Recognition: unknown
ViserDex: Visual Sim-to-Real for Robust Dexterous In-hand Reorientation
Pith reviewed 2026-05-10 15:22 UTC · model grok-4.3
The pith
Domain randomization inside 3D Gaussians produces training images that let a single RGB camera guide reliable in-hand reorientation on real hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
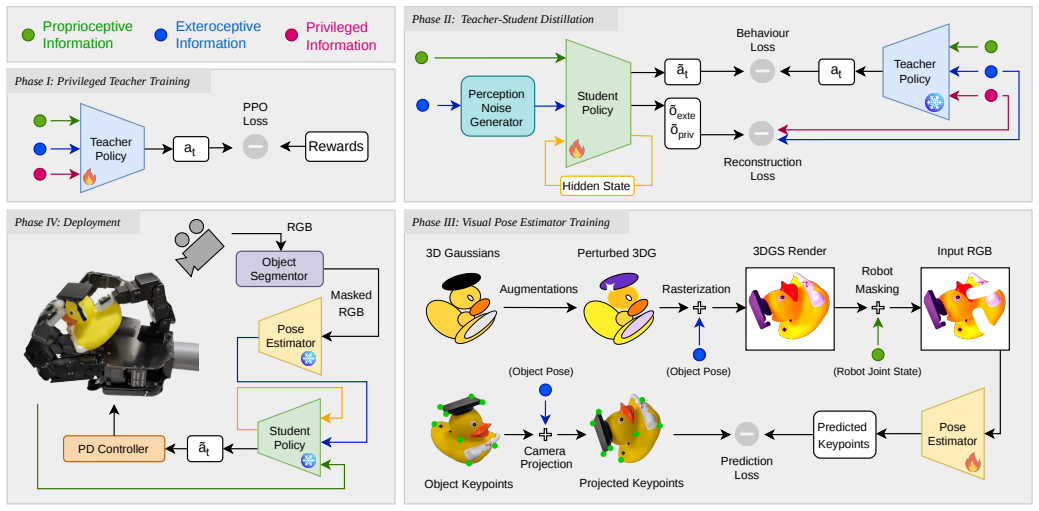
Performing domain randomization inside the 3D Gaussian representation before rendering produces photorealistic yet randomized visual data that supports accurate object pose estimation during dynamic, contact-rich sequences. Both the pose estimator and the manipulation policy, the latter trained via curriculum reinforcement learning with teacher-student distillation, can be learned independently on consumer hardware. On real hardware the combined system achieves robust reorientation of five diverse objects under challenging lighting using only a monocular RGB camera.
What carries the argument
Domain randomization applied to 3D Gaussian Splatting representations before rendering, which supplies the visual training distribution for the monocular pose estimator.
If this is right
- Object pose can be recovered from a single RGB camera even while the fingers execute complex reorientation sequences.
- Perception and control components train separately without requiring large compute clusters.
- The same pipeline supports reorientation of multiple object geometries under varied real lighting.
- Gaussian splatting replaces costly ray-tracing renderers for visual sim-to-real transfer in dexterous tasks.
Where Pith is reading between the lines
- The same pre-rendering randomization step could be tested on other contact-rich tasks such as precision insertion or tool use where visual feedback must survive motion blur and occlusion.
- Because perception and control are trained independently, the pose estimator could be fine-tuned on new objects or lighting without retraining the entire policy.
- If Gaussian models already encode 3D structure, future extensions might predict contact points or slip directly from the same representation rather than routing everything through explicit pose.
Load-bearing premise
Pre-rendering augmentations applied to 3D Gaussians create a visual data distribution close enough to real-world variations to keep pose estimation accurate throughout fast, contact-heavy finger motions.
What would settle it
Measure object pose estimation error on the physical hand during active reorientation while lighting changes rapidly; if the 3DGS-trained estimator shows no improvement over conventional rendering or loses track, the central claim fails.
