Recognition: unknown
Deep-Reporter: Deep Research for Grounded Multimodal Long-Form Generation
Pith reviewed 2026-05-10 15:39 UTC · model grok-4.3
The pith
Deep-Reporter orchestrates agentic multimodal search, checklist-guided synthesis, and recurrent context management to enable grounded long-form multimodal generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recent agentic search frameworks enable deep research via iterative planning and retrieval, reducing hallucinations and enhancing factual grounding. However, they remain text-centric, overlooking the multimodal evidence that characterizes real-world expert reports. We introduce a pressing task: multimodal long-form generation. Accordingly, we propose Deep-Reporter, a unified agentic framework for grounded multimodal long-form generation. It orchestrates: (i) Agentic Multimodal Search and Filtering to retrieve and filter textual passages and information-dense visuals; (ii) Checklist-Guided Incremental Synthesis to ensure coherent image-text integration and optimal citation placement; and (iii
What carries the argument
Deep-Reporter, the unified agentic framework that orchestrates agentic multimodal search and filtering, checklist-guided incremental synthesis, and recurrent context management.
If this is right
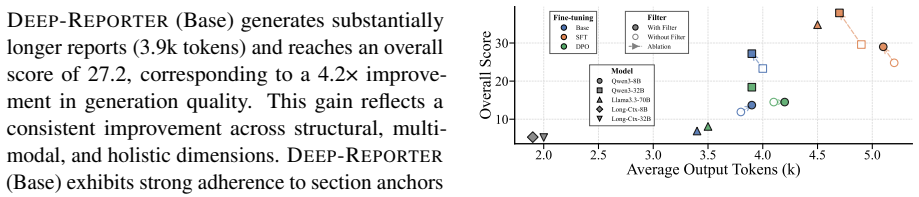
- Post-training on the curated 8K agentic traces narrows the performance gap in multimodal long-form generation.
- Multimodal selection and integration remain the hardest parts of the task even after applying the framework.
- Checklist-guided incremental synthesis produces coherent image-text integration and places citations at optimal points.
- Recurrent context management maintains long-range coherence while preserving local fluency.
- M2LongBench provides a stable sandbox for evaluating 247 tasks across nine domains.
Where Pith is reading between the lines
- The same orchestration pattern could be tested on generating educational materials or technical documentation that mix text with diagrams.
- Recurrent context management might allow the framework to scale to documents longer than those in the current benchmark.
- Effective agent orchestration for multimodal grounding could transfer to reducing hallucinations in other agentic systems that retrieve and combine evidence.
- Evaluating the framework on open-ended user queries outside the sandbox would reveal whether the curated traces capture real-world variability.
Load-bearing premise
The three components can be orchestrated without introducing new hallucinations, incoherence, or poor visual selection, and the 8K traces plus M2LongBench are representative enough to show general effectiveness.
What would settle it
Running the framework on research tasks drawn from domains or modalities outside the nine covered in M2LongBench and checking whether new hallucinations, broken image-text alignment, or citation errors appear would directly test whether the orchestration generalizes.
Figures




read the original abstract
Recent agentic search frameworks enable deep research via iterative planning and retrieval, reducing hallucinations and enhancing factual grounding. However, they remain text-centric, overlooking the multimodal evidence that characterizes real-world expert reports. We introduce a pressing task: multimodal long-form generation. Accordingly, we propose Deep-Reporter, a unified agentic framework for grounded multimodal long-form generation. It orchestrates: (i) Agentic Multimodal Search and Filtering to retrieve and filter textual passages and information-dense visuals; (ii) Checklist-Guided Incremental Synthesis to ensure coherent image-text integration and optimal citation placement; and (iii) Recurrent Context Management to balance long-range coherence with local fluency. We develop a rigorous curation pipeline producing 8K high-quality agentic traces for model optimization. We further introduce M2LongBench, a comprehensive testbed comprising 247 research tasks across 9 domains and a stable multimodal sandbox. Extensive experiments demonstrate that long-form multimodal generation is a challenging task, especially in multimodal selection and integration, and effective post-training can bridge the gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of multimodal long-form generation and proposes Deep-Reporter, a unified agentic framework that orchestrates Agentic Multimodal Search and Filtering for retrieving textual passages and visuals, Checklist-Guided Incremental Synthesis for coherent image-text integration and citation placement, and Recurrent Context Management for balancing coherence and fluency. It describes a curation pipeline yielding 8K high-quality agentic traces for optimization, introduces M2LongBench as a benchmark with 247 tasks across 9 domains and a multimodal sandbox, and reports experiments indicating the task is challenging (especially multimodal selection/integration) but improvable via post-training.
