Recognition: 2 theorem links
· Lean TheoremRethinking Entropy Allocation in LLM-based ASR: Understanding the Dynamics between Speech Encoders and LLMs
Pith reviewed 2026-05-10 18:02 UTC · model grok-4.3
The pith
Rethinking entropy allocation between speech encoders and LLMs yields efficient ASR with fewer hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
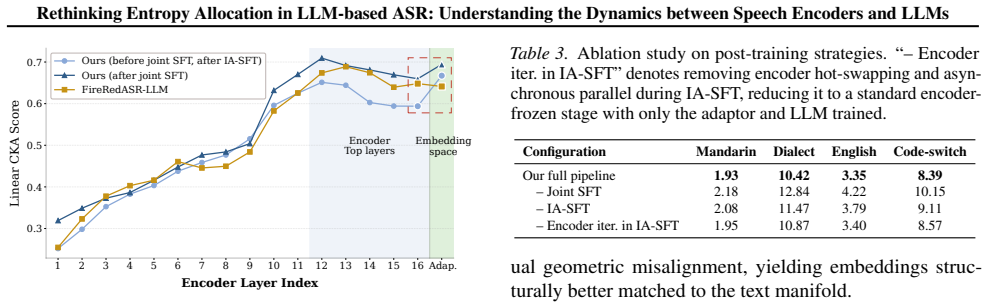
By measuring entropy allocation with three new metrics and applying a capability-boundary-aware multi-stage training strategy that includes redesigned pretraining plus iterative asynchronous SFT, LLM-based ASR models achieve strong recognition performance at lower parameter counts while constraining encoder drift and reducing hallucinations.
What carries the argument
Three metrics that quantify entropy reduction sharing between encoder and LLM, together with a multi-stage pipeline that uses asynchronous supervised fine-tuning to maintain functional decoupling after initial alignment.
Load-bearing premise
The three metrics correctly capture the meaningful dynamics of entropy allocation between encoder and LLM.
What would settle it
Training a baseline model with the proposed multi-stage strategy but observing no reduction in hallucination rate or no gain in word error rate on the Mandarin and English test sets.
Figures




read the original abstract
Integrating large language models (LLMs) into automatic speech recognition (ASR) has become a dominant paradigm. Although recent LLM-based ASR models have shown promising performance on public benchmarks, it remains challenging to balance recognition quality with latency and overhead, while hallucinations further limit real-world deployment. In this study, we revisit LLM-based ASR from an entropy allocation perspective and introduce three metrics to characterize how training paradigms allocate entropy reduction between the speech encoder and the LLM. To remedy entropy-allocation inefficiencies in prevailing approaches, we propose a principled multi-stage training strategy grounded in capability-boundary awareness, optimizing parameter efficiency and hallucination robustness. Specifically, we redesign the pretraining strategy to alleviate the speech-text modality gap, and further introduce an iterative asynchronous SFT stage between alignment and joint SFT to preserve functional decoupling and constrain encoder representation drift. Experiments on Mandarin and English benchmarks show that our method achieves competitive performance with state-of-the-art models using only 2.3B parameters, while also effectively mitigating hallucinations through our decoupling-oriented design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based ASR can be improved by analyzing entropy allocation between speech encoders and LLMs. It introduces three metrics to characterize entropy reduction dynamics under different training paradigms, then proposes a multi-stage strategy: redesigned pretraining to reduce the speech-text modality gap, followed by an iterative asynchronous supervised fine-tuning (SFT) stage between alignment and joint SFT to preserve functional decoupling. Experiments on Mandarin and English benchmarks are said to yield competitive results versus state-of-the-art models with a 2.3B-parameter model while mitigating hallucinations.