Figures





read the original abstract
In-hand object reorientation requires precise estimation of the object pose to handle complex task dynamics. While RGB sensing offers rich semantic cues for pose tracking, existing solutions rely on multi-camera setups or costly ray tracing. We present a sim-to-real framework for monocular RGB in-hand reorientation that integrates 3D Gaussian Splatting (3DGS) to bridge the visual sim-to-real gap. Our key insight is performing domain randomization in the Gaussian representation space: by applying physically consistent, pre-rendering augmentations to 3D Gaussians, we generate photorealistic, randomized visual data for object pose estimation. The manipulation policy is trained using curriculum-based reinforcement learning with teacher-student distillation, enabling efficient learning of complex behaviors. Importantly, both perception and control models can be trained independently on consumer-grade hardware, eliminating the need for large compute clusters. Experiments show that the pose estimator trained with 3DGS data outperforms those trained using conventional rendering data in challenging visual environments. We validate the system on a physical multi-fingered hand equipped with an RGB camera, demonstrating robust reorientation of five diverse objects even under challenging lighting conditions. Our results highlight Gaussian splatting as a practical path for RGB-only dexterous manipulation. For videos of the hardware deployments and additional supplementary materials, please refer to the project website: https://rffr.leggedrobotics.com/works/viserdex/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViserDex, a sim-to-real framework for monocular RGB-based in-hand object reorientation that uses 3D Gaussian Splatting (3DGS) to perform domain randomization directly in Gaussian space via physically consistent pre-rendering augmentations. This generates training data for a pose estimator, while a separate manipulation policy is trained via curriculum reinforcement learning with teacher-student distillation. Both components train independently on consumer hardware. The central empirical claims are that the 3DGS-trained pose estimator outperforms conventional rendering baselines in challenging visual conditions and that the full system enables robust reorientation of five diverse objects on a physical multi-fingered hand with RGB camera under difficult lighting.
Significance. If the reported outperformance and hardware robustness are substantiated with quantitative metrics, the work would offer a practical route to RGB-only dexterous manipulation that avoids multi-camera rigs or expensive ray-tracing, while demonstrating that 3DGS can serve as an effective sim-to-real bridge for contact-rich tasks. The independent training of perception and control on modest hardware is a notable engineering strength that lowers barriers to reproduction and extension.
major comments (3)
- [§4] §4 (Experiments) and abstract: the headline claim that the 3DGS-trained pose estimator 'outperforms those trained using conventional rendering data in challenging visual environments' is presented without any quantitative metrics, baseline details, error bars, ablation tables, or per-phase error breakdowns on either simulated or hardware data. This absence directly undermines assessment of whether the central sim-to-real transfer claim holds.
- [§3.2] §3.2 (Gaussian-space domain randomization): the key assumption that pre-rendering physically consistent augmentations on (typically static, object-centric) 3D Gaussians produces a training distribution sufficiently close to real monocular RGB observations throughout dynamic, contact-rich sequences is not supported by any distribution metrics (e.g., FID or perceptual distances), ablation isolating the pre-rendering step, or analysis of motion-dependent effects such as finger-induced shadows and evolving partial occlusions.
- [§5] Hardware validation paragraph and §5: the demonstration of 'robust reorientation of five diverse objects even under challenging lighting conditions' on the physical hand lacks per-object success rates, failure-mode analysis, or quantitative pose-estimation error during contact phases, leaving the practical robustness claim difficult to evaluate.
minor comments (2)
- The project website is referenced for videos and supplementary materials, but the manuscript does not indicate whether code, trained models, or the exact 3DGS augmentation parameters will be released to support reproducibility.
- Notation for the teacher-student distillation and curriculum schedule could be clarified with a single diagram or pseudocode block to make the independent training pipeline easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight areas where additional quantitative support and analysis will strengthen the manuscript. We address each major comment below and will revise accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and abstract: the headline claim that the 3DGS-trained pose estimator 'outperforms those trained using conventional rendering data in challenging visual environments' is presented without any quantitative metrics, baseline details, error bars, ablation tables, or per-phase error breakdowns on either simulated or hardware data. This absence directly undermines assessment of whether the central sim-to-real transfer claim holds.
Authors: We agree that the current §4 would benefit from expanded quantitative reporting to substantiate the outperformance claim. In the revised manuscript we will add comprehensive tables with mean rotation/translation errors, baseline comparisons to conventional rendering, error bars from repeated trials, and per-phase breakdowns for both simulated and hardware data under varied lighting. This will enable direct evaluation of the sim-to-real transfer. revision: yes
-
Referee: [§3.2] §3.2 (Gaussian-space domain randomization): the key assumption that pre-rendering physically consistent augmentations on (typically static, object-centric) 3D Gaussians produces a training distribution sufficiently close to real monocular RGB observations throughout dynamic, contact-rich sequences is not supported by any distribution metrics (e.g., FID or perceptual distances), ablation isolating the pre-rendering step, or analysis of motion-dependent effects such as finger-induced shadows and evolving partial occlusions.
