Recognition: no theorem link
ACE-Bench: A Lightweight Benchmark for Evaluating Azure SDK Usage Correctness
Pith reviewed 2026-05-15 22:59 UTC · model grok-4.3
The pith
ACE-Bench converts Azure SDK documentation examples into coding tasks and scores LLM outputs for correct API usage using regex patterns and reference-based LLM judges without any code execution or cloud resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
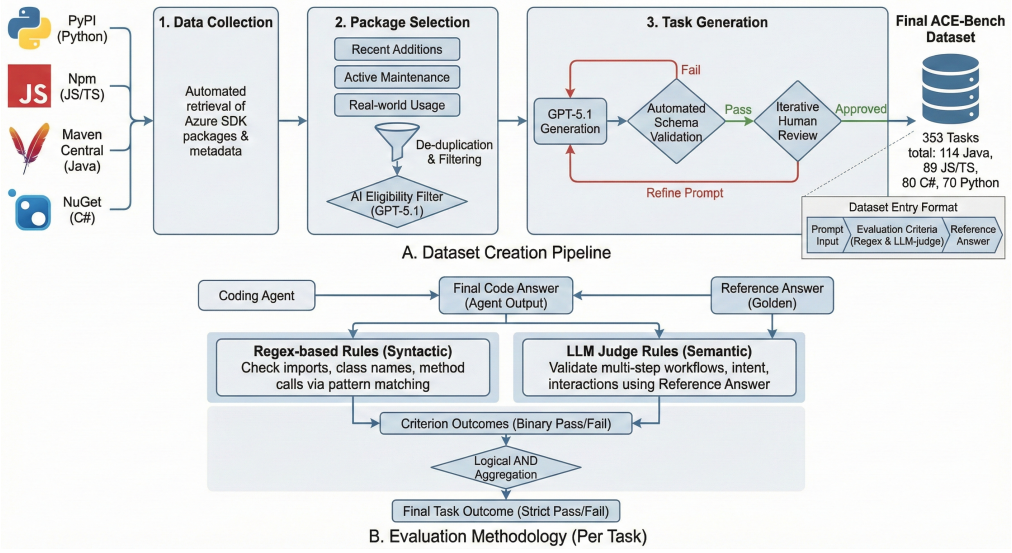
ACE-Bench turns official Azure SDK documentation examples into self-contained coding tasks and validates solutions with task-specific atomic criteria: deterministic regex checks that enforce required API usage patterns and reference-based LLM-judge checks that capture semantic workflow constraints. This design makes SDK-centric evaluation practical in day-to-day development and CI: it reduces evaluation cost, improves repeatability, and scales to new SDKs and languages as documentation evolves.
What carries the argument
Task-specific atomic criteria that combine deterministic regex checks for required API calls with reference-based LLM-judge scoring for semantic correctness.
If this is right
- Reduces the cost and complexity of evaluating LLM coding agents on cloud SDK tasks by eliminating the need for cloud provisioning or end-to-end test environments.
- Enables repeatable benchmarking in CI pipelines as new SDK documentation is released.
- Quantifies measurable improvements in LLM performance when retrieval from official documentation is enabled during code generation.
- Reveals substantial differences in how well different state-of-the-art LLMs follow required Azure SDK usage patterns.
Where Pith is reading between the lines
- The same regex-plus-LLM-judge structure could be applied to SDKs from other cloud providers without major redesign.
- Task-specific criteria may surface recurring error patterns that could guide targeted fine-tuning or prompt improvements for coding agents.
- Execution-free validation may allow larger-scale studies of retrieval-augmented generation across many SDK versions than execution-based methods permit.
Load-bearing premise
The chosen regex patterns and LLM-judge criteria accurately and completely capture what counts as correct Azure SDK usage for each task.
What would settle it
A generated solution that passes both the regex checks and the LLM judge yet produces incorrect behavior or errors when the same code is run against real Azure resources.