Significance. If the entropy metrics prove to be valid, independent diagnostics and the asynchronous SFT demonstrably maintains decoupling without degrading recognition quality, the work could meaningfully advance parameter-efficient and hallucination-robust LLM-ASR systems. The emphasis on capability-boundary awareness and staged training offers a principled alternative to standard joint fine-tuning approaches.
major comments (3)
- [Section introducing the three metrics] The three entropy metrics are load-bearing for the central claim yet lack explicit mathematical definitions or normalization procedures (e.g., how entropy reduction is partitioned between encoder and LLM or how it is normalized across layers). Without these formulas, it is impossible to determine whether the metrics are diagnostic tools or post-hoc descriptors of the training process itself.
- [Experimental section / ablation studies] No ablations or controlled experiments are described that test whether the metrics respond predictably when encoder or LLM capacity is deliberately altered (e.g., by freezing components or varying parameter counts). This absence weakens the assertion that the metrics accurately capture allocation dynamics and that the iterative asynchronous SFT preserves functional decoupling.
- [Results and Experiments] The abstract and summary report competitive performance and hallucination reduction but supply no quantitative baselines, statistical significance tests, error bars, or exact metric definitions. Without these details, the performance claims cannot be evaluated for robustness.
minor comments (2)
- [Abstract and Experiments] Clarify the exact benchmarks (e.g., specific Mandarin and English datasets) and the precise definition of 'hallucination' used in the evaluation.
- [Notation and Figures] Ensure all notation for entropy quantities is introduced before first use and remains consistent across figures and text.
Simulated Author's Rebuttal
We sincerely thank the referee for their thorough and constructive feedback. The comments highlight important opportunities to improve clarity, experimental validation, and reporting rigor in our work on entropy allocation for LLM-based ASR. We address each major comment point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Section introducing the three metrics] The three entropy metrics are load-bearing for the central claim yet lack explicit mathematical definitions or normalization procedures (e.g., how entropy reduction is partitioned between encoder and LLM or how it is normalized across layers). Without these formulas, it is impossible to determine whether the metrics are diagnostic tools or post-hoc descriptors of the training process itself.
Authors: We acknowledge that greater explicitness is needed in presenting the three entropy metrics (Encoder Entropy Reduction, LLM Entropy Reduction, and Allocation Ratio). These are introduced in Section 3.2 based on information-theoretic entropy differences pre- and post-processing, with the allocation ratio defined as their normalized quotient. However, the exact partitioning formula and layer-wise normalization (e.g., dividing by the maximum possible entropy for the given sequence length) were described at a conceptual level rather than with full equations. In the revised manuscript, we will add the complete mathematical definitions, including the normalization procedure normalized_reduction = (H_before - H_after) / H_before, along with a computation algorithm. This will establish the metrics as diagnostic tools grounded in the training dynamics rather than post-hoc descriptors. revision: yes
-
Referee: [Experimental section / ablation studies] No ablations or controlled experiments are described that test whether the metrics respond predictably when encoder or LLM capacity is deliberately altered (e.g., by freezing components or varying parameter counts). This absence weakens the assertion that the metrics accurately capture allocation dynamics and that the iterative asynchronous SFT preserves functional decoupling.
Authors: The referee correctly identifies the value of controlled ablations for validating the metrics' sensitivity to capacity changes and the decoupling benefits of asynchronous SFT. While our experiments compare training paradigms (redesigned pretraining and iterative SFT variants) on fixed 2.3B models, we did not include deliberate alterations such as freezing encoder layers or scaling LLM parameter counts. We agree this limits the strength of our claims. In the revision, we will incorporate a new ablation subsection with experiments that freeze the speech encoder during SFT stages and measure resulting shifts in the entropy metrics, plus variants with reduced LLM capacity. These will show predictable metric responses and confirm that asynchronous SFT maintains decoupling without quality loss. revision: yes
-
Referee: [Results and Experiments] The abstract and summary report competitive performance and hallucination reduction but supply no quantitative baselines, statistical significance tests, error bars, or exact metric definitions. Without these details, the performance claims cannot be evaluated for robustness.