Authors: We acknowledge that explicit distribution metrics and ablations would better support the assumption. While downstream task performance already indicates effectiveness, the revision will include FID and perceptual distance comparisons between 3DGS-augmented renders and real images, an ablation isolating the pre-rendering step, and targeted analysis of motion-dependent phenomena (shadows, partial occlusions) on dynamic sequences. These additions will directly address the concern. revision: yes
-
Referee: [§5] Hardware validation paragraph and §5: the demonstration of 'robust reorientation of five diverse objects even under challenging lighting conditions' on the physical hand lacks per-object success rates, failure-mode analysis, or quantitative pose-estimation error during contact phases, leaving the practical robustness claim difficult to evaluate.
Authors: We agree that more granular hardware metrics are needed for a complete assessment. The revised §5 will report per-object success rates across repeated trials, a categorized failure-mode analysis (e.g., tracking loss, slippage), and quantitative pose-estimation errors specifically during contact phases under challenging lighting. This will provide a clearer quantitative basis for the robustness claims. revision: yes
Circularity Check
No circularity: empirical comparisons rest on independent training regimes and hardware tests
full rationale
The paper describes a sim-to-real pipeline that applies domain randomization directly in 3D Gaussian space before rendering, trains a pose estimator and an RL policy separately, and validates via side-by-side performance metrics on synthetic and real RGB data. No equations, fitted parameters, or predictions are defined in terms of the target quantities; the central claim (3DGS-augmented data yields better pose estimation under challenging lighting) is an empirical outcome measured against a conventional-rendering baseline, not a self-referential construction. No load-bearing self-citations or uniqueness theorems appear in the provided text. The distribution-closeness assumption is treated as a testable hypothesis rather than an input that is renamed as output.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption 3D Gaussian Splatting can be augmented in a physically consistent manner before rendering to bridge the visual sim-to-real gap for object pose estimation
- domain assumption Curriculum-based reinforcement learning with teacher-student distillation enables efficient learning of complex dexterous in-hand behaviors
Reference graph
Works this paper leans on
- [1]
-
[2]
Learning dexterous in-hand manipula- tion.The International Journal of Robotics Research, 39 (1):3–20, 2020
OpenAI: Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Jozefowicz, Bob McGrew, Jakub Pa- chocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, et al. Learning dexterous in-hand manipula- tion.The International Journal of Robotics Research, 39 (1):3–20, 2020
2020
-
[3]
Surprisingly robust in-hand manipulation: An empirical study.Robotics: Science and Systems, 2021
Aditya Bhatt, Adrian Sieler, Steffen Puhlmann, and Oliver Brock. Surprisingly robust in-hand manipulation: An empirical study.Robotics: Science and Systems, 2021
2021
-
[4]
Filip Bjelonic, Fabian Tischhauser, and Marco Hut- ter. Towards bridging the gap: Systematic sim-to- real transfer for diverse legged robots.arXiv preprint arXiv:2509.06342, 2025
-
[5]
Visual dexterity: In- hand reorientation of novel and complex object shapes
Tao Chen, Megha Tippur, Siyang Wu, Vikash Kumar, Ed- ward Adelson, and Pulkit Agrawal. Visual dexterity: In- hand reorientation of novel and complex object shapes. Science Robotics, 8(84):eadc9244, 2023
2023
-
[6]
