Recognition: unknown
ClawBench: Can AI Agents Complete Everyday Online Tasks?
Pith reviewed 2026-05-10 17:29 UTC · model grok-4.3
The pith
AI agents complete only a small portion of everyday online tasks on live websites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
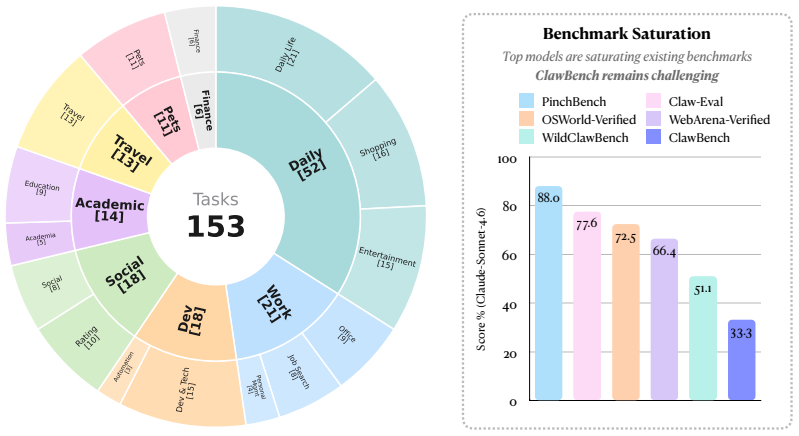
ClawBench consists of 153 tasks spanning 15 categories on 144 live platforms that require agents to obtain information from documents, execute multi-step workflows, and perform write-heavy form filling on production websites. The framework employs a lightweight interception layer that captures and blocks only the final submission request, allowing safe testing without real-world effects. Evaluations across seven frontier models reveal that both proprietary and open-source systems finish only a small fraction of the tasks, with Claude Sonnet 4.6 reaching 33.3 percent success.
What carries the argument
ClawBench, the evaluation framework that runs agents directly on live production websites while using an interception layer to prevent actual submissions and thereby maintain safety.
If this is right
- Current frontier models lack the capabilities needed to automate most routine online tasks reliably.
- Benchmarks must shift from static sandboxes to production environments to capture real dynamic challenges.
- Agents require stronger skills in document information use, long-horizon planning, and accurate form completion.
- Progress measured by ClawBench would directly advance agents toward functioning as general-purpose assistants.
- Both proprietary and open-source models exhibit similar limitations on these practical web workflows.
Where Pith is reading between the lines
- Better results on ClawBench would likely translate to agents handling more personal administrative work without human oversight.
- The benchmark could be extended to include tasks with financial or legal consequences to test higher-stakes reliability.
- Training focused on live-site navigation and error recovery might close the gap shown in the current evaluations.
Load-bearing premise
The 153 tasks are representative of everyday online activities and the interception layer preserves full task complexity without introducing evaluation artifacts.
What would settle it
A new model that completes more than 50 percent of the same 153 tasks under the identical live-site and interception conditions would indicate the reported performance ceiling no longer holds.
Figures





read the original abstract
AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper introduces ClawBench, a benchmark of 153 everyday online tasks spanning 144 live platforms in 15 categories. Unlike prior benchmarks using static pages, it runs on production websites with a lightweight interception layer to safely block final submissions. Evaluations of seven frontier models reveal low completion rates, with Claude Sonnet 4.6 achieving only 33.3%, suggesting significant limitations in current AI agents for real-world web tasks.
Significance. Should the evaluation methodology prove robust, ClawBench offers a valuable, realistic testbed for AI agent capabilities in practical scenarios such as purchases, bookings, and job applications. The focus on dynamic live platforms and demanding write-heavy operations (e.g., detailed form filling and document-based information extraction) provides a stronger signal than sandbox-based evaluations. The reported results establish a clear baseline for measuring progress toward reliable general-purpose agents.
major comments (1)
- [§3 (Benchmark Design)] §3 (Benchmark Design): The description of the interception layer asserts that it 'preserves the full complexity, dynamic nature, and challenges of real-world web interaction' by blocking only the final submission. However, the manuscript does not include any validation such as ablation studies comparing performance with and without the layer, analysis of altered page states or feedback loops, or human performance baselines on the same tasks. This is a load-bearing assumption for the central claim that the low success rates (e.g., 33.3% for Claude Sonnet 4.6) reflect inherent model limitations rather than artifacts from the evaluation setup.
minor comments (2)
- [Abstract] Abstract: It would improve clarity to report success rates for all evaluated models rather than highlighting only the best one (Claude Sonnet 4.6 at 33.3%).
- [Experiments] Experiments section: Details on the number of trials per task, variance in results, or statistical tests for the performance differences are not mentioned, which would help assess the reliability of the findings.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our ClawBench benchmark paper. We are grateful for the positive remarks on its significance and the call for robust evaluation methodology. Below, we provide a point-by-point response to the major comment.
read point-by-point responses
-
Referee: [§3 (Benchmark Design)] §3 (Benchmark Design): The description of the interception layer asserts that it 'preserves the full complexity, dynamic nature, and challenges of real-world web interaction' by blocking only the final submission. However, the manuscript does not include any validation such as ablation studies comparing performance with and without the layer, analysis of altered page states or feedback loops, or human performance baselines on the same tasks. This is a load-bearing assumption for the central claim that the low success rates (e.g., 33.3% for Claude Sonnet 4.6) reflect inherent model limitations rather than artifacts from the evaluation setup.