Authors: We thank the referee for emphasizing the need for robust quantitative reporting. The manuscript presents benchmark results in Tables 1-3, comparing our model against SOTA LLM-ASR and Whisper variants on Mandarin and English test sets using CER/WER and hallucination rate metrics. However, we omitted error bars, statistical tests, and fully explicit metric definitions in the main results (with some details in the appendix). In the revised version, we will expand the results section to report means and standard deviations across three random seeds, include paired t-test p-values against key baselines, and move the exact definitions of all metrics (including the three entropy metrics with formulas) into the main text. This will allow proper assessment of the competitive performance and hallucination mitigation. revision: yes
Circularity Check
No circularity: metrics are diagnostic, performance claims rest on experiments
full rationale
The paper introduces three entropy metrics as tools to characterize allocation dynamics and grounds its multi-stage training strategy in capability-boundary awareness, but the abstract and context provide no equations showing these metrics defined in terms of the performance outcomes they diagnose or any fitted parameters renamed as predictions. No self-citation chains, uniqueness theorems, or ansatz smuggling are referenced as load-bearing for the central claims. The reported competitive results with 2.3B parameters and hallucination mitigation are presented as experimental outcomes, not reductions to the metrics by construction. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Entropy reduction between speech encoder and LLM can be meaningfully separated and measured by the three introduced metrics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce three metrics to characterize how training paradigms allocate entropy reduction between the speech encoder and the LLM... Normalized spectral entropy (NSE)... Phonetic accessible information (PAI)... conditional semantic accessible information (CSAI)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
capability-boundary-aware design principle... iterative asynchronous SFT stage... preserve functional decoupling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
NIM4-ASR: Towards Efficient, Robust, and Customizable Real-Time LLM-Based ASR
NIM4-ASR delivers SOTA ASR performance on public benchmarks using a 2.3B-parameter LLM with multi-stage training, real-time streaming, and million-scale hotword customization via RAG.
Reference graph
Works this paper leans on
-
[1]
An, K., Chen, Y ., Deng, C., Gao, C., Gao, Z., Gong, B., Li, X., Li, Y ., Lv, X., Ji, Y ., et al. Funaudio-asr technical report.arXiv preprint arXiv:2509.12508,
-
[2]
Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition
Bai, Y ., Chen, J., Chen, J., Chen, W., Chen, Z., Ding, C., Dong, L., Dong, Q., Du, Y ., Gao, K., et al. Seed-asr: Un- derstanding diverse speech and contexts with llm-based speech recognition.arXiv preprint arXiv:2407.04675, 2024a. Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., and Shou, M. Z. Hallucination of multimodal large language models: ...
-
[3]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,
Chen, G., Chai, S., Wang, G., Du, J., Zhang, W.-Q., Weng, C., Su, D., Povey, D., Trmal, J., Zhang, J., et al. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio.arXiv preprint arXiv:2106.06909,
-
[4]
Chu, Y ., Xu, J., Yang, Q., Wei, H., Wei, X., Guo, Z., Leng, Y ., Lv, Y ., He, J., Lin, J., et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759,
work page internal anchor Pith review arXiv
-
[5]
Dai, Y ., Zhang, Z., Wang, S., Li, L., Guo, Z., Zuo, T., Wang, S., Xue, H., Wang, C., Wang, Q., et al. Wenetspeech- chuan: A large-scale sichuanese corpus with rich anno- tation for dialectal speech processing.arXiv preprint arXiv:2509.18004,
-
[6]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review arXiv
-
[7]
Ding, D., Ju, Z., Leng, Y ., Liu, S., Liu, T., Shang, Z., Shen, K., Song, W., Tan, X., Tang, H., et al. Kimi-audio techni- cal report.arXiv preprint arXiv:2504.18425,
work page internal anchor Pith review arXiv
-
[8]
Aishell-2: Transform- ing mandarin asr research into industrial scale,
