Recognition: no theorem link
Multimodal Reasoning with LLM for Encrypted Traffic Interpretation: A Benchmark
Pith reviewed 2026-05-10 17:57 UTC · model grok-4.3
The pith
A multimodal LLM framework generates evidence-grounded explanations for encrypted network traffic while preserving classification accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the BGTD benchmark, by supplying raw bytes paired with expert annotations, supports the mmTraffic framework in producing high-fidelity, human-readable, evidence-grounded traffic interpretation reports with classification accuracy competitive to unimodal models like NetMamba, through a jointly-optimized perception-cognition architecture.
What carries the argument
The mmTraffic framework, consisting of a perception-centered traffic encoder and a cognition-centered LLM generator that jointly optimize to bridge physical encoding and semantic interpretation while reducing modality interference.
If this is right
- Enables production of verifiable chains of evidence for traffic classifications.
- Overcomes black-box limitations by generating human-readable reports.
- Maintains competitive accuracy against specialized unimodal models.
- Supports multidimensional semantic capture beyond unimodal patterns.
Where Pith is reading between the lines
- The benchmark may facilitate development of similar explainable systems for other data modalities in security.
- Real-time deployment could provide operators with actionable insights rather than raw labels.
- Future reductions in annotation requirements could broaden applicability to diverse traffic types.
Load-bearing premise
The expert annotations in BGTD accurately and comprehensively represent traffic behaviors without bias that would limit generalization to new patterns.
What would settle it
Evaluation by independent experts finds the generated reports deviate from the BGTD annotations or include unsupported claims, or accuracy tests show mmTraffic underperforming NetMamba on standard encrypted traffic datasets.
Figures




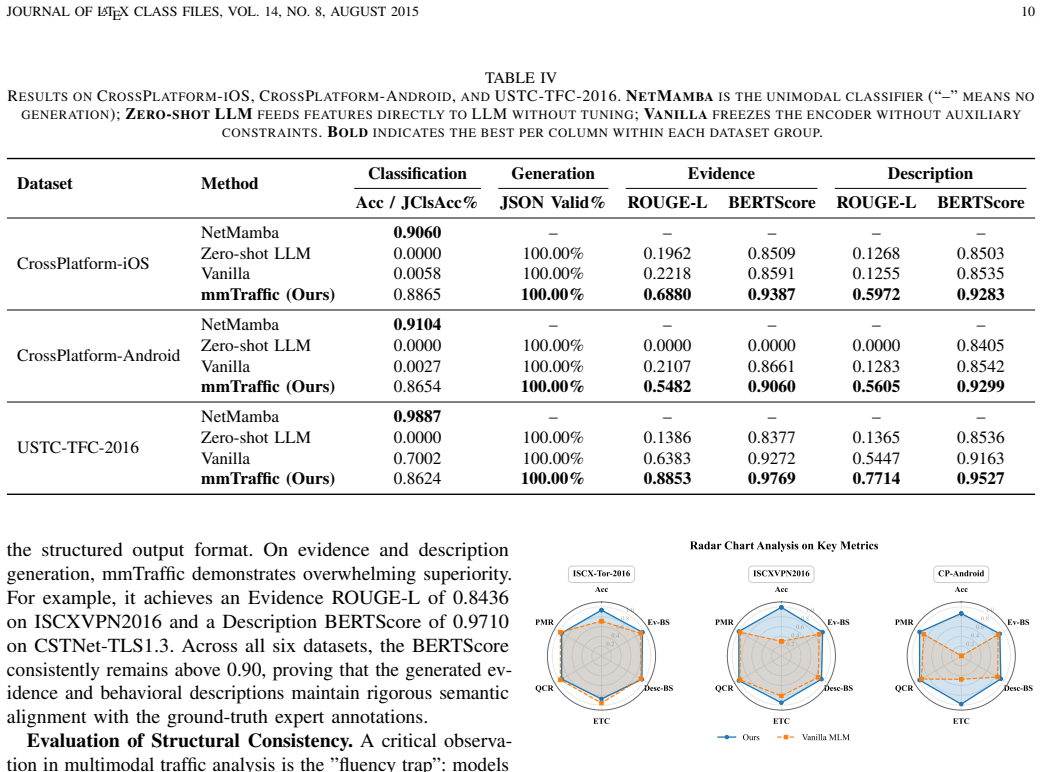
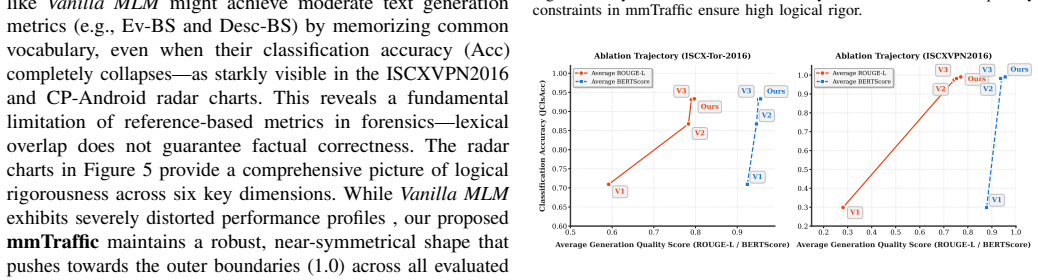
read the original abstract
