Recognition: unknown
Plasticity-Enhanced Multi-Agent Mixture of Experts for Dynamic Objective Adaptation in UAVs-Assisted Emergency Communication Networks
Pith reviewed 2026-05-10 16:50 UTC · model grok-4.3
The pith
A phase controller with mixture-of-experts actors restores plasticity in multi-agent UAV policies for adapting to abrupt changes in emergency networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
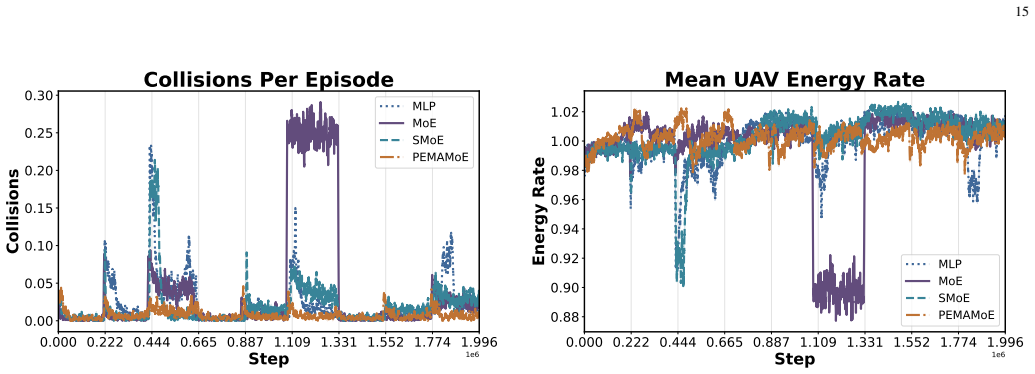
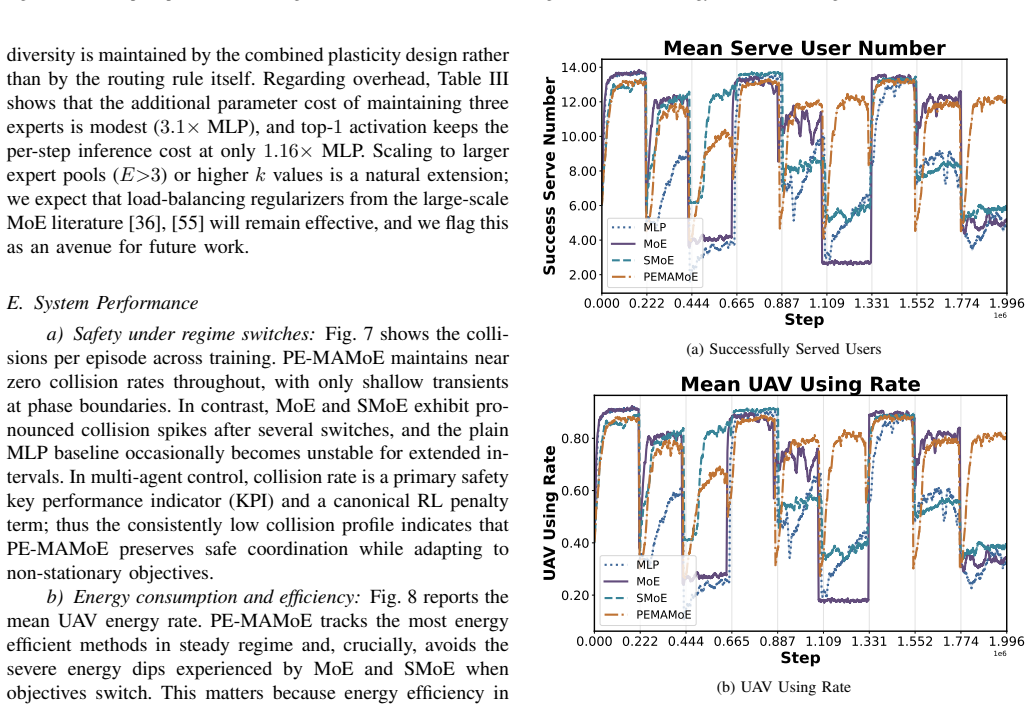
PE-MAMoE equips UAV agents with sparsely gated mixture of experts actors whose router selects one specialist per step. The non-parametric Phase Controller injects brief expert-only stochastic perturbations after phase switches, resets the action log-standard-deviation, anneals entropy and learning rate, and schedules router temperature to re-plasticize the policy without destabilizing safe behaviors. A derived dynamic regret bound shows tracking error scales with environment variation and cumulative noise energy. Simulations confirm 26.3% improvement in normalized interquartile mean return, 12.8% increase in served-user capacity, and approximately 75% reduction in collisions, with diagnostic
What carries the argument
The non-parametric Phase Controller that detects phase switches and applies targeted perturbations along with hyperparameter annealing to maintain policy plasticity in the multi-agent mixture of experts setup.
