Recognition: no theorem link
A Physical Agentic Loop for Language-Guided Grasping with Execution-State Monitoring
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Wrapping an unchanged grasp model with execution-state monitoring lets robots detect failures and recover in a bounded way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
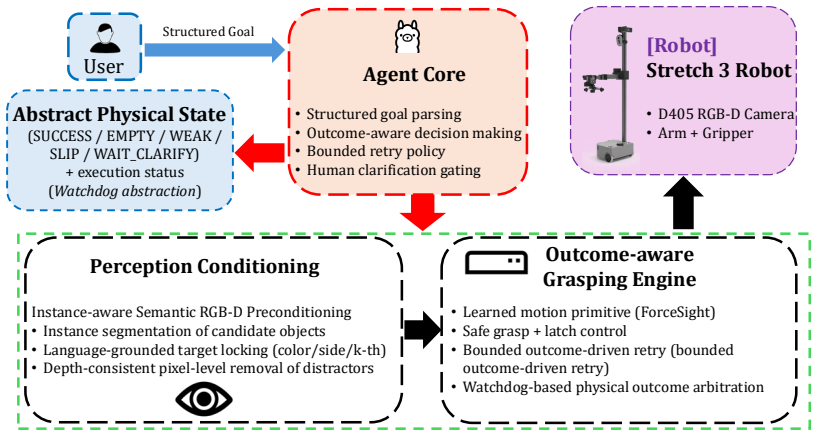
The paper presents a physical agentic loop that wraps an unmodified grasp-and-lift primitive with an event-based interface and an execution monitoring layer called Watchdog. Watchdog fuses contact-aware gripper telemetry and applies temporal stabilization to produce discrete labels for outcomes such as success, empty grasp, slip, stall, or timeout. These labels, optionally augmented by post-grasp semantic checks, drive a deterministic bounded policy that either finalizes the task, retries within limits, or escalates to the user, guaranteeing termination. Experiments on a mobile manipulator with eye-in-hand camera across cases of visual ambiguity, distractors, and forced failures show that on
What carries the argument
The Watchdog layer, which converts noisy gripper telemetry into discrete outcome labels via contact-aware fusion and temporal stabilization to feed a bounded recovery policy.
If this is right
- Failures such as slips and empty grasps become explicit events that the decision layer can act on.
- The bounded policy guarantees finite termination by limiting retries and offering escalation.
- The overall system stays interpretable because all outcomes are reduced to a small set of discrete states.
- The underlying learned grasp model requires no changes, keeping architectural overhead low.
Where Pith is reading between the lines
- The same monitoring wrapper could be applied to other manipulation primitives such as insertion or pouring without retraining the core model.
- Longer-horizon tasks could use the same outcome stream to trigger replanning rather than simple retry logic.
- If the telemetry-to-label mapping generalizes, similar loops could be added to mobile navigation or tool-use agents.
Load-bearing premise
The Watchdog layer can reliably turn noisy gripper telemetry into accurate discrete outcome labels in the tested scenarios.
What would settle it
A controlled run in which the Watchdog assigns the wrong label to a grasp outcome, such as reporting success on an empty gripper or failure on a secure lift, causing the policy to take an incorrect recovery action.
Figures





read the original abstract
Robotic manipulation systems that follow language instructions often execute grasp primitives in a largely single-shot manner: a model proposes an action, the robot executes it, and failures such as empty grasps, slips, stalls, timeouts, or semantically wrong grasps are not surfaced to the decision layer in a structured way. Inspired by agentic loops in digital tool-using agents, we reformulate language-guided grasping as a bounded embodied agent operating over grounded execution states, where physical actions expose an explicit tool-state stream. We introduce a physical agentic loop that wraps an unmodified learned manipulation primitive (grasp-and-lift) with (i) an event-based interface and (ii) an execution monitoring layer, Watchdog, which converts noisy gripper telemetry into discrete outcome labels using contact-aware fusion and temporal stabilization. These outcome events, optionally combined with post-grasp semantic verification, are consumed by a deterministic bounded policy that finalizes, retries, or escalates to the user for clarification, guaranteeing finite termination. We validate the resulting loop on a mobile manipulator with an eye-in-hand D405 camera, keeping the underlying grasp model unchanged and evaluating representative scenarios involving visual ambiguity, distractors, and induced execution failures. Results show that explicit execution-state monitoring and bounded recovery enable more robust and interpretable behavior than open-loop execution, while adding minimal architectural overhead. For the source code and demo refer to our project page: https://wenzewwz123.github.io/Agentic-Loop/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a physical agentic loop for language-guided grasping that wraps an unmodified grasp-and-lift primitive with an event-based interface and a Watchdog monitoring layer. Watchdog fuses noisy gripper telemetry via contact-aware methods and temporal stabilization to emit discrete outcome labels (empty grasp, slip, stall, timeout, semantic mismatch). These labels feed a deterministic bounded policy that finalizes, retries, or escalates to the user, optionally augmented by post-grasp semantic verification. The loop is evaluated on a mobile manipulator with eye-in-hand D405 camera across scenarios with visual ambiguity, distractors, and induced failures, with the claim that explicit state monitoring yields more robust and interpretable behavior than open-loop execution while adding minimal overhead.