Network traffic, as a key media format, is crucial for ensuring security and communications in modern internet infrastructure. While existing methods offer excellent performance, they face two key bottlenecks: (1) They fail to capture multidimensional semantics beyond unimodal sequence patterns. (2) Their black box property, i.e., providing only category labels, lacks an auditable reasoning process. We identify a key factor that existing network traffic datasets are primarily designed for classification and inherently lack rich semantic annotations, failing to generate human-readable evidence report. To address data scarcity, this paper proposes a Byte-Grounded Traffic Description (BGTD) benchmark for the first time, combining raw bytes with structured expert annotations. BGTD provides necessary behavioral features and verifiable chains of evidence for multimodal reasoning towards explainable encrypted traffic interpretation. Built upon BGTD, this paper proposes an end-to-end traffic-language representation framework (mmTraffic), a multimodal reasoning architecture bridging physical traffic encoding and semantic interpretation. In order to alleviate modality interference and generative hallucinations, mmTraffic adopts a jointly-optimized perception-cognition architecture. By incorporating a perception-centered traffic encoder and a cognition-centered LLM generator, mmTraffic achieves refined traffic interpretation with guaranteed category prediction. Extensive experiments demonstrate that mmTraffic autonomously generates high-fidelity, human-readable, and evidence-grounded traffic interpretation reports, while maintaining highly competitive classification accuracy comparing to specialized unimodal model (e.g., NetMamba). The source code is available at https://github.com/lgzhangzlg/Multimodal-Reasoning-with-LLM-for-Encrypted-Traffic-Interpretation-A-Benchmark
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes the Byte-Grounded Traffic Description (BGTD) benchmark, which pairs raw encrypted traffic bytes with structured expert annotations to enable multimodal reasoning for explainable traffic classification. It introduces mmTraffic, an end-to-end multimodal framework featuring a perception-centered traffic encoder and a cognition-centered LLM generator that are jointly optimized to generate human-readable, evidence-grounded interpretation reports while ensuring accurate category predictions. The work demonstrates that mmTraffic achieves competitive classification accuracy compared to unimodal models such as NetMamba, while providing interpretable outputs that address the black-box limitations of existing methods.