If this is right
- The dynamic regret bound indicates that tracking error grows proportionally with the degree of environment variation and the total noise energy introduced.
- Diagnostics show persistently higher expert feature rank and recovery from dormant neurons specifically at regime switches.
- Normalized interquartile mean return improves by 26.3% compared to the strongest baseline.
- Served user capacity rises by 12.8% while collisions drop by roughly 75% in the evaluated simulator.
Where Pith is reading between the lines
- Applying the phase controller concept to single-agent RL or other domains with abrupt changes could similarly combat plasticity loss.
- Testing the method in real-world UAV deployments or with imperfect phase detection would reveal practical robustness.
- If phase switches are not clearly identifiable, an alternative continuous adaptation mechanism might be needed to maintain the benefits.
Load-bearing premise
The non-stationary environment provides detectable phase switches that let the Phase Controller time its interventions to restore plasticity without causing unsafe actions.
What would settle it
If the performance advantages and plasticity recovery metrics vanish when the simulator is modified to lack clear phase switches or when the Phase Controller is disabled, the central claim would be falsified.
Figures






read the original abstract
Unmanned aerial vehicles serving as aerial base stations can rapidly restore connectivity after disasters, yet abrupt changes in user mobility and traffic demands shift the quality of service trade-offs and induce strong non-stationarity. Deep reinforcement learning policies suffer from plasticity loss under such shifts, as representation collapse and neuron dormancy impair adaptation. We propose plasticity enhanced multi-agent mixture of experts (PE-MAMoE), a centralized training with decentralized execution framework built on multi-agent proximal policy optimization. PE-MAMoE equips each UAV with a sparsely gated mixture of experts actor whose router selects a single specialist per step. A non-parametric Phase Controller injects brief, expert-only stochastic perturbations after phase switches, resets the action log-standard-deviation, anneals entropy and learning rate, and schedules the router temperature, all to re-plasticize the policy without destabilizing safe behaviors. We derive a dynamic regret bound showing the tracking error scales with both environment variation and cumulative noise energy. In a phase-driven simulator with mobile users and 3GPP-style channels, PE-MAMoE improves normalized interquartile mean return by 26.3\% over the best baseline, increases served-user capacity by 12.8\%, and reduces collisions by approximately 75\%. Diagnostics confirm persistently higher expert feature rank and periodic dormant-neuron recovery at regime switches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes plasticity-enhanced multi-agent mixture of experts (PE-MAMoE), a CTDE framework based on multi-agent PPO in which each UAV agent uses a sparsely gated MoE actor. A non-parametric Phase Controller detects phase switches in a non-stationary environment (mobile users, 3GPP channels) and responds by injecting expert-only perturbations, resetting action log-std, annealing entropy/LR, and scheduling router temperature to counteract plasticity loss. A dynamic regret bound is derived that scales tracking error with environment variation and cumulative noise energy. In a phase-driven simulator the method reports 26.3% higher normalized interquartile mean return, 12.8% higher served-user capacity, and ~75% fewer collisions than the best baseline, together with diagnostics of higher expert feature rank and periodic neuron recovery.
Significance. If the central claims hold, the work offers a concrete mechanism for restoring plasticity in multi-agent RL under abrupt regime shifts, which is relevant to UAV-assisted emergency networks. The combination of a derived dynamic regret bound, explicit handling of representation collapse via targeted perturbations, and quantitative diagnostics on expert utilization is a positive contribution. The empirical margins are substantial, but their dependence on oracle phase information limits immediate generalizability.
major comments (3)
- [Abstract] Abstract: the dynamic regret bound is asserted to scale with environment variation and cumulative noise energy, yet the abstract supplies neither the derivation nor the explicit assumptions on how the variation term is bounded. Without these it is impossible to verify whether the bound is independent of the listed free parameters (router temperature schedule, entropy and learning-rate annealing rates) or whether it implicitly incorporates the Phase Controller's schedule.
