Recognition: 1 theorem link
AcademiClaw: When Students Set Challenges for AI Agents
Pith reviewed 2026-05-08 19:17 UTC · model grok-4.3
The pith
AcademiClaw benchmark shows frontier AI models complete only 55% of real student academic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
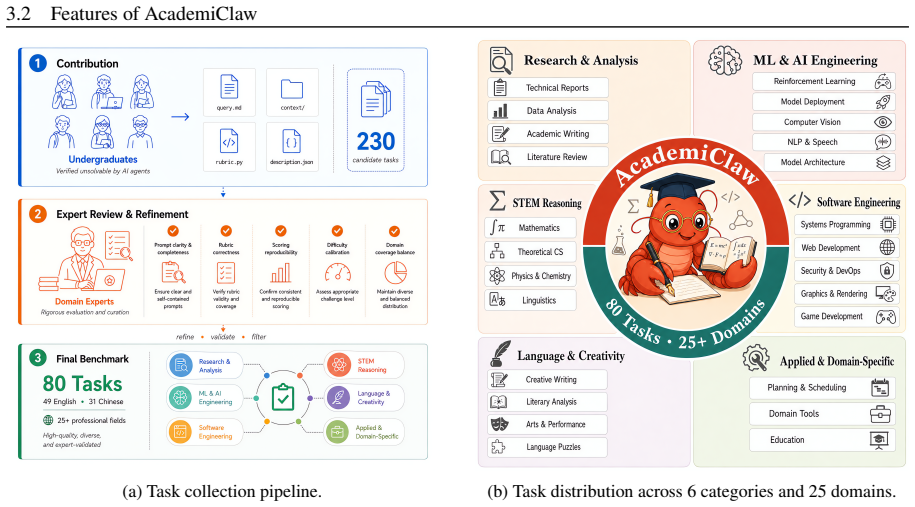
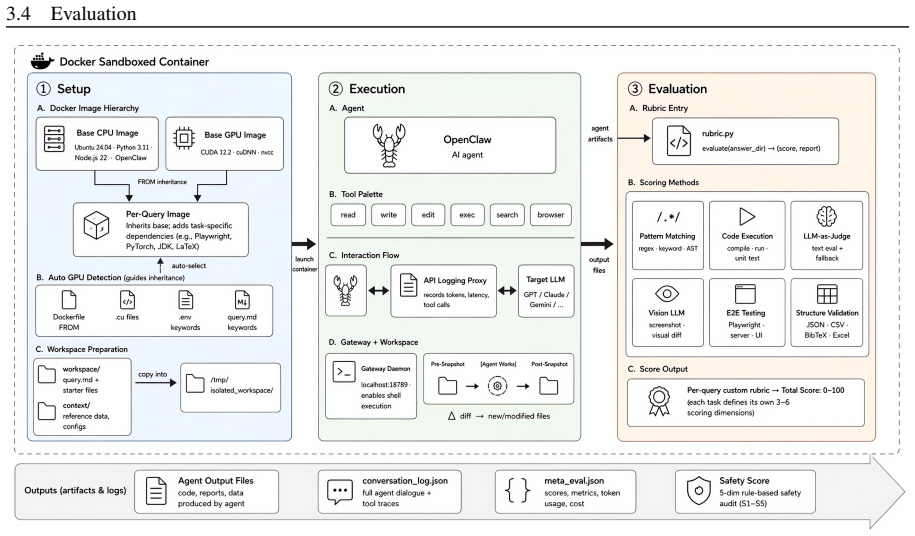
AcademiClaw is a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows such as homework, research projects, competitions, and personal projects. The tasks were curated from 230 student-submitted candidates through rigorous expert review and span 25+ professional domains, with 16 requiring CUDA GPU execution. Each task runs in an isolated Docker sandbox and receives scores from multi-dimensional rubrics that combine six complementary techniques, supplemented by an independent five-category safety audit. Experiments on six frontier models show that even the best model achieves only a 55% pass rate, with further analysis showing
What carries the argument
The AcademiClaw benchmark, which executes tasks in isolated Docker sandboxes and scores completion using multi-dimensional rubrics that combine six techniques together with separate safety audits.
Load-bearing premise
The 80 curated tasks, chosen from student submissions by expert review, accurately represent the academic challenges that capable AI agents should be expected to solve.
What would settle it
Re-testing the same six models on a new independent collection of 80 similar academic tasks and obtaining pass rates above 70% would indicate the original results do not reflect a general limitation.
