Recognition: no theorem link
Interactive ASR: Towards Human-Like Interaction and Semantic Coherence Evaluation for Agentic Speech Recognition
Pith reviewed 2026-05-10 18:17 UTC · model grok-4.3
The pith
An agentic ASR framework uses LLM judges for semantic evaluation and multi-turn LLM agents for interactive refinement to improve meaning-level accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that an LLM prompted as a semantic judge can evaluate recognition quality beyond word matches, and that an LLM agent simulating multi-turn human interaction can iteratively refine ASR outputs through semantic feedback, producing higher semantic fidelity on GigaSpeech, WenetSpeech, and ASRU 2019 code-switching sets as measured by both objective and subjective criteria.
What carries the argument
LLM-as-a-Judge semantic evaluation metric together with an LLM-driven multi-turn agent that issues clarification requests and applies corrections to the ASR transcript.
If this is right
- ASR quality can be assessed at the level of sentence meaning rather than individual word matches.
- Systems can recover from recognition errors through dialogue instead of requiring a complete re-recognition pass.
- The approach scales to multiple languages and code-switching without retraining the base ASR model.
- Both automated semantic metrics and human listeners register measurable gains in fidelity and correction capability.
Where Pith is reading between the lines
- Real voice interfaces could adopt similar agents to request user clarifications in live settings rather than waiting for full utterances.
- Post-processing agent layers might reduce reliance on ever-larger training corpora by correcting errors after initial decoding.
- The same judge-plus-agent pattern could apply to other modalities such as video captioning or live translation where semantic drift also occurs.
Load-bearing premise
An LLM prompted as a judge can reliably judge semantic correctness of ASR outputs without injecting its own biases or hallucinations, and the simulated multi-turn interactions do not degrade final accuracy.
What would settle it
A side-by-side human rating study in which raters consistently assign different semantic-correctness scores to the same ASR outputs than the LLM judge, or a blind test showing that adding interactive turns raises rather than lowers final word or semantic error rates.
Figures



read the original abstract
Recent years have witnessed remarkable progress in automatic speech recognition (ASR), driven by advances in model architectures and large-scale training data. However, two important aspects remain underexplored. First, Word Error Rate (WER), the dominant evaluation metric for decades, treats all words equally and often fails to reflect the semantic correctness of an utterance at the sentence level. Second, interactive correction-an essential component of human communication-has rarely been systematically studied in ASR research. In this paper, we integrate these two perspectives under an agentic framework for interactive ASR. We propose leveraging LLM-as-a-Judge as a semantic-aware evaluation metric to assess recognition quality beyond token-level accuracy. Furthermore, we design an LLM-driven agent framework to simulate human-like multi-turn interaction, enabling iterative refinement of recognition outputs through semantic feedback. Extensive experiments are conducted on standard benchmarks, including GigaSpeech (English), WenetSpeech (Chinese), the ASRU 2019 code-switching test set. Both objective and subjective evaluations demonstrate the effectiveness of the proposed framework in improving semantic fidelity and interactive correction capability. We will release the code to facilitate future research in interactive and agentic ASR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic framework for interactive ASR. It uses an LLM-as-a-Judge to provide semantic-aware evaluation of ASR outputs beyond token-level WER and designs an LLM-driven multi-turn agent to simulate human-like interactive corrections via semantic feedback. Experiments are conducted on GigaSpeech (English), WenetSpeech (Chinese), and the ASRU 2019 code-switching set, with claims that both objective and subjective evaluations show improved semantic fidelity and correction capability. Code release is promised.
Significance. If the LLM judge proves reliable and the agent yields genuine gains without accuracy degradation, the work could meaningfully advance ASR beyond WER-centric evaluation and static decoding toward more interactive, semantically grounded systems. The idea of agentic interaction is timely. However, the absence of any reported validation, baselines, or quantitative evidence in the provided description substantially weakens the potential impact at present.
major comments (3)
- The abstract asserts effectiveness based on experiments on GigaSpeech, WenetSpeech, and ASRU 2019 but supplies no prompting details, baselines, quantitative deltas, statistical significance, or controls for LLM variability, leaving the central claim of improved semantic fidelity and interactive correction unsupported by visible evidence.