- [Abstract] Abstract, Phase Controller description: all reported gains (26.3% NIMR, 12.8% capacity, ~75% collision reduction) and the plasticity-recovery diagnostics are obtained in a simulator whose phases are explicitly scheduled and therefore known to the controller. The perturbation injection, log-std reset, and annealing steps are triggered after these known switches. If phase changes must instead be inferred from observations, the mechanism may fire at incorrect times or during stable regimes, directly affecting the central claim of robust adaptation.
- [Abstract] Abstract: the weakest assumption listed in the reader report—that the environment exhibits detectable phase switches allowing the Phase Controller to act without destabilizing safe behaviors—is load-bearing for both the regret bound and the empirical results. No evidence is provided that the controller remains effective when switch detection is replaced by an online inference procedure.
minor comments (2)
- [Abstract] The abstract mentions 'diagnostics confirm persistently higher expert feature rank' but does not indicate where the corresponding plots or tables appear or how feature rank is computed.
- [Abstract] No information is given on the number of independent seeds, confidence intervals, or statistical tests supporting the 26.3%, 12.8%, and 75% figures.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each of the major comments below, providing clarifications and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the dynamic regret bound is asserted to scale with environment variation and cumulative noise energy, yet the abstract supplies neither the derivation nor the explicit assumptions on how the variation term is bounded. Without these it is impossible to verify whether the bound is independent of the listed free parameters (router temperature schedule, entropy and learning-rate annealing rates) or whether it implicitly incorporates the Phase Controller's schedule.
Authors: We agree that the abstract, being a concise summary, does not include the full derivation. The dynamic regret bound is derived in Section 4 of the manuscript, where we explicitly state the assumptions: bounded total variation in the environment dynamics and additive noise with finite energy. The bound incorporates the Phase Controller's actions (including schedules for temperature, entropy, and learning rate) as part of the cumulative noise energy term, so it is not independent of them; rather, the controller is designed to minimize the effective noise. We will revise the abstract to briefly reference the section and key assumptions to improve verifiability. revision: yes
-
Referee: [Abstract] Abstract, Phase Controller description: all reported gains (26.3% NIMR, 12.8% capacity, ~75% collision reduction) and the plasticity-recovery diagnostics are obtained in a simulator whose phases are explicitly scheduled and therefore known to the controller. The perturbation injection, log-std reset, and annealing steps are triggered after these known switches. If phase changes must instead be inferred from observations, the mechanism may fire at incorrect times or during stable regimes, directly affecting the central claim of robust adaptation.
Authors: The referee correctly identifies that our evaluation uses a phase-driven simulator where phase switches are known a priori. This setup allows us to isolate and evaluate the plasticity-enhancing mechanisms of the Phase Controller without confounding effects from detection errors. The non-parametric nature refers to the response strategy (perturbation injection, resets, annealing) rather than the detection itself. We will revise the manuscript to clarify this distinction and add a limitations section discussing the need for online phase detection in real deployments. revision: partial
-
Referee: [Abstract] Abstract: the weakest assumption listed in the reader report—that the environment exhibits detectable phase switches allowing the Phase Controller to act without destabilizing safe behaviors—is load-bearing for both the regret bound and the empirical results. No evidence is provided that the controller remains effective when switch detection is replaced by an online inference procedure.
Authors: We acknowledge that the current work assumes detectable phase switches and provides no empirical evidence for performance under online inference of switches. The regret bound derivation assumes perfect detection timing, and the simulations use oracle switches. Extending to online detection would require additional experiments with change-point detection algorithms, which is beyond the scope of this paper but represents an important direction for future work. revision: no
- The lack of empirical validation for the Phase Controller under online phase inference from observations, as this would require new experiments not present in the current manuscript.
Circularity Check
No significant circularity in derivation chain; regret bound and empirical claims remain independent of inputs.
full rationale
The paper states it derives a dynamic regret bound in which tracking error scales with environment variation and cumulative noise energy. No equations are supplied in the abstract, and the provided text contains no self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the bound to the controller schedule by construction. The Phase Controller's use of scheduled phase switches is an explicit design choice inside the evaluation simulator rather than a mathematical reduction of the bound or the performance claims. Empirical gains (NIMR, capacity, collisions) are reported as direct simulation outcomes under 3GPP-style channels and mobile users; they are not presented as predictions forced by the bound. The derivation chain is therefore self-contained against standard dynamic-regret analysis in non-stationary MDPs and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- router temperature schedule
- entropy and learning-rate annealing rates
axioms (2)
- domain assumption MAPPO training dynamics remain stable when the Phase Controller injects perturbations and resets parameters.