Significance. If the monitoring layer produces reliable labels, the approach provides a lightweight, reusable mechanism for adding structured recovery and termination guarantees to existing learned manipulation primitives. This is a practical contribution toward more agentic robotic systems that surface physical execution states without retraining models or increasing architectural complexity. The bounded policy and source-code release are positive elements that support interpretability and reproducibility.
major comments (2)
- [Validation / Results description] The validation (described in the abstract and results) reports end-to-end robustness on representative scenarios but supplies no quantitative metrics, baselines, or error analysis. In particular, there are no precision/recall figures or confusion matrices for the five outcome classes produced by Watchdog against ground truth. This is load-bearing for the central claim that explicit execution-state monitoring enables more robust behavior than open-loop execution, because monitoring errors could themselves explain any observed gains or cause the bounded policy to propagate failures.
- [Watchdog execution monitoring layer] The weakest assumption—that contact-aware fusion and temporal stabilization reliably map noisy gripper telemetry to accurate discrete labels across failure modes—is not quantitatively tested. Without such data, it is impossible to determine whether the reported robustness stems from the monitoring layer or from the specific induced-failure scenarios chosen.
minor comments (1)
- [Abstract] The abstract states that 'results show' improved robustness but does not indicate whether the comparison to open-loop execution was qualitative, quantitative, or both; adding a brief clarification would help readers assess the strength of the evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where our validation can be strengthened. We address each major comment below and commit to revisions that will incorporate quantitative evaluation of the Watchdog layer.
read point-by-point responses
-
Referee: [Validation / Results description] The validation (described in the abstract and results) reports end-to-end robustness on representative scenarios but supplies no quantitative metrics, baselines, or error analysis. In particular, there are no precision/recall figures or confusion matrices for the five outcome classes produced by Watchdog against ground truth. This is load-bearing for the central claim that explicit execution-state monitoring enables more robust behavior than open-loop execution, because monitoring errors could themselves explain any observed gains or cause the bounded policy to propagate failures.
Authors: We agree that quantitative metrics are necessary to substantiate the central claim. In the revised manuscript we will add a dedicated evaluation subsection reporting precision, recall, and confusion matrices for the five Watchdog outcome classes against ground-truth labels collected from repeated trials. We will also include end-to-end success rates comparing the full agentic loop against open-loop execution, together with an error analysis that decomposes failures attributable to monitoring versus other sources. These additions will directly address whether monitoring errors could explain observed gains. revision: yes
-
Referee: [Watchdog execution monitoring layer] The weakest assumption—that contact-aware fusion and temporal stabilization reliably map noisy gripper telemetry to accurate discrete labels across failure modes—is not quantitatively tested. Without such data, it is impossible to determine whether the reported robustness stems from the monitoring layer or from the specific induced-failure scenarios chosen.