- No validation of the LLM-as-Judge metric against human semantic judgments (e.g., correlation coefficients, inter-annotator agreement, or ablation on prompt sensitivity) is described. This is load-bearing because the entire evaluation framework and the agent's feedback loop depend on the judge being free of systematic bias or hallucination when scoring meaning preservation.
- The multi-turn agent framework is presented without analysis of error propagation across turns, comparison to non-agentic correction baselines, or measurement of whether iterative refinement preserves or degrades overall WER. These omissions directly affect the claim that the approach enables human-like interaction without accuracy loss.
minor comments (2)
- Clarify the exact definition of 'semantic coherence' used by the LLM judge and how it differs from existing semantic similarity metrics in the ASR literature.
- The abstract mentions 'standard benchmarks' but does not list exact test-set sizes or splits; include these in the experimental section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional empirical detail and validation will strengthen the paper. We have revised the manuscript to address each major comment directly by expanding the experimental reporting, adding validation studies, and including targeted analyses of the agent framework.
read point-by-point responses
-
Referee: The abstract asserts effectiveness based on experiments on GigaSpeech, WenetSpeech, and ASRU 2019 but supplies no prompting details, baselines, quantitative deltas, statistical significance, or controls for LLM variability, leaving the central claim of improved semantic fidelity and interactive correction unsupported by visible evidence.
Authors: We agree the abstract is necessarily concise and omits these specifics. The full manuscript already contains the experimental details in Sections 3 and 4, including the LLM prompts, baseline systems (standard ASR and non-interactive correction), quantitative deltas on both WER and semantic metrics, and significance testing. To improve visibility, we have revised the abstract to reference the key gains and added an explicit summary paragraph plus controls for LLM variability (results averaged over multiple runs with varied seeds) in the experimental section. revision: yes
-
Referee: No validation of the LLM-as-Judge metric against human semantic judgments (e.g., correlation coefficients, inter-annotator agreement, or ablation on prompt sensitivity) is described. This is load-bearing because the entire evaluation framework and the agent's feedback loop depend on the judge being free of systematic bias or hallucination when scoring meaning preservation.
Authors: This is a fair and important observation. We have added a dedicated validation subsection that reports Pearson and Spearman correlations with human semantic judgments, inter-annotator agreement statistics, and an ablation on prompt variations to demonstrate robustness. The revised manuscript now explicitly addresses potential biases and how they were mitigated. revision: yes
-
Referee: The multi-turn agent framework is presented without analysis of error propagation across turns, comparison to non-agentic correction baselines, or measurement of whether iterative refinement preserves or degrades overall WER. These omissions directly affect the claim that the approach enables human-like interaction without accuracy loss.
Authors: We accept that these analyses are necessary to support the interaction claims. The revision includes new experiments that track WER and semantic scores across turns to quantify error propagation, direct comparisons to non-agentic single-turn baselines, and explicit measurements confirming that iterative refinement preserves (and in some cases slightly improves) WER while raising semantic fidelity. These results appear in updated tables and figures. revision: yes
Circularity Check
No circularity: framework and evaluations are externally grounded
full rationale
The paper introduces an LLM-as-Judge metric and multi-turn agent framework for interactive ASR, with effectiveness claims resting on described experiments across GigaSpeech, WenetSpeech, and code-switching benchmarks rather than any internal derivation. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the central claims to tautological inputs by construction. The methodology applies external LLMs for judgment and correction without redefining success metrics in terms of themselves, making the work self-contained against the reported objective and subjective results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can serve as reliable judges of semantic correctness in ASR transcripts
- domain assumption LLM agents can simulate effective human-like multi-turn correction without introducing new errors
invented entities (2)
-
LLM-as-a-Judge
no independent evidence
-
LLM-driven agent framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Introduction Automatic speech recognition (ASR) plays a pivotal role in human–computer interaction by enabling computers to under- stand users’ intent through speech. In recent years, ASR tech- nologies have achieved remarkable progress, driven by advances in both model architectures and large-scale training data. Ex- tensive research has explored a varie...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
To address this, several semantic-aware metrics have been proposed
Related Works While WER has long served as the standard metric for ASR eval- uation, its inherent design of assigning equal weight to all words fails to capture critical semantic errors. To address this, several semantic-aware metrics have been proposed. Semantic WER
-
[3]
Moving to embedding-based evaluation, SemDist [18] utilized RoBERTa-based sentence embeddings to measure se- mantic similarity beyond literal overlap
introduced dynamic weighting, which utilizes Named En- tity Recognition to extract keywords, assigning higher weights to critical entities and lower weights to filler words during error cal- culation. Moving to embedding-based evaluation, SemDist [18] utilized RoBERTa-based sentence embeddings to measure se- mantic similarity beyond literal overlap. Most ...
