Incentive Design without Hypergradients: A Social-Gradient Method
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
The gradient of the social cost is always a descent direction for the planner's objective irrespective of agents' private costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that the social cost gradient is always a descent direction for the planner's objective, irrespective of the agent cost landscape. In the idealized setting where equilibrium responses are observable, the social-gradient flow converges to the unique socially optimal incentive. When equilibria are not directly observable, the social-gradient flow emerges as the slow-timescale limit of a two-timescale interaction, in which agents' strategies evolve on a faster timescale. It is established that the joint strategy-incentive dynamics converge to the social optimum for any agent learning rule that asymptotically tracks the equilibrium.
What carries the argument
The social-gradient flow: an incentive-update rule that follows the gradient of the planner's social cost evaluated at the agents' joint actions, serving as a descent direction without any computation of equilibrium sensitivities to incentives.
If this is right
- The method requires no knowledge of individual agent cost functions.
- It converges to the unique socially optimal incentive when equilibrium actions are observable.
- In the unobservable case the flow arises automatically as the slow dynamics of any two-timescale system where agents track equilibrium on the fast scale.
- Convergence holds for every agent learning rule that asymptotically reaches the Nash equilibrium.
Where Pith is reading between the lines
- The same descent property might be usable in other bilevel problems where the upper-level objective depends only on lower-level variables.
- One could examine convergence rates by instantiating the flow in concrete economic settings such as routing or resource-allocation games.
- The two-timescale separation suggests a template for hypergradient-free algorithms in broader classes of equilibrium-constrained optimization.
Load-bearing premise
The planner's social cost depends on the agents' joint actions.
What would settle it
An analytical example or numerical run in which the social cost is a function of joint actions yet following its gradient at the equilibrium increases the planner's objective for some choice of agent cost functions.
Figures

read the original abstract
Incentive design problems consider a system planner who steers self-interested agents toward a socially optimal Nash equilibrium by issuing incentives in the presence of information asymmetry, that is, uncertainty about the agents' cost functions. A common approach formulates the problem as a Mathematical Program with Equilibrium Constraints (MPEC) and optimizes incentives using hypergradients-the total derivatives of the planner's objective with respect to incentives. However, computing or approximating the hypergradients typically requires full or partial knowledge of equilibrium sensitivities to incentives, which is generally unavailable under information asymmetry. In this paper, we propose a hypergradient-free incentive law, called the social-gradient flow, for incentive design when the planner's social cost depends on the agents' joint actions. We prove that the social cost gradient is always a descent direction for the planner's objective, irrespective of the agent cost landscape. In the idealized setting where equilibrium responses are observable, the social-gradient flow converges to the unique socially optimal incentive. When equilibria are not directly observable, the social-gradient flow emerges as the slow-timescale limit of a two-timescale interaction, in which agents' strategies evolve on a faster timescale. It is established that the joint strategy-incentive dynamics converge to the social optimum for any agent learning rule that asymptotically tracks the equilibrium. Theoretical results are also validated via numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hypergradient-free 'social-gradient flow' for incentive design problems, where a planner issues incentives u to steer self-interested agents to a socially optimal Nash equilibrium under uncertainty about agent costs. When the planner's social cost S depends on the agents' joint actions x(u), the method sets du/dt = -∇_x S(x(u)) and claims this is always a descent direction for the planner's objective Φ(u) = S(x(u)), irrespective of the agent cost landscape. Convergence to the unique optimal incentive is proved when equilibria are observable; when not, the flow arises as the slow-timescale limit of a two-timescale system in which agents track equilibrium on the fast scale, for any learning rule that asymptotically reaches equilibrium. Numerical experiments validate the approach.
