Recognition: 2 theorem links
· Lean TheoremSkill-Conditioned Visual Geolocation for Vision-Language Models
Pith reviewed 2026-05-14 21:58 UTC · model grok-4.3
The pith
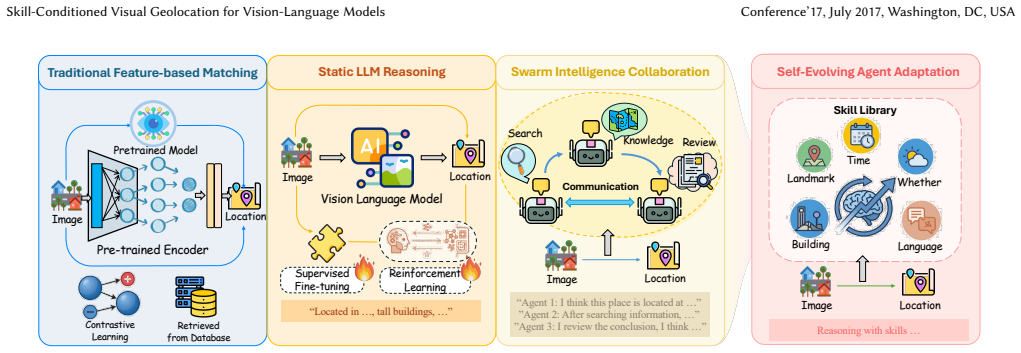
GeoSkill equips vision-language models with an evolving Skill-Graph that improves image geolocation accuracy and reasoning faithfulness without any parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GeoSkill maintains a Skill-Graph of atomic natural-language skills that conditions direct reasoning by the inference model; an Autonomous Evolution loop then runs a larger model on web-scale image-coordinate pairs, verifies the resulting trajectories, and uses both successes and failures to synthesize additional skills or prune geographic biases, expanding the graph and correcting errors without any parameter updates.
What carries the argument
The evolving Skill-Graph, a dynamic collection of atomic natural-language skills that guides and is refined by reasoning trajectories.
If this is right
- Geolocation accuracy rises on the GeoRC benchmark while reasoning faithfulness improves.
- Performance generalizes better across diverse external datasets than prior implicit-memory approaches.
- Novel, verifiable skills emerge automatically from analysis of successful and failed trajectories.
- Geographic biases are corrected through iterative pruning without retraining the underlying model.
- The system supports continuous self-evolution through repeated rollout-and-refine cycles.
Where Pith is reading between the lines
- The same rollout-verification loop could be applied to other structured reasoning domains such as medical diagnosis or legal analysis.
- If verification quality scales with model size, larger models could bootstrap progressively richer skill graphs for smaller inference models.
- Interpretability of VLM outputs increases because every reasoning step is explicitly tied to a named skill from the graph.
- Long-term maintenance of the graph could become a lightweight data-curation task rather than a full retraining process.
Load-bearing premise
Rollouts generated by a larger model on web-sourced image-coordinate pairs can be verified reliably enough to synthesize new skills and prune biases without introducing fresh hallucinations.
What would settle it
Running the evolved Skill-Graph on a held-out collection of images with known ground-truth coordinates and finding no gain in accuracy or an increase in erroneous reasoning steps compared with the initial graph would falsify the central claim.
Figures



read the original abstract
Vision-language models (VLMs) have shown a promising ability in image geolocation, but they still lack structured geographic reasoning and the capacity for autonomous self-evolution. Existing methods predominantly rely on implicit parametric memory, which often exploits outdated knowledge and generates hallucinated reasoning. Furthermore, current inference is a "one-off" process, lacking the feedback loops necessary for self-evolution based on reasoning outcomes. To address these issues, we propose GeoSkill, a training-free framework based on an evolving Skill-Graph. We first initialize the graph by refining human expert trajectories into atomic, natural-language skills. For execution, GeoSkill employs an inference model to perform direct reasoning guided by the current Skill-Graph. For continuous growth, an Autonomous Evolution mechanism leverages a larger model to conduct multiple reasoning rollouts on image-coordinate pairs sourced from web-scale data and verified real-world reasoning. By analyzing both successful and failed trajectories from these rollouts, the mechanism iteratively synthesizes and prunes skills, effectively expanding the Skill-Graph and correcting geographic biases without any parameter updates. Experiments demonstrate that GeoSkill achieves promising performance in both geolocation accuracy and reasoning faithfulness on GeoRC, while maintaining superior generalization across diverse external datasets. Furthermore, our autonomous evolution fosters the emergence of novel, verifiable skills, significantly enhancing the system's cognition of real-world geographic knowledge beyond isolated case studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoSkill, a training-free framework for vision-language models in visual geolocation. It initializes a Skill-Graph from refined human expert trajectories, guides inference with the current graph, and uses an Autonomous Evolution mechanism in which a larger model performs multiple reasoning rollouts on web-sourced image-coordinate pairs. Successful and failed trajectories are analyzed to iteratively synthesize new skills and prune biases, expanding the graph without parameter updates. The authors claim that this yields promising geolocation accuracy and reasoning faithfulness on the GeoRC benchmark, superior generalization on external datasets, and the emergence of novel verifiable skills.