Du, J., Na, X., Liu, X., and Bu, H. Aishell-2: Transforming mandarin asr research into industrial scale.arXiv preprint arXiv:1808.10583,
-
[9]
Endo, M. and Yeung-Levy, S. Downscaling intelligence: Exploring perception and reasoning bottlenecks in small multimodal models.arXiv preprint arXiv:2511.17487,
-
[10]
The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage,
Galvez, D., Diamos, G., Ciro, J., Cer´on, J. F., Achorn, K., Gopi, A., Kanter, D., Lam, M., Mazumder, M., and Reddi, V . J. The people’s speech: A large-scale diverse english speech recognition dataset for commercial usage.arXiv preprint arXiv:2111.09344,
-
[11]
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models
Goel, A., Ghosh, S., Kim, J., Kumar, S., Kong, Z., Lee, S.-g., Yang, C.-H. H., Duraiswami, R., Manocha, D., Valle, R., et al. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. arXiv preprint arXiv:2507.08128,
work page internal anchor Pith review arXiv
-
[12]
Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
Graves, A. Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
-
[13]
Conformer: Convolution- augmented transformer for speech recognition,
Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y ., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y ., et al. Con- former: Convolution-augmented transformer for speech recognition.arXiv preprint arXiv:2005.08100,
-
[14]
Libriheavy: A 50,000 hours asr corpus with punctuation casing and context
Kang, W., Yang, X., Yao, Z., Kuang, F., Yang, Y ., Guo, L., Lin, L., and Povey, D. Libriheavy: A 50,000 hours asr corpus with punctuation casing and context. InICASSP 2024-2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), pp. 10991– 10995. IEEE,
2024
-
[15]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Koluguri, N. R., Sekoyan, M., Zelenfroynd, G., Meister, S., Ding, S., Kostandian, S., Huang, H., Karpov, N., Balam, J., Lavrukhin, V ., et al. Granary: Speech recognition and translation dataset in 25 european languages.arXiv preprint arXiv:2505.13404,
-
[17]
Li, S., You, Y ., Wang, X., Tian, Z., Ding, K., and Wan, G. Msr-86k: An evolving, multilingual corpus with 86,300 hours of transcribed audio for speech recognition research. arXiv preprint arXiv:2406.18301,
-
[18]
Liu, A. H., Ehrenberg, A., Lo, A., Denoix, C., Barreau, C., Lample, G., Delignon, J.-M., Chandu, K. R., von Platen, P., Muddireddy, P. R., et al. V oxtral.arXiv preprint arXiv:2507.13264,
-
[19]
O’Neill, P. K., Lavrukhin, V ., Majumdar, S., Noroozi, V ., Zhang, Y ., Kuchaiev, O., Balam, J., Dovzhenko, Y ., Frey- berg, K., Shulman, M. D., et al. Spgispeech: 5,000 hours of transcribed financial audio for fully formatted end-to- end speech recognition.arXiv preprint arXiv:2104.02014,
-
[20]
A survey on speech large language models for understanding,
Peng, J., Wang, Y ., Li, B., Guo, Y ., Wang, H., Fang, Y ., Xi, Y ., Li, H., Li, X., Zhang, K., et al. A survey on speech large language models for understanding.arXiv preprint arXiv:2410.18908,
- [21]
-
[22]
W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I
Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. Whisper: Robust speech recogni- tion via large-scale weak supervision.arXiv preprint arXiv:2212.01234,
-
[23]
Shi, X., Wang, X., Guo, Z., Wang, Y ., Zhang, P., Zhang, X., Guo, Z., Hao, H., Xi, Y ., Yang, B., et al. Qwen3-asr technical report.arXiv preprint arXiv:2601.21337,
work page internal anchor Pith review arXiv
-
[24]
Step-audio 2 technical report.arXiv preprint arXiv:2507.16632, 2025
10 Rethinking Entropy Allocation in LLM-based ASR: Understanding the Dynamics between Speech Encoders and LLMs Wu, B., Yan, C., Hu, C., Yi, C., Feng, C., Tian, F., Shen, F., Yu, G., Zhang, H., Li, J., et al. Step-audio 2 technical report.arXiv preprint arXiv:2507.16632,
-
[25]
Xia, Y ., Tang, J., Hou, J., Xu, G., and Yao, H. Uni-asr: Unified llm-based architecture for non-streaming and streaming automatic speech recognition.arXiv preprint arXiv:2603.11123,
-
[26]
Xu, J., Guo, Z., Hu, H., Chu, Y ., Wang, X., He, J., Wang, Y ., Shi, X., He, T., Zhu, X., et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025a. Xu, K.-T., Xie, F.-L., Tang, X., and Hu, Y . Fireredasr: Open-source industrial-grade mandarin speech recogni- tion models from encoder-decoder to llm integration. arXiv preprint arXiv:2501.14...