Significance. If the descent property can be established under clearly stated conditions, the hypergradient-free formulation would be a useful practical advance for incentive design under information asymmetry, avoiding the need to compute or estimate equilibrium sensitivities. The two-timescale result that holds for arbitrary equilibrium-tracking agent dynamics is a strength, as is the explicit numerical validation. The work addresses a genuine gap between theoretical MPEC formulations and implementable incentive laws.
major comments (2)
- [Abstract / §3 (Main Results)] Abstract and the statement of the main descent result (likely §3 or Theorem 1): the claim that 'the social cost gradient is always a descent direction for the planner's objective, irrespective of the agent cost landscape' does not hold for arbitrary agent costs. In the standard setup, dx/du = H^{-1} where H is the Jacobian of the pseudo-gradient; then dΦ/dt = -∇S^T H^{-1} ∇S, which is ≤0 for all ∇S only when H ≻ 0. Non-convex or non-monotone agent costs allow H with negative eigenvalues, so the direction need not be descent. The joint-action dependence of S is necessary but insufficient; the 'irrespective' qualifier is load-bearing for the hypergradient-free contribution and must be corrected or qualified with explicit assumptions (e.g., strong monotonicity of the pseudo-gradient).
- [§4 (Two-timescale Convergence)] §4 (Two-timescale analysis): the convergence claim for the joint strategy-incentive dynamics relies on the fast timescale reaching equilibrium, but the slow-timescale limit argument should explicitly verify that the social-gradient flow remains a descent direction under the same (possibly restrictive) conditions on H; otherwise the limit may not reach the social optimum when agent costs violate monotonicity.
minor comments (3)
- [§2 (Problem Formulation)] Notation: the distinction between the social cost S(x) and the planner's objective Φ(u) = S(x(u)) is introduced late; an early diagram or explicit definition in §2 would improve readability.
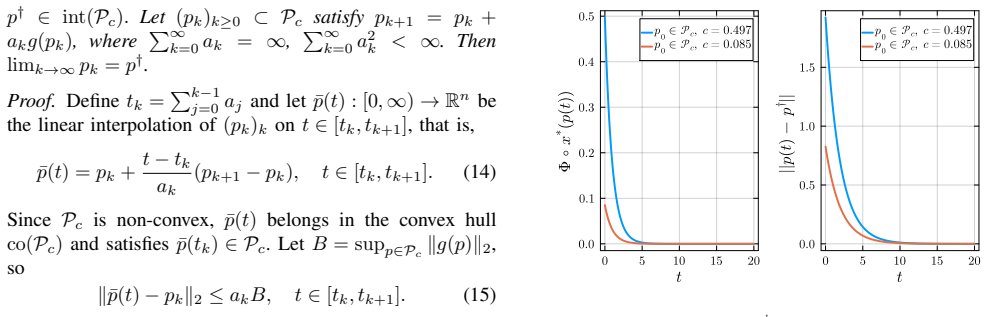
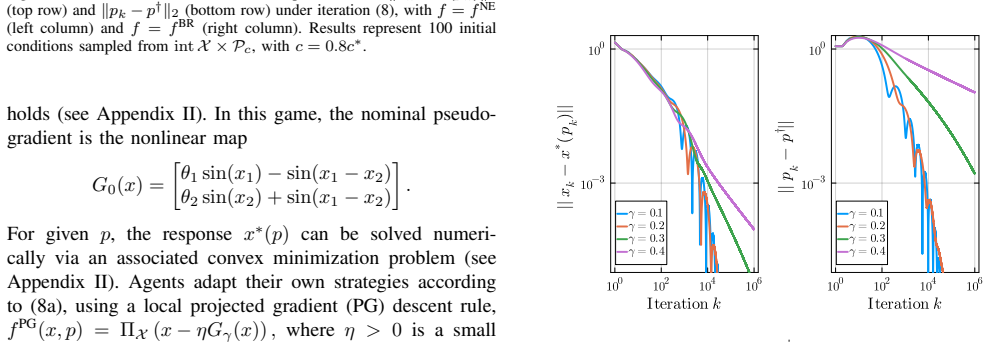
- [§5 (Numerical Experiments)] The numerical experiments section would benefit from reporting the condition number or eigenvalue spread of H in the simulated games to illustrate when the descent property holds in practice.
