Recognition: unknown
E2E-REME: Towards End-to-End Microservices Auto-Remediation via Experience-Simulation Reinforcement Fine-Tuning
Pith reviewed 2026-05-10 15:27 UTC · model grok-4.3
The pith
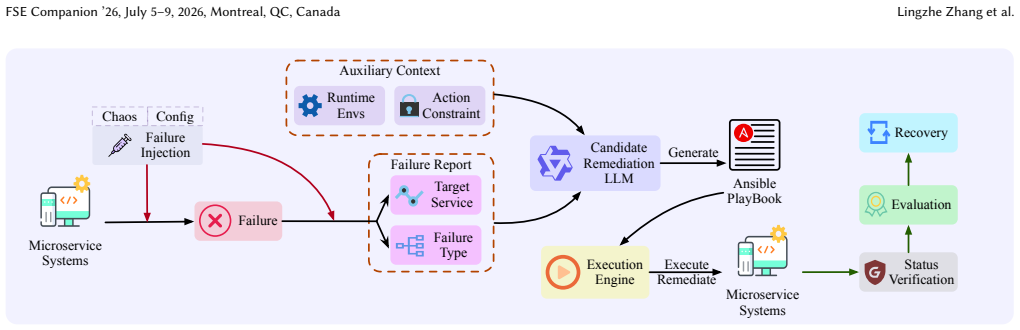
E2E-REME generates executable Ansible playbooks directly from microservice diagnosis reports through experience-simulation reinforcement fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
E2E-REME, trained via experience-simulation reinforcement fine-tuning, directly generates executable playbooks from diagnosis reports and achieves superior accuracy and efficiency compared with nine representative LLMs when restoring faulty microservice systems on public and industrial platforms.
What carries the argument
experience-simulation reinforcement fine-tuning, which uses simulated failure-and-repair episodes to refine the model so that it produces safe, executable remediation playbooks without relying on large general-purpose LLMs or hand-crafted prompts.
If this is right
- Microservice operators can trigger fully autonomous recovery from diagnosis reports alone.
- Remediation no longer depends on large general-purpose LLMs or expert prompt engineering.
- Accuracy and speed of recovery improve measurably on both open and production platforms.
- The same training loop can be reused for new failure types once the simulation environment is extended.
Where Pith is reading between the lines
- The method could be combined with continuous monitoring systems to close the loop from detection to repair.
- If the simulation fidelity is increased, the same fine-tuning recipe might apply to other distributed-system failure domains.
- Deployment cost drops because smaller fine-tuned models replace repeated calls to large frontier LLMs.
Load-bearing premise
The simulation-trained playbooks transfer to live industrial microservice environments without introducing new failures or needing heavy human oversight.
What would settle it
Execution of an E2E-REME-generated playbook on a live industrial microservice cluster that produces additional failures or fails to restore service.
Figures





read the original abstract
Contemporary microservice systems continue to grow in scale and complexity, leading to increasingly frequent and costly failures. While recent LLM-based auto-remediation approaches have emerged, they primarily translate textual instructions into executable Ansible playbooks and rely on expert-crafted prompts, lacking runtime knowledge guidance and depending on large-scale general-purpose LLMs, which limits their accuracy and efficiency. We introduce \textit{End-to-End Microservice Remediation} (E2E-MR), a new task that requires directly generating executable playbooks from diagnosis reports to autonomously restore faulty systems. To enable rigorous evaluation, we build \textit{MicroRemed}, a benchmark that automates microservice deployment, failure injection, playbook execution, and post-repair verification. We further propose \textit{E2E-REME}, an end-to-end auto-remediation model trained via experience-simulation reinforcement fine-tuning. Experiments on public and industrial microservice platforms, compared with nine representative LLMs, show that E2E-REME achieves superior accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the End-to-End Microservice Remediation (E2E-MR) task, which requires generating executable Ansible playbooks directly from diagnosis reports to restore faulty microservice systems. It presents the MicroRemed benchmark that automates microservice deployment, failure injection, playbook execution, and post-repair verification. The proposed E2E-REME model is trained via experience-simulation reinforcement fine-tuning and is claimed to outperform nine representative LLMs in accuracy and efficiency on both public and industrial microservice platforms.