Figures



read the original abstract
Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AcademiClaw, a bilingual benchmark of 80 complex, long-horizon academic tasks sourced from university students' real workflows (homework, research, competitions) that they found current AI agents unable to solve. Tasks were curated from 230 candidates via expert review, span 25+ domains (including olympiad math, RL, and full-stack debugging with 16 requiring CUDA), run in isolated Docker sandboxes, and scored via multi-dimensional rubrics using six techniques plus a safety audit. Experiments on six frontier models report a maximum 55% pass rate, with further breakdowns of domain-specific boundaries, model behavioral differences, and token consumption vs. quality disconnect.
Significance. If the tasks prove representative and the rubrics reliable, AcademiClaw would offer a useful diagnostic resource for identifying limits in current agents on realistic academic workloads, complementing existing assistant-level benchmarks. The explicit open-sourcing of data and code strengthens reproducibility and community utility.
major comments (3)
- [Abstract] Abstract: The central claim that the 55% pass rate reveals capability boundaries is undermined by the task sourcing criterion ('sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively'). This upstream filter from student-reported failures makes the low ceiling confirmatory of the selection process rather than an independent measure of academic-level limits.
- [Benchmark construction] Task curation process (described in abstract and benchmark construction): No details are provided on the expert review protocol for reducing 230 candidates to 80, inter-rater agreement for inclusion/exclusion decisions, or handling of potential biases in the final distribution across the 25+ domains. These omissions are load-bearing because they directly affect whether the reported domain-specific analyses and overall 55% rate can be interpreted as general rather than artifactual.
- [Evaluation methodology] Evaluation and scoring section: The multi-dimensional rubrics (six complementary techniques) and five-category safety audit lack reported inter-rater reliability statistics, application consistency checks, or statistical validation of scoring. This weakens the evidential basis for both the aggregate pass rate and the claims of sharp capability boundaries and behavioral divergences.
minor comments (2)
- [Introduction] The abstract and introduction could more explicitly distinguish the benchmark's goals from prior OpenClaw assistant-level evaluations to clarify its incremental contribution.
- [Results] Figure and table captions would benefit from additional detail on how pass rates and domain breakdowns were computed to aid reader interpretation without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which has identified key areas where additional transparency will strengthen the manuscript. We address each major comment below and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] The central claim that the 55% pass rate reveals capability boundaries is undermined by the task sourcing criterion ('sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively'). This upstream filter from student-reported failures makes the low ceiling confirmatory of the selection process rather than an independent measure of academic-level limits.
Authors: We appreciate this observation and agree that the abstract should more precisely characterize the benchmark's scope. The sourcing criterion was chosen deliberately to surface long-horizon academic tasks that students themselves identified as difficult for current agents, thereby creating a diagnostic tool focused on capability boundaries rather than a statistically representative sample of all academic work. The reported 55% ceiling, together with the domain-specific and behavioral analyses, is intended to illuminate where agents fail on realistic workloads. We will revise the abstract to clarify that AcademiClaw is a curated collection of challenging tasks rather than a broad survey, and we will add a sentence distinguishing its purpose from general academic benchmarks. revision: yes
-
Referee: [Benchmark construction] Task curation process (described in abstract and benchmark construction): No details are provided on the expert review protocol for reducing 230 candidates to 80, inter-rater agreement for inclusion/exclusion decisions, or handling of potential biases in the final distribution across the 25+ domains. These omissions are load-bearing because they directly affect whether the reported domain-specific analyses and overall 55% rate can be interpreted as general rather than artifactual.
Authors: We agree that greater detail on the curation protocol is necessary. The reduction from 230 to 80 tasks was performed by a panel of domain-expert reviewers who applied explicit criteria for academic complexity, human solvability, sandbox compatibility, and domain diversity. We will expand the benchmark construction section with a full description of the review workflow, the inclusion/exclusion criteria, and the steps taken to mitigate domain imbalance. While formal inter-rater agreement statistics were not computed, we will document the consensus procedure used by the review team. revision: yes
-
Referee: [Evaluation methodology] Evaluation and scoring section: The multi-dimensional rubrics (six complementary techniques) and five-category safety audit lack reported inter-rater reliability statistics, application consistency checks, or statistical validation of scoring. This weakens the evidential basis for both the aggregate pass rate and the claims of sharp capability boundaries and behavioral divergences.
Authors: The rubrics were applied by the core author team with internal cross-validation on a subset of tasks to promote consistency. We acknowledge that explicit inter-rater reliability metrics and formal statistical validation were not reported. In the revised manuscript we will add a dedicated subsection describing the scoring protocol, the combination of the six techniques, the safety audit procedure, and any consistency checks that were performed. We will also discuss the limitations of the current validation approach. revision: partial
Circularity Check
No significant circularity in this empirical benchmark paper
full rationale
The paper is a purely empirical benchmark description with no derivations, equations, fitted parameters, or theoretical predictions. Tasks are curated from student submissions and evaluated directly via model runs and rubric scoring; the 55% pass rate is a straightforward measurement on the fixed set rather than a quantity derived from or equivalent to the selection process by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support any central claim, and the work remains self-contained against external benchmarks without reducing its results to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Student-submitted tasks represent genuine academic challenges that capable AI agents should be able to solve.