Significance. If the experimental claims hold with proper validation, the work is significant for extending text-centric agentic frameworks to multimodal settings. The curation of 8K traces and introduction of M2LongBench with its stable sandbox represent concrete contributions that could support reproducible research and standardized evaluation in grounded multimodal generation. These elements address a clear gap in prior work and provide falsifiable testbeds for future agentic systems.
major comments (2)
- [Abstract and §6] Abstract and §6 (Experiments): The central claim that 'extensive experiments demonstrate that long-form multimodal generation is a challenging task, especially in multimodal selection and integration, and effective post-training can bridge the gap' is load-bearing, yet the abstract provides no quantitative metrics, baselines, error analysis, or specific results (e.g., no reported scores on M2LongBench for selection accuracy or coherence). This makes it impossible to assess the magnitude of the challenge or the improvement from post-training without the full experimental details.
- [§3] §3 (Framework): The assumption that the three components can be orchestrated without introducing new hallucinations or poor visual selection is central to the framework's validity, but the high-level description lacks concrete mechanisms (e.g., no pseudocode, interaction protocols, or filtering criteria) for how Recurrent Context Management interacts with Checklist-Guided Incremental Synthesis to maintain grounding across long outputs.
minor comments (3)
- [Abstract and §5] The abstract refers to a 'stable multimodal sandbox' without defining its scope, implementation, or how it ensures stability across the 9 domains; this should be clarified in §5 (Benchmark) for reproducibility.
- [§3] Notation for the three framework components is introduced without consistent acronyms or diagrams; a figure summarizing the orchestration pipeline would improve clarity.
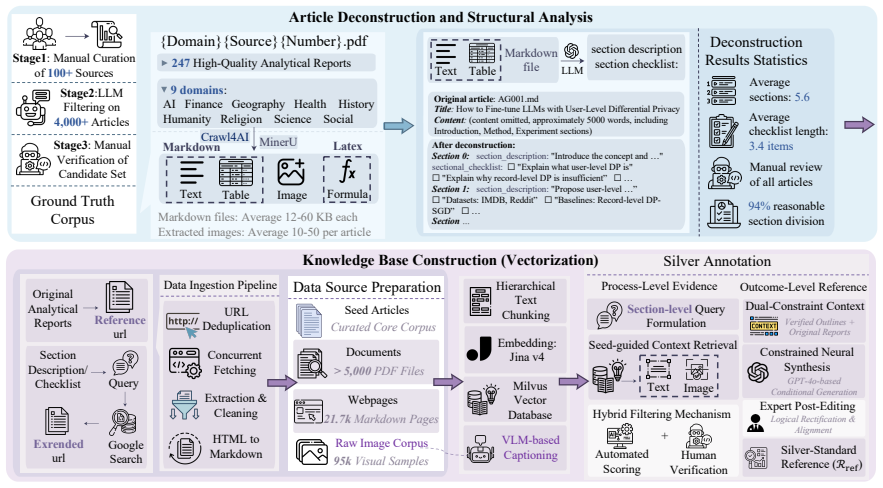
- [§4] The curation pipeline for the 8K traces is mentioned but lacks details on quality control metrics or inter-annotator agreement; these should be added to §4 to strengthen the data contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §6] Abstract and §6 (Experiments): The central claim that 'extensive experiments demonstrate that long-form multimodal generation is a challenging task, especially in multimodal selection and integration, and effective post-training can bridge the gap' is load-bearing, yet the abstract provides no quantitative metrics, baselines, error analysis, or specific results (e.g., no reported scores on M2LongBench for selection accuracy or coherence). This makes it impossible to assess the magnitude of the challenge or the improvement from post-training without the full experimental details.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights to allow readers to immediately gauge the scale of the challenge and the gains from post-training. In the revised manuscript, we will update the abstract to report specific M2LongBench results, including baseline scores for multimodal selection accuracy and coherence as well as the improvements achieved via post-training. The full experimental details, baselines, and error analysis will continue to be presented in §6. revision: yes
-
Referee: [§3] §3 (Framework): The assumption that the three components can be orchestrated without introducing new hallucinations or poor visual selection is central to the framework's validity, but the high-level description lacks concrete mechanisms (e.g., no pseudocode, interaction protocols, or filtering criteria) for how Recurrent Context Management interacts with Checklist-Guided Incremental Synthesis to maintain grounding across long outputs.