Authors: We acknowledge that the manuscript currently relies on end-to-end scenario demonstrations rather than isolated quantitative tests of the Watchdog mapping. We will add controlled experiments that induce each failure mode (empty grasp, slip, stall, timeout, semantic mismatch) and measure the accuracy of the contact-aware fusion and temporal stabilization steps against ground truth. The revised results will report these per-component metrics, allowing readers to assess the reliability of the monitoring layer independently of the chosen scenarios. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents a descriptive engineering architecture for a physical agentic loop that wraps an unmodified grasp primitive with an event-based interface and a Watchdog monitoring layer converting gripper telemetry to discrete labels via contact-aware fusion and temporal stabilization, followed by a deterministic bounded policy. No mathematical derivations, equations, fitted parameters, or self-citations appear as load-bearing elements in the central claim; the robustness argument rests on empirical validation across representative scenarios rather than any reduction to inputs by construction or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gripper telemetry can be fused with contact awareness and temporal stabilization to produce reliable discrete outcome labels
- domain assumption The bounded policy over outcome events will always terminate in finite steps
invented entities (1)
-
Watchdog execution monitoring layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Openclaw: An open-source autonomous ai agent framework,
E. O. P. Steinbergeret al., “Openclaw: An open-source autonomous ai agent framework,” 2026. [Online]. Available: https://github.com/o penclaw/openclaw
2026
-
[2]
Forcesight: Text-guided mobile manipulation with visual-force goals,
J. A. Collins, C. Houff, Y . L. Tan, and C. C. Kemp, “Forcesight: Text-guided mobile manipulation with visual-force goals,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 10 874–10 880
2024
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations (ICLR), 2023, also arXiv:2210.03629. [Online]. Available: https: //openreview.net/forum?id=WE vluYUL-X
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems (NeurIPS), 2023. [Online]. Available: https://arxiv.org/abs/2302.04761
work page internal anchor Pith review arXiv 2023
-
[5]
Cliport: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” inProceedings of the 5th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 2022, pp. 894–906. [Online]. Available: https://proceedings.mlr.press/v164/shridhar22a.html
2022
-
[6]
Perceiver-actor: A multi-task transformer for robotic manipulation,
——, “Perceiver-actor: A multi-task transformer for robotic manipulation,” inProceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, K. Liu, D. Kulic, and J. Ichnowski, Eds., vol. 205. PMLR, 2023, pp. 785–799. [Online]. Available: https://proceedings.mlr.press/v205/shridhar23a.html
2023
-
[7]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. Sanketi, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Julia...
2023
-
[8]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence, “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023. [Online...
work page internal anchor Pith review arXiv 2023
-
[9]
H. Zhanget al., “Vcot-grasp: Grasp foundation models with visual chain-of-thought reasoning for language-driven grasp generation,” arXiv preprint arXiv:2510.05827, 2025, preprint; no conference pub- lication confirmed as of 2026
-
[10]
Y . Cui, S. Karamcheti, R. Palleti, D. Sadigh, P. Liang, and J. Bohg, ““No, to the Right” – Online Language Corrections for Robotic Manipulation via Shared Autonomy,” inProceedings of the 2023 ACM/IEEE International Conference on Human- Robot Interaction (HRI), 2023, pp. 93–101. [Online]. Available: https://dl.acm.org/doi/10.1145/3568162.3578623
-
[11]
Correcting robot plans with natural language feedback,
P. Sharma, B. Sundaralingam, V . Blukis, C. Paxton, T. Hermans, A. Torralba, J. Andreas, and D. Fox, “Correcting robot plans with natural language feedback,” inRobotics: Science and Systems (RSS), 2022, also arXiv:2204.05186. [Online]. Available: https: //www.roboticsproceedings.org/rss18/p065.pdf
-
[12]
arXiv preprint arXiv:2410.00371 , year=
J. Duan, W. Pumacay, N. Kumar, Y . Wang, S. Tian, W. Yuan, Y . Guo, et al., “Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation,”arXiv preprint arXiv:2410.00371, 2024, preprint; no conference publication confirmed as of 2026
-
[13]
Fpc-vla: A vision- language-action framework with a supervisor for failure prediction and correction,
Y . Yang, Z. Duan, T. Xie, F. Cao, and J. Liu, “Fpc-vla: A vision- language-action framework with a supervisor for failure prediction and correction,”Expert Systems with Applications, 2026
2026
-
[14]
