Recognition: unknown
Multimodal Dataset Normalization and Perceptual Validation for Music-Taste Correspondences
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Synthetic flavor labels on a large music corpus preserve cross-modal structure and align with human listener ratings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The quantitative transfer analysis shows that correlations between audio features and flavor profiles, along with feature-importance rankings and latent-factor structures, remain consistent when moving from the human-annotated soundtrack set to the synthetic FMA labels. The listener study further demonstrates that the computational flavor targets, derived from a food-chemistry pipeline, align with participant ratings at statistically significant levels according to permutation testing, Mantel correlation, and Procrustes analysis. These converging results indicate that sonic seasoning effects are detectable within the synthetic annotations.
What carries the argument
Transfer testing of cross-modal correlations combined with perceptual alignment metrics applied to synthetic flavor labels produced by a food-chemistry pipeline.
If this is right
- Large existing music libraries can be used for scaled music-flavor studies once normalized with the synthetic labeling method.
- Cross-modal AI models can be trained on the released normalized datasets without requiring new human annotation campaigns.
- Reproducible pipelines for creating aligned multimodal corpora become available for other sensory correspondence questions.
- Validation metrics such as Mantel correlation and Procrustes distance can serve as benchmarks for future synthetic labeling approaches.
Where Pith is reading between the lines
- The same normalization and validation steps could be adapted to test correspondences between music and other sensory domains such as color or aroma.
- Refining the food-chemistry pipeline to reduce possible label biases might increase the strength of observed alignments in subsequent studies.
- Music recommendation systems could incorporate taste-profile predictions derived from these synthetic annotations to suggest tracks for specific dining contexts.
Load-bearing premise
The synthetic flavor labels produced by the food chemistry pipeline accurately capture perceptual targets without systematic biases that would artificially strengthen the transfer or alignment results.
What would settle it
A new listener experiment on a fresh set of tracks that yields non-significant alignment between the computational flavor targets and human ratings, or that shows substantially weaker transfer metrics than those reported.
Figures


read the original abstract
Collecting large, aligned cross-modal datasets for music-flavor research is difficult because perceptual experiments are costly and small by design. We address this bottleneck through two complementary experiments. The first tests whether audio-flavor correlations, feature-importance rankings, and latent-factor structure transfer from an experimental soundtracks collection (257~tracks with human annotations) to a large FMA-derived corpus ($\sim$49,300 segments with synthetic labels). The second validates computational flavor targets -- derived from food chemistry via a reproducible pipeline -- against human perception in an online listener study (49~participants, 20~tracks). Results from both experiments converge: the quantitative transfer analysis confirms that cross-modal structure is preserved across supervision regimes, and the perceptual evaluation shows significant alignment between computational targets and listener ratings (permutation $p<0.0001$, Mantel $r=0.45$, Procrustes $m^2=0.51$). Together, these findings support the conclusion that sonic seasoning effects are present in synthetic FMA annotations. We release datasets and companion code to support reproducible cross-modal AI research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the difficulty of collecting large aligned cross-modal datasets for music-flavor research by conducting two experiments. The first examines whether audio-flavor correlations, feature-importance rankings, and latent-factor structure transfer from a 257-track human-annotated soundtrack collection to a ~49,300-segment FMA corpus with synthetic labels generated via a food-chemistry pipeline. The second validates the computational flavor targets against human perception through an online study with 49 listeners rating 20 tracks. Results show significant alignment (permutation p<0.0001, Mantel r=0.45, Procrustes m^2=0.51) and preserved cross-modal structure, supporting the conclusion that sonic seasoning effects are present in the synthetic FMA annotations. Datasets and code are released for reproducibility.
Significance. If the results hold, the work offers a practical route to scale music-taste correspondence research beyond the typical small size of perceptual experiments. The dual approach—quantitative transfer analysis plus direct perceptual validation—provides convergent evidence that strengthens confidence in the synthetic labels. Explicit release of data and code is a clear asset for the field, enabling independent checks and extensions in multimodal audio research.
major comments (2)
- [Transfer analysis] The transfer analysis section does not provide sufficient detail on the audio feature normalization procedure or the exact mapping steps in the food-chemistry pipeline used to create synthetic labels. These choices are load-bearing for the claim that cross-modal structure is preserved, because different normalization or mapping decisions could alter the reported feature rankings and latent-factor alignments.