Authors: We thank the referee for highlighting the need for greater specificity in the orchestration details. While §3 outlines the roles and high-level interactions of Agentic Multimodal Search and Filtering, Checklist-Guided Incremental Synthesis, and Recurrent Context Management, we acknowledge that explicit mechanisms would improve clarity and verifiability. In the revision, we will add pseudocode for the overall agentic loop and provide concrete interaction protocols, including the filtering criteria and context-update rules that Recurrent Context Management applies to Checklist-Guided Incremental Synthesis to preserve grounding and mitigate hallucinations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new agentic framework (Deep-Reporter) with three explicitly defined components for multimodal long-form generation, a curation pipeline yielding 8K traces, and a new benchmark (M2LongBench). Claims rest on motivation from gaps in prior text-centric agentic search work plus experimental results on the introduced benchmark and traces. No equations or definitions reduce claims to inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing steps rely on self-citation chains or imported uniqueness theorems. The central proposal is self-contained as a constructive framework plus empirical evaluation on newly created resources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Text-centric agentic search frameworks can be extended to multimodal retrieval and filtering without fundamental architectural changes
invented entities (4)
-
Agentic Multimodal Search and Filtering
no independent evidence
-
Checklist-Guided Incremental Synthesis
no independent evidence
-
Recurrent Context Management
no independent evidence
-
M2LongBench
no independent evidence
Forward citations
Cited by 1 Pith paper
-
ViDR: Grounding Multimodal Deep Research Reports in Source Visual Evidence
ViDR treats source figures as retrievable and verifiable evidence objects in multimodal deep research reports and introduces MMR Bench+ to measure improvements in visual integration and verifiability.
Reference graph
Works this paper leans on
-
[1]
Evaluation of text generation: A survey.arXiv preprint arXiv:2006.14799. Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Sahel Shari- fymoghaddam, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. 2025. Browsecomp-plus...
-
[2]
Webwatcher: Breaking new frontier of vision-language deep research agent.arXiv preprint arXiv:2508.05748. Alireza Ghafarollahi and Markus J Buehler. 2025. Scia- gents: automating scientific discovery through bioin- spired multi-agent intelligent graph reasoning.Ad- vanced Materials, 37(22):2413523. Hongchao Gu, Dexun Li, Kuicai Dong, Hao Zhang, Hang Lv, H...
-
[3]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Visual hallucinations of multi-modal large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9614– 9631. Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv ...
work page internal anchor Pith review arXiv 2024
-
[4]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text.arXiv preprint arXiv:1606.05250. David Rein, Betty Li Hou, Asa Cooper Sticklan...
work page internal anchor Pith review arXiv 2016
-
[5]
MiroMind Team, S Bai, L Bing, L Lei, R Li, X Li, X Lin, E Min, L Su, B Wang, and 1 others
DeepDiver: Adaptive search intensity scaling via open-web reinforcement learning.arXiv preprint arXiv: 2505.24332. MiroMind Team, S Bai, L Bing, L Lei, R Li, X Li, X Lin, E Min, L Su, B Wang, and 1 others
-
[6]
MiroThinker-1.7 & H1: Towards heavy-duty research agents via ver- ification
Mirothinker-1.7 & h1: Towards heavy-duty research agents via verification.arXiv preprint arXiv:2603.15726. Yong-En Tian, Yu-Chien Tang, Kuang-Da Wang, An-Zi Yen, and Wen-Chih Peng. 2025. Template-based fi- nancial report generation in agentic and decomposed information retrieval. InProceedings of the 48th In- ternational ACM SIGIR Conference on Research a...