Timothy Chen, Ola Shorinwa, Joseph Bruno, Aiden Swann, Javier Yu, Weijia Zeng, Keiko Nagami, Philip Dames, and Mac Schwager. Splat-nav: Safe real-time robot navigation in gaussian splatting maps, 2024. URL https://arxiv.org/abs/2403.02751
-
[7]
Dextreme: Transfer of agile in-hand manipulation from simulation to reality
Ankur Handa, Arthur Allshire, Viktor Makoviychuk, Aleksei Petrenko, Ritvik Singh, Jingzhou Liu, Denys Makoviichuk, Karl Van Wyk, Alexander Zhurkevich, Balakumar Sundaralingam, et al. Dextreme: Transfer of agile in-hand manipulation from simulation to reality. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5977–5984. IEEE, 2023
2023
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, (CVPR), pages 770–778, 2016
2016
-
[9]
Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular, stereo, and rgb-d cameras
Huajian Huang, Longwei Li, Cheng Hui, and Sai-Kit Yeung. Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular, stereo, and rgb-d cameras. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024
2024
-
[10]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023. URL https://repo-sam.inria.fr/fungraph/ 3d-gaussian-splatting/
2023
-
[11]
Yongseok Lee, Hyunsu Kim, Harim Ji, Jinuk Heo, Youngseon Lee, Jiseock Kang, Jeongseob Lee, and Dongjun Lee. Human-in-the-loop gaussian splatting for robotic teleoperation.IEEE Robotics and Automation Letters, 11(1):105–112, 2026. doi: 10.1109/LRA.2025. 3632755
-
[12]
Robogsim: A real2sim2real robotic gaus- sian splatting simulator,
Xinhai Li, Jialin Li, Ziheng Zhang, Rui Zhang, Fan Jia, Tiancai Wang, Haoqiang Fan, Kuo-Kun Tseng, and Ruiping Wang. Robogsim: A real2sim2real robotic gaussian splatting simulator, 2024. URL https://arxiv. org/abs/2411.11839
-
[13]
Hidenobu Matsuki, Riku Murai, Paul H. J. Kelly, and Andrew J. Davison. Gaussian Splatting SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[14]
Real-time sampling-based safe motion planning for robotic manipulators in dynamic environments,
Jonathan Michaux, Seth Isaacson, Challen Enninful Adu, Adam Li, Rahul Kashyap Swayampakula, Parker Ewen, Sean Rice, Katherine A. Skinner, and Ram Vasudevan. Let’s make a splan: Risk-aware trajectory optimization in a normalized gaussian splat.IEEE Transactions on Robotics, pages 1–19, 2025. doi: 10.1109/TRO.2025. 3584559
-
[15]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
Takahiro Miki, Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, and Marco Hutter. Learning robust perceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022. doi: 10.1126/scirobotics.abk2822. URL https://www.science. org/doi/abs/10.1126/scirobotics.abk2822
-
[16]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Mu ˜noz, Xinjie Yao, Ren ´e Zurbr ¨ugg, Nikita Rudin, Lukasz Wawrzyniak, Milad Rakhsha, Alain Denzler, Eric Hei- den, Ales Borovicka, Ossama Ahmed, Iretiayo Akinola, Abrar Anwar, Mark T. Carlson, Ji Yuan Feng, Ani- mesh Garg, Renato Gasoto, Lionel Gulich, Yijie...
work page internal anchor Pith review arXiv 2025
-
[17]
Taylor, and Peter Stone
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E. Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: a frame- work and survey.J. Mach. Learn. Res., 21(1), January
-
[18]
Learning a shape- conditioned agent for purely tactile in-hand manipulation of various objects
Johannes Pitz, Lennart R ¨ostel, Leon Sievers, Darius Burschka, and Berthold B ¨auml. Learning a shape- conditioned agent for purely tactile in-hand manipulation of various objects. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13112–13119. IEEE, 2024
2024
-
[19]
Polycam - lidar & 3d scanner for iphone and android, 2024
Polycam Inc. Polycam - lidar & 3d scanner for iphone and android, 2024. URL https://poly.cam/. Accessed: 2024-05-20
2024
-
[20]
General In-Hand Object Rotation with Vision and Touch
