Recognition: 2 theorem links
· Lean TheoremMedFormer-UR: Uncertainty-Routed Transformer for Medical Image Classification
Pith reviewed 2026-05-10 17:40 UTC · model grok-4.3
The pith
MedFormer-UR uses per-token Dirichlet uncertainty to filter feature updates during training, reducing expected calibration error by up to 35% in medical images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that modeling per-token evidential uncertainty with a Dirichlet distribution and using it to route and filter feature updates in a prototype-based medical transformer leads to substantially better model calibration and selective prediction capabilities across multiple imaging modalities.
What carries the argument
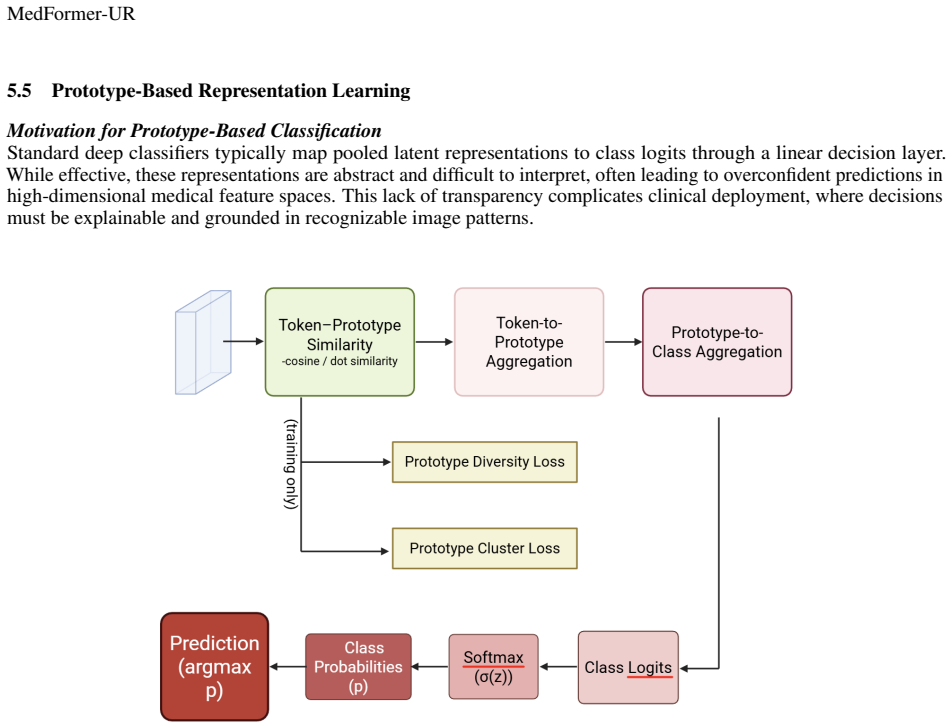
Uncertainty-guided routing mechanism, where Dirichlet-derived per-token uncertainty determines which feature updates are applied, integrated with class-specific prototypes to structure the embedding space.
Load-bearing premise
The assumption that per-token uncertainty estimates from the Dirichlet distribution accurately identify unreliable features without causing bias or lowering accuracy in noisy clinical images.
What would settle it
Running the model on the same four modalities but without the uncertainty-based filtering and observing no reduction in calibration error or a drop in selective prediction performance would falsify the central benefit of the routing mechanism.