-
[4]
Unlike these continuous scoring metrics, our LLM-as-a-Judge adopts a binary functional criterion, acting as a strict gatekeeper to determine if the user’s intent is executable
leveraged LLMs to assign graded penalties based on er- ror severity (e.g., ignoring colloquial variations while penalizing meaning changes). Unlike these continuous scoring metrics, our LLM-as-a-Judge adopts a binary functional criterion, acting as a strict gatekeeper to determine if the user’s intent is executable. Regarding error correction based on hum...
-
[5]
Proposed Paradigm Let 𝐼 denote the user speech and𝑌 the output transcript. Existing ASR systems operate under a single-pass decoding paradigm: 𝑌 = ASR(𝐼) (1) This formulation is static: once a transcription is produced, the system has no mechanism to incorporate subsequent user feed- back. To address this limitation, we propose the Interactive ASR framewo...
-
[6]
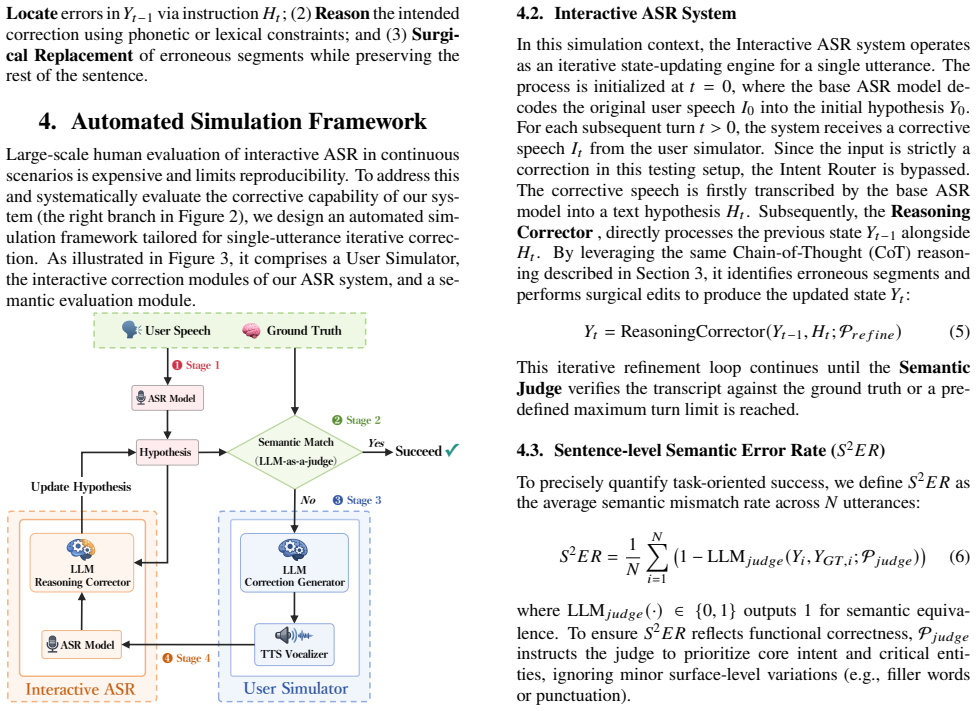
Automated Simulation Framework Large-scale human evaluation of interactive ASR in continuous scenarios is expensive and limits reproducibility. To address this and systematically evaluate the corrective capability of our sys- tem (the right branch in Figure 2), we design an automated sim- ulation framework tailored for single-utterance iterative correc- t...
