Recognition: 2 theorem links
· Lean TheoremLitmus (Re)Agent: A Benchmark and Agentic System for Predictive Evaluation of Multilingual Models
Pith reviewed 2026-05-10 17:41 UTC · model grok-4.3
The pith
Litmus (Re)Agent predicts missing multilingual model results by decomposing queries into hypotheses and aggregating evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Litmus (Re)Agent achieves the best overall performance across six systems on the 1,500-question benchmark, with the largest gains in transfer-heavy scenarios where direct evidence is weak or absent, by decomposing queries into hypotheses, retrieving evidence from the literature, and synthesising predictions through feature-aware aggregation.
What carries the argument
Litmus (Re)Agent, a DAG-orchestrated agentic system that decomposes queries into hypotheses, retrieves evidence, and synthesises predictions through feature-aware aggregation.
If this is right
- Agentic decomposition and evidence aggregation improve accuracy most when direct results are missing.
- The separated-evidence benchmark provides a repeatable testbed for other predictive systems.
- Such methods can guide which language-task pairs to evaluate next by ranking likely performance.
- Structured reasoning over literature reduces reliance on exhaustive new testing.
Where Pith is reading between the lines
- The same query-decomposition pattern could apply to other sparse-evaluation domains such as low-resource language tasks.
- If the approach scales, it might lower the cost of deciding which models to deploy in new languages.
- Extending the benchmark to real, noisy published papers would test whether the controlled scenarios generalise.
Load-bearing premise
The controlled benchmark of 1,500 questions and five evidence scenarios sufficiently represents real-world incomplete literature evidence for multilingual model evaluation.
What would settle it
A test in which Litmus (Re)Agent is run on a larger collection of actual published papers with held-out results and fails to outperform simple baselines on prediction accuracy.
Figures











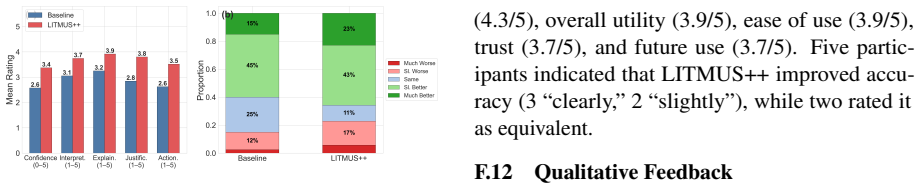











read the original abstract
We study predictive multilingual evaluation: estimating how well a model will perform on a task in a target language when direct benchmark results are missing. This problem is common in multilingual deployment, where evaluation coverage is sparse and published evidence is uneven across languages, tasks, and model families. We introduce a controlled benchmark of 1,500 questions spanning six tasks and five evidence scenarios. The benchmark separates accessible evidence from ground truth, enabling evaluation of systems that must infer missing results from incomplete literature evidence. We also present Litmus (Re)Agent, a DAG-orchestrated agentic system that decomposes queries into hypotheses, retrieves evidence, and synthesises predictions through feature-aware aggregation. Across six systems, Litmus (Re)Agent achieves the best overall performance, with the largest gains in transfer-heavy scenarios where direct evidence is weak or absent. These results show that structured agentic reasoning is a promising approach to multilingual performance estimation under incomplete evidence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a controlled benchmark of 1,500 questions spanning six tasks and five evidence scenarios designed to evaluate systems for predicting multilingual model performance when direct results are missing from the literature. It presents Litmus (Re)Agent, a DAG-orchestrated agentic system that decomposes queries into hypotheses, retrieves evidence, and synthesizes predictions through feature-aware aggregation. The central claim is that this system achieves the best overall performance across six compared systems, with the largest gains in transfer-heavy scenarios where direct evidence is weak or absent.
Significance. If the performance claims hold under rigorous verification, the work would be significant for multilingual NLP by addressing the practical problem of sparse evaluation coverage. The benchmark's explicit separation of accessible evidence from ground truth is a methodological strength that enables systematic, reproducible testing of predictive approaches. The agentic DAG design offers a structured alternative to simpler baselines for handling incomplete information, with potential implications for model selection in low-resource languages. Credit is due for the controlled benchmark construction that facilitates clear evaluation of evidence-based inference.
major comments (2)
- [Abstract] Abstract: The claim that Litmus (Re)Agent achieves the best overall performance with largest gains in transfer-heavy scenarios provides no details on the six systems used as baselines, the exact metrics, statistical tests, error bars, or aggregation methods across scenarios and tasks. These omissions are load-bearing for the central empirical result and prevent verification of the headline finding.