work page internal anchor Pith review arXiv
-
[27]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Yao, Z., Kang, W., Yang, X., Kuang, F., Guo, L., Zhu, H., Jin, Z., Li, Z., Lin, L., and Povey, D. Cr-ctc: Consistency regularization on ctc for improved speech recognition. arXiv preprint arXiv:2410.05101,
-
[29]
Zeng, A., Du, Z., Liu, M., Wang, K., Jiang, S., Zhao, L., Dong, Y ., and Tang, J. Glm-4-voice: Towards intelli- gent and human-like end-to-end spoken chatbot.arXiv preprint arXiv:2412.02612,
-
[30]
Why does CTC result in peaky behavior?
Zeyer, A., Schl¨uter, R., and Ney, H. Why does ctc result in peaky behavior?arXiv preprint arXiv:2105.14849,
-
[31]
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition
Zhang, B., Lv, H., Guo, P., Shao, Q., Yang, C., Xie, L., Xu, X., Bu, H., Chen, X., Zeng, C., et al. Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. InICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6182–6186. IEEE,
2022
-
[32]
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition
Zhang, Y ., Xu, M., Bai, X., Zhang, P., Xiang, Y ., Zhang, M., et al. Instruction anchors: Dissecting the causal dynamics of modality arbitration.arXiv preprint arXiv:2602.03677,
work page internal anchor Pith review arXiv
-
[33]
Zhou, G., Yan, Y ., Zou, X., Wang, K., Liu, A., and Hu, X. Mitigating modality prior-induced hallucinations in mul- timodal large language models via deciphering attention causality.arXiv preprint arXiv:2410.04780,
-
[34]
Zhou, J., Guo, Y ., Zhao, S., Sun, H., Wang, H., He, J., Kong, A., Wang, S., Yang, X., Wang, Y ., et al. Cs- dialogue: A 104-hour dataset of spontaneous mandarin- english code-switching dialogues for speech recognition. arXiv preprint arXiv:2502.18913, 2025a. Zhou, W., Jia, J., Sari, L., Mahadeokar, J., and Kalinli, O. Cjst: Ctc compressor based joint spe...
-
[35]
Mandarin English Code Switch Conversation 10 In-house data English / Mandarin Conversation ∼50K Total English / Mandarin All ∼560K A.2. Our LLM-based ASR Architecture Feature extraction.We extract 80-dimensional log-Mel spectrograms using a 25ms window and a 10ms frame shift, followed by global mean and variance normalization. Speech encoder.The backbone ...
2020
-
[36]
is used across all training stages. Experiments are conducted on NVIDIA A100 80GB GPUs using DeepSpeed ZeRO Stage-2 (Rajbhandari et al., 2020), with gradient accumulation over 4 steps, bfloat16 precision, and FlashAttention-2 (Dao, 2023). A.4. Training Details of IA-SFT Here, we provide additional details on the implementation of IA-SFT. CKA-guided encode...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.