- domain assumption Non-stationarity in the UAV environment occurs in detectable phases that the controller can exploit.
invented entities (1)
-
Phase Controller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on drl based uav communications and networking: Drl fun- damentals, applications and implementations,
W. Zhao, S. Cui, W. Qiu, Z. He, Z. Liu, X. Zheng, B. Mao, and N. Kato, “A survey on drl based uav communications and networking: Drl fun- damentals, applications and implementations,”IEEE Communications Surveys & Tutorials, pp. 1–1, 2025
2025
-
[2]
Energy efficiency maximization for wpt-enabled uav-assisted emergency communication with user mobility,
J. Sun, Z. Sheng, A. A. Nasir, Z. Huang, H. Yu, and Y . Fang, “Energy efficiency maximization for wpt-enabled uav-assisted emergency communication with user mobility,”Physical Communication, vol. 61, p. 102200, 2023. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S1874490723002033
2023
-
[3]
Joint trajectory and communication design for multi-uav enabled wireless networks,
Q. Wu, Y . Zeng, and R. Zhang, “Joint trajectory and communication design for multi-uav enabled wireless networks,”IEEE Transactions on Wireless Communications, vol. 17, no. 3, pp. 2109–2121, 2018
2018
-
[4]
Counterfactual multi-agent policy gradients,
J. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” 2024. [Online]. Available: https://arxiv.org/abs/1705.08926
-
[5]
Distributed dynamic task allocation for unmanned aerial vehicle swarm systems: A networked evolutionary game-theoretic approach,
Z. Zhang, J. Jiang, W.-A. ZHANGet al., “Distributed dynamic task allocation for unmanned aerial vehicle swarm systems: A networked evolutionary game-theoretic approach,”Chinese Journal of Aeronautics, vol. 37, no. 6, pp. 182–204, 2024
2024
-
[6]
Spectrum- aware mobile edge computing for uavs using reinforcement learning,
B. Badnava, T. Kim, K. Cheung, Z. Ali, and M. Hashemi, “Spectrum- aware mobile edge computing for uavs using reinforcement learning,” in 2021 IEEE/ACM Symposium on Edge Computing (SEC). IEEE, 2021, pp. 376–380
2021
-
[7]
DeepThinkVLA: Enhancing Reasoning Capability of Vision-Language-Action Models
C. Yin, Y . Lin, W. Xu, S. Tam, X. Zeng, Z. Liu, and Z. Yin, “Deep- thinkvla: Enhancing reasoning capability of vision-language-action mod- els,”arXiv preprint arXiv:2511.15669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Adaptive bitrate with user-level qoe preference for video streaming,
X. Zuo, J. Yang, M. Wang, and Y . Cui, “Adaptive bitrate with user-level qoe preference for video streaming,” inIEEE INFOCOM 2022 - IEEE Conference on Computer Communications, 2022, pp. 1279–1288
2022
-
[9]
Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks,
H. Lee, H. Cho, H. Kim, D. Kim, D. Min, J. Choo, and C. Lyle, “Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks,” 2025. [Online]. Available: https://arxiv.org/abs/2406.02596
-
[12]
The primacy bias in deep reinforcement learning,
E. Nikishin, M. Schwarzer, P. D’Oro, P.-L. Bacon, and A. Courville, “The primacy bias in deep reinforcement learning,” 2022. [Online]. Available: https://arxiv.org/abs/2205.07802
-
[13]
Non-stationary learning of neural networks with automatic soft parameter reset,
A. Galashov, M. Titsias, A. Gy ¨orgy, C. Lyle, R. Pascanu, Y . W. Teh, and M. Sahani, “Non-stationary learning of neural networks with automatic soft parameter reset,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 83 ...