-
[7]
Hey everyone,
**De-noise Content**: First, mentally filter out and ignore all non-essential elements: advertisements, self-promotion, conversational filler ("Hey everyone," "Thanks for reading"), website navigation elements, and any metadata. Focus only on the substantive content that advances the main argument or narrative
-
[8]
**Infer Core Intent**: Based on the core content, determine the central topic to formulate the`query`and identify the key promises or questions answered to create the` overall_checklist`
-
[9]
- Instead, read through the entire article and identify natural logical breaks where the discussion shifts to a substantially different aspect of the main topic
**Identify Natural Content Divisions**: - **CRITICAL**: Completely ignore markdown heading hierarchy (#, ##, ###) as it may be corrupted or inconsistent due to web scraping issues. - Instead, read through the entire article and identify natural logical breaks where the discussion shifts to a substantially different aspect of the main topic. - Look for tra...
-
[10]
- Consider combining related content that might appear under separate headings if they serve the same logical purpose
**Section Boundaries Guidelines**: - A new section should only begin when there's a clear shift in focus, not just a new paragraph or minor sub-point. - Consider combining related content that might appear under separate headings if they serve the same logical purpose. - Look for natural narrative flow: Introduction -> Main Arguments/Evidence -> Analysis ...
-
[11]
Key sub-topics include: 1. Topic A details, 2. Topic B details, 3. Topic C details
**Section Description and Sub-topics**: For each identified section: - Write a comprehensive`section_description`that captures the main thrust and purpose of that section. - Only include sub-topics if the section genuinely covers multiple distinct concepts that would benefit from enumeration. - Format sub-topics as: "Key sub-topics include: 1. Topic A det...
-
[12]
query":
**Checklist Allocation**: Distribute the`overall_checklist`items across sections based on where those concepts are actually discussed in the article, ensuring comprehensive coverage without redundancy. **Strict Output Specification** Your output MUST be a single, valid JSON object and nothing else. The JSON object must follow this exact structure: <output...
-
[13]
Write a comprehensive description that provides enough context for a writer to understand what needs to be written
**section_description**: A DETAILED description (2-4 sentences) that clearly explains: - What this section is about - What specific aspects will be covered - How it contributes to the overall article - What the reader should learn from this section **IMPORTANT**: DO NOT just write a title or short phrase. Write a comprehensive description that provides en...
-
[14]
outline": [ {
**sectional_checklist**: A list of 3-5 specific, actionable requirements for this section **Output Format (JSON):** ```json { "outline": [ { "section_description": "This section provides a comprehensive introduction to the transformer architecture...", "sectional_checklist": [ "Define what transformers are and their primary purpose in deep learning", "Exp...
-
[15]
**text_queries**: For finding related text passages, explanations, or documentation (3-5 queries)
-
[16]
text_queries
**image_queries**: For finding relevant diagrams, charts, figures, or visualizations (2-4 queries) **Output Format (JSON):** ```json {{ "text_queries": [ "query 1 for text retrieval", "query 2 for text retrieval", "query 3 for text retrieval" ], "image_queries": [ "query 1 for image retrieval", "query 2 for image retrieval" ] }} ``` Generate the queries n...
-
[17]
Recent studies show significant progress in AI safety[citation:txt3]
**Text Citation Format:** - When using information from a text source, cite it as:`[citation:txt1]`,`[citation:txt2]`, etc. - Example: "Recent studies show significant progress in AI safety[citation:txt3]."