Haozhi Qi, Brent Yi, Sudharshan Suresh, Mike Lambeta, Yi Ma, Roberto Calandra, and Jitendra Malik. General In-Hand Object Rotation with Vision and Touch. In Conference on Robot Learning (CoRL), 2023
2023
-
[21]
Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting, 2024
Mohammad Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, and Abhishesh Silwal. Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting, 2024. URL https://arxiv.org/abs/2409.10161
-
[23]
URL https://arxiv.org/abs/2408.00714
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
A reduction of imitation learning and structured prediction to no-regret online learning
St ´ephane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelli- gence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[25]
Plenoxels: Radiance fields without neural networks
Sara Fridovich-Keil and Alex Yu, Matthew Tancik, Qin- hong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In CVPR, 2022
2022
-
[26]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.ArXiv, abs/1707.06347, 2017. URL https: //api.semanticscholar.org/CorpusID:28695052
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
arXiv preprint arXiv:2509.10771 , year=
Clemens Schwarke, Mayank Mittal, Nikita Rudin, David Hoeller, and Marco Hutter. Rsl-rl: A learning library for robotics research.arXiv preprint arXiv:2509.10771, 2025
-
[28]
Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands,
Ritvik Singh, Arthur Allshire, Ankur Handa, Nathan Ratliff, and Karl Van Wyk. Dextrah-rgb: Visuomotor policies to grasp anything with dexterous hands.arXiv preprint arXiv:2412.01791, 2024
-
[29]
Synthetica: Large scale synthetic data generation for robot perception
Ritvik Singh, Jason Jingzhou Liu, Karl Van Wyk, Yu-Wei Chao, Jean-Francois Lafleche, Florian Shkurti, Nathan Ratliff, and Ankur Handa. Synthetica: Large scale synthetic data generation for robot perception. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7810–7817. IEEE, 2025
2025
-
[30]
Jos M. F. ten Berge. The rigid orthogonal procrustes rotation problem.Psychometrika, 71(1):201–205, 2006. doi: 10.1007/s11336-004-1160-5
-
[31]
Jiaxu Wang, Qiang Zhang, Jingkai Sun, Jiahang Cao, Gang Han, Wen Zhao, Weining Zhang, Yecheng Shao, Yijie Guo, and Renjing Xu. Reinforcement learning with generalizable gaussian splatting. In2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 435–441, 2024. doi: 10.1109/IROS58592. 2024.10801348
-
[32]
Birch- field
Bowen Wen, Wei Yang, Jan Kautz, and Stanley T. Birch- field. Foundationpose: Unified 6d pose estimation and tracking of novel objects.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17868–17879, 2023. URL https://api.semanticscholar. org/CorpusID:266191252
2024
-
[33]
Zhao, Chenfeng Xu, Chen Tang, Chenran Li, Mingyu Ding, Masayoshi Tomizuka, and Wei Zhan
Maximum Wilder-Smith, Vaishakh Patil, and Marco Hut- ter. Radiance fields for robotic teleoperation. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13861–13868, 2024. doi: 10.1109/IROS58592.2024.10801345
-
[34]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Yuxuan Wu, Lei Pan, Wenhua Wu, Guangming Wang, Yanzi Miao, Fan Xu, and Hesheng Wang. Rl-gsbridge: 3d gaussian splatting based real2sim2real method for robotic manipulation learning. In2025 IEEE International Con- ference on Robotics and Automation (ICRA), pages 192– 198, 2025. doi: 10.1109/ICRA55743.2025.11128103
-
[35]
Ford, Haoran Li, Efi Psomopoulou, David A.W
Max Yang, chenghua lu, Alex Church, Yijiong Lin, Christopher J. Ford, Haoran Li, Efi Psomopoulou, David A.W. Barton, and Nathan F. Lepora. Anyro- tate: Gravity-invariant in-hand object rotation with sim- to-real touch. In8th Annual Conference on Robot Learning, 2024. URL https://openreview.net/forum?id= 8Yu0TNJNGK
2024
-
[36]
Rotating without seeing: Towards in-hand dexterity through touch.Robotics: Science and Systems, 2023
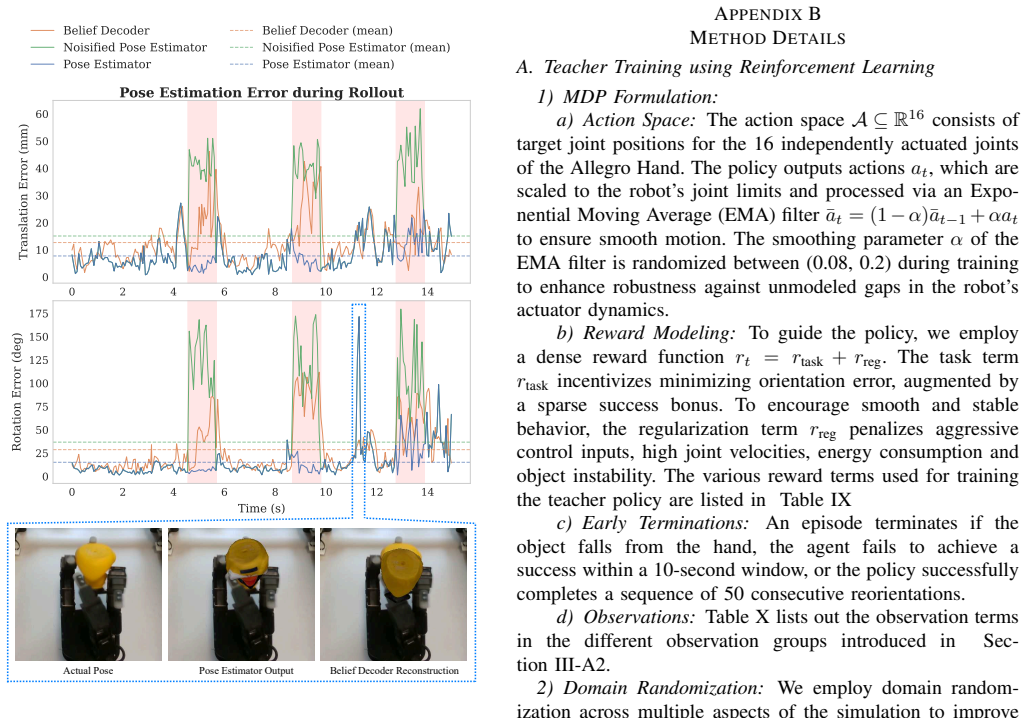
