Recognition: unknown
PRAGMA: Revolut Foundation Model
Pith reviewed 2026-05-10 17:30 UTC · model grok-4.3
The pith
PRAGMA pre-trains transformers on raw banking event sequences to create general-purpose embeddings for financial tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRAGMA pre-trains a Transformer-based architecture with masked modelling on a large-scale, heterogeneous banking event corpus using a self-supervised objective tailored to the discrete, variable-length nature of financial records. The resulting model supports a wide range of downstream tasks such as credit scoring, fraud detection, and lifetime value prediction: strong performance can be achieved by training a simple linear model on top of the extracted embeddings and can be further improved with lightweight fine-tuning. Through extensive evaluation on downstream tasks, we demonstrate that PRAGMA achieves superior performance across multiple domains directly from raw event sequences, as a a
What carries the argument
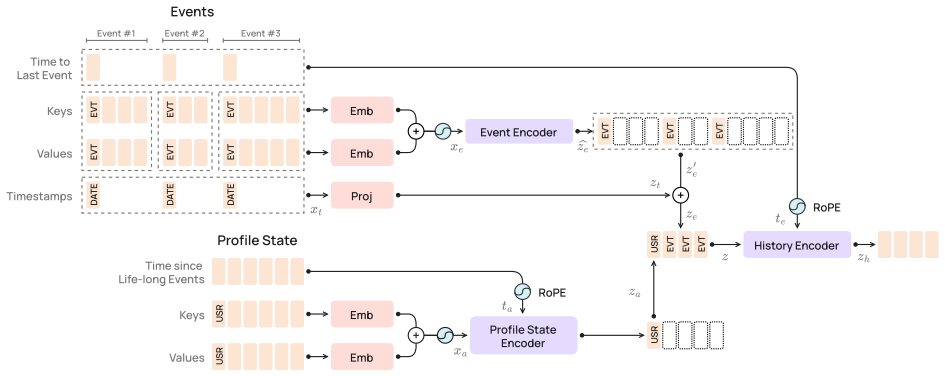
The PRAGMA Transformer architecture pre-trained with a tailored masked modeling objective on heterogeneous banking event sequences to produce transferable embeddings.
Load-bearing premise
The self-supervised masked modeling objective on a heterogeneous banking event corpus captures rich, transferable economic signals sufficient to outperform prior approaches on downstream tasks without domain-specific features or extensive engineering.
What would settle it
Head-to-head comparison on credit scoring where a linear head on PRAGMA embeddings underperforms a strong baseline that uses hand-engineered domain features would falsify the claim of superiority from raw sequences alone.
Figures




read the original abstract
Modern financial systems generate vast quantities of transactional and event-level data that encode rich economic signals. This paper presents PRAGMA, a family of foundation models for multi-source banking event sequences. Our approach pre-trains a Transformer-based architecture with masked modelling on a large-scale, heterogeneous banking event corpus using a self-supervised objective tailored to the discrete, variable-length nature of financial records. The resulting model supports a wide range of downstream tasks such as credit scoring, fraud detection, and lifetime value prediction: strong performance can be achieved by training a simple linear model on top of the extracted embeddings and can be further improved with lightweight fine-tuning. Through extensive evaluation on downstream tasks, we demonstrate that PRAGMA achieves superior performance across multiple domains directly from raw event sequences, providing a general-purpose representation layer for financial applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PRAGMA, a family of Transformer-based foundation models pre-trained via masked modeling on large-scale heterogeneous banking event sequences. It claims that embeddings from this self-supervised pre-training enable strong performance on downstream financial tasks (credit scoring, fraud detection, lifetime value prediction) via simple linear probing or lightweight fine-tuning, outperforming prior approaches directly from raw event sequences without domain-specific features.
Significance. If the empirical results hold, the work would provide a general-purpose representation layer for financial event data, potentially reducing reliance on hand-crafted features across banking applications. This aligns with foundation-model trends in other domains and could be impactful for financial ML if the gains are robust and reproducible.
major comments (2)
- [Abstract] Abstract: the claim of 'superior performance across multiple domains' is asserted without any metrics, baselines, dataset sizes, evaluation protocols, or statistical significance tests. This prevents verification of whether the data support the central claim of outperformance from raw sequences.
- [Abstract] The self-supervised masked modeling objective is described as 'tailored to the discrete, variable-length nature of financial records,' but no equations, loss formulation, or masking strategy details are supplied in the available text to show how this tailoring avoids trivial solutions or data leakage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying that the full paper contains the supporting details while agreeing to strengthen the abstract where appropriate for better verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'superior performance across multiple domains' is asserted without any metrics, baselines, dataset sizes, evaluation protocols, or statistical significance tests. This prevents verification of whether the data support the central claim of outperformance from raw sequences.