Diagnose, correct, and learn from manipulation failures via visual symbols,
X. Zeng, X. Zhou, Y . Li, J. Shi, T. Li,et al., “Diagnose, correct, and learn from manipulation failures via visual symbols,”arXiv preprint arXiv:2512.02787, 2025, preprint; no conference publication confirmed as of 2026
-
[15]
I-failsense: Towards general robotic failure detection with vision-language models,
C. Grislain, H. Rahimi, O. Sigaud, and M. Chetouani, “I-failsense: Towards general robotic failure detection with vision-language mod- els,”arXiv preprint arXiv:2509.16072, 2025, preprint; no conference publication confirmed as of 2026
-
[16]
Reflect: Summarizing robot experiences for failure explanation and correction,
Z. Liu, A. Bahety, and S. Song, “Reflect: Summarizing robot experiences for failure explanation and correction,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 2023, pp. 3468–3484. [Online]. Available: https://proceedings.mlr.press/v229/liu23g.html
2023
-
[17]
Guardian: Detecting robotic planning and execution errors with vision-language models,
P. Pacaud, R. Garcia, S. Chen, and C. Schmid, “Guardian: Detecting robotic planning and execution errors with vision-language models,”
-
[18]
Available: https://arxiv.org/abs/2512.01946
[Online]. Available: https://arxiv.org/abs/2512.01946
-
[19]
Maniagent: An agentic framework for general robotic manipulation,
o. Yang, “Maniagent: An agentic framework for general robotic manipulation,” 2025, preprint
2025
-
[20]
Agentic robot: A brain-inspired framework for vision-language-action models in embodied agents,
Z. Yang, Y . Chen, X. Zhou, J. Yan, D. Song, Y . Liu, Y . Li, Y . Zhang, P. Zhou, H. Chen, and L. Sun, “Agentic robot: A brain-inspired framework for vision-language-action models in embodied agents,”
-
[21]
Agentic robot: A brain-inspired framework for vision-language-action models in embodied agents,
[Online]. Available: https://arxiv.org/abs/2505.23450
-
[22]
Arrc: Advanced reasoning robot control—knowledge- driven autonomous manipulation using retrieval-augmented genera- tion,
o. V orobiov, “Arrc: Advanced reasoning robot control—knowledge- driven autonomous manipulation using retrieval-augmented genera- tion,” 2025, preprint
2025
-
[23]
Manipulate-anything: Automating real-world robots using vision-language models,
J. Duanet al., “Manipulate-anything: Automating real-world robots using vision-language models,” 2024, preprint
2024
-
[24]
Do as i can, not as i say: Grounding language in robotic affordances,
b. ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. Toshev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Luu,...
2023
-
[25]
Code as Policies: Language Model Programs for Embodied Control
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 9493–9500. [Online]. Available: https://arxiv.org/abs/2209.07753
work page internal anchor Pith review arXiv 2023
-
[26]
Progprompt: Generating situated robot task plans using large language models
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “Progprompt: Generating situated robot task plans using large language models,” in2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023. [Online]. Available: https://arxiv.org/abs/2209.11302
-
[27]
Hicrisp: An llm-based hierarchical closed-loop robotic intelligent self-correction planner,
C. Ming, J. Lin, P. Fong, H. Wang, X. Duan, and J. He, “Hicrisp: An llm-based hierarchical closed-loop robotic intelligent self-correction planner,” 2023. [Online]. Available: https://arxiv.org/abs/2309.12089
-
[28]
V oxposer: Composable 3d value maps for robotic manipulation with language models,
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxposer: Composable 3d value maps for robotic manipulation with language models,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 2023, pp. 540–562. [Online]. Available: https://pr...
2023
-
[29]
Sim2real transfer for vision-based grasp verification,
P. Amargant, P. H ¨onig, and M. Vincze, “Sim2real transfer for vision-based grasp verification,” inProceedings of the Austrian Robotics Workshop (ARW), 2025, accepted at ARW 2025; originally arXiv:2505.03046
-
[30]
Slip detection with combined tactile and visual information,
J. Li, S. Dong, and E. H. Adelson, “Slip detection with combined tactile and visual information,” in2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018. [Online]. Available: https://arxiv.org/abs/1802.10153
-
[31]
Stretch 3®: A Fully Integrated Mobile Manipulator,
Hello Robot Inc., “Stretch 3®: A Fully Integrated Mobile Manipulator,” Product page, [Online]. Available: https://hello- robot.com/stretch-3-product, accessed 2026-02-25. [Online]. Avail- able: https://hello-robot.com/stretch-3-product
2026
-
[32]
TinyLlama: An Open-Source Small Language Model
P. Zhang, G. Zeng, T. Wang, and W. Lu, “Tinyllama: An open-source small language model,”arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.