Significance. If the superiority claims hold with proper validation, the work could advance automated remediation in complex microservice architectures by moving beyond prompt-engineered general LLMs toward task-specific RL fine-tuning that incorporates simulated runtime experience. The automated MicroRemed benchmark, with its failure injection and verification pipeline, represents a constructive step toward reproducible evaluation in the field. The approach addresses a practical pain point in DevOps, but its significance is currently limited by the absence of supporting quantitative evidence and sim-to-real validation.
major comments (2)
- [§4 Experiments] §4 Experiments: The central claim that E2E-REME achieves superior accuracy and efficiency over nine LLMs is asserted without any reported quantitative metrics (e.g., success rate, execution time, or cost), ablation studies on the experience-simulation RL components, or error analysis, rendering it impossible to assess whether the data support the claim.
- [§4.3 Industrial Platform Evaluation] §4.3 (Industrial Platform Evaluation): No quantitative evidence or ablation is provided on sim-to-real transfer, such as metrics for additional failures introduced by simulation-trained playbooks or confirmation that execution on live industrial clusters occurred without human intervention or rollback; this is load-bearing for the safety and autonomy claims.
minor comments (2)
- [Abstract] Abstract: The phrase 'superior accuracy and efficiency' is used without defining the concrete metrics or baselines employed.
- [§3 Method] §3 Method: The description of the experience-simulation reinforcement fine-tuning lacks explicit details on the reward function, policy update mechanism, and training hyperparameters needed for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We acknowledge the need for more explicit quantitative support in the experiments and will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments: The central claim that E2E-REME achieves superior accuracy and efficiency over nine LLMs is asserted without any reported quantitative metrics (e.g., success rate, execution time, or cost), ablation studies on the experience-simulation RL components, or error analysis, rendering it impossible to assess whether the data support the claim.
Authors: We agree that the current presentation of results in §4 is insufficiently detailed. While the abstract summarizes the comparative outcomes on the MicroRemed benchmark, we did not include the full numerical tables, ablation results on the experience-simulation RL components, or error analysis in the main text. In the revision we will add these elements, including success rates, execution times, costs, component ablations, and error breakdowns, to allow direct assessment of the claims. revision: yes
-
Referee: [§4.3 Industrial Platform Evaluation] §4.3 (Industrial Platform Evaluation): No quantitative evidence or ablation is provided on sim-to-real transfer, such as metrics for additional failures introduced by simulation-trained playbooks or confirmation that execution on live industrial clusters occurred without human intervention or rollback; this is load-bearing for the safety and autonomy claims.
Authors: We concur that explicit sim-to-real metrics are necessary to substantiate the safety and autonomy claims. The industrial evaluation involved execution on live clusters, yet we recognize that the manuscript lacks the requested quantitative details on additional failures from simulation-trained playbooks and confirmation of fully autonomous runs without intervention or rollback. We will expand §4.3 with these metrics, ablations, and explicit statements on the execution protocol. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new task (E2E-MR) and benchmark (MicroRemed) for generating executable playbooks from diagnosis reports, then applies a standard experience-simulation reinforcement fine-tuning pipeline to train E2E-REME. Central claims rest on empirical comparisons against nine LLMs showing superior accuracy and efficiency on public and industrial platforms. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or description. The derivation is self-contained: the method is a direct application of RL fine-tuning to a new domain, with results validated externally via automated failure injection, playbook execution, and post-repair verification rather than by construction from inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Towards Robust LLM Post-Training: Automatic Failure Management for Reinforcement Fine-Tuning
Introduces the first benchmark for fine-grained failures in reinforcement fine-tuning of LLMs and an automatic management framework that detects, diagnoses, and remediates them.