-
[18]
The architecture is shown below:\n\nAs illustrated, the system
**Image Citation Format:** - When you want to insert an image/figure, use:``,``, etc. - Example: "The architecture is shown below:\n\nAs illustrated, the system ..." - ONLY use this format for sources explicitly marked as "Image"
-
[19]
**Citation Placement:** - Place text citations at the end of the sentence or claim - Place image citations on their own line where the visual should appear - You can cite the same source multiple times if needed
-
[20]
In conclusion
**Important Distinctions:** - Text sources -> use`[citation:txt1]`,`[citation:txt2]`, etc. - Image sources -> use``,``, etc. # Position-Aware Writing Instructions **Is this the FIRST section?** {is_first_section} **Is this the LAST section?** {is_last_section} ## If FIRST section (is_first_section = yes): - Start with a...
-
[21]
**Address all sectional requirements** in the checklist above
-
[22]
**Maintain coherence** with previous sections using the provided context
-
[23]
**Use retrieved materials** as the foundation of your content
-
[24]
**Cite sources properly** using the formats specified above
-
[25]
**Write naturally** - your content should flow smoothly while integrating citations
-
[26]
**Appropriate length** - typically 300-800 words depending on the complexity of requirements # Markdown Formatting Requirements **CRITICAL: You MUST use proper Markdown formatting for structure:**
-
[27]
**Section Title (Required):** - Start your content with a section title using`# Title` - The title should reflect the section description
-
[28]
**Subsections (If Needed):** - Use`## Subsection Title`for major subsections - Use`### Subsubsection Title`for deeper nesting - Use appropriate heading levels to create clear hierarchy
-
[29]
**Example Structure:** ```markdown # Introduction to Machine Learning Machine learning has revolutionized...[citation:txt1] ## Supervised Learning Supervised learning approaches...[citation:txt2] ### Classification Classification tasks involve...[citation:txt3] ## Unsupervised Learning Unlike supervised methods...[citation:txt5] ``` # Output Format Provid...
-
[30]
Does the image visually illustrate concepts mentioned in the requirements?
-
[31]
Is it a diagram, chart, figure, or visualization that adds value?
-
[32]
YES" if the image is relevant and should be kept -
Does it relate to the section topic? # Response Format Answer with ONLY ONE WORD: - "YES" if the image is relevant and should be kept - "NO" if the image is not relevant Your answer: Prompt Template: Text Filter You are an efficient information filtering assistant. # Task Determine which of the provided information sources are highly relevant to the curre...
-
[33]
Read each numbered source carefully (txt1, txt2, txt3, etc.)
-
[34]
Determine if it provides valuable information for the section requirements
-
[35]
In summary
Return the numbers of ALL useful sources # Output Format Return ONLY a list of numbers (comma-separated or Python list format): - Correct example 1: 1, 3, 5, 8 - Correct example 2: [1, 3, 5, 8] - If none are useful: [] Note: The sources are labeled as txt1, txt2, etc., but you should return just the numbers (1, 2, 3...). Your response: C Training Implemen...
2024
-
[36]
The judge examines the ac- tual rendered images alongside the section content to assess visual element quality, placement, and coherence
to evaluate multimodal grounding quality on the same 0–10 scale. The judge examines the ac- tual rendered images alongside the section content to assess visual element quality, placement, and coherence. Calculation 2: Relative Score Scaling.Raw scalar scores are inherently difficult to interpret across tasks of varying complexity. To calibrate these score...
-
[38]
Penalize superficial content heavily
**Be Harsh**: Default to a lower score if you are unsure. Penalize superficial content heavily. ## Article Overview **Query**: {query} **Overall Checklist**: {overall_checklist} **Number of Sections**: {num_sections} ## Evaluation Tasks ### Part 1: Section-Level Evaluation For each section, you will evaluate:
-
[39]
**Description Completion Score (0-10)**: How well does the generated content match the intended section description?
-
[40]
### Part 2: Article-Level Evaluation For the entire article, evaluate the following dimensions (each scored 0-10):
**Checklist Completion**: For each item in the sectional checklist, evaluate the quality of the coverage with a brief explanation. ### Part 2: Article-Level Evaluation For the entire article, evaluate the following dimensions (each scored 0-10):
-
[41]
**Coherence**: How well do the sections connect with each other? Are there smooth transitions? Is there a logical flow?
-
[42]
**Fluency**: Is the writing clear, natural, and easy to read? Are sentences well-constructed?
-
[43]
**Repetition**: Are there unnecessary repetitions across sections?
-
[44]
section_evaluations
**Termination**: Are there inappropriate concluding statements in non-conclusion sections? ( Lower score = more inappropriate conclusions) ## Sections Data {sections_data} ## Output Format Respond with a valid JSON object (no markdown code blocks, just raw JSON) with the structure: {{ "section_evaluations": [ {{ "section_index": 0, "description_completion...