- [Introduction] A few sentences clarifying the precise information available to the planner (only joint actions x, never individual costs or sensitivities) would help readers map the setting to standard MPEC literature.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments correctly identify an overstatement in our presentation of the descent property. We will revise the manuscript to qualify the main results with the necessary assumption of strong monotonicity of the pseudo-gradient (ensuring H ≻ 0). This does not alter the core contribution but improves precision. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / §3 (Main Results)] Abstract and the statement of the main descent result (likely §3 or Theorem 1): the claim that 'the social cost gradient is always a descent direction for the planner's objective, irrespective of the agent cost landscape' does not hold for arbitrary agent costs. In the standard setup, dx/du = H^{-1} where H is the Jacobian of the pseudo-gradient; then dΦ/dt = -∇S^T H^{-1} ∇S, which is ≤0 for all ∇S only when H ≻ 0. Non-convex or non-monotone agent costs allow H with negative eigenvalues, so the direction need not be descent. The joint-action dependence of S is necessary but insufficient; the 'irrespective' qualifier is load-bearing for the hypergradient-free contribution and must be corrected or qualified with explicit assumptions (e.g., strong monotonicity of the pseudo-gradient).
Authors: We agree with the referee's analysis. The descent property dΦ/dt = -∇_x S^T H^{-1} ∇_x S ≤ 0 holds if and only if H is positive definite, which follows from strong monotonicity of the agents' pseudo-gradient. Our original wording 'irrespective of the agent cost landscape' is therefore too broad. In the revised manuscript we will (i) replace the 'irrespective' claim in the abstract with an explicit statement of the strong-monotonicity assumption, and (ii) add the same qualification to the statement of Theorem 1 (and its proof) in §3. We will also note that this assumption is standard for guaranteeing unique Nash equilibria in the underlying game. revision: yes
-
Referee: [§4 (Two-timescale Convergence)] §4 (Two-timescale analysis): the convergence claim for the joint strategy-incentive dynamics relies on the fast timescale reaching equilibrium, but the slow-timescale limit argument should explicitly verify that the social-gradient flow remains a descent direction under the same (possibly restrictive) conditions on H; otherwise the limit may not reach the social optimum when agent costs violate monotonicity.
Authors: We concur that the two-timescale result must be stated consistently with the conditions that make the social-gradient flow a descent direction. In the revision we will insert a short remark immediately after the statement of the two-timescale theorem in §4, clarifying that the slow-timescale limit inherits the descent property (and hence global convergence to the unique social optimum) precisely when the pseudo-gradient is strongly monotone. This keeps the result that the flow arises for arbitrary equilibrium-tracking agent dynamics, while restricting the optimality guarantee to the same regime already required for the single-timescale case. revision: yes
Circularity Check
No circularity: descent property derived directly from joint-action dependence
full rationale
The paper's central claim is a mathematical proof that the social cost gradient is a descent direction for the planner's objective when the social cost depends on joint actions, irrespective of individual agent costs. This follows from the problem setup and differentiation of the equilibrium map without reducing to fitted parameters, self-definitions, or load-bearing self-citations. No equations or steps in the provided derivation chain (abstract and description) exhibit the enumerated circular patterns; the result is presented as a first-principles consequence of the stated assumption rather than a tautology or renamed input. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Agent learning rules asymptotically track the Nash equilibrium