-
[7]
We first outline the experimental setup in Section 5.1, detailing the diverse benchmarks and the foun- dational models
Experiments In this section, we comprehensively evaluate the proposed Inter- active ASR framework. We first outline the experimental setup in Section 5.1, detailing the diverse benchmarks and the foun- dational models. Before analyzing the system performance, we conduct a Human-AI Alignment Study in Section 5.2 to es- tablish the credibility of 𝑆2𝐸 𝑅 by d...
-
[8]
We introduced 𝑆2𝐸 𝑅, a novel met- ric that leverages LLMs as judges to prioritize sentence-level semantic coherence
Conclusion In this work, we addressed two critical limitations in traditional ASR: semantic-blind evaluation and the absence of interactive correction mechanisms. We introduced 𝑆2𝐸 𝑅, a novel met- ric that leverages LLMs as judges to prioritize sentence-level semantic coherence. Furthermore, we proposed an Interactive ASR framework that employs CoT reason...
-
[9]
Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning , 2006, pp. 369–376
2006
-
[10]
Sequence transduction with recurrent neural networks.arXiv preprint arXiv:1211.3711,
A. Graves, “Sequence transduction with recurrent neural net- works,” arXiv preprint arXiv:1211.3711, 2012
-
[11]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,
W . Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” in 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP) . IEEE, 2016, pp. 4960– 4964
2016
-
[12]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” in International conference on machine learning . PMLR, 2023, pp. 28 492–28 518
2023
-
[13]
On decoder-only architecture for speech- to-text and large language model integration,
J. Wu, Y . Gaur, Z. Chen, L. Zhou, Y . Zhu, T. Wang, J. Li, S. Liu, B. Ren, L. Liu et al. , “On decoder-only architecture for speech- to-text and large language model integration,” in 2023 IEEE au- tomatic speech recognition and understanding workshop (ASRU) . IEEE, 2023, pp. 1–8
2023
-
[14]
Slm: Bridge the thin gap between speech and text foundation models,
M. Wang, W. Han, I. Shafran, Z. Wu, C.-C. Chiu, Y . Cao, N. Chen, Y . Zhang, H. Soltau, P . K. Rubenstein et al. , “Slm: Bridge the thin gap between speech and text foundation models,” in 2023 IEEE Automatic Speech Recognition and Understanding Work- shop (ASRU). IEEE, 2023, pp. 1–8
2023
-
[15]
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,” arXiv preprint arXiv:2310.13289, 2023
-
[16]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Y . Chu, J. Xu, X. Zhou, Q. Y ang, S. Zhang, Z. Y an, C. Zhou, and J. Zhou, “Qwen-audio: Advancing universal audio understand- ing via unified large-scale audio-language models,”arXiv preprint arXiv:2311.07919, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Prompt- ing large language models with speech recognition abilities,
Y . Fathullah, C. Wu, E. Lakomkin, J. Jia, Y . Shangguan, K. Li, J. Guo, W. Xiong, J. Mahadeokar, O. Kalinli et al. , “Prompt- ing large language models with speech recognition abilities,” in ICASSP 2024-2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) . IEEE, 2024, pp. 13 351–13 355
2024
-
[18]
An embarrassingly simple approach for LLM with strong ASR capacity,
Z. Ma, G. Y ang, Y . Y ang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang et al., “An embarrassingly simple approach for llm with strong asr capacity,” arXiv preprint arXiv:2402.08846 , 2024
-
[19]
Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition,
Y . Bai, J. Chen, J. Chen, W. Chen, Z. Chen, C. Ding, L. Dong, Q. Dong, Y . Du, K. Gao et al., “Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition,” arXiv preprint arXiv:2407.04675, 2024
-
[20]
K.-T. Xu, F.-L. Xie, X. Tang, and Y . Hu, “Fireredasr: Open-source industrial-grade mandarin speech recognition mod- els from encoder-decoder to llm integration,” arXiv preprint arXiv:2501.14350, 2025