Significance. If the empirical claims are substantiated, this work would represent a meaningful advance in applying multimodal LLMs to network traffic analysis. By creating a benchmark with semantic annotations and a framework that bridges low-level byte data with high-level interpretations, it could facilitate more auditable and trustworthy systems for encrypted traffic interpretation in security applications. The joint optimization approach to mitigate hallucinations and modality interference is a notable technical contribution that could influence future designs in multimodal AI for specialized domains.
major comments (3)
- [BGTD Benchmark] The manuscript provides no information on the annotation protocol, inter-annotator agreement, or validation of the expert annotations in BGTD. This is a load-bearing issue for the claims of 'high-fidelity' and 'evidence-grounded' reports, as these are measured against BGTD annotations; without such details, the reliability of the ground truth cannot be assessed.
- [Experiments] The paper reports competitive accuracy but omits quantitative details on hallucination rates, ablation studies for the jointly-optimized architecture, and controls demonstrating that category prediction is 'guaranteed' independently of the generative process. These omissions undermine the central claim that the framework alleviates generative hallucinations while maintaining accuracy.
- [mmTraffic Architecture] The description of how the perception module enforces category prediction to 'guarantee' it during report generation lacks sufficient technical detail or experimental validation, particularly regarding the prevention of modality interference between the traffic encoder and LLM generator.
minor comments (1)
- The abstract claims 'guaranteed category prediction' but this terminology should be clarified or supported with specific metrics in the main text to avoid overstatement.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the presentation of BGTD, the experimental validation, and the technical description of mmTraffic. We address each major comment below and will revise the manuscript to incorporate additional details and clarifications where needed.
read point-by-point responses
-
Referee: [BGTD Benchmark] The manuscript provides no information on the annotation protocol, inter-annotator agreement, or validation of the expert annotations in BGTD. This is a load-bearing issue for the claims of 'high-fidelity' and 'evidence-grounded' reports, as these are measured against BGTD annotations; without such details, the reliability of the ground truth cannot be assessed.
Authors: We agree that the current version of the manuscript does not sufficiently detail the annotation process. In the revised manuscript, we will add a new subsection under the BGTD benchmark description that specifies the annotation protocol, including expert selection criteria, annotation guidelines, inter-annotator agreement statistics (such as Fleiss' kappa), and validation steps used to ensure annotation quality. This addition will directly support the claims of high-fidelity and evidence-grounded reports. revision: yes
-
Referee: [Experiments] The paper reports competitive accuracy but omits quantitative details on hallucination rates, ablation studies for the jointly-optimized architecture, and controls demonstrating that category prediction is 'guaranteed' independently of the generative process. These omissions undermine the central claim that the framework alleviates generative hallucinations while maintaining accuracy.
Authors: We acknowledge the need for more quantitative evidence. The revised manuscript will include explicit hallucination rate measurements (e.g., via entailment-based consistency checks against BGTD annotations), comprehensive ablation studies isolating the effects of joint optimization, and control experiments that isolate the perception module's category prediction from the generative output. These additions will strengthen the demonstration that hallucinations are mitigated without sacrificing classification performance. revision: yes
-
Referee: [mmTraffic Architecture] The description of how the perception module enforces category prediction to 'guarantee' it during report generation lacks sufficient technical detail or experimental validation, particularly regarding the prevention of modality interference between the traffic encoder and LLM generator.