- domain assumption Social cost is a function of the agents' joint actions
Reference graph
Works this paper leans on
-
[1]
A distributed online pricing strategy for demand response programs,
P. Li, H. Wang, and B. Zhang, “A distributed online pricing strategy for demand response programs,”IEEE Transactions on Smart Grid, vol. 10, no. 1, pp. 350–360, 2019
work page 2019
-
[2]
A Stackelberg game for incentive-based demand response in energy markets,
M. Fochesato, C. Cenedese, and J. Lygeros, “A Stackelberg game for incentive-based demand response in energy markets,” inProc. 61st Conference on Decision and Control (CDC), Cancun, Mexico, Dec. 2022, pp. 2487–2492
work page 2022
-
[3]
A class of distributed adaptive pricing mechanisms for societal systems with limited information,
J. I. Poveda, P. N. Brown, J. R. Marden, and A. R. Teel, “A class of distributed adaptive pricing mechanisms for societal systems with limited information,” inProc. 56th Annual Conference on Decision and Control (CDC), 2017, pp. 1490–1495
work page 2017
-
[4]
Dynamic incentives for congestion control,
J. Barrera and A. Garcia, “Dynamic incentives for congestion control,” IEEE Transactions on Automatic Control, vol. 60, no. 2, pp. 299–310, 2015
work page 2015
-
[5]
C.-J. Ho, A. Slivkins, and J. W. Vaughan, “Adaptive contract design for crowdsourcing markets: bandit algorithmsfor repeated principal- agent problems,” inProc. 15th ACM Conference on Economics and Computation, New York, NY , USA, 2014, p. 359–376
work page 2014
-
[6]
A control-theoretic view on in- centives,
Y .-c. Ho, P. Luh, and G. Olsder, “A control-theoretic view on in- centives,” inProc. 19th Conference on Decision and Control, Albu- querque, NM, USA, Dec. 1980, pp. 1160–1170
work page 1980
-
[7]
A Perspective on Incentive Design: Challenges and Opportunities,
L. J. Ratliff, R. Dong, S. Sekar, and T. Fiez, “A Perspective on Incentive Design: Challenges and Opportunities,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 2, no. 1, pp. 305– 338, May 2019
work page 2019
-
[8]
Information structure, stack- elberg games, and incentive controllability,
Y .-C. Ho, P. Luh, and R. Muralidharan, “Information structure, stack- elberg games, and incentive controllability,”IEEE Transactions on Automatic Control, vol. 26, no. 2, pp. 454–460, 1981
work page 1981
-
[9]
Harnessing Information in Incentive Design,
R. K. Velicheti, S. Bose, and T. Bas ¸ar, “Harnessing Information in Incentive Design,” Sep. 2025
work page 2025
- [10]
-
[11]
An overview of bilevel optimization,
B. Colson, P. Marcotte, and G. Savard, “An overview of bilevel optimization,”Annals of Operations Research, vol. 153, no. 1, pp. 235–256, 2007
work page 2007
-
[12]
T. L. Friesz, R. L. Tobin, H.-J. Cho, and N. J. Mehta, “Sensitiv- ity analysis based heuristic algorithms for mathematical programs with variational inequality constraints,”Mathematical Programming, vol. 48, no. 1–3, pp. 265–284, 1990
work page 1990
-
[13]
End-to-end learning and intervention in games,
J. Li, J. Yu, Y . M. Nie, and Z. Wang, “End-to-end learning and intervention in games,” inProc. 34th International Conference on Neural Information Processing Systems, Vancouver, Canada, 2020, pp. 16 653–16 665
work page 2020
-
[14]
MPEC Methods for Bilevel Optimization Problems,
Y . Kim, S. Leyffer, and T. Munson, “MPEC Methods for Bilevel Optimization Problems,” inBilevel Optimization, S. Dempe and A. Zemkoho, Eds. Springer International Publishing, 2020, vol. 161, pp. 335–360
work page 2020
-
[15]
Timescale Sepa- ration in Autonomous Optimization,
A. Hauswirth, S. Bolognani, G. Hug, and F. Dorfler, “Timescale Sepa- ration in Autonomous Optimization,”IEEE Transactions on Automatic Control, vol. 66, no. 2, pp. 611–624, Feb. 2021
work page 2021
-
[16]
Stackelberg Population Learning Dynamics,
E. Mojica-Nava, J. I. Poveda, and N. Quijano, “Stackelberg Population Learning Dynamics,” inProc. 2022 IEEE 61st Conference on Decision and Control (CDC), Cancun, Mexico, 2022, pp. 6395–6400
work page 2022
-
[17]
