Recognition: unknown
GPU Acceleration of Sparse Fully Homomorphic Encrypted DNNs
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
Sparse matrix multiplication on GPUs for fully homomorphic encrypted DNNs reduces complexity from cubic to semi-linear and outperforms CPU implementations by up to 3x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By exploiting sparsity in both operands of ciphertext matrix multiplication, the proposed GPU implementation achieves up to 3.0x better runtime than its CPU counterpart and reduces the time complexity of FHE matmul from cubic to semi-linear, providing a concrete improvement over prior FHE matrix-multiplication techniques.
What carries the argument
Sparse ciphertext matrix multiplication on GPUs that processes only the non-zero elements of both FHE operands inside the FIDESlib library.
If this is right
- Encrypted DNN inference can execute faster on commodity GPUs without decrypting intermediate values.
- The semi-linear complexity enables scaling encrypted models to larger layer widths than previously feasible on CPUs.
- FHE libraries can incorporate sparsity-aware kernels as a standard optimization for DNN workloads.
- Privacy-preserving machine learning becomes more practical for edge or cloud deployment where GPUs are available.
Where Pith is reading between the lines
- Similar sparsity exploitation could be applied to other linear algebra primitives inside FHE, such as convolutions.
- The technique may extend to other GPU vendors if the underlying FHE library is ported.
- Lower latency for encrypted inference could encourage adoption in regulated domains such as healthcare or finance.
Load-bearing premise
The matrix multiplications inside FHE-based DNNs contain enough sparsity in the ciphertexts to deliver the claimed complexity reduction and speedup while preserving correctness and security.
What would settle it
Run the same sparse matmul kernel on representative FHE DNN layers with measured sparsity below 50 percent and check whether the observed speedup drops below 1.5x or the complexity reverts to cubic scaling.
Figures



read the original abstract
Fully homomorphic encryption (FHE) has recently attracted significant attention as both a cryptographic primitive and a systems challenge. Given the latest advances in accelerated computing, FHE presents a promising opportunity for progress, with applications ranging from machine learning to information security. We target the most computationally intensive operation in deep neural networks from a hardware perspective, matrix multiplication (matmul), and adapt it for execution on AMD GPUs. We propose a new optimized method that improves the runtime and complexity of ciphertext matmul by using FIDESlib, a recent open-source FHE library designed specifically for GPUs. By exploiting sparsity in both operands, our sparse matmul implementation outperforms its CPU counterpart by up to $3.0\times$ and reduces the time complexity from cubic to semi-linear, demonstrating an improvement over existing FHE matmul implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a GPU-accelerated sparse matrix multiplication method for fully homomorphic encrypted (FHE) deep neural networks, implemented on AMD GPUs using the open-source FIDESlib library. It claims that exploiting sparsity in both operands yields up to 3.0× speedup over CPU implementations and reduces ciphertext matmul time complexity from cubic to semi-linear, improving on prior FHE matmul approaches.
Significance. If the claimed speedups and complexity reduction are rigorously demonstrated with detailed algorithms and experiments, the work would be significant for practical FHE-based machine learning, as it targets the core computational bottleneck of encrypted DNN inference through hardware acceleration and sparsity. The reliance on an open-source GPU FHE library supports reproducibility in systems cryptography research.
major comments (2)
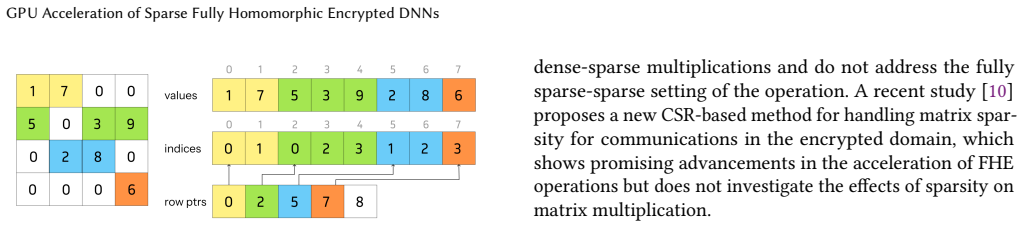
- [Abstract] Abstract: The central claim that exploiting sparsity in both operands reduces time complexity from cubic to semi-linear is load-bearing but unsupported; the text supplies no sparsity ratios for DNN weights/activations, no pseudocode or equations for the sparse ciphertext matmul, and no analysis of how zero positions are identified and skipped in the encrypted domain while preserving FHE correctness and security (see skeptic note on unquantified sparsity exploitation).
- [Abstract] Abstract and full text: No experimental methodology, baseline comparisons (e.g., dense FHE matmul or other GPU FHE libraries), error analysis, or verification is provided to confirm that the reported 3.0× speedup and complexity improvement derive from the described sparsity method rather than unstated optimizations or implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each point below and will revise the manuscript accordingly to strengthen the presentation of our claims and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that exploiting sparsity in both operands reduces time complexity from cubic to semi-linear is load-bearing but unsupported; the text supplies no sparsity ratios for DNN weights/activations, no pseudocode or equations for the sparse ciphertext matmul, and no analysis of how zero positions are identified and skipped in the encrypted domain while preserving FHE correctness and security (see skeptic note on unquantified sparsity exploitation).