Zhao-Heng Yin, Binghao Huang, Yuzhe Qin, Qifeng Chen, and Xiaolong Wang. Rotating without seeing: Towards in-hand dexterity through touch.Robotics: Science and Systems, 2023. APPENDIXA ADDITIONALRESULTS A. Simulation Results To quantify the distillation gap and robustness against observation noise, we evaluate the teacher and student policies across rando...
2023
-
[37]
MDP Formulation: a) Action Space:The action spaceA ⊆R 16 consists of target joint positions for the 16 independently actuated joints of the Allegro Hand. The policy outputs actionsa t, which are scaled to the robot’s joint limits and processed via an Expo- nential Moving Average (EMA) filter¯at = (1−α)¯at−1 +αa t to ensure smooth motion. The smoothing par...
-
[38]
Domain Randomization:We employ domain random- ization across multiple aspects of the simulation to improve robustness against varying physical conditions and facilitate sim-to-real transfer. Physical properties of both the robot and the object, including link and object mass, friction coefficients, and restitution, are randomized to account for inaccuraci...
-
[39]
Unlike standard implementations, where only the critic has access to privileged state information, we provide privileged observationsO priv to both the actor and the critic
Policy Architecture and Optimization:We employ a modified asymmetric actor-critic framework to learn the teacher policy. Unlike standard implementations, where only the critic has access to privileged state information, we provide privileged observationsO priv to both the actor and the critic. The asymmetry is instead introduced in the actor’s propri- oce...
-
[40]
Student Policy:The parameters for the student policy architecture and training are listed in Table XIII
-
[41]
During data collec- tion, we generate trajectories by stochastically mixing the teacher’s and student’s actions
Online DAgger:We employ an online variant of DAg- ger [23] to mitigate the covariate shift between states induced by the student’s and teacher’s actions. During data collec- tion, we generate trajectories by stochastically mixing the teacher’s and student’s actions. At each timestep, the action TABLE XI: Domain Randomization Parameters Parameter Type Dist...
-
[42]
Perception Noise Generator:The various noise terms used in the perception noise model and their distribution parameters are listed in Table XIV . C. Visual Object Representation and Augmentations
-
[43]
The parameters used for different augmentation layers are provided in Table I
Pre-Rasterization Augmentations:We outline the gen- eral algorithm for applying the pre-rasterization augmentations TABLE XIII: Student Policy and Distillation Hyperparameters Parameter Value STUDENTARCHITECTURE Actor MLP[1024,1024,512,512] Exteroceptive MLP[256,256] Exteroceptive Latent Dim64 Privileged Latent Dim256 Activation Function ELU Initial Actio...
-
[44]
A complete list of these augmentations and parameters is provided in Table XV
Post-process Image Augmentations:Consistent with prior work [7, 27], our baselines utilize standard post- process image augmentations for data randomization (see Section IV-A). A complete list of these augmentations and parameters is provided in Table XV . D. Visual Object Pose Estimator Training
-
[45]
The network receives120×120 pixel RGB images, which are normalized and upsampled to 224×224pixels to align with the backbone’s input size
Network Architecture and Training:The pose estimator employs a ResNet-34 [8] backbone, initialized with weights pre-trained on ImageNet. The network receives120×120 pixel RGB images, which are normalized and upsampled to 224×224pixels to align with the backbone’s input size. Feature maps extracted from the final convolutional layer are spatially compresse...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.