Significance. If the autonomous evolution mechanism can be shown to produce skills that are independently verifiable and that genuinely correct geographic biases rather than reinforcing internal model patterns, the work would provide a concrete demonstration of training-free self-improvement for VLMs on tasks that require structured external knowledge. The Skill-Graph approach offers a potential alternative to purely parametric memory and could generalize to other reasoning domains.
major comments (3)
- [Autonomous Evolution mechanism] Autonomous Evolution mechanism (as described in the abstract and method): verification of rollouts is performed solely by a larger model on web-sourced image-coordinate pairs with no independent ground-truth oracle, external map cross-validation, or human-verified subset specified. This is load-bearing for the central claims of 'verifiable skills' and 'correcting geographic biases,' because shared hallucination patterns between the inference and evolution models could produce circular reinforcement rather than genuine correction.
- [Experiments and results] Experiments and results (abstract and evaluation sections): the manuscript asserts 'promising performance in both geolocation accuracy and reasoning faithfulness on GeoRC' and 'superior generalization across diverse external datasets,' yet the provided description contains no quantitative metrics, ablation tables, error breakdowns, or baseline comparisons. Without these, the empirical support for the headline claims cannot be assessed.
- [Skill-Graph initialization and evolution] Skill-Graph initialization and evolution (method section): the process of distilling expert trajectories into atomic skills and then synthesizing/pruning via rollouts lacks any description of conflict resolution, redundancy detection, or consistency checks within the graph. This omission directly affects the reliability of the guided inference step that the framework relies upon.
minor comments (2)
- [Abstract] The abstract introduces the GeoRC benchmark and external datasets without a citation or brief description of their construction and size.
- [Method] Notation for the Skill-Graph (nodes, edges, skill representation) is used throughout but never given a formal definition or pseudocode, making it difficult to reproduce the initialization and update rules.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of clarity, empirical rigor, and methodological transparency that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Autonomous Evolution mechanism] Autonomous Evolution mechanism (as described in the abstract and method): verification of rollouts is performed solely by a larger model on web-sourced image-coordinate pairs with no independent ground-truth oracle, external map cross-validation, or human-verified subset specified. This is load-bearing for the central claims of 'verifiable skills' and 'correcting geographic biases,' because shared hallucination patterns between the inference and evolution models could produce circular reinforcement rather than genuine correction.
Authors: We appreciate this observation on the verification process. The current description relies on the larger model for rollout analysis of web-sourced pairs, described as 'verified real-world reasoning.' We acknowledge the potential for circular reinforcement if hallucination patterns are shared. In the revised manuscript we will add a dedicated subsection on verification, including a human-verified subset of 200 rollouts (with reported agreement statistics) and explicit prompting instructions that require the larger model to reference external geographic facts where possible. This will be presented as a partial revision to strengthen the verifiability claims. revision: partial
-
Referee: [Experiments and results] Experiments and results (abstract and evaluation sections): the manuscript asserts 'promising performance in both geolocation accuracy and reasoning faithfulness on GeoRC' and 'superior generalization across diverse external datasets,' yet the provided description contains no quantitative metrics, ablation tables, error breakdowns, or baseline comparisons. Without these, the empirical support for the headline claims cannot be assessed.