Reference graph
Works this paper leans on
-
[1]
Toufique Ahmed, Supriyo Ghosh, Chetan Bansal, Thomas Zimmermann, Xuchao Zhang, and Saravan Rajmohan. 2023. Recommending root-cause and mitigation steps for cloud incidents using large language models. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1737–1749
2023
-
[2]
Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, et al. 2024. Automatic root cause analysis via large language models for cloud incidents. In Proceedings of the Nineteenth European Conference on Computer Systems. 674–688
2024
-
[3]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems 30 (2017)
2017
-
[4]
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. 2024. A decoder- only foundation model for time-series forecasting. In Forty-first International Conference on Machine Learning
2024
- [5]
- [6]
-
[7]
Google Cloud Platform. 2025. Online Boutique: A Cloud-First Microservices Demo Application. https://github.com/GoogleCloudPlatform/microservices- demo. Accessed: October 15, 2025
2025
- [8]
-
[9]
Pouya Hamadanian, Behnaz Arzani, Sadjad Fouladi, Siva Kesava Reddy Kakarla, Rodrigo Fonseca, Denizcan Billor, Ahmad Cheema, Edet Nkposong, and Ranveer Chandra. 2023. A Holistic View of AI-driven Network Incident Management. In Proceedings of the 22nd ACM Workshop on Hot Topics in Networks. 180–188
2023
-
[10]
Yongqi Han, Qingfeng Du, Ying Huang, Jiaqi Wu, Fulong Tian, and Cheng He
-
[11]
In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering
The Potential of One-Shot Failure Root Cause Analysis: Collaboration of the Large Language Model and Small Classifier. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 931– 943
- [12]
- [13]
-
[14]
O’Reilly Media, Inc
Lorin Hochstein and Rene Moser. 2017. Ansible: Up and Running: Automating configuration management and deployment the easy way. " O’Reilly Media, Inc. "
2017
-
[15]
Weijie Hong, Yifan Wu, Lingzhe Zhang, Chiming Duan, Pei Xiao, Minghua He, Xixuan Yang, and Ying Li. 2025. CSLParser: A Collaborative Framework Using Small and Large Language Models for Log Parsing. In 2025 IEEE 36th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 61– 72
2025
-
[16]
Xiaosong Huang, Hongyi Liu, Yifan Wu, Lingzhe Zhang, Tong Jia, Ying Li, and Zhonghai Wu. 2025. UDA-RCL: Unsupervised Domain Adaptation for Microser- vice Root Cause Localization Utilizing Multimodal Data. IEEE Transactions on Services Computing (2025)
2025
-
[17]
Information Technology Intelligence Consulting (ITIC). 2024. ITIC 2024 Global Server Hardware,Server OS Reliability Report. Annual Report. ITIC
2024
-
[18]
Yuxuan Jiang, Chaoyun Zhang, Shilin He, Zhihao Yang, Minghua Ma, Si Qin, Yu Kang, Yingnong Dang, Saravan Rajmohan, Qingwei Lin, et al. 2024. Xpert: Empowering incident management with query recommendations via large lan- guage models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[19]
Sathvik Joel, Jie Wu, and Fatemeh Fard. 2024. A survey on llm-based code generation for low-resource and domain-specific programming languages. ACM Transactions on Software Engineering and Methodology (2024)
2024
-
[20]
Yuyuan Kang, Xiangdong Huang, Shaoxu Song, Lingzhe Zhang, Jialin Qiao, Chen Wang, Jianmin Wang, and Julian Feinauer. 2022. Separation or not: On handing out-of-order time-series data in leveled lsm-tree. In 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 3340–3352
2022
-
[21]
Van-Hoang Le and Hongyu Zhang. 2024. Prelog: A pre-trained model for log analytics. Proceedings of the ACM on Management of Data 2, 3 (2024), 1–28
2024
-
[22]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Hongyi Liu, Xiaosong Huang, Mengxi Jia, Lingzhe Zhang, Tong Jia, Zhonghai Wu, and Ying Li. 2025. AAAD: Asynchronous Inter-Variable Relationship-Aware Anomaly Detection for Multivariate Time Series. In 2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
2025
-
[24]
Hongyi Liu, Yinping Ma, Xiaosong Huang, Lingzhe Zhang, Tong Jia, and Ying Li
-
[25]
In Proceedings of the 39th ACM International Conference on Supercomputing
ORA: Job Runtime Prediction for High-Performance Computing Platforms Using the Online Retrieval-Augmented Language Model. In Proceedings of the 39th ACM International Conference on Supercomputing. 884–894
-
[26]
