Recognition: unknown
ODUTQA-MDC: A Task for Open-Domain Underspecified Tabular QA with Multi-turn Dialogue-based Clarification
Pith reviewed 2026-05-10 15:50 UTC · model grok-4.3
The pith
A multi-agent framework resolves ambiguities in open-domain tabular questions through multi-turn dialogue clarification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
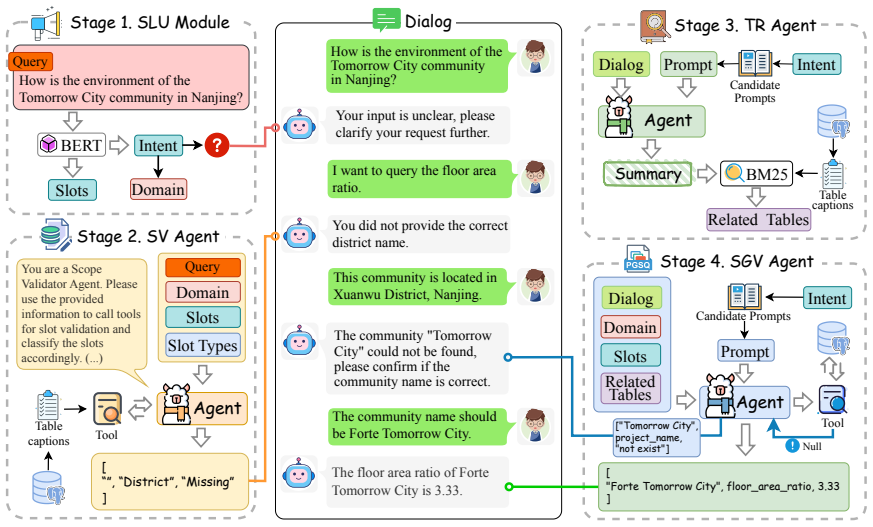
The paper establishes the ODUTQA-MDC task for open-domain underspecified tabular question answering with multi-turn dialogue-based clarification. It creates a large-scale dataset with 209 tables and 25,105 QA pairs, introduces a fine-grained labeling scheme, and develops a dynamic clarification interface. Additionally, it proposes the MAIC-TQA multi-agent framework that excels at detecting ambiguities, clarifying them through dialogue, and refining answers, with experiments validating the benchmark and framework.
What carries the argument
The MAIC-TQA multi-agent framework, which detects ambiguities in tabular queries, engages in multi-turn dialogue for clarification, and refines answers based on user feedback simulated by the dynamic interface.
If this is right
- The benchmark supports detailed evaluation of ambiguity types in tabular data using the fine-grained labeling scheme.
- MAIC-TQA shows that multi-agent coordination improves detection and resolution of uncertain expressions in table queries.
- The dynamic clarification interface enables controlled testing of interactive refinement loops.
- Together these elements provide a foundation for developing more robust conversational tabular QA systems.
Where Pith is reading between the lines
- The multi-agent clarification pattern could transfer to other structured-data tasks such as spreadsheet analysis or database querying.
- The labeling scheme offers a way to generate training signals for models that learn to ask targeted follow-up questions.
- Real deployment would still need direct user studies to confirm that simulated feedback matches actual human responses.
Load-bearing premise
The constructed ODUTQA dataset and fine-grained labeling scheme faithfully represent real-world underspecified open-domain tabular queries, and the dynamic clarification interface provides a realistic simulation of user feedback.
What would settle it
An experiment in which human users give substantially different clarifications than the dynamic interface simulates for the same underspecified questions would show that the benchmark does not capture realistic interaction.
Figures









read the original abstract
The advancement of large language models (LLMs) has enhanced tabular question answering (Tabular QA), yet they struggle with open-domain queries exhibiting underspecified or uncertain expressions. To address this, we introduce the ODUTQA-MDC task and the first comprehensive benchmark to tackle it. This benchmark includes: (1) a large-scale ODUTQA dataset with 209 tables and 25,105 QA pairs; (2) a fine-grained labeling scheme for detailed evaluation; and (3) a dynamic clarification interface that simulates user feedback for interactive assessment. We also propose MAIC-TQA, a multi-agent framework that excels at detecting ambiguities, clarifying them through dialogue, and refining answers. Experiments validate our benchmark and framework, establishing them as a key resource for advancing conversational, underspecification-aware Tabular QA research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ODUTQA-MDC task to address open-domain tabular QA challenges with underspecified or uncertain queries. It contributes a benchmark comprising a dataset of 209 tables and 25,105 QA pairs, a fine-grained labeling scheme for evaluation, and a dynamic clarification interface simulating user feedback. The authors also propose the MAIC-TQA multi-agent framework for ambiguity detection, multi-turn clarification, and answer refinement, claiming that experiments validate both the benchmark and framework.