Figures

read the original abstract
We present ACE-Bench (Azure SDK Coding Evaluation Benchmark), an execution-free benchmark that provides fast, reproducible pass or fail signals for whether large language model (LLM)-based coding agents use Azure SDKs correctly-without provisioning cloud resources or maintaining fragile end-to-end test environments. ACE-Bench turns official Azure SDK documentation examples into self-contained coding tasks and validates solutions with task-specific atomic criteria: deterministic regex checks that enforce required API usage patterns and reference-based LLM-judge checks that capture semantic workflow constraints. This design makes SDK-centric evaluation practical in day-to-day development and CI: it reduces evaluation cost, improves repeatability, and scales to new SDKs and languages as documentation evolves. Using a lightweight coding agent, we benchmark multiple state-of-the-art LLMs and quantify the benefit of retrieval in an MCP-enabled augmented setting, showing consistent gains from documentation access while highlighting substantial cross-model differences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ACE-Bench, an execution-free benchmark that converts official Azure SDK documentation examples into self-contained coding tasks for LLM-based agents. Solutions are validated via task-specific atomic criteria: deterministic regex checks enforcing required API usage patterns and reference-based LLM-judge checks capturing semantic workflow constraints. The authors benchmark multiple state-of-the-art LLMs using a lightweight agent and report consistent gains from retrieval in an MCP-augmented setting.
Significance. If the criteria prove reliable, ACE-Bench would provide a practical, low-cost, and highly reproducible method for evaluating SDK usage correctness without cloud provisioning or fragile end-to-end tests. This directly addresses scalability and repeatability challenges in coding-agent evaluation for cloud services and supports ongoing maintenance as documentation evolves.
major comments (2)
- [Abstract and Evaluation Criteria] Abstract and § on evaluation criteria: the central claim that regex plus reference-based LLM-judge criteria produce reliable pass/fail signals is unsupported, as the manuscript supplies no quantitative validation (precision/recall, false-positive rates, or inter-annotator agreement with human experts) against actual Azure executions or ground truth.
- [Results] Results section: the paper states that it quantifies benefits of retrieval and highlights cross-model differences, yet provides no tables, figures, or numerical outcomes, leaving the empirical claims unsubstantiated.
minor comments (1)
- [Methodology] Clarify the exact construction process for the atomic criteria from documentation examples so that extension to new SDKs and languages is fully reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the evaluation criteria require quantitative validation and that the results section must include the supporting tables and figures. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation Criteria] Abstract and § on evaluation criteria: the central claim that regex plus reference-based LLM-judge criteria produce reliable pass/fail signals is unsupported, as the manuscript supplies no quantitative validation (precision/recall, false-positive rates, or inter-annotator agreement with human experts) against actual Azure executions or ground truth.
Authors: We acknowledge that the current manuscript lacks quantitative validation of the combined regex and LLM-judge criteria. Because ACE-Bench is intentionally execution-free, direct comparison to live Azure executions is outside the benchmark's scope. However, we agree that reliability must be demonstrated. In the revision we will add a human-evaluation study on a representative subset of tasks, reporting precision, recall, false-positive rate, and inter-annotator agreement between the automated criteria and expert judgments derived from the official documentation. This will supply the missing empirical support for the pass/fail signals. revision: yes
-
Referee: [Results] Results section: the paper states that it quantifies benefits of retrieval and highlights cross-model differences, yet provides no tables, figures, or numerical outcomes, leaving the empirical claims unsubstantiated.
Authors: The referee correctly notes that the submitted manuscript references benchmarking results and retrieval gains but does not present the actual data. This was an oversight in the submission package. The revised version will include a complete Results section containing (i) tables with pass rates for each evaluated LLM under the baseline and MCP-augmented settings, (ii) numerical quantification of retrieval benefit (absolute and relative gains), and (iii) figures illustrating cross-model performance differences. All claims will be directly supported by these tables and figures. revision: yes
Circularity Check
No circularity: benchmark constructed directly from documentation
full rationale
The paper defines ACE-Bench by converting official Azure SDK documentation examples into tasks and specifies validation via deterministic regex for API patterns plus reference-based LLM judges for workflow semantics. These criteria are presented as explicit, task-specific constructions without any fitted parameters, predictions that reduce to inputs, or load-bearing self-citations. LLM benchmarking is shown as an application of the benchmark rather than a derivation that loops back to its own definitions. The derivation chain is self-contained against external documentation sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Official Azure SDK documentation examples represent correct and complete usage patterns.