Authors: We agree that the abstract's high-level claim would benefit from more context. The full manuscript provides these details in Sections 4 and 5, with tables reporting specific metrics (AUC, F1, RMSE), baselines (XGBoost on handcrafted features, LSTM/Transformer variants), dataset sizes (millions of sequences across multiple sources), evaluation protocols (temporal splits, multiple downstream tasks), and significance testing. We will revise the abstract to incorporate key quantitative results and a brief mention of the evaluation setup. revision: yes
-
Referee: [Abstract] The self-supervised masked modeling objective is described as 'tailored to the discrete, variable-length nature of financial records,' but no equations, loss formulation, or masking strategy details are supplied in the available text to show how this tailoring avoids trivial solutions or data leakage.
Authors: The abstract summarizes at a high level due to length constraints. The full manuscript details the objective in Section 3, including the cross-entropy loss over masked tokens, a 15% random masking strategy applied to entire events and attributes while preserving temporal order (to avoid leakage), and variable-length handling via special delimiter and padding tokens. This prevents trivial solutions such as position-based prediction. We will add a short clarifying phrase to the abstract and ensure the introduction expands on the tailoring. revision: partial
Circularity Check
No significant circularity
full rationale
The paper presents a standard self-supervised masked modeling pre-training pipeline for a Transformer on heterogeneous banking event sequences, followed by linear probing or lightweight fine-tuning for downstream tasks. No equations, derivations, or load-bearing steps are described that reduce claimed performance to fitted parameters by construction, self-referential definitions, or self-citation chains. The approach is internally consistent with established sequence foundation model practices and relies on empirical evaluation rather than any tautological reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BEiT: BERT Pre-Training of Image Transformers
17 Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: BERT pre-training of image transformers.arXiv preprint arXiv:2106.08254,
work page internal anchor Pith review arXiv
-
[2]
DT Braithwaite, Misael Cavalcanti, R Austin McEver, Hiroto Udagawa, Daniel Silva, Rohan Ramanath, Felipe Mene- ses, Arissa Yoshida, Evan Wingert, Matheus Ramos, et al. Your spending needs attention: Modeling financial habits with transformers.arXiv preprint arXiv:2507.23267,
-
[3]
NV-Retriever: Improving text embedding models with effective hard-negative mining
Gabriel de Souza P. Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge. Nv- retriever: Improving text embedding models with effective hard-negative mining.arXiv preprint arXiv:2407.15831,
-
[4]
NV-Retriever: Improving text embedding models with effective hard-negative mining
doi: 10.48550/arXiv.2407.15831. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized llms.Advances in Neural Information Processing Systems,
-
[5]
Transactiongpt.arXiv preprint arXiv:2511.08939,
Yingtong Dou, Zhimeng Jiang, Tianyi Zhang, Mingzhi Hu, Zhichao Xu, Shubham Jain, Uday Singh Saini, Xiran Fan, Jiarui Sun, Menghai Pan, et al. Transactiongpt.arXiv preprint arXiv:2511.08939,
-
[6]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. TabPFN-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667,
-
[8]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678,
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678,
-
[10]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Scaling recommender transformers to one billion parameters.arXiv preprint arXiv:2507.15994,
Kirill Khrylchenko, Artem Matveev, Sergei Makeev, and Vladimir Baikalov. Scaling recommender transformers to one billion parameters.arXiv preprint arXiv:2507.15994,
-
[13]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982,
work page internal anchor Pith review arXiv
-
[14]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
19 Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C Bayan Bruss, and Tom Goldstein. SAINT: Improved neural networks for tabular data via row attention and contrastive pre-training.arXiv preprint arXiv:2106.01342,
-
[16]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Ghaffari, Binyam Gebre, Abra- ham Ittycheriah, and Gideon Mann. BloombergGPT: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review arXiv
-
[17]
TransAct V2: Lifelong user action sequence modeling on Pinterest recommendation
Xue Xia, Saurabh Vishwas Joshi, Kousik Rajesh, Kangnan Li, Yangyi Lu, Nikil Pancha, Dhruvil Deven Badani, Jiajing Xu, and Pong Eksombatchai. TransAct V2: Lifelong user action sequence modeling on Pinterest recommendation. arXiv preprint arXiv:2506.02267,
-
[18]
Yi Yang, Mark Christopher Siy Uy, and Allen Huang. FinBERT: A pretrained language model for financial commu- nications.arXiv preprint arXiv:2006.08097,
-
[19]
20 Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, Yinghai Lu, and Yu Shi. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.