Haoxin Liu, Zhiyuan Zhao, Jindong Wang, Harshavardhan Kamarthi, and B Aditya Prakash. 2024. LSTPrompt: Large Language Models as Zero-Shot Time Series Forecasters by Long-Short-Term Prompting. InFindings of the Association for Computational Linguistics ACL 2024. 7832–7840
2024
- [27]
-
[28]
Xu Liu, Junfeng Hu, Yuan Li, Shizhe Diao, Yuxuan Liang, Bryan Hooi, and Roger Zimmermann. 2024. Unitime: A language-empowered unified model for cross- domain time series forecasting. InProceedings of the ACM WebConference 2024. 4095–4106
2024
- [29]
-
[30]
Yilun Liu, Shimin Tao, Weibin Meng, Jingyu Wang, Wenbing Ma, Yuhang Chen, Yanqing Zhao, Hao Yang, and Yanfei Jiang. 2024. Interpretable online log analysis using large language models with prompt strategies. In Proceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 35–46
2024
-
[31]
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. 2024. Timer: generative pre-trained transformers are large time series models. In Proceedings of the 41st International Conference on Machine Learning. 32369–32399
2024
-
[32]
Chaos Mesh. 2025. A powerful chaos engineering platform for kubernetes. URL: https://chaos-mesh.org (2025)
2025
-
[33]
Zakeya Namrud, Komal Sarda, Marin Litoiu, Larisa Shwartz, and Ian Watts
-
[34]
In Companion of the 15th ACM/SPEC International Conference on Performance Engineering
Kubeplaybook: A repository of ansible playbooks for kubernetes auto- remediation with llms. In Companion of the 15th ACM/SPEC International Conference on Performance Engineering. 57–61
-
[35]
Ruben Opdebeeck, Ahmed Zerouali, and Coen De Roover. 2021. Andromeda: A dataset of Ansible Galaxy roles and their evolution. In 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR). IEEE, 580– 584
2021
-
[36]
Jonathan Pan, Wong Swee Liang, and Yuan Yidi. 2024. Raglog: Log anomaly detection using retrieval augmented generation. In 2024 IEEE World Forum on Public Safety Technology (WFPST). IEEE, 169–174
2024
- [37]
-
[38]
Leyi Pan, Shuchang Tao, Yunpeng Zhai, Zheyu Fu, Liancheng Fang, Minghua He, Lingzhe Zhang, Zhaoyang Liu, Bolin Ding, Aiwei Liu, et al . 2025. d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models.arXiv preprint arXiv:2512.09675 (2025)
work page internal anchor Pith review arXiv 2025
-
[39]
Saurabh Pujar, Luca Buratti, Xiaojie Guo, Nicolas Dupuis, Burn Lewis, Sahil Suneja, Atin Sood, Ganesh Nalawade, Matt Jones, Alessandro Morari, et al. 2023. Automated code generation for information technology tasks in yaml through FSE Companion ’26, July 5–9, 2026, Montreal, QC, Canada Lingzhe Zhang et al. large language models. In 2023 60th ACM/IEEE Desi...
2023
-
[40]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems 36 (2023), 53728–53741
2023
-
[41]
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, et al. 2023. Lag-llama: Towards foundation models for time series forecasting. In R0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models
2023
- [42]
-
[43]
Priyam Sahoo, Saurabh Pujar, Ganesh Nalawade, Richard Genhardt, Louis Mandel, and Luca Buratti. 2024. Ansible lightspeed: A code generation service for it automation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 2148–2158
2024
-
[44]
Komal Sarda, Zakeya Namrud, Marin Litoiu, Larisa Shwartz, and Ian Watts. 2024. Leveraging large language models for the auto-remediation of microservice ap- plications: An experimental study. In Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 358–369
2024
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Jie Shi, Sihang Jiang, Bo Xu, Jiaqing Liang, Yanghua Xiao, and Wei Wang. 2023. ShellGPT: Generative Pre-trained Transformer Model for Shell Language Un- derstanding. In 2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 671–682
2023
-
[47]
Aditi Singh, Abul Ehtesham, Saket Kumar, and Tala Talaei Khoei. 2025. Agen- tic retrieval-augmented generation: A survey on agentic rag. arXiv preprint arXiv:2501.09136 (2025)
work page internal anchor Pith review arXiv 2025
-
[48]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al . 2025. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534 (2025)
work page internal anchor Pith review arXiv 2025
- [49]
-