-
[21]
K. An, Y . Chen, Z. Chen, C. Deng, Z. Du, C. Gao, Z. Gao, B. Gong, X. Li, Y . Li et al. , “Fun-asr technical report,” arXiv preprint arXiv:2509.12508, 2025
-
[22]
X. Shi, X. Wang, Z. Guo, Y . Wang, P . Zhang, X. Zhang, Z. Guo, H. Hao, Y . Xi, B. Y anget al., “Qwen3-asr technical report,” arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review arXiv 2026
-
[23]
arXiv preprint arXiv:2106.02016 , year=
S. Roy, “Semantic-wer: A unified metric for the evaluation of asr transcript for end usability,” arXiv preprint arXiv:2106.02016, 2021
-
[24]
De- noising ger: A noise-robust generative error correction with llm for speech recognition,
Y . Liu, M. Xu, Y . Chen, L. He, L. Fang, S. Fang, and L. Liu, “De- noising ger: A noise-robust generative error correction with llm for speech recognition,” in 2025 International Joint Conference on Neural Networks (IJCNN). IEEE, 2025, pp. 1–8
2025
-
[25]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xing et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” Advances in neural information pro- cessing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[26]
S. Kim, A. Arora, D. Le, C.-F. Y eh, C. Fuegen, O. Kalinli, and M. L. Seltzer, “Semantic distance: A new metric for asr perfor- mance analysis towards spoken language understanding,” arXiv preprint arXiv:2104.02138, 2021
-
[27]
Laser: An llm-based asr scoring and evaluation rubric,
A. Parulekar and P . Jyothi, “Laser: An llm-based asr scoring and evaluation rubric,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 773–24 782
2025
-
[28]
Multimodal error correction for speech user interfaces,
B. Suhm, B. Myers, and A. Waibel, “Multimodal error correction for speech user interfaces,”ACM transactions on computer-human interaction (TOCHI), vol. 8, no. 1, pp. 60–98, 2001
2001
-
[29]
Efficient speech transcription through respeaking
M. Sperber, G. Neubig, C. Fügen, S. Nakamura, and A. Waibel, “Efficient speech transcription through respeaking.” in Inter- speech, 2013, pp. 1087–1091
2013
-
[30]
React: Synergizing reasoning and acting in language models,
S. Y ao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” in The eleventh international conference on learning rep- resentations, 2022
2022
-
[31]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in neural information pro- cessing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[32]
X. Shi, Q. Feng, and L. Xie, “The asru 2019 mandarin-english code-switching speech recognition challenge: Open datasets, tracks, methods and results,” arXiv preprint arXiv:2007.05916 , 2020
-
[33]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,
G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhang et al. , “Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,” arXiv preprint arXiv:2106.06909, 2021
-
[34]
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,
B. Zhang, H. Lv, P . Guo, Q. Shao, C. Y ang, L. Xie, X. Xu, H. Bu, X. Chen, C. Zeng et al., “Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2022, pp. 6182–6186
2022
-
[35]
A. Y ang, A. Li, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system,
W . Deng, S. Zhou, J. Shu, J. Wang, and L. Wang, “Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system,” arXiv preprint arXiv:2502.05512, 2025
-
[37]
Zechner and K
K. Zechner and K. Evanini, Eds., Automated Speaking As- sessment: Using Language Technologies to Score Spontaneous Speech, 1st ed. Routledge, 2019
2019
-
[38]
Proceedings of the Royal Society of London 58, 240–242
K. Pearson, “Vii. note on regression and inheritance in the case of two parents,” Proceedings of the Royal Society of London , vol. 58, no. 347-352, pp. 240–242, 12 1895. [Online]. Available: https://doi.org/10.1098/rspl.1895.0041
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.