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The five controlled evidence scenarios rely on artificial missingness that cleanly separates accessible evidence from ground truth, but the manuscript does not report external validation against real published multilingual literature containing contradictions, omissions, and reporting artifacts. This assumption is central to interpreting the agent's largest gains in transfer-heavy cases as generalizable rather than an artifact of the benchmark's clean design.
minor comments (1)
- [Benchmark section] The paper would benefit from an early summary table listing the six tasks, languages, and question counts to improve accessibility of the benchmark scope.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's potential significance. We respond point-by-point to the major comments below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Litmus (Re)Agent achieves the best overall performance with largest gains in transfer-heavy scenarios provides no details on the six systems used as baselines, the exact metrics, statistical tests, error bars, or aggregation methods across scenarios and tasks. These omissions are load-bearing for the central empirical result and prevent verification of the headline finding.
Authors: We agree that the abstract would benefit from additional details to support the headline claim. The full paper provides these in the experimental sections (Sections 4 and 5), including descriptions of the six baseline systems, the exact metrics, statistical tests, error bars, and aggregation methods. In the revision, we will update the abstract to concisely reference the evaluation setup and direct readers to the detailed results in the main text. This will improve verifiability. revision: yes
-
Referee: [§3 (Benchmark Construction)] §3 (Benchmark Construction): The five controlled evidence scenarios rely on artificial missingness that cleanly separates accessible evidence from ground truth, but the manuscript does not report external validation against real published multilingual literature containing contradictions, omissions, and reporting artifacts. This assumption is central to interpreting the agent's largest gains in transfer-heavy cases as generalizable rather than an artifact of the benchmark's clean design.
Authors: The use of controlled artificial missingness is a deliberate methodological choice to ensure a clean separation between evidence and ground truth, allowing for reproducible and systematic evaluation of predictive systems across scenarios. This design avoids the confounding effects present in real literature. We recognize the value of external validation and will add a discussion in the limitations section addressing the differences between the controlled benchmark and real-world published data, including potential artifacts and suggestions for future validation studies on actual literature. revision: partial
Circularity Check
No circularity: benchmark construction and agent evaluation remain independent.
full rationale
The paper introduces a controlled benchmark that explicitly separates accessible evidence from held-out ground truth across 1,500 questions and five scenarios, then evaluates the Litmus (Re)Agent (plus baselines) on predictive accuracy against that ground truth. No equations, parameter fits, or self-citations appear in the provided text that would reduce the performance claims to the benchmark inputs by construction. The central result is an empirical comparison on a deliberately held-out test set, which does not collapse into self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
controlled benchmark of 1,500 questions spanning six tasks and five evidence scenarios... DAG-orchestrated agentic system that decomposes queries into hypotheses, retrieves evidence, and synthesises predictions through feature-aware aggregation
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
enhanced code execution with linguistic feature libraries... lang2vec and the URIEL typological database... regression models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
uttler, Mike Lewis, Wen-tau Yih, Tim Rockt
Magentic-one: A generalist multi-agent sys- tem for solving complex tasks.arXiv preprint arXiv:2410.04468. Junjie Hu, Sebastian Ruder, Aditya Siddhant, Graham Neubig, Orhan Firat, and Melvin Johnson. 2020. Xtreme: A massively multilingual multi-task bench- mark for evaluating cross-lingual generalisation. In International conference on machine learning, p...
-
[2]
Choosing transfer languages for cross-lingual learning. InProceedings of the 57th Annual Meet- ing of the Association for Computational Linguistics, pages 3125–3135. Patrick Littell, David R Mortensen, Ke Lin, Katherine Kairis, Carlisle Turner, and Lori Levin. 2017. Uriel and lang2vec: Representing languages as typological, geographical, and phylogenetic ...
-
[3]
No Language Left Behind: Scaling Human-Centered Machine Translation
Don’t give me the details, just the summary! topic-aware convolutional neural networks for ex- treme summarization. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 1797–1807. Cuong Nguyen, Tal Hassner, Matthias Seeger, and Cedric Archambeau. 2020. Leep: A new measure to evaluate transferability of learned re...
work page internal anchor Pith review arXiv 2018
-
[4]
Judgebench: A benchmark for evaluating llm- based judges. https://openreview.net/forum? id=G0dksFayVq. Alexander Tsvetkov and Alon Kipnis. 2024. Informa- tion parity: Measuring and predicting the multilin- gual capabilities of language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 7971–7989. Shunyu Yao, Jeffrey Zha...