Authors: We will expand the architecture section with additional technical details on the perception-centered encoder, including the specific joint optimization objective that couples classification loss with generation constraints. We will also add experimental validation, such as modality interference metrics and comparisons between jointly-trained and separately-trained variants, to demonstrate how category prediction is enforced independently of the LLM generation process. revision: yes
Circularity Check
No circularity in derivation or claims
full rationale
The paper introduces BGTD as an external benchmark with structured expert annotations and mmTraffic as a multimodal architecture evaluated empirically against independent unimodal baselines (e.g., NetMamba). No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims of high-fidelity reports and competitive accuracy rest on standard train/eval splits and external comparisons rather than quantities defined by the paper's own inputs or derivations. The annotation process is presented as an independent contribution, not derived from model outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Distiller: Encrypted traffic classification via multimodal multitask deep learning,
G. Aceto, D. Ciuonzo, A. Montieri, and A. Pescap ´e, “Distiller: Encrypted traffic classification via multimodal multitask deep learning,”Journal of Network and Computer Applications, vol. 183, p. 102985, 2021
2021
-
[2]
Securebert: A domain- specific language model for cybersecurity,
E. Aghaei, X. Niu, W. Shadid, and E. Al-Shaer, “Securebert: A domain- specific language model for cybersecurity,” ininternational conference on security and privacy in communication systems, 2022, pp. 39–56
2022
-
[3]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynoldset al., “Flamingo: a visual language model for few-shot learning,”NeurIPS, pp. 23 716–23 736, 2022
2022
-
[4]
Semantic-driven interpretable deep multi-modal hashing for large-scale multimedia retrieval,
Anonymous, “Semantic-driven interpretable deep multi-modal hashing for large-scale multimedia retrieval,”IEEE Transactions on Multimedia, vol. 23, 2021
2021
-
[5]
Explainable artificial intelligence (xai): Concepts, taxonomies, opportu- nities and challenges toward responsible ai,
A. B. Arrieta, N. D ´ıaz-Rodr´ıguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. Garc ´ıa, S. Gil-L´opez, D. Molina, R. Benjaminset al., “Explainable artificial intelligence (xai): Concepts, taxonomies, opportu- nities and challenges toward responsible ai,”Information fusion, vol. 58, pp. 82–115, 2020
2020
-
[6]
Mpaf: Encrypted traffic classification with multi- phase attribute fingerprint,
Y . Chen and Y . Wang, “Mpaf: Encrypted traffic classification with multi- phase attribute fingerprint,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 7091–7105, 2024
2024
-
[7]
T. Cui, X. Lin, S. Li, M. Chen, Q. Yin, Q. Li, and K. Xu, “Trafficllm: Enhancing large language models for network traffic analysis with generic traffic representation,”arXiv preprint arXiv:2504.04222, 2025
-
[8]
Instructblip: Towards general-purpose vision-language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P. N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision-language models with instruction tuning,”NeurIPS, pp. 49 250–49 267, 2023
2023
-
[9]
Tor: The second- generation onion router,
R. Dingledine, N. Mathewson, and P. Syverson, “Tor: The second- generation onion router,” 2004
2004
-
[10]
Deep learning and pre- training technology for encrypted traffic classification: A comprehensive review,
W. Dong, J. Yu, X. Lin, G. Gou, and G. Xiong, “Deep learning and pre- training technology for encrypted traffic classification: A comprehensive review,”Neurocomputing, vol. 617, p. 128444, 2025
2025
-
[11]
Characterization of encrypted and vpn traffic using time-related,
G. Draper-Gil, A. H. Lashkari, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of encrypted and vpn traffic using time-related,” in ICISSP, 2016, pp. 407–414
2016
-
[12]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
P. Goyal, P. Doll´ar, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tulloch, Y . Jia, and K. He, “Accurate, large minibatch sgd: Training imagenet in 1 hour,”arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review arXiv 2017
-
[13]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst conference on language modeling, 2024
2024
-
[14]
Ld-man: Layout-driven multimodal attention network for online news sentiment recognition,
W. Guo, Y . Zhang, X. Cai, L. Meng, J. Yang, and X. Yuan, “Ld-man: Layout-driven multimodal attention network for online news sentiment recognition,”IEEE Transactions on Multimedia, 2020
2020