Authors: We agree that the current manuscript text lacks the specific quantitative results, tables, and comparisons needed to fully support the claims. The revised version will expand the evaluation section with concrete accuracy numbers on GeoRC, baseline comparisons, ablation studies isolating the Skill-Graph and evolution components, error breakdowns by geographic region, and generalization results on the external datasets. Corresponding tables and figures will be added. revision: yes
-
Referee: [Skill-Graph initialization and evolution] Skill-Graph initialization and evolution (method section): the process of distilling expert trajectories into atomic skills and then synthesizing/pruning via rollouts lacks any description of conflict resolution, redundancy detection, or consistency checks within the graph. This omission directly affects the reliability of the guided inference step that the framework relies upon.
Authors: Thank you for pointing out this gap in the method description. We will revise the Skill-Graph section to explicitly describe: (1) conflict resolution via confidence-weighted voting from successful rollouts, (2) redundancy detection using embedding similarity thresholds with a merge policy, and (3) consistency checks performed by re-evaluating a held-out expert trajectory set after each evolution cycle. These additions will clarify how the graph remains reliable for inference. revision: yes
Circularity Check
Autonomous evolution's skill synthesis reduces to larger-model self-verification of its own rollouts on web pairs, with no independent oracle.
specific steps
-
self definitional
[Abstract (Autonomous Evolution mechanism)]
"an Autonomous Evolution mechanism leverages a larger model to conduct multiple reasoning rollouts on image-coordinate pairs sourced from web-scale data and verified real-world reasoning. By analyzing both successful and failed trajectories from these rollouts, the mechanism iteratively synthesizes and prunes skills, effectively expanding the Skill-Graph and correcting geographic biases without any parameter updates."
The phrase 'verified real-world reasoning' is supplied by the larger model itself judging its own rollouts; therefore the success/failure classification that drives skill synthesis is defined in terms of the model's internal outputs rather than an independent external criterion, making the emergence of 'novel, verifiable skills' equivalent to re-labeling the model's existing behavior.
full rationale
The paper's central claim of autonomous growth and emergence of novel verifiable skills rests on the evolution mechanism. The description states that a larger model performs rollouts on web-sourced image-coordinate pairs and then analyzes successful/failed trajectories to synthesize and prune skills in the Skill-Graph. Because verification of 'real-world reasoning' is performed internally by the same class of VLM (the larger model), the success labels, bias corrections, and new skills are generated from the model's own outputs rather than from external ground truth, cross-validation, or human-verified subsets. This makes the reported generalization gains and skill emergence dependent on the internal consistency of the model's judgments, satisfying the self-definitional pattern.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs rely on implicit parametric memory that produces outdated knowledge and hallucinations
- domain assumption Image-coordinate pairs from web-scale data can serve as reliable ground truth for verifying reasoning trajectories
invented entities (2)
-
Skill-Graph
no independent evidence
-
Autonomous Evolution mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Autonomous Evolution mechanism leverages a larger model to conduct multiple reasoning rollouts on image-coordinate pairs... iteratively synthesizes and prunes skills
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Skill-Graph... atomic skills... Jcost not referenced
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gabriele Berton, Carlo Masone, and Barbara Caputo. 2022. Rethinking visual geo- localization for large-scale applications. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4878–4888
work page 2022
-
[2]
Gabriele Berton, Carlo Masone, Valerio Paolicelli, and Barbara Caputo. 2021. Viewpoint invariant dense matching for visual geolocalization. InProceedings of the IEEE/CVF International Conference on Computer Vision. 12169–12178
work page 2021
-
[3]
Ron Campos, Ashmal Vayani, Parth Parag Kulkarni, Rohit Gupta, Aritra Dutta, and Mubarak Shah. 2025. Gaea: A geolocation aware conversational model.arXiv e-prints(2025), arXiv–2503
work page 2025
- [4]
-
[5]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Lukas Haas, Michal Skreta, Silas Alberti, and Chelsea Finn. 2024. Pigeon: Predict- ing image geolocations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12893–12902