Authors: We agree the claim requires explicit support. In the revision we will add typical DNN sparsity ratios (e.g., 70-90% zero weights after pruning), pseudocode and equations for the sparse matmul kernel in FIDESlib, and a complexity analysis. Zero positions are identified from known plaintext weights (one operand); corresponding ciphertext multiplications are omitted, which is equivalent and leaks no information, preserving FHE correctness and security. This yields the stated semi-linear scaling in the number of non-zeros. revision: yes
-
Referee: [Abstract] Abstract and full text: No experimental methodology, baseline comparisons (e.g., dense FHE matmul or other GPU FHE libraries), error analysis, or verification is provided to confirm that the reported 3.0× speedup and complexity improvement derive from the described sparsity method rather than unstated optimizations or implementation details.
Authors: We acknowledge the need for fuller experimental rigor. The revision will include a dedicated methodology section, direct comparisons against dense FHE matmul (CPU and GPU) and other libraries, noise/error analysis confirming equivalence to dense results, and ablation studies isolating the contribution of sparsity to the observed 3.0× speedup. revision: yes
Circularity Check
No circularity: performance claims derive from implementation and benchmarking
full rationale
The paper presents an empirical systems contribution: a GPU-accelerated sparse ciphertext matrix multiplication for FHE DNNs built on FIDESlib. The claimed 3.0× speedup and reduction from cubic to semi-linear complexity are stated as direct outcomes of the implemented algorithm that exploits sparsity in both operands. No equations, parameters, or predictions are fitted to target results and then re-presented as independent derivations; no self-citations supply load-bearing uniqueness theorems or ansatzes; and no renaming of known patterns occurs. The derivation chain is therefore self-contained in the described implementation and its measured behavior, which remains externally verifiable through code and benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption FHE schemes maintain semantic security and correct decryption after operations
- domain assumption Matrix operands in encrypted DNNs contain sufficient zero entries to yield semi-linear complexity
Reference graph
Works this paper leans on
-
[1]
2023.On Architecting Fully Homo- morphic Encryption-based Computing Systems
Rashmi Agrawal and Ajay Joshi. 2023.On Architecting Fully Homo- morphic Encryption-based Computing Systems. Springer Cham
2023
- [2]
- [3]
-
[4]
Ahmad Al Badawi, Jack Bates, Flavio Bergamaschi, David Bruce Cousins, Saroja Erabelli, Nicholas Genise, Shai Halevi, Hamish Hunt, Andrey Kim, Yongwoo Lee, Zeyu Liu, Daniele Micciancio, Ian Quah, Yuriy Polyakov, Saraswathy R.V., Kurt Rohloff, Jonathan Saylor, Dmitriy Suponitsky, Matthew Triplett, Vinod Vaikuntanathan, and Vincent Zucca. 2022. OpenFHE: Open...
2022
-
[5]
Pedro Alves, Jheyne Ortiz, and Diego Aranha. 2023. Performance of hierarchical transforms in homomorphic encryption: a case study on logistic regression inference.J. of Cryptographic Engineering(2023)
2023
-
[6]
Zvika Brakerski, Craig Gentry, and Vinod Vaikuntanathan. 2014. (Lev- eled) Fully Homomorphic Encryption without Bootstrapping.ACM Trans. Comput. Theory6, 3, Article 13 (July 2014), 36 pages
2014
-
[7]
Liu, Hao Wang, and Cheng Hong
Chaochao Chen, Jun Zhou, Li Wang, Xibin Wu, Wenjing Fang, Jin Tan, Lei Wang, Alex X. Liu, Hao Wang, and Cheng Hong. 2021. When Homomorphic Encryption Marries Secret Sharing: Secure Large-Scale Sparse Logistic Regression and Applications in Risk Control. In27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining
2021
-
[8]
Xiaofeng Chen, Xinyi Huang, Jin Li, Jianfeng Ma, Wenjing Lou, and Duncan S. Wong. 2015. New Algorithms for Secure Outsourcing of Large-Scale Systems of Linear Equations.IEEE Transactions on Information Forensics and Security10, 1 (2015), 69–78
2015
-
[9]
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. 2017. Homomorphic Encryption for Arithmetic of Approximate Numbers. InAdvances in Cryptology – ASIACRYPT 2017. 409–437
2017
-
[10]
Moontaha Nishat Chowdhury, André Bauer, and Minxuan Zhou. 2025. Efficient Privacy-Preserving Recommendation on Sparse Data using Fully Homomorphic Encryption. In2025 IEEE International Conference on eScience (eScience). 1–9
2025
-
[11]
Jinming Cui, Chaochao Chen, Lingjuan Lyu, Carl Yang, and Wang Li
-
[12]
InAdvances in Neural Information Processing Systems
Exploiting Data Sparsity in Secure Cross-Platform Social Rec- ommendation. InAdvances in Neural Information Processing Systems
-
[