2024
-
[14]
Stabilising experience replay for deep multi- agent reinforcement learning,
J. N. Foerster, N. Nardelli, G. Farquhar, P. H. S. Torr, P. Kohli, and S. Whiteson, “Stabilising experience replay for deep multi- agent reinforcement learning,”arXiv preprint arXiv:1702.08887, 2017. [Online]. Available: https://arxiv.org/abs/1702.08887
-
[15]
Learning with opponent-learning awareness,
J. Foerster, R. Y . Chen, M. Al-Shedivat, S. Whiteson, P. Abbeel, and I. Mordatch, “Learning with opponent-learning awareness,” in Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2018, pp. 122–130. [Online]. Available: https://dl.acm.org/doi/10.5555/3237383.3237408
-
[16]
Pola: Proximal optimistic learning with opponent-learning awareness,
X. Zhao, X. Chen, K. Zhang, and T. Basar, “Pola: Proximal optimistic learning with opponent-learning awareness,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022. [Online]. Available: https://papers.nips.cc/paper files/paper/2022/hash/ 4dbf3707a3e6730b4fef79aece343bfc-Abstract-Conference.html
2022
-
[17]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational Conference on Machine Learning, 2017, pp. 1126–1135
2017
-
[18]
A survey of multi-agent reinforcement learning: Foundations, advances, and challenges,
X. Li, X. Zhouet al., “A survey of multi-agent reinforcement learning: Foundations, advances, and challenges,”arXiv preprint arXiv:2203.08975, 2024. [Online]. Available: https://arxiv.org/abs/2203. 08975
-
[19]
Tackling non-stationarity in decentralized multi-agent reinforcement learning: Prudent q-learning,
S. Guptaet al., “Tackling non-stationarity in decentralized multi-agent reinforcement learning: Prudent q-learning,” inInternational Conference on Principles and Practice of Multi-Agent Systems (PRIMA). Springer, 2022, pp. 491–507
2022
-
[20]
Energy efficiency maximization for wpt-enabled uav-assisted emergency communication with user mobility,
X. Sun, J. Wang, and Z. Ding, “Energy efficiency maximization for wpt-enabled uav-assisted emergency communication with user mobility,” Physical Communication, vol. 56, p. 102200, 2023
2023
-
[21]
Quantum computing in wireless communications and networking: A tutorial-cum-survey,
W. Zhao, T. Weng, Y . Ruan, Z. Liu, X. Wu, X. Zheng, and N. Kato, “Quantum computing in wireless communications and networking: A tutorial-cum-survey,”IEEE Communications Surveys & Tutorials, vol. 27, no. 4, pp. 2378–2419, 2025
2025
-
[22]
Computing challenges of uav networks: A comprehensive survey
A. Hussain, S. Li, T. Hussain, X. Lin, F. Ali, and A. A. AlZubi, “Computing challenges of uav networks: A comprehensive survey.” Computers, Materials & Continua, vol. 81, no. 2, 2024
2024
-
[23]
Survey of uav-assisted wireless com- munications: Technical challenges, standardization, and future trends,
L. Zhang, R. Xie, P. Wanget al., “Survey of uav-assisted wireless com- munications: Technical challenges, standardization, and future trends,” IEEE Communications Surveys & Tutorials, vol. 25, no. 1, pp. 188–223, 2023
2023
-
[24]
Loss of plasticity in deep continual learning,
S. K. Dohare, M. Abbaset al., “Loss of plasticity in deep continual learning,”Nature, vol. 627, no. 8002, pp. 123–130, 2024
2024
-
[25]
Understanding plasticity in neural networks, 2023
C. Lyle, Z. Zheng, E. Nikishin, B. A. Pires, R. Pascanu, and W. Dabney, “Understanding plasticity in neural networks,” 2023. [Online]. Available: https://arxiv.org/abs/2303.01486
-
[26]
Loss of plasticity in continual deep reinforcement learning,
Z. Abbas, R. Zhao, J. Modayil, A. White, and M. C. Machado, “Loss of plasticity in continual deep reinforcement learning,” 2023. [Online]. Available: https://arxiv.org/abs/2303.07507
-
[27]
The dormant neuron phenomenon in deep reinforcement learning,
G. Sokar, R. Agarwal, P. S. Castro, and U. Evci, “The dormant neuron phenomenon in deep reinforcement learning,” inProceedings of the 40th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 202, 2023. [Online]. Available: https://proceedings.mlr.press/v202/sokar23a/sokar23a.pdf
2023
-
[28]
Meta-learning plasticity rules for continual learning,