-
[5]
**Task + Model + Language**: Questions about specific model performance on specific language
-
[6]
**Task + Language**: Questions about how different models perform on a specific language
-
[7]
**Task + Model**: Questions about how a specific model performs across languages
-
[8]
**Model + Language**: Questions about model performance on language (task implied)
-
[9]
**Task only**: Questions about overall task performance across languages/models ### Question Templates (adapt and vary phrasing):
-
[10]
*What is the performance of {{model}} on {{task}} for {{language}}?*
-
[11]
*How does {{model}} perform on {{task}} in {{language}}?*
-
[12]
*Compare {{model1}} and {{model2}} performance for {{language}} on {{task}}.*
-
[13]
*Which model performs best for {{task}} in {{language}}?*
-
[14]
*What are the {{task}} results for {{model}} across all languages?*
-
[15]
*How does {{language}} performance vary across models for {{task}}?*
-
[16]
*What languages show the best performance for {{task}}?*
-
[17]
*Which models have been evaluated for {{task}} in {{language}}?*
-
[18]
*What is the cross-lingual performance of {{model}} on {{task}}?*
-
[19]
*How do low-resource languages perform on {{task}}?* ### Rules
-
[20]
Generate questions only for natural languages
**Only use languages and models from the provided mapping** - do not invent new ones. Generate questions only for natural languages. For tasks like code generation, programming languages might be present as well. DO NOT generate questions for programming languages
-
[21]
Use the exact task name provided
-
[22]
If multiple models/languages appear in a question, list them alphabetically, comma-separated (no spaces)
-
[23]
If task, model, or language is not present in a question, set it as`""`in the output
-
[24]
Questions must be clear, end with`?`, and avoid hallucinations
-
[25]
Generate diverse questions; avoid repetitive phrasing
-
[26]
Focus on realistic evaluation scenarios where GT data would be available. ### Output Format Return **only JSON** in this structure: class QuestionsGenerated(BaseModel): class Question(BaseModel): complete_question: str task: str models: str languages: str questions: list[Question] Generate {num_questions} diverse questions covering different question type...
-
[27]
4: Good justification; minor gaps (e.g., limited uncertainty discussion)
Predictive plausibility: 5: Clear assumptions; modeling choices justified; uncertainty quantified; sanity checks present. 4: Good justification; minor gaps (e.g., limited uncertainty discussion). 3: Some plausible ideas but notable missing justifications or contradictory reasoning. 2: Weak or ad-hoc predictive reasoning; unexplained leaps. 1: Implausible ...
-
[28]
4: Strong feature list with reasonable justifications; some missing depth
Feature selection: 5: Expert-level: linguistically justified features, selection method described, interaction effects explored. 4: Strong feature list with reasonable justifications; some missing depth. 3: Useful features but shallow rationale; key multilingual features missing. 2: Generic or ill-suited features; little reasoning. 1: No coherent feature ...
-
[29]
4: Mostly coherent; minor organizational or phrasing issues
Coherence: 5: Logical flow; claims follow from premises; clear definitions; few language errors. 4: Mostly coherent; minor organizational or phrasing issues. 3: Fragmented arguments or occasional contradictions; several clarity issues. 2: Disorganized, hard to follow, or contradictory statements. 1: Incoherent, contradictory, or unintelligible
-
[30]
metrics": [ {
Citation emphasis: 5: Key claims tied to relevant citations; literature justifies design choices. 4: Many claims cited, but a few unsupported assertions remain. 3: Some grounding, but important claims lack citations. 2: Sparse citation support; many claims unsupported. 1: Virtually no citation grounding; unusual claims without references. Output format (s...
-
[31]
DETERMINE is_answer_present: - Set to true ONLY if agent's report contains a relevant, clear answer - Set to false if no answer found or report is unclear/irrelevant
-
[32]
61.25%"): extract number -> 61.25 * If value is decimal 0-1 (e.g.,
FOR PREDICTIVE QUERIES: - Extract ALL performance metrics mentioned (e.g., accuracy, pass@1, BLEU, ROUGE, F1) - For EACH metric found, create an object with: * metric_name: exact name of the metric (string) * value: original value AS STATED in the report (string) * value_in_100_range: numeric value scaled to 0-100 range (float) - Scaling rules for value_i...
-
[33]
FOR QNA QUERIES: - Extract CONCISE answer value(s) from agent's report: * For model questions: extract model name ONLY (e.g., "GPT-4") * For language questions: extract language name(s) ONLY * For numeric questions: extract number(s) ONLY - NEVER include full sentences or explanations
-
[34]
is_answer_present
BOTH PREDICTIVE AND QNA: - If the question can be answered BOTH ways (metrics AND concise answer): * Provide BOTH predicted_metrics_and_values_for_predictive AND answer_text_for_qna OUTPUT FORMAT (strict JSON, no markdown): For PREDICTIVE: { "is_answer_present": true, "predicted_metrics_and_values_for_predictive": [ {"metric_name": "pass@1", "value": "61....
-
[35]
TASK-QUERY ALIGNMENT: Does the code address the user's research question?
-
[36]
ALGORITHMS & MODELS: Identify all algorithms; assess appropriateness and correctness
-
[37]
FEATURES & VARIABLES: List features; assess engineering sophistication and validity
-
[38]
METHODOLOGY: Identify approach; assess statistical rigor and evaluation strategy
-
[39]
CODE QUALITY: Assess organization, error handling, and best practices
-
[40]
RESEARCH APPROPRIATENESS: Is the methodology scientifically sound?
-
[41]
algorithms_used
SOPHISTICATION: Rate as Basic, Intermediate, or Advanced. Output JSON: { "algorithms_used": ["..."], "algorithm_appropriateness": "appropriate|questionable|inappropriate", "features_used": ["..."], "feature_engineering_level": "none|basic|moderate|advanced", "methodology_type": "regression|classification|...", "methodology_rigor": "high|moderate|low", "co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.