Reference graph
Works this paper leans on
-
[2]
Yihong Dong, Xue Jiang, Jiaru Qian, Tian Wang, Kechi Zhang, Zhi Jin, and Ge Li
-
[3]
A Survey on Code Generation with LLM-based Agents. arXiv:2508.00083 (2025). doi:10.48550/arXiv.2508.00083 arXiv:2508.00083 [cs]
-
[4]
Markus Freitag, Ricardo Rei, Nitika Mathur, Chi-kiu Lo, Craig Stewart, George Foster, Alon Lavie, and Ondřej Bojar. 2021. Results of the WMT21 Metrics Shared Task: Evaluating Metrics with Expert-based Human Evaluations on TED and News Domain. InProceedings of the Sixth Conference on Machine Translation, Loic Barrault, Ondrej Bojar, Fethi Bougares, Rajen C...
work page 2021
-
[5]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. A Survey on LLM-as-a-Judge. arXiv:2411.15594 (Oct. 2025). doi:10.48550/arXiv.2411.15594 arXiv:2411.15594 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15594 2025
-
[6]
Hangfeng He, Hongming Zhang, and Dan Roth. 2024. SocREval: Large Lan- guage Models with the Socratic Method for Reference-Free Reasoning Evaluation. arXiv:2310.00074 (Dec. 2024). doi:10.48550/arXiv.2310.00074 arXiv:2310.00074 [cs]
-
[7]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation. (Nov. 2024). doi:10. 1145/3747588 arXiv:2406.00515 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Marzena Karpinska and Mohit Iyyer. 2023. Large language models effectively leverage document-level context for literary translation, but critical errors persist. arXiv:2304.03245 (May 2023). doi:10.48550/arXiv.2304.03245 arXiv:2304.03245 [cs]
-
[10]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2021. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 (April 2021). doi:10.48550/ arXiv.2005.11401 arXiv:2005.11401 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien De Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
-
[12]
Nikolaos Malamas, Emmanouil Tsardoulias, Konstantinos Panayiotou, and An- dreas L. Symeonidis. 2025. Toward efficient vibe coding: An LLM-based agent for low-code software development.Journal of Computer Languages85 (2025), 101367. doi:10.1016/j.cola.2025.101367
-
[14]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. FActScore: Fine- grained Atomic Evaluation of Factual Precision in Long Form Text Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguis...
-
[16]
Nidhish Shah, Zulkuf Genc, and Dogu Araci. 2024. StackEval: Benchmarking LLMs in Coding Assistance. arXiv:2412.05288 (Nov. 2024). doi:10.48550/arXiv. 2412.05288 arXiv:2412.05288 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2024
- [17]
-
[18]
Wannita Takerngsaksiri, Jirat Pasuksmit, Patanamon Thongtanunam, Chakkrit Tantithamthavorn, Ruixiong Zhang, Fan Jiang, Jing Li, Evan Cook, Kun Chen, and Ming Wu. 2025. Human-In-the-Loop Software Development Agents. arXiv:2411.12924 (Jan. 2025). doi:10.48550/arXiv.2411.12924 arXiv:2411.12924 [cs]
-
[19]
Sijun Tan, Siyuan Zhuang, Kyle Montgomery, William Yuan Tang, Alejandro Cuadron, Chenguang Wang, Raluca Popa, and Ion Stoica. 2025. JudgeBench: A Benchmark for Evaluating LLM-Based Judges. InThe Thirteenth Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= G0dksFayVq
work page 2025
-
[20]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Un- derstanding and Generation. InProceedings of the 2021 Conference on Empir- ical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Eds.). Association...
-
[21]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, Diyi Yang, Sida Wang, and Ofir Press. 2025. SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?. InThe Thirteenth International Confer- ence on Learning Representations. https://openr...
work page 2025
-
[22]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685 (Dec. 2023). doi:10.48550/arXiv.2306.05685 arXiv:2306.05685 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
-
[23]
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. 2025. JudgeLM: Fine-tuned Large Language Models are Scalable Judges. arXiv:2310.17631 (March 2025). doi:10.48550/arXiv.2310.17631 arXiv:2310.17631 [cs]
-
[24]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, Thong Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Biny...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.15877 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.