- [Perceptual validation] In the perceptual validation experiment, the manuscript reports Mantel r=0.45 and Procrustes m^2=0.51 but does not specify how potential systematic biases in the synthetic labels (e.g., from the external pipeline) were isolated from listener confounds such as track selection or rating scale usage. This detail is needed to confirm that the reported alignment (p<0.0001) is not inflated by unaccounted factors.
minor comments (3)
- [Abstract] The abstract states the FMA corpus size as ~49,300 segments; the main text should use the exact count and clarify whether segments are non-overlapping.
- [Methods] Notation for the three alignment metrics (permutation test, Mantel, Procrustes) should be introduced consistently in the methods before results are presented.
- [Results] Figure captions for the transfer and validation results should explicitly state the number of tracks or listeners used in each panel.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify key methodological aspects of our work. We address each major point below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Transfer analysis] The transfer analysis section does not provide sufficient detail on the audio feature normalization procedure or the exact mapping steps in the food-chemistry pipeline used to create synthetic labels. These choices are load-bearing for the claim that cross-modal structure is preserved, because different normalization or mapping decisions could alter the reported feature rankings and latent-factor alignments.
Authors: We agree that additional detail on these procedures will enhance reproducibility and support the transfer claims. In the revised manuscript we will expand the Methods section with a complete description of the audio feature normalization (specifying the exact scaling method, parameters, and any per-feature or global transformations applied) and the precise mapping steps in the food-chemistry pipeline, including compound thresholds, weighting functions, and any transformations used to generate the synthetic flavor labels. These additions will be cross-referenced to the released code repository. revision: yes
-
Referee: [Perceptual validation] In the perceptual validation experiment, the manuscript reports Mantel r=0.45 and Procrustes m^2=0.51 but does not specify how potential systematic biases in the synthetic labels (e.g., from the external pipeline) were isolated from listener confounds such as track selection or rating scale usage. This detail is needed to confirm that the reported alignment (p<0.0001) is not inflated by unaccounted factors.
Authors: We acknowledge the need for explicit discussion of controls. Track selection used stratified random sampling from the FMA corpus to promote genre diversity and reduce selection bias; rating scales were standardized (1-7 Likert) with identical instructions across participants. Significance was assessed via permutation tests that shuffle the synthetic labels, establishing a null distribution independent of label biases. In revision we will add a dedicated paragraph describing these controls, discussing potential pipeline-induced biases, and noting how the convergent transfer-analysis results (preserved cross-modal structure) provide additional support. Raw listener ratings will also be released alongside the existing datasets. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain consists of two independent experiments whose outputs do not reduce to quantities defined by the paper's own equations or fitted parameters. The transfer analysis compares cross-modal structure (feature rankings, latent factors) between an external 257-track human-annotated collection and a large FMA corpus whose labels originate from a separate food-chemistry pipeline; the perceptual validation compares computational targets against fresh human listener ratings (49 participants) and reports alignment statistics that are computed directly from those independent ratings. No self-citation is invoked to establish uniqueness or to justify an ansatz, and no prediction is obtained by fitting a parameter to a subset and then re-using the same fitted value. The chain is therefore self-contained against external benchmarks and code release.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Audio feature extraction and normalization preserve cross-modal correlations between the small human-annotated set and the large synthetic corpus
- domain assumption The food chemistry pipeline produces targets that are comparable to human perceptual judgments
Reference graph
Works this paper leans on
-
[1]
INTRODUCTION Sonic seasoning studies how sound modulates flavor per- ception, and cross-modal AI offers a route to model these effects at scale [1, 2]. The literature documents robust audio–taste correspondences for pitch, timbre, and related musical attributes [3–6], explained by statistical, seman- tic, and affective mechanisms [1, 7]. Controlled studie...
