Tong, Zeyu Lei, Xinyu Yang, Chi-Man Pun, Jiancheng Lv, and Jizhe Zhou. 2024. IMDL-BenCo: A Comprehensive Benchmark and Codebase for Image Manipulation Detection & Localization. InAdvances in Neural Information Processing Systems, Vol. 37. 134591–134613
2024
-
[30]
Vijay Mahadevan, Wei-Xin Li, Viral Bhalodia, and Nuno Vasconcelos. 2010. Anom- aly Detection in Crowded Scenes. InProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR). 1975–1981
2010
-
[31]
2004.A Data Set of Authentic and Spliced Image Blocks
Tian-Tsong Ng and Shih-Fu Chang. 2004.A Data Set of Authentic and Spliced Image Blocks. Technical Report 203-2004-3. Columbia University
2004
-
[32]
Adam Novozamsky, Babak Mahdian, and Stanislav Saic. 2020. IMD2020: A Large-Scale Annotated Dataset Tailored for Detecting Manipulated Images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV) Workshops. 71–80
2020
-
[33]
Mauricio Perez, Alex C Kot, and Anderson Rocha. 2019. Detection of real-world fights in surveillance videos. InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2662–2666
2019
-
[34]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2024. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. InInternational Conference on Learning Representations
2024
-
[35]
Qwen Team. 2025. Qwen3-VL Technical Report. arXiv:2511.21631 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Alec Radford, Luke Metz, and Soumith Chintala. 2015. Unsupervised representa- tion learning with deep convolutional generative adversarial networks.arXiv preprint arXiv:1511.06434(2015)
work page internal anchor Pith review arXiv 2015
-
[37]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[38]
Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.061251, 2 (2022), 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. 2024. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[41]
Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. FaceForensics++: Learning to Detect Manipulated Facial Images. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 1–11
2019
-
[42]
Chitwan Saharia et al. 2022. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.arXiv preprint arXiv:2205.11487(2022)
work page internal anchor Pith review arXiv 2022
-
[43]
Waqas Sultani, Chen Chen, and Mubarak Shah. 2018. Real-world anomaly de- tection in surveillance videos. InProceedings of the IEEE conference on computer vision and pattern recognition. 6479–6488
2018
-
[44]
Z-Image Team. 2025. Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.arXiv preprint arXiv:2511.22699(2025). Preprint, Apr 08, 2026, Arxiv Wang et al
work page internal anchor Pith review arXiv 2025
-
[45]
Dijana Tralic, Ivan Zupancic, Sonja Grgic, and Mislav Grgic. 2013. CoMoFoD: New Database for Copy-Move Forgery Detection. InProceedings ELMAR-2013. 49–54
2013
-
[46]
Junke Wang, Zuxuan Wu, Jingjing Chen, Xintong Han, Abhinav Shrivastava, Ser-Nam Lim, and Yu-Gang Jiang. 2022. ObjectFormer for Image Manipulation Detection and Localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2364–2373
2022
-
[47]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingku...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, Zhenda Xie, Yu Wu, Kai Hu, Jiawei Wang, Yaofeng Sun, Yukun Li, Yishi Piao, Kang Guan, Aixin Liu, Xin Xie, Yuxiang You, Kai Dong, Xingkai Yu, Haowei Zhang, Liang Zhao, Yisong Wang, and Chong Ruan. 2024. DeepSeek-VL2: Mixture-of-Experts...
work page internal anchor Pith review arXiv 2024
-
[49]
Zhipei Xu, Xuanyu Zhang, Runyi Li, Zecheng Tang, Qing Huang, and Jian Zhang
-
[50]
InInternational Conference on Learning Representations
FakeShield: Explainable Image Forgery Detection and Localization via Multi-modal Large Language Models. InInternational Conference on Learning Representations
-
[51]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. 2024. Depth Anything V2. InAdvances in Neural Information Processing Systems
2024
-
[52]
Candi Zheng, Yuan Lan, and Yang Wang. 2025. LanPaint: Training-Free Diffusion Inpainting with Asymptotically Exact and Fast Conditional Sampling.Transac- tions on Machine Learning Research(2025). https://openreview.net/forum?id= JPC8JyOUSW
2025
- [53]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.