work page 2024
-
[8]
Xiao Han, Chen Zhu, Hengshu Zhu, and Xiangyu Zhao. 2025. Swarm intelligence in geo-localization: A multi-agent large vision-language model collaborative framework. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 814–825
work page 2025
- [9]
-
[10]
Furong Jia, Ling Dai, Wenjin Deng, Fan Zhang, Chen Hu, Daxin Jiang, and Yu Liu
- [11]
- [12]
- [13]
- [14]
- [15]
- [16]
- [17]
-
[18]
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, et al. 2025. Large language model agent: A survey on methodology, applications and challenges.arXiv preprint arXiv:2503.21460(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Eric Muller-Budack, Kader Pustu-Iren, and Ralph Ewerth. 2018. Geolocation estimation of photos using a hierarchical model and scene classification. In Proceedings of the European conference on computer vision (ECCV). 563–579
work page 2018
-
[20]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
work page 2022
-
[21]
Shraman Pramanick, Ewa M Nowara, Joshua Gleason, Carlos D Castillo, and Rama Chellappa. 2022. Where in the world is this image? transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision. Springer, 196–215
work page 2022
- [22]
-
[23]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
work page 2023
-
[24]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs.CL] https://arxiv.org/abs/ 1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
2009.The probabilistic relevance frame- work: BM25 and beyond
Stephen Robertson and Hugo Zaragoza. 2009.The probabilistic relevance frame- work: BM25 and beyond. Vol. 4. Now Publishers Inc
work page 2009
-
[26]
Paul Hongsuck Seo, Tobias Weyand, Jack Sim, and Bohyung Han. 2018. Cplanet: Enhancing image geolocalization by combinatorial partitioning of maps. InPro- ceedings of the European Conference on Computer Vision (ECCV). 536–551
work page 2018
- [27]
-
[28]
Mohit Talreja, Joshua Diao, Jim Thannikary James, Radu Casapu, Tejas Santanam, Ethan Mendes, Alan Ritter, Wei Xu, and James Hays. 2026. GeoRC: A Benchmark for Geolocation Reasoning Chains.arXiv preprint arXiv:2601.21278(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. 2023. Geoclip: Clip-inspired alignment between locations and images for effective worldwide geo-localization.Advances in Neural Information Processing Systems36 (2023), 8690–8701
work page 2023
-
[31]
Nam Vo, Nathan Jacobs, and James Hays. 2017. Revisiting im2gps in the deep learning era. InProceedings of the IEEE international conference on computer vision. 2621–2630
work page 2017
-
[32]
Chun Wang, Xiaojun Ye, Xiaoran Pan, Zihao Pan, Haofan Wang, and Yiren Song
- [33]
-
[34]
Yikun Wang, Zuyan Liu, Ziyi Wang, Han Hu, Pengfei Liu, and Yongming Rao
-
[35]
arXiv preprint arXiv:2511.15705(2025)
GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization. arXiv preprint arXiv:2511.15705(2025)
-
[36]
Zhangyu Wang, Jielu Zhang, Zhongliang Zhou, Qian Cao, Nemin Wu, Zeping Liu, Lan Mu, Yang Song, Yiqun Xie, Ni Lao, et al. 2025. LocDiffusion: Identifying locations on Earth by diffusing in the Hilbert space. (2025)
work page 2025
-
[37]
Tobias Weyand, Ilya Kostrikov, and James Philbin. 2016. Planet-photo geolocation with convolutional neural networks. InEuropean conference on computer vision. Springer, 37–55
work page 2016
-
[38]
Daniel Wilson, Xiaohan Zhang, Waqas Sultani, and Safwan Wshah. 2024. Image and object geo-localization.International Journal of Computer Vision132, 4 (2024), 1350–1392
work page 2024
-
[39]
Renjun Xu and Yang Yan. 2026. Agent skills for large language models: Architec- ture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Shixiong Xu, Chenghao Zhang, Lubin Fan, Gaofeng Meng, Shiming Xiang, and Jieping Ye. 2024. Addressclip: Empowering vision-language models for city-wide image address localization. InEuropean Conference on Computer Vision. Springer, 76–92
work page 2024
- [41]
-
[42]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. 2025. Group sequence policy optimization.arXiv preprint arXiv:2507.18071(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Xin Zheng, Jialong Han, and Aixin Sun. 2018. A survey of location prediction on twitter.IEEE Transactions on Knowledge and Data Engineering30, 9 (2018), 1652–1671
work page 2018
-
[47]
Fan Zhou, Xiuxiu Qi, Kunpeng Zhang, Goce Trajcevski, and Ting Zhong. 2022. Metageo: a general framework for social user geolocation identification with few-shot learning.IEEE Transactions on Neural Networks and Learning Systems 34, 11 (2022), 8950–8964. Conference’17, July 2017, Washington, DC, USA Chengjie Yang, Yutian Jiang, and Chenyu Wu
work page 2022
-
[48]
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2023. Minigpt-4: Enhancing vision-language understanding with advanced large lan- guage models.arXiv preprint arXiv:2304.10592(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.