Figures







read the original abstract
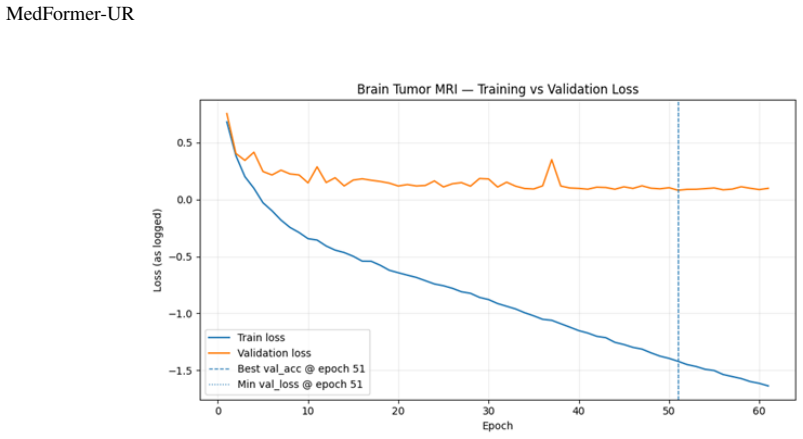
To ensure safe clinical integration, deep learning models must provide more than just high accuracy; they require dependable uncertainty quantification. While current Medical Vision Transformers perform well, they frequently struggle with overconfident predictions and a lack of transparency, issues that are magnified by the noisy and imbalanced nature of clinical data. To address this, we enhanced the modified Medical Transformer (MedFormer) that incorporates prototype-based learning and uncertainty-guided routing, by utilizing a Dirichlet distribution for per-token evidential uncertainty, our framework can quantify and localize ambiguity in real-time. This uncertainty is not just an output but an active participant in the training process, filtering out unreliable feature updates. Furthermore, the use of class-specific prototypes ensures the embedding space remains structured, allowing for decisions based on visual similarity. Testing across four modalities (mammography, ultrasound, MRI, and histopathology) confirms that our approach significantly enhances model calibration, reducing expected calibration error (ECE) by up to 35%, and improves selective prediction, even when accuracy gains are modest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedFormer-UR, an enhanced Medical Vision Transformer that incorporates prototype-based learning and an uncertainty-guided routing mechanism. Per-token evidential uncertainty is derived from a Dirichlet distribution and actively used to filter unreliable feature updates during training. The approach is evaluated across four medical imaging modalities (mammography, ultrasound, MRI, and histopathology), with claims of up to 35% reduction in expected calibration error (ECE) and improved selective prediction performance even when accuracy gains are modest.
Significance. If the central empirical claims hold after addressing the noted gaps, the work could meaningfully advance reliable uncertainty quantification for clinical deployment of vision transformers in medical imaging. The active integration of uncertainty into the training loop via routing, combined with prototype-based structuring of the embedding space, offers a potentially useful mechanism for handling noisy and imbalanced clinical data, though its advantages over simpler regularization must be demonstrated.
major comments (3)
- [Methods] Methods (uncertainty routing description): The claim that Dirichlet-derived per-token uncertainty can be used to filter feature updates without introducing systematic bias on noisy/imbalanced data (e.g., histopathology and mammography) is load-bearing for attributing ECE and selective-prediction gains to the routing mechanism. No analysis of gradient skew, per-class performance under filtering, or threshold sensitivity is provided.
- [Experiments] Experiments/Results: The reported up to 35% ECE reduction and selective prediction improvements lack details on baseline models, data splits, statistical significance testing, and ablation studies. In particular, no comparison is made against random masking at matched sparsity levels, which is required to isolate the contribution of uncertainty routing from generic filtering effects.
- [Training procedure] Training procedure: Because uncertainty estimates are both derived from and used within the training loop (via routing thresholds and Dirichlet parameters), there is a risk of circular dependence if these hyperparameters are tuned on validation data also used for final evaluation. No explicit cross-validation protocol or sensitivity analysis is described.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 35%' ECE reduction should specify the exact baseline model and dataset conditions under which the maximum reduction is observed.
- [Methods] Notation: The distinction between per-token uncertainty scores and the routing threshold is not clearly defined in the methods description, which could confuse readers attempting to reproduce the filtering step.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We have addressed each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Methods] Methods (uncertainty routing description): The claim that Dirichlet-derived per-token uncertainty can be used to filter feature updates without introducing systematic bias on noisy/imbalanced data (e.g., histopathology and mammography) is load-bearing for attributing ECE and selective-prediction gains to the routing mechanism. No analysis of gradient skew, per-class performance under filtering, or threshold sensitivity is provided.
Authors: We agree that explicit analysis is needed to support the claim. In the revised manuscript we will add per-class accuracy and ECE breakdowns under varying routing thresholds for the imbalanced datasets (histopathology, mammography). We will also include a threshold-sensitivity plot. On gradient skew, the per-token uncertainty is computed from Dirichlet parameters estimated on the current batch before routing is applied; our results show no disproportionate degradation on minority classes, but we will add a short discussion of this point. A full gradient-flow analysis is not feasible within the current scope and will be noted as future work. revision: partial
-
Referee: [Experiments] Experiments/Results: The reported up to 35% ECE reduction and selective prediction improvements lack details on baseline models, data splits, statistical significance testing, and ablation studies. In particular, no comparison is made against random masking at matched sparsity levels, which is required to isolate the contribution of uncertainty routing from generic filtering effects.