Reference graph
Works this paper leans on
-
[1]
Anthropic . 2025. Claude code. https://claude.com/product/claude-code. Anthropic's agentic coding tool
2025
-
[2]
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M a dry. 2024. MLE -bench: Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095
work page Pith review arXiv 2024
-
[3]
arXiv preprint arXiv:2502.08235 , year =
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Panda, Joseph E. Gonzalez, Ion Stoica, et al. 2025. The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks. arXiv preprint arXiv:2502.08235
-
[4]
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. 2023. C-Eval : A multi-level multi-discipline Chinese evaluation suite for foundation models. In Advances in Neural Information Processing Systems 36
2023
-
[5]
InternLM Team . 2026. WildClawBench : An in-the-wild benchmark for AI agents. https://internlm.github.io/WildClawBench/. 60 adversarially difficult OpenClaw tasks
2026
-
[6]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. https://openreview.net/forum?id=VTF8yNQM66 SWE -bench: Can language models resolve real-world GitHub issues? In The Twelfth International Conference on Learning Representations
2024
-
[7]
Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina Williams. 2021. Dynabench: Rethinking benchmarking in NLP . In Proceedings of...
2021
-
[8]
Kilo AI . 2026. PinchBench : Benchmarking system for evaluating LLM models as OpenClaw agents. https://pinchbench.com. 23 real-world OpenClaw agent tasks
2026
-
[9]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tiber Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench : Evaluating LLMs as agents. In The Twelfth International Conference on Lear...
2024
-
[10]
Xiang Long, Li Du, Yilong Xu, Fangcheng Liu, Haoqing Wang, Ning Ding, Ziheng Li, Jianyuan Guo, and Yehui Tang. 2026. LiveClawBench : Benchmarking LLM agents on complex, real-world assistant tasks. arXiv preprint arXiv:2604.13072
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. GAIA : A benchmark for general AI assistants. arXiv preprint arXiv:2311.12983
work page internal anchor Pith review arXiv 2023
- [12]
-
[13]
OpenAI . 2025. Introducing Codex . https://openai.com/index/introducing-codex/. OpenAI's agentic coding tool
2025
-
[14]
OpenClaw Community . 2026. OpenClaw . https://github.com/openclaw/openclaw. Open-source AI agent framework
2026
-
[15]
Long Phan, Alice Gatti, Ziwen Han, Nathaniel Li, Josephina Hu, Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, et al. 2025. Humanity's last exam. arXiv preprint arXiv:2501.14249
work page internal anchor Pith review arXiv 2025
-
[16]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. 2024. Identifying the risks of LM agents with an LM -emulated sandbox. In The Twelfth International Conference on Learning Representations
2024
-
[17]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems 36
2023
- [18]
-
[19]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shi, Zhaoyang Lu, et al. 2024. OSWorld : Benchmarking multimodal agents for open-ended tasks in real computer environments. In Advances in Neural Information Processing Systems
2024
-
[20]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. 2024. TheAgentCompany : Benchmarking LLM agents on consequential real world tasks...
work page internal anchor Pith review arXiv 2024
-
[21]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. -bench: A benchmark for tool-agent-user interaction in real-world domains. arXiv preprint arXiv:2406.12045
work page internal anchor Pith review arXiv 2024
-
[22]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct : Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations
2023
-
[23]
Bowen Ye, Rang Li, Qibin Yang, Zhihui Xie, Yuanxin Liu, Linli Yao, Hanglong Lyu, and Lei Li. 2026. Claw-Eval : Toward trustworthy evaluation of autonomous agents. arXiv preprint arXiv:2604.06132
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. 2024. R-Judge : Benchmarking safety risk awareness for LLM agents. In Findings of the Association for Computational Linguistics: EMNLP 2024
2024
-
[25]
Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, Songcheng Cai, Xiaochen Wang, Huaisong Zhang, Xian Wu, Yi Lu, Minyi Lei, Kai Zou, Huifeng Yin, Ping Nie, Liang Chen, Dongfu Jiang, Wenhu Chen, and Kelsey R. Allen. 2026. ClawBench : Can AI agents complete everyday online tasks? arXiv preprint arXiv:2604.08523
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM -as-a-judge with MT -bench and Chatbot Arena . In Advances in Neural Information Processing Systems 36 (NeurIPS 2023) Datasets and Benchmarks Track
2023
-
[27]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2023. WebArena : A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854
work page Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.