C. Beattieet al., “Meta-learning plasticity rules for continual learning,” IEEE Transactions on Neural Networks and Learning Systems, 2022
2022
-
[29]
The dormant neuron phenomenon in multi-agent reinforcement learning value factorization,
H. Qin, C. Ma, M. Deng, Z. Liu, S. Mei, X. Liu, C. Wang, and S. Shen, “The dormant neuron phenomenon in multi-agent reinforcement learning value factorization,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=4NGrHrhJPx
2024
-
[30]
Dealing with non-stationarity in multi-agent deep reinforcement learning,
G. Papoudakis, F. Christianos, A. Rahman, and S. V . Albrecht, “Dealing with non-stationarity in multi-agent deep reinforcement learning,” 2019. [Online]. Available: https://arxiv.org/abs/1906.04737
-
[31]
Scaling multi-agent reinforcement learning with selective parameter sharing,
F. Christianos, G. Papoudakis, M. A. Rahman, and S. V . Albrecht, “Scaling multi-agent reinforcement learning with selective parameter sharing,” inInternational Conference on Machine Learning. PMLR, 2021, pp. 1989–1998
2021
-
[32]
arXiv preprint arXiv:2003.08039 , year=
T. Wang, H. Dong, V . Lesser, and C. Zhang, “Roma: Multi- agent reinforcement learning with emergent roles,”arXiv preprint arXiv:2003.08039, 2020
-
[33]
Multiagent continual coordination via progressive task contextualization,
L. Yuan, L. Li, Z. Zhang, F. Zhang, C. Guan, and Y . Yu, “Multiagent continual coordination via progressive task contextualization,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 4, pp. 6326–6340, 2025
2025
-
[34]
Adaptive mixtures of local experts,
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton, “Adaptive mixtures of local experts,”Neural Computation, vol. 3, no. 1, pp. 79–87, 1991. 19
1991
-
[35]
Mixture of experts in a mixture of reinforcement learning settings,
Y . He and X. Liu, “Mixture of experts in a mixture of reinforcement learning settings,”arXiv preprint arXiv:2406.18420, 2024
-
[36]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” 2022. [Online]. Available: https://arxiv.org/abs/2101.03961
work page internal anchor Pith review arXiv 2022
-
[37]
Enabling personalized video quality optimization with vidhoc,
X. Zhang, P. Schmitt, M. Chetty, N. Feamster, and J. Jiang, “Enabling personalized video quality optimization with vidhoc,” 2022. [Online]. Available: https://arxiv.org/abs/2211.15959
-
[38]
A comprehensive survey on uav communication channel modeling,
C. Yan, L. Fu, J. Zhang, and J. Wang, “A comprehensive survey on uav communication channel modeling,”IEEE Access, vol. 7, p. —, 2019, early access version; comprehensive A2G/A2A/G2G survey
2019
-
[39]
Study on channel model for frequencies from 0.5 to 100 GHz,
3GPP, “Study on channel model for frequencies from 0.5 to 100 GHz,” 3GPP, Technical Report TR 38.901, Nov. 2020, release 16. UMi/UMa/InH channel models; LoS probability and path loss baselines. [Online]. Available: https://www.etsi.org/deliver/etsi tr/138900 138999/ 138901/16.01.00 60/tr 138901v160100p.pdf
2020
-
[40]
New energy consumption model for rotary-wing UA V propulsion,
H. Yan, Y . Chen, and S.-H. Yang, “New energy consumption model for rotary-wing UA V propulsion,”IEEE Wireless Communications Letters, vol. 10, no. 9, pp. 2009–2012, 2021
2009
-
[41]
Energy minimization for wireless communication with rotary-wing UA V,
Y . Zeng, J. Xu, and R. Zhang, “Energy minimization for wireless communication with rotary-wing UA V,”IEEE Transactions on Wireless Communications, vol. 18, no. 4, pp. 2329–2345, 2019
2019
-
[42]
Maximizing energy-efficiency for ris–uav assisted mobile edge computing,
Z. Wanget al., “Maximizing energy-efficiency for ris–uav assisted mobile edge computing,”Applied Soft Computing, 2024, remarks that the communication portion is negligible relative to flight energy in UA V systems. [Online]. Available: https://www.sciencedirect.com/ science/article/abs/pii/S1874490724001575
2024
-
[43]
A survey of mobility models for ad hoc network research,
T. Camp, J. Boleng, and V . Davies, “A survey of mobility models for ad hoc network research,”Wireless Communications and Mobile Computing, vol. 2, no. 5, pp. 483–502, 2002
2002
-
[44]