[50]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Zhaoyang Yu, Changhua Pei, Xin Wang, Minghua Ma, Chetan Bansal, Saravan Rajmohan, Qingwei Lin, Dongmei Zhang, Xidao Wen, Jianhui Li, et al . 2024. Pre-trained kpi anomaly detection model through disentangled transformer. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6190–6201
2024
-
[52]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review arXiv 2025
- [53]
-
[54]
Dylan Zhang, Xuchao Zhang, Chetan Bansal, Pedro Las-Casas, Rodrigo Fon- seca, and Saravan Rajmohan. 2024. LM-PACE: Confidence estimation by large language models for effective root causing of cloud incidents. In Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 388–398
2024
- [55]
- [56]
-
[57]
Lingzhe Zhang, Tong Jia, Mengxi Jia, Ying Li, Yong Yang, and Zhonghai Wu
-
[58]
In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Multivariate log-based anomaly detection for distributed database. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4256–4267
-
[59]
Lingzhe Zhang, Tong Jia, Mengxi Jia, Hongyi Liu, Yong Yang, Zhonghai Wu, and Ying Li. 2024. Towards close-to-zero runtime collection overhead: Raft- based anomaly diagnosis on system faults for distributed storage system. IEEE Transactions on Services Computing (2024)
2024
-
[60]
Lingzhe Zhang, Tong Jia, Mengxi Jia, Yifan Wu, Aiwei Liu, Yong Yang, Zhonghai Wu, Xuming Hu, Philip Yu, and Ying Li. 2025. A Survey of AIOps in the Era of Large Language Models. Comput. Surveys (2025)
2025
-
[61]
Lingzhe Zhang, Tong Jia, Mengxi Jia, Yifan Wu, Hongyi Liu, and Ying Li. 2025. ScalaLog: Scalable Log-Based Failure Diagnosis Using LLM. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2025
-
[62]
Lingzhe Zhang, Tong Jia, Mengxi Jia, Yifan Wu, Hongyi Liu, and Ying Li. 2025. XRAGLog: A resource-efficient and context-aware log-based anomaly detec- tion method using retrieval-augmented generation. In AAAI 2025 Workshop on Preventing and Detecting LLM Misinformation (PDLM)
2025
-
[63]
Lingzhe Zhang, Tong Jia, Xinyu Tan, Xiangdong Huang, Mengxi Jia, Hongyi Liu, Zhonghai Wu, and Ying Li. 2025. E-log: Fine-grained elastic log-based anomaly detection and diagnosis for databases.IEEE Transactions on Services Computing (2025)
2025
- [64]
-
[65]
Lingzhe Zhang, Tong Jia, Kangjin Wang, Mengxi Jia, Yong Yang, and Ying Li
-
[66]
InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement
Reducing events to augment log-based anomaly detection models: An empirical study. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. 538–548
- [67]
- [68]
- [69]
- [70]
-
[71]
Lingzhe Zhang, Yunpeng Zhai, Tong Jia, Xiaosong Huang, Chiming Duan, and Ying Li. 2025. Agentfm: Role-aware failure management for distributed databases with llm-driven multi-agents. In Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering. 525–529
2025
-
[72]
Ling-Zhe Zhang, Xiang-Dong Huang, Yan-Kai Wang, Jia-Lin Qiao, Shao-Xu Song, and Jian-Min Wang. 2024. Time-tired compaction: An elastic compaction scheme for LSM-tree based time-series database. Advanced Engineering Informatics 59 (2024), 102224
2024
-
[73]
Shenglin Zhang, Sibo Xia, Wenzhao Fan, Binpeng Shi, Xiao Xiong, Zhenyu Zhong, Minghua Ma, Yongqian Sun, and Dan Pei. 2024. Failure diagnosis in microservice systems: A comprehensive survey and analysis. ACM Transactions on Software Engineering and Methodology (2024)
2024
-
[74]
Tianyang Zhang, Zhuoxuan Jiang, Shengguang Bai, Tianrui Zhang, Lin Lin, Yang Liu, and Jiawei Ren. 2024. RAG4ITOps: A Supervised Fine-Tunable and Com- prehensive RAG Framework for IT Operations and Maintenance. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 738–754
2024
-
[75]
Wanhao Zhang, Qianli Zhang, Enyu Yu, Yuxiang Ren, Yeqing Meng, Mingxi Qiu, and Jilong Wang. 2024. LogRAG: Semi-Supervised Log-based Anomaly Detection with Retrieval-Augmented Generation. In 2024 IEEE International Conference on Web Services (ICWS). IEEE, 1100–1102
2024
-
[76]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems 43, 6 (2025), 1–47
2025
-
[77]
Xiang Zhou, Xin Peng, Tao Xie, Jun Sun, Chao Ji, Wenhai Li, and Dan Ding. 2018. Fault analysis and debugging of microservice systems: Industrial survey, bench- mark system, and empirical study. IEEE Transactions on Software Engineering 47, 2 (2018), 243–260
2018
-
[78]
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593 (2019)
work page internal anchor Pith review arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.