-
[45]
- **8-10 points**: Excellent/outstanding performance
**Use a scale of 0-10 (continuous values)**: Do not cluster scores around 8-10. - **8-10 points**: Excellent/outstanding performance. Fully meets or exceeds requirements. - **6-8 points**: Good performance. Largely meets requirements with notable strengths. - **4-6 points**: Average performance. Basically meets requirements, neither good nor bad. - **2-4 ...
-
[46]
Penalize poor images heavily
**Be Harsh**: Score lower if unsure. Penalize poor images heavily
-
[47]
**Evaluate All Dimensions Independently**: Dimensions assess image usage quality
-
[48]
N/A", "None
**IMPORTANT - Always Return Numeric Scores**: Never use "N/A", "None", or text descriptions as scores. Always provide a numeric value (0-10) based on the evaluation criteria below. ## Section Context **Section Description**: {section_description} **Section Content (with image placeholders)**: {section_content} **Number of Images in Section**: {num_images}...
-
[49]
**System/Model Architecture**: Diagrams showing components and connections
-
[50]
**Algorithms/Methods**: Flowcharts or pseudocode visualizations
-
[51]
**Experimental Setup**: Photos or diagrams of equipment/environments
-
[52]
**Results/Data**: Charts, graphs, tables showing findings
-
[53]
**Processes/Workflows**: Step-by-step visual representations
-
[54]
**Comparisons**: Side-by-side visual comparisons
-
[55]
**Examples/Case Studies**: Concrete visual examples ## Content Types That May NOT Need Images
-
[56]
**Abstract Definitions**: Pure conceptual explanations
-
[57]
**Literature Review**: Discussion of related work (unless comparing approaches)
-
[58]
**Theoretical Background**: Mathematical proofs, theoretical foundations
-
[59]
**Introductory Text**: Background context, motivation
-
[60]
richness_score
**Conclusions**: Summary statements, future work discussions ## Output Format You MUST respond with ONLY a valid JSON object. Follow this EXACT structure: {{ "richness_score": <float between 0-10>, "richness_reasoning": "<your explanation here>", "coherence_score": <float between 0-10>, "coherence_reasoning": "<your explanation here>", "placement_score": ...
-
[61]
richness_score
**Score Fields Must Contain NUMBERS ONLY** (not text): - Replace`<float between 0-10>`with an actual number like 7.5 or 3.2 - CORRECT: "richness_score": 7.5 - CORRECT: "richness_score": 3.0 - WRONG: "richness_score": "This section lacks images" - WRONG: "richness_score": "N/A" - WRONG: "richness_score": "Since no images are present..." - WRONG: "richness_...
-
[62]
richness_reasoning
**Reasoning Fields Must Contain TEXT ONLY**: - Replace`<your explanation here>`with your actual explanation - CORRECT: "richness_reasoning": "Brief explanation of the score" - WRONG: Put explanations in the score field
-
[63]
E Additional Experimental Results E.1 Runtime Breakdown and Cost Analysis We provide a detailed runtime breakdown of DEEP- REPORTERto complement the main experimen- tal results
**For sections with NO images**: - Still provide NUMERIC scores (not text or "N/A") - Low score if images are needed - High score if images not needed - Put explanation in reasoning field Model Filter Train Total Query Search Filter Write Qwen3-8B✓Base 630 10.6 30.4 541.4 47.5 Qwen3-8B✗Base 170 18.1 75.1 - 77.2 Qwen3-8B✓SFT 636 12.1 31.6 530.3 61.5 Qwen3-...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.