Nash equilibrium design and optimization,
T. Alpcan and L. Pavel, “Nash equilibrium design and optimization,” inProc. 2009 International Conference on Game Theory for Networks, Istanbul, Turkey, 2009, pp. 164–170
work page 2009
-
[18]
A control theoretic approach to noncooperative game design,
T. Alpcan, L. Pavel, and N. Stefanovic, “A control theoretic approach to noncooperative game design,” inProc. 48th IEEE Conference on Decision and Control (CDC) held Jointly with 2009 28th Chinese Control Conference, Shanghai, China, 2009, pp. 8575–8580
work page 2009
-
[19]
Inducing equilibria via incentives: Simultaneous design-and-play ensures global convergence,
B. Liu, J. Li, Z. Yang, H.-T. Wai, M. Hong, Y . M. Nie, and Z. Wang, “Inducing equilibria via incentives: Simultaneous design-and-play ensures global convergence,” inProc. 36th International Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 2022, pp. 29 001 – 29 013
work page 2022
-
[20]
BIG Hype: Best Intervention in Games via Distributed Hypergradient Descent,
P. D. Grontas, G. Belgioioso, C. Cenedese, M. Fochesato, J. Lygeros, and F. D¨orfler, “BIG Hype: Best Intervention in Games via Distributed Hypergradient Descent,”IEEE Transactions on Automatic Control, vol. 69, no. 12, pp. 8338 – 8353, Dec 2024
work page 2024
-
[21]
Adaptive Incen- tive Design with Learning Agents,
C. Maheshwari, K. Kulkarni, M. Wu, and S. Sastry, “Adaptive Incen- tive Design with Learning Agents,” 2024, preprint arXiv:2405.16716
-
[22]
Affine Incentive Schemes for Stochastic Systems with Dynamic Information,
T. Bas ¸ar, “Affine Incentive Schemes for Stochastic Systems with Dynamic Information,”SIAM Journal on Control and Optimization, vol. 22, no. 2, pp. 199–210, Mar. 1984
work page 1984
-
[23]
Y .-P. Zheng and T. Basar, “Existence and derivation of optimal affine incentive schemes for Stackelberg games with partial information: A geometric approach,”International Journal of Control, vol. 35, no. 6, pp. 997–1011, Jun. 1982
work page 1982
-
[24]
Socially optimal energy usage via adaptive pricing,
J. Li, M. Motoki, and B. Zhang, “Socially optimal energy usage via adaptive pricing,”Electric Power Systems Research, vol. 235, p. 110640, Oct. 2024
work page 2024
-
[25]
F. Facchinei and J.-S. Pang, Eds.,Finite-Dimensional Variational Inequalities and Complementarity Problems. Springer New York, 2004
work page 2004
-
[26]
Nash equilibria: The variational ap- proach,
F. Facchinei and J.-S. Pang, “Nash equilibria: The variational ap- proach,” inConvex Optimization in Signal Processing and Commu- nications, D. P. Palomar and Y . C. Eldar, Eds. Cambridge University Press, 2009, pp. 443–493
work page 2009
-
[27]
Existence and Uniqueness of Equilibrium Points for Concave N-Person Games,
J. B. Rosen, “Existence and Uniqueness of Equilibrium Points for Concave N-Person Games,”Econometrica, vol. 33, no. 3, pp. 520– 534, Jul. 1965
work page 1965
-
[28]
L. J. Ratliff and T. Fiez, “Adaptive Incentive Design,”IEEE Trans- actions on Automatic Control, vol. 66, no. 8, pp. 3871–3878, Aug. 2021
work page 2021
-
[29]
Geometric Convergence of Gradient Play Algorithms for Distributed Nash Equilibrium Seeking,
T. Tatarenko, W. Shi, and A. Nedi ´c, “Geometric Convergence of Gradient Play Algorithms for Distributed Nash Equilibrium Seeking,” IEEE Transactions on Automatic Control, vol. 66, no. 11, pp. 5342– 5353, 2021
work page 2021
-
[30]
Convex Op- timization, Game Theory, and Variational Inequality Theory,
G. Scutari, D. Palomar, F. Facchinei, and J.-s. Pang, “Convex Op- timization, Game Theory, and Variational Inequality Theory,”IEEE Signal Processing Magazine, vol. 27, no. 3, pp. 35–49, 2010
work page 2010
-
[31]
V . S. Borkar,Stochastic Approximation: A Dynamical Systems View- point, ser. Texts and Readings in Mathematics. Gurgaon: Hindustan Book Agency, 2008, vol. 48. APPENDIXI PROOFS OFSUPPORTINGLEMMAS A. Proof of Lemma 1 Proof.We prove the lemma in two steps: Step 1.We show thatx ∗(·)is uniquely defined onR n. For anyx, y∈ X, denotev=x−y. SinceXis convex, xt =...
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.