-
[15]
Text-to-image person re- identification based on multimodal graph convolutional network,
G. Han, M. Lin, Z. Li, H. Zhao, and S. Kwong, “Text-to-image person re- identification based on multimodal graph convolutional network,”IEEE Transactions on Multimedia, vol. 26, 2024
2024
-
[16]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” Iclr, 2022
2022
-
[17]
Characterization of tor traffic using time based features,
A. H. Lashkari, G. D. Gil, M. S. I. Mamun, and A. A. Ghorbani, “Characterization of tor traffic using time based features,” inISSP, vol. 2, 2017, pp. 253–262
2017
-
[18]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[19]
Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification,
X. Lin, G. Xiong, G. Gou, Z. Li, J. Shi, and J. Yu, “Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification,” inProceedings of the ACM Web Conference 2022, 2022
2022
-
[20]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”NeurIPS, vol. 36, pp. 34 892–34 916, 2023
2023
-
[21]
Is chatgpt a good recommender? a preliminary study,
J. Liu, C. Liu, P. Zhou, R. Lv, K. Zhou, and Y . Zhang, “Is chatgpt a good recommender? a preliminary study,”arXiv, 2023
2023
-
[22]
Flowletformer: Network behavioral semantic aware pre-training model for traffic classification,
L. Liu, R. Li, Q. Li, M. Hou, Y . Jiang, and M. Xu, “Flowletformer: Network behavioral semantic aware pre-training model for traffic classification,”arXiv preprint arXiv:2508.19924, 2025
-
[23]
Depth-aware and semantic guided relational attention network for visual question answering,
Y . Liu, W. Wei, D. Peng, X.-L. Mao, Z. He, and P. Zhou, “Depth-aware and semantic guided relational attention network for visual question answering,”IEEE Transactions on Multimedia, 2022
2022
-
[24]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”NeurIPS, vol. 30, 2017
2017
-
[26]
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkateshet al., “Mixed precision training,”arXiv preprint arXiv:1710.03740, 2017
work page internal anchor Pith review arXiv 2017
-
[27]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[28]
Zero: Memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: Memory optimizations toward training trillion parameter models,” inSC20: international conference for high performance computing, networking, storage and analysis. IEEE, 2020, pp. 1–16
2020
-
[29]
An international view of privacy risks for mobile apps,
J. Ren, D. Dubois, and D. Choffnes, “An international view of privacy risks for mobile apps,”Tech. Rep, 2019
2019
-
[30]
Why should i trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin, “Why should i trust you?” explaining the predictions of any classifier,” inACM SIGKDD, 2016
2016
-
[31]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inICCV, Oct 2017
2017
-
[32]
Robust detection of malicious encrypted traffic via contrastive learning,
M. Shen, J. Wu, K. Ye, K. Xu, G. Xiong, and L. Zhu, “Robust detection of malicious encrypted traffic via contrastive learning,”IEEE Transactions on Information Forensics and Security, vol. 20, pp. 4228–4242, 2025
2025
-
[33]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[34]
Netmamba: Efficient network traffic classification via pre-training unidirectional mamba,
T. Wang, X. Xie, W. Wang, C. Wang, Y . Zhao, and Y . Cui, “Netmamba: Efficient network traffic classification via pre-training unidirectional mamba,”arXiv preprint arXiv:2405.11449, 2024
-
[35]
Malware traffic classification using convolutional neural network for representation learning,
W. Wang, M. Zhu, X. Zeng, X. Ye, and Y . Sheng, “Malware traffic classification using convolutional neural network for representation learning,” inICOIN, 2017, pp. 712–717
2017
-
[36]
Qwen3 technical report,
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv, 2025
2025
-
[37]
Bertscore: Evaluating text generation with bert,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “Bertscore: Evaluating text generation with bert,”arXiv, 2019
2019
-
[38]
Yet another traffic classifier: A masked autoencoder based traffic transformer with multi-level flow representation,
R. Zhao, M. Zhan, X. Deng, Y . Wang, Y . Wang, G. Gui, and Z. Xue, “Yet another traffic classifier: A masked autoencoder based traffic transformer with multi-level flow representation,” inAAAI, vol. 37, 2023
2023
-
[39]
Wf-transformer: Learning temporal features for accurate anonymous traffic identification by using transformer networks,
Q. Zhou, L. Wang, H. Zhu, T. Lu, and V . S. Sheng, “Wf-transformer: Learning temporal features for accurate anonymous traffic identification by using transformer networks,”IEEE Transactions on Information Forensics and Security, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.