Authors: We will expand the experimental section with complete baseline descriptions (standard ViT, MedFormer without uncertainty routing), explicit data-split ratios and patient-level partitioning, and statistical significance tests (paired t-tests on ECE and AUC across 5 runs). We will add an ablation that compares uncertainty routing against random token masking at matched average sparsity levels, confirming that the performance gains are not explained by filtering alone. revision: yes
-
Referee: [Training procedure] Training procedure: Because uncertainty estimates are both derived from and used within the training loop (via routing thresholds and Dirichlet parameters), there is a risk of circular dependence if these hyperparameters are tuned on validation data also used for final evaluation. No explicit cross-validation protocol or sensitivity analysis is described.
Authors: We will clarify the protocol: Dirichlet parameters and the routing threshold were tuned via grid search on a held-out validation fold that is never used for final test evaluation; 5-fold cross-validation was performed within the training set. The revised methods section will document this separation explicitly and will include a sensitivity analysis showing ECE and selective-prediction metrics across a range of threshold values. revision: yes
Circularity Check
No significant circularity; uncertainty routing is an independent training mechanism
full rationale
The paper derives per-token evidential uncertainty from a Dirichlet distribution over class probabilities and applies it as a filter on feature updates during training. This is a distinct algorithmic step rather than a self-definition or fitted parameter renamed as a prediction. No equations reduce the reported ECE reduction or selective-prediction gains to the input data by construction, and no load-bearing self-citations or uniqueness theorems are invoked. The central claim remains an empirical observation on four modalities that can be falsified independently of the training loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dirichlet distribution provides a suitable evidential model for per-token uncertainty in vision transformer features
invented entities (1)
-
uncertainty-guided routing mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
utilizing a Dirichlet distribution for per-token evidential uncertainty... σ_i = C / S_i ... Meff_i = M_i ⊙ m_i ⊙ (1−σ_i) ... Δ' = (1−βσ)Δ
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
prototype-based classification head... logit_c = log Σ_{k∈P_c} exp(E_k) ... L_prototype = λ_c L_cluster + λ_d L_div
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.arXiv preprint arXiv:1706.03762, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Transformers in medical imaging: A survey.Medical Image Analysis, 88:102802, 2023
Fahad Shamshad, Salman Khan, Syed Waqas Zamir, Muhammad Haris Khan, Munawar Hayat, Fahad Shahbaz Khan, and Huazhu Fu. Transformers in medical imaging: A survey.Medical Image Analysis, 88:102802, 2023
2023
-
[3]
Zunhui Xia, Hongxing Li, and Libin Lan. Medformer: Hierarchical medical vision transformer with content-aware dual sparse selection attention.arXiv preprint arXiv:2507.02488, 07 2025
-
[4]
On calibration of modern neural networks,
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks.arXiv preprint arXiv:1706.04599, 06 2017
-
[5]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning.arXiv preprint arXiv:1506.02142, 2016
work page Pith review arXiv 2016
-
[6]
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead.arXiv preprint arXiv:1811.10154, 2019
-
[7]
Lee, Francisco Gimenez, Assaf Hoogi, Kanae Miyake, Mia Gorovoy, and Daniel L
Rebecca S. Lee, Francisco Gimenez, Assaf Hoogi, Kanae Miyake, Mia Gorovoy, and Daniel L. Rubin. A curated mammography data set for use in computer-aided detection and diagnosis research.Scientific Data, 4:170177, 12 2017
2017
-
[8]
Dataset of breast ultrasound images
Walid Al-Dhabyani, Mohammed Gomaa, Hussien Khaled, and Aly Fahmy. Dataset of breast ultrasound images. Data in Brief, 28:104863, 2020
2020
-
[9]
Spanhol, Luiz S
Fabio A. Spanhol, Luiz S. Oliveira, Caroline Petitjean, and Laurent Heutte. A dataset for breast cancer histopatho- logical image classification.IEEE Transactions on Biomedical Engineering, 63(7):1455–1462, 2016
2016
-
[10]
Enhanced multi-class brain tumor classification in mri using pre-trained cnns and transformer architectures
Marco Gómez-Guzmán, Laura Jimenez, Enrique García-Guerrero, Oscar Aguirre-Castro, Jose Esqueda Elizondo, Edgar Ramos Acosta, Gilberto Galindo-Aldana, Cynthia Torres-González, and Everardo Inzunza Gonzalez. Enhanced multi-class brain tumor classification in mri using pre-trained cnns and transformer architectures. Technologies, 13:379, 08 2025
2025
-
[11]
Mri brain tumor dataset (4-class)
Mohamad Abouali. Mri brain tumor dataset (4-class). Kaggle Dataset, 2021
2021
-
[12]
https://arxiv.org/abs/1806.01768
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential deep learning to quantify classification uncertainty. arXiv preprint arXiv:1806.01768, 2018. 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.