Authors: We agree that empirical validation of the interception layer's neutrality would strengthen our claims. The layer is implemented as a minimal proxy that only prevents the final submission HTTP request from reaching the server, without modifying any preceding network responses, DOM elements, or JavaScript behavior. All agent actions, including navigation, clicking, typing, and reading page content, occur exactly as they would in an unmediated session. To address this, we have revised Section 3 to include a more precise specification of the interception logic, including the criteria used to identify the 'final submission' request. We have also added a limitations paragraph noting the absence of ablations and human baselines, and we will prioritize collecting human performance data on a subset of tasks for a follow-up study. This revision clarifies the methodology and acknowledges the assumption's importance. revision: yes
Circularity Check
Pure empirical benchmark paper with no derivations or self-referential reductions.
full rationale
ClawBench is an evaluation framework that defines 153 tasks on live platforms and reports direct success rates for 7 models (e.g., Claude Sonnet 4.6 at 33.3%). The manuscript contains no equations, fitted parameters, predictions derived from prior inputs, or mathematical derivations. The central claims are empirical measurements on the introduced benchmark; the interception layer is presented as a design choice that preserves complexity, not as a result derived from or reducing to the reported percentages. No self-citation chains, ansatzes, or renamings of known results appear in the load-bearing steps. The paper is self-contained as a benchmark introduction and evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The selected 153 tasks represent typical everyday online activities across 15 categories.
- domain assumption Intercepting only the final submission request preserves evaluation validity while ensuring safety.
Forward citations
Cited by 7 Pith papers
-
WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
A new native-runtime benchmark reveals that current frontier AI agents succeed on at most 62 percent of realistic long-horizon CLI tasks.
-
LITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
LITMUS is the first benchmark using semantic-physical dual verification and OS state rollback to measure behavioral jailbreaks in LLM agents, revealing that even strong models execute 40%+ of high-risk operations and ...
-
Can a Single Message Paralyze the AI Infrastructure? The Rise of AbO-DDoS Attacks through Targeted Mobius Injection
Mobius Injection exploits semantic closure in LLM agents to enable single-message AbO-DDoS attacks achieving up to 51x call amplification and 229x latency inflation.
-
AcademiClaw: When Students Set Challenges for AI Agents
AcademiClaw is a new benchmark of 80 student-sourced academic tasks where the best frontier AI agents achieve only a 55% pass rate.
-
Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
Continued pre-training with balanced long-document VQA data extends a 7B LVLM to 128K context, improving long-document VQA by 7.1% and generalizing to 512K without further training.
-
NeuroClaw Technical Report
NeuroClaw introduces a three-tier multi-agent framework and NeuroBench benchmark that improve executability and reproducibility scores for neuroimaging tasks when used with multimodal LLMs.
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
Introducing computer use
Anthropic. Introducing computer use. https://www.anthropic.com/news/ 3-5-models-and-computer-use, 2025a. Accessed: 2026-03-20. Anthropic. Claude haiku 4.5. https://www.anthropic.com/news/claude-haiku-4-5 , 2025b. Anthropic. Claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6 ,
2026
- [2]
-
[3]
arXiv preprint arXiv:2504.11543 , year =
Divyansh Garg, Shaun VanWeelden, Diego Caples, Andis Draguns, Nikil Ravi, Pranav Putta, Naman Garg, Tomas Abraham, Michael Lara, Federico Lopez, et al. Real: Bench- marking autonomous agents on deterministic simulations of real websites.arXiv preprint arXiv:2504.11543,
-
[4]
arXiv:2307.12856. Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InAnnual Meeting of the Association for Computational Linguistics (ACL),
-
[5]
Zefang Liu and Yinzhu Quan. Econwebarena: Benchmarking autonomous agents on economic tasks in realistic web environments.arXiv preprint arXiv:2506.08136,
work page internal anchor Pith review arXiv
-
[6]
arXiv:2112.09332. OpenAI. Introducing operator.https://openai.com/index/introducing-operator/,
work page internal anchor Pith review arXiv
-
[7]
arXiv preprint arXiv:2406.12373 , year=
11 Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. Webcanvas: Benchmarking web agents in online environments.arXiv preprint arXiv:2406.12373,
-
[8]
Kimi K2.5: Visual Agentic Intelligence
Accessed: 2026-03-20. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
arXiv:2508.20453 [cs.CL] https://arxiv.org/abs/ 2508.20453
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, et al. Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers.arXiv preprint arXiv:2508.20453,
-
[10]
Accessed: 2026-03-20
Peking University & University of Hong Kong. Accessed: 2026-03-20. Ori Yoran, Samuel Joseph Amouyal, Chaitanya Malaviya, Ben Bogin, Ofir Press, and Jonathan Berant. Assistantbench: Can web agents solve realistic and time-consuming tasks? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 8938–8968,
2026
-
[11]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review arXiv
-
[12]
arXiv:2401.01614. Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR),
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.