Significance. If the empirical claims hold, this provides a timely new resource for conversational tabular QA research, targeting a clear gap where current LLMs fail on underspecified inputs. The scale of the dataset, the interactive evaluation setup, and the multi-agent clarification approach could become a standard testbed for future work on ambiguity handling in structured-data QA.
major comments (1)
- Abstract: the statement that 'Experiments validate our benchmark and framework' is unsupported by any reported metrics, baselines, or error analysis. Without these quantitative details it is impossible to assess whether MAIC-TQA actually excels at ambiguity detection and answer refinement, which is load-bearing for the central claim that the framework advances the state of the art.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: Abstract: the statement that 'Experiments validate our benchmark and framework' is unsupported by any reported metrics, baselines, or error analysis. Without these quantitative details it is impossible to assess whether MAIC-TQA actually excels at ambiguity detection and answer refinement, which is load-bearing for the central claim that the framework advances the state of the art.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports detailed experiments (including baselines, accuracy/F1 metrics for ambiguity detection, clarification success rates, and answer refinement improvements) in the Experiments section with error analysis. To make the abstract self-contained and directly support the validation claim, we will revise it to summarize the main empirical findings (e.g., MAIC-TQA's gains over single-agent baselines). revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a new task (ODUTQA-MDC), constructs a dataset (209 tables, 25,105 QA pairs), a fine-grained labeling scheme, a dynamic clarification interface, and proposes the MAIC-TQA multi-agent framework. These are definitional and constructive contributions with no load-bearing derivations, equations, or predictions that reduce by construction to prior self-citations, fitted inputs, or self-defined terms. The central claims rest on the novelty of the benchmark and framework rather than any internal chain that loops back to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can be improved for underspecified tabular QA by using multi-agent dialogue systems.
invented entities (1)
-
ODUTQA-MDC task
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 150–160
Improving generalization in language model- based text-to-sql semantic parsing: Two simple se- mantic boundary-based techniques. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 150–160. Association for Computational Linguistics. Tonghui Re...
2023
-
[2]
Kimi K2: Open Agentic Intelligence
ACM / Morgan & Claypool. Kimi Team, Yifan Bai, Yiping Bao, and et al. 2025. Kimi k2: Open agentic intelligence.Preprint, arXiv:2507.20534. Zhensheng Wang, Wenmian Yang, Kun Zhou, Yiquan Zhang, and Weijia Jia. 2025. RETQA: A large-scale open-domain tabular question answering dataset for real estate sector. InAAAI-25, Sponsored by the Asso- ciation for the ...
work page internal anchor Pith review arXiv 2025
-
[3]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103. A Dataset Construction and Statistics A.1 Template Filling A.1.1 Implementation Details Based on 209 tables, we design 222 seed templates. As shown in Figure 3, these templates are catego- rized by underspecification type: 38 with SELECT unders...
work page internal anchor Pith review arXiv 2023
-
[4]
Shanghai
Slot Tags (BIO Annotation):We employ the BIO (Begin-Inside-Outside) tagging scheme to identify specific entities that act as filtering constraints in the SQL query. In the visual example, the tokens “Shanghai”, “July”, and “2022” are explicitly tagged asB-C (City), B-M (Month), and B-Y (Year), respectively. Among them, “Shanghai” serves as the table scope...
2022
-
[5]
forbidden key- words
Intent Labels:Intents capture the semantic goal of the query, determining which columns and operations (such as sorting or aggregation) are required. The example demonstrates a composite intentscenario where the user asks for both volume ranking and price comparison. Consequently, the utterance is labeled with two intents. Role in TQA.In the Table Questio...
2022
-
[6]
The correct city is [Bei- jing]
Data Retrieval and Template Construc- tion. When the system correctly detects an un- derspecification (e.g., a missing city in the scope), the interface looks up the ground-truth value from the dataset’s clarification dictionary (e.g., FROM_clarification). It then constructs a standard response sentence, such as “The correct city is [Bei- jing].”
-
[7]
In the dynamic scenario, to simulate the diverse and unpredictable nature of real human language, we employ a LLM (Qwen2.5-72B) to rewrite the standard response
Dynamic Response Generation (LLM-based Rewriting). In the dynamic scenario, to simulate the diverse and unpredictable nature of real human language, we employ a LLM (Qwen2.5-72B) to rewrite the standard response. We utilize a spe- cialized prompt (see Figure 7) that instructs the LLM to act as a grammar expert, making the sen- tence more colloquial and us...
-
[8]
real” envi- ronment would make it mathematically impossible to fairly compare different models or track progress over time, as the “test set
Reliability Control Mechanism. A critical challenge in automatic generation is ensuring fac- tual consistency. We address this by strict keyword extraction and validation: • Keyword Extraction: Before generation, the system identifies the critical information slot (e.g., "Beijing") that must be present in the response. • Iterative Validation: The generati...
-
[9]
Unknown domain
The Table Retrieval Agent then uses the prompt shown in Figure 9 to summarize the target table. Finally, the SQL Generation and Validation Agent utilizes the prompt in Figure 10 to generate and validate SQL queries, and utilizes the tool defined by Algorithm 2 to execute SQL statements. Algorithm 1The slotSearchTool used by the SV agent Require:slots: str...
-
[10]
<Keywords> are the city name, district name, year, month, or time range
<Keywords> listed must not be altered and must appear in the <Rewritten_query>. <Keywords> are the city name, district name, year, month, or time range
-
[11]
You can only use approximate phrasing
<Forbidden_keywords> listed must not appear in the rewritten query. You can only use approximate phrasing. The intent of the <Rewritten_query> is to phrase a vague question regarding the <Forbidden_keywords>
-
[12]
Rewriting methods include, but are not limited to, inversion and synonym replacement
You only need to rewrite the question, not answer it. Rewriting methods include, but are not limited to, inversion and synonym replacement
-
[13]
<Forbidden_keywords>: 'None'
"<Forbidden_keywords>: 'None'" indicates there are no forbidden words
-
[14]
type:slot
You can be creative and increase sentence diversity while ensuring the meaning remains unchanged, <Keywords> are preserved, and <Forbidden_keywords> do not appear. ############Example 1############## <Query>:Which environment is better when comparing Yuyue Guangnian and Nanan Chaoming in Yuhuatai District, Nanjing City? <Keywords>:['Yuyue Guangnian', 'Nan...
-
[15]
Extract Target Slots: Filter all slots in <Slots> that match the <Target Slot Types>
-
[16]
- Combined-slot Verification: Combine target slots (e.g., city + district) according to their order of appearance in <Query>, then perform combined verification
Invoke Tool for Verification: - Single-slot Verification: Search each target slot individually and record the results. - Combined-slot Verification: Combine target slots (e.g., city + district) according to their order of appearance in <Query>, then perform combined verification. ============Step 2: Slot Classification (Apply rules in priority order) ====...
-
[17]
'Missing': - If a target slot type does not appear at all in <Slots>, classify it as ['', slot_type, 'Missing']
-
[18]
- Important: Once classified as 'Unmatch', these slots cannot be reclassified as 'Error' or 'Correct'
'Unmatch' (Combination Mismatch): - All individual slot checks return values > 0 (i.e., all exist individually); - But the combination slot query returns 0; - Then both slots in the combination are classified as [slot, slot_type, 'Unmatch']. - Important: Once classified as 'Unmatch', these slots cannot be reclassified as 'Error' or 'Correct'
-
[19]
'Error' (Retrieval Failed): - If a slot is present in '<Slots>' but its single-slot verification result is 0, classify it as [slot, slot_type, 'Error']
-
[20]
Please provide the building density of Dongping Town in Shanghai and Yuntai Yuanzhu in Jianye District, Nanjing
'Correct' (Fully Matched): - All target slot types are present; - All individual slot queries return values > 0; - Combined slot query also returns > 0; - Then each involved slot is classified as [slot, slot_type, 'Correct']. ############ [Example] ########## <Query>: "Please provide the building density of Dongping Town in Shanghai and Yuntai Yuanzhu in ...
-
[21]
system" represents the system's follow-up questions based on the user's original input, and
In the <Dialog>, "system" represents the system's follow-up questions based on the user's original input, and "user" represents the user's supplementary information in response to errors or omissions
-
[22]
The user’s original query may contain mistakes — you should make judgments based on the user’s supplemental input
-
[23]
Table of Property Transaction Prices in Haidian District, Beijing
The <Summary> should be a list consisting of a geographic region + table name, such as "Table of Property Transaction Prices in Haidian District, Beijing"; ############ Example 1 ############## <Dialog>: User: Could you tell me how many property units were sold in November 2020 in Park No.1 in Daxing District, Beijing, and Jing'an No.1 in Shanghai? System...
2020
-
[24]
Analyze the content of the <Dialog> to identify the user's query intent
-
[25]
Important: Always prioritize the corrected information provided by the user over the erroneous information in the original query
-
[26]
Generate an SQL query using the provided <SLOTS> and <Table_Captions>
-
[27]
Enterprise Name
Strictly follow the format shown in the examples below. ############ Example 1 ############## <Dialog>: User: What is the operating profit of Lishui Economic Development Group? System: Your input is missing the year. Please provide a year between 2019 and 2022. User: I'm interested in the year 2021. <Domain>: enterpriseFinanceField <SLOTS>: {'Lishui Econo...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.