A group mobility model for ad hoc wireless networks,
X. Hong, M. Gerla, G. Pei, and C.-C. Chiang, “A group mobility model for ad hoc wireless networks,” inProc. ACM/IEEE MSWiM, 1999, pp. 53–60
1999
-
[45]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” inarXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. I. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” arXiv:1506.02438, 2016
work page internal anchor Pith review arXiv 2016
-
[47]
C. Amato, “An introduction to centralized training for decentralized execution in cooperative multi-agent reinforcement learning,” 2024. [Online]. Available: https://arxiv.org/abs/2409.03052
-
[48]
Disentangling the causes of plasticity loss in neural networks,
C. Lyle, Z. Zheng, K. Khetarpal, H. van Hasselt, R. Pascanu, J. Martens, and W. Dabney, “Disentangling the causes of plasticity loss in neural networks,” 2024. [Online]. Available: https://arxiv.org/abs/2402.18762
-
[49]
Reinforcement learning for non-stationary markov decision processes: The blessing of (more) optimism,
W. C. Cheung, D. Simchi-Levi, and R. Zhu, “Reinforcement learning for non-stationary markov decision processes: The blessing of (more) optimism,” inProceedings of the 37th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 119, 2020, pp. 1843–1854. [Online]. Available: https://proceedings.mlr.press/v11...
2020
-
[50]
Dynamic regret of policy optimization in non-stationary environments,
Y . Fei, Z. Yang, Z. Wang, and Q. Xie, “Dynamic regret of policy optimization in non-stationary environments,” inAdvances in Neural Information Processing Systems (NeurIPS 2020),
2020
-
[51]
Available: https://proceedings.neurips.cc/paper/2020/ file/4b0091f82f50ff7095647fe893580d60-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper/2020/ file/4b0091f82f50ff7095647fe893580d60-Paper.pdf
2020
-
[52]
Trust region-guided proximal policy optimization,
Y . Wang, H. He, X. Tan, and Y . Gan, “Trust region-guided proximal policy optimization,” 2019. [Online]. Available: https: //arxiv.org/abs/1901.10314
-
[53]
Ppo in the fisher-rao geometry,
R.-A. Lascu, D. ˇSiˇska, and Łukasz Szpruch, “Ppo in the fisher-rao geometry,” 2025. [Online]. Available: https://arxiv.org/abs/2506.03757
-
[54]
Towards understanding the mixture-of-experts layer in deep learning,
Z. Chen, Y . Deng, Y . Wu, Q. Gu, and Y . Li, “Towards understanding the mixture-of-experts layer in deep learning,” inAdvances in Neural Information Processing Systems (NeurIPS 2022), 2022, includes theory and supplemental material on non-collapse and specialization. [On- line]. Available: https://proceedings.neurips.cc/paper files/paper/2022/ file/91edf...
2022
-
[55]
A theoretical view on sparsely activated networks,
C. Baykal, N. Dikkala, R. Panigrahy, C. Rashtchian, and X. Wang, “A theoretical view on sparsely activated networks,” 2022. [Online]. Available: https://arxiv.org/abs/2208.04461
-
[56]
Mixture- of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. Dai, Z. Chen, Q. V . Le, and J. Laudon, “Mixture- of-experts with expert choice routing,” inAdvances in Neural Information Processing Systems (NeurIPS 2022), 2022. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2022/file/2f00ecd787b432c1d36f3de9800728eb-Paper-Conference.pdf
2022
-
[57]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Claudia, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proc. Nat. Acad. Sci. USA, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[58]
R. Agarwal, M. Schwarzer, P. S. Castro, A. Courville, and M. G. Bellemare, “Deep reinforcement learning at the edge of the statistical precipice,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021, introduces robust aggregate metrics such as IQM; library: https://github.com/google-research/rliable. [Online]. Available: https://arxiv.org/...
-
[59]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V . Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,” inInternational Conference on Learning Representations (ICLR), 2017, iCLR 2017; see also PDF mirror: https://www.cs.toronto.edu/ ∼hinton/absps/Outrageously. pdf. [Online]. Available: https:/...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.