2026
-
[2]
Multimodal Dataset Normalization and Perceptual Validation for Music-Taste Correspondences
RELATED WORK 2.1 Cross-Modal and Neuroscientific Background Prior work in multisensory perception shows systematic interactions between auditory cues and gustatory judg- ments, motivating computational sonic seasoning as a data- driven extension of cross-modal correspondences [1]. arXiv:2604.10632v1 [cs.SD] 12 Apr 2026 Classic and contemporary studies con...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
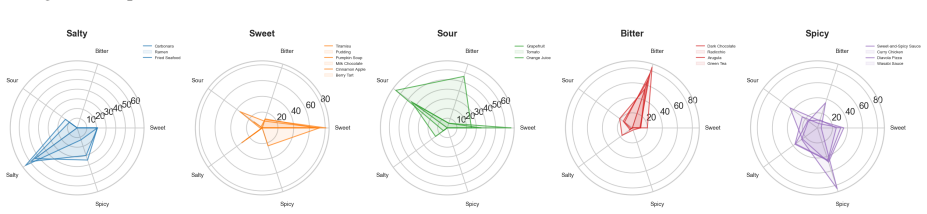
All com- ponents are mapped to a common five-dimensional taste space (sweet, bitter, sour, salty, spicy)
METHODOLOGY 3.1 Data Sources and Harmonization We jointly analyze: (i) an experimental soundtracks collec- tion (257 tracks) with human flavor annotations aggregated from 22 published studies, (ii) an FMA-extended chunk- level dataset (∼49,30030-second segments) with syn- thetic flavor annotations, and (iii) FoodDB-derived food chemistry resources [23] fo...
2048
-
[4]
Procrustes/PROTEST analysis for structural correspon- dence
-
[5]
Experiment 1operates on the experimental soundtracks collection (257 human-annotated tracks) and the FMA- extended corpus (∼49,300chunks from 5,878 tracks with synthetic labels)
EXPERIMENTAL SETUP The two experiments share the five-dimensional taste space (sweet, bitter, sour, salty, spicy) and a common set of ex- tracted audio features. Experiment 1operates on the experimental soundtracks collection (257 human-annotated tracks) and the FMA- extended corpus (∼49,300chunks from 5,878 tracks with synthetic labels). Statistical test...
-
[6]
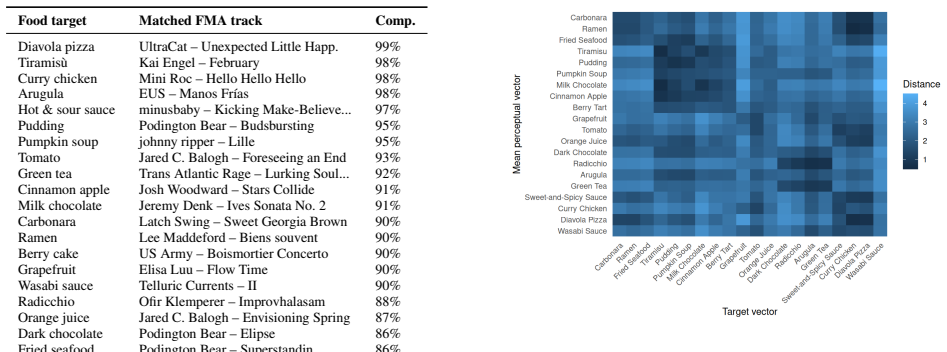
RESULTS 5.1 Experiment 1: Cross-Modal Transfer 5.1.1 Audio–Flavor Transfer The transfer analysis indicates preserved cross-modal trends between corpora. Sign agreement across the top five pairwise feature–flavor associations is high (22/25), meaning that the direction of audio–flavor relationships is largely consistent regardless of whether annotations co...
-
[7]
DISCUSSION The two experiments provide converging evidence that the sonic seasoning effect—systematic audio–flavor corre- spondences documented in controlled laboratory studies— is preserved in synthetic annotations of the FMA dataset. Experiment 1 shows that the correlation structure, feature-importance rankings, and latent-factor coupling observed in th...
-
[8]
CONCLUSIONS We presented two complementary experiments addressing whether sonic seasoning effects are preserved in synthetic annotations of a large music corpus. Experiment 1 demon- strates that audio–flavor correlations, feature-importance rankings, and latent-factor structure transfer significantly from the experimental soundtracks collection to the FMA...
-
[9]
Crossmodal correspondences: A tuto- rial review,
C. Spence, “Crossmodal correspondences: A tuto- rial review,”Attention, Perception, & Psychophysics, vol. 73, no. 4, pp. 971–995, 2011
2011
-
[10]
Listening to sustainable bites: Assessing the influence of sound on sustainable food perceptions and behaviors using a data-driven ap- proach,
B. M. Rodr ´ıguez Rivera, “Listening to sustainable bites: Assessing the influence of sound on sustainable food perceptions and behaviors using a data-driven ap- proach,” PhD thesis, Universidad de los Andes, Bogot´a - Colombia, June 2025
2025
-
[11]
Implicit association be- tween basic tastes and pitch,
A.-S. Crisinel and C. Spence, “Implicit association be- tween basic tastes and pitch,”Neuroscience letters, vol. 464, no. 1, pp. 39–42, 2009
2009
-
[12]
As bitter as a trombone: Synesthetic corre- spondences in nonsynesthetes between tastes/flavors and musical notes,
——, “As bitter as a trombone: Synesthetic corre- spondences in nonsynesthetes between tastes/flavors and musical notes,”Attention, Perception, & Psy- chophysics, vol. 72, no. 7, pp. 1994–2002, 2010
1994
-
[13]
A sweet sound? food names reveal im- plicit associations between taste and pitch,
——, “A sweet sound? food names reveal im- plicit associations between taste and pitch,”Perception, vol. 39, no. 3, pp. 417–425, 2010
2010
-
[14]
That sounds sweet: Using cross-modal correspon- dences to communicate gustatory attributes,
K. M. Knoeferle, A. Woods, F. K¨appler, and C. Spence, “That sounds sweet: Using cross-modal correspon- dences to communicate gustatory attributes,”Psychol- ogy & Marketing, vol. 32, no. 1, pp. 107–120, 2015
2015
-
[15]
Reflections on cross-modal correspondences: Current understand- ing and issues for future research,
K. Motoki, L. E. Marks, and C. Velasco, “Reflections on cross-modal correspondences: Current understand- ing and issues for future research,”Multisensory Re- search, vol. 37, no. 1, pp. 1–23, 2023
2023
-
[16]
Effects of the sound of the bite on apple perceived crispness and hardness,
M. L. Dematt `e, N. Pojer, I. Endrizzi, M. L. Corol- laro, E. Betta, E. Aprea, M. Charles, F. Biasioli, M. Zampini, and F. Gasperi, “Effects of the sound of the bite on apple perceived crispness and hardness,” F ood Quality and Preference, vol. 38, pp. 58–64, 2014
2014
-
[17]
The sound of silence: Presence and absence of sound affects meal duration and hedo- nic eating experience,
S. L. Mathiesen, A. Hopia, P. Ojansivu, D. V . Byrne, and Q. J. Wang, “The sound of silence: Presence and absence of sound affects meal duration and hedo- nic eating experience,”Appetite, vol. 174, p. 106011, 2022
2022
-
[18]
Impact of music on the dy- namic perception of coffee and evoked emotions eval- uated by temporal dominance of sensations (tds) and emotions (tde),
M. V . Galmarini, R. S. Paz, D. E. Choquehuanca, M. C. Zamora, and B. Mesz, “Impact of music on the dy- namic perception of coffee and evoked emotions eval- uated by temporal dominance of sensations (tds) and emotions (tde),”F ood Research International, vol. 150, p. 110795, 2021
2021
-
[19]
Fma: A dataset for music analysis,
M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “FMA: A dataset for music analysis,” in 18th International Society for Music Information Re- trieval Conference (ISMIR), 2017. [Online]. Available: https://arxiv.org/abs/1612.01840
-
[20]
Gestalt psychology,
W. K ¨ohler, “Gestalt psychology,”Psychologische forschung, vol. 31, no. 1, pp. XVIII–XXX, 1967
1967
-
[21]
A multimodal symphony: integrating taste and sound through generative ai,
M. Spanio, M. Zampini, A. Rod `a, and F. Pierucci, “A multimodal symphony: integrating taste and sound through generative ai,”Frontiers in Computer Science, vol. V olume 7 - 2025, 2025. [Online]. Available: https: //www.frontiersin.org/journals/computer-science/ articles/10.3389/fcomp.2025.1575741
-
[22]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inInternational conference on machine learning. Pmlr, 2021, pp. 8821–8831
2021
-
[23]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchiet al., “Musiclm: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
A re- view of affective computing: From unimodal analysis to multimodal fusion,
S. Poria, E. Cambria, R. Bajpai, and A. Hussain, “A re- view of affective computing: From unimodal analysis to multimodal fusion,”Information fusion, vol. 37, pp. 98–125, 2017
2017
-
[25]
Emotion-based end-to-end matching be- tween image and music in valence-arousal space,
S. Zhao, Y . Li, X. Yao, W. Nie, P. Xu, J. Yang, and K. Keutzer, “Emotion-based end-to-end matching be- tween image and music in valence-arousal space,” in Proceedings of the 28th ACM international conference on multimedia, 2020, pp. 2945–2954
2020
-
[26]
Towards emotionally aware ai: Chal- lenges and opportunities in the evolution of multimodal generative models,
M. Spanioet al., “Towards emotionally aware ai: Chal- lenges and opportunities in the evolution of multimodal generative models,”Proceedings of the AIxIA Doctoral Consortium, vol. 2024, 2024
2024
-
[27]
Key clarity is blue, relaxed, and maluma: Machine learning used to discover cross-modal connections between sensory items and the music they spontaneously evoke,
M. Murari, A. Chmiel, E. Tiepolo, J. D. Zhang, S. Canazza, A. Rod `a, and E. Schubert, “Key clarity is blue, relaxed, and maluma: Machine learning used to discover cross-modal connections between sensory items and the music they spontaneously evoke,” inIn- ternational Conference on Kansei Engineering & Emo- tion Research. Springer, 2020, pp. 214–223
2020
-
[28]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,
J. Johnson, B. Hariharan, L. van der Maaten, J. Hoff- man, L. Fei-Fei, C. L. Zitnick, and R. Girshick, “Clevr: A diagnostic dataset for compositional language and elementary visual reasoning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2901–2910
2017
-
[29]
Gqa: A new dataset for real-world visual reasoning and composi- tional question answering,
D. A. Hudson and C. D. Manning, “Gqa: A new dataset for real-world visual reasoning and composi- tional question answering,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2019, pp. 6700–6709
2019
-
[30]
Smmqg: A large-scale dataset for mul- timodal question generation,
H. Wu, Y . He, Y . Hong, Y . Liu, L. Fu, J. Yin, L. Tang, and X. Wang, “Smmqg: A large-scale dataset for mul- timodal question generation,” inFindings of the Asso- ciation for Computational Linguistics: EMNLP 2024, 2024, pp. 12 960–12 993
2024
-
[31]
FooDB: The food database,
FooDB, “FooDB: The food database,” 2024, version 1.0. [Online]. Available: https://foodb.ca/
2024
-
[32]
AST: Audio Spectrogram Transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “AST: Audio Spectrogram Transformer,” inInterspeech 2021, 2021, pp. 571–575
2021
-
[33]
librosa: Audio and music signal analysis in python,
B. McFee, C. Raffel, D. Liang, D. P. Ellis, M. McVicar, E. Battenberg, and O. Nieto, “librosa: Audio and music signal analysis in python,”SciPy 2015, 2015. [Online]. Available: https://doi.org/10. 25080/Majora-7b98e3ed-003
2015
-
[34]
A chemical language model for molecular taste prediction,
Y . Zimmermann, L. Sieben, H. Seng, P. Pestlin, and F. G¨orlich, “A chemical language model for molecular taste prediction,” 12 2024. [Online]. Available: http://dx.doi.org/10.26434/chemrxiv-2024-d6n15-v2
-
[35]
Psytoolkit: A novel web-based method for running online questionnaires and reaction-time exper- iments,
G. Stoet, “Psytoolkit: A novel web-based method for running online questionnaires and reaction-time exper- iments,”Teaching of Psychology, vol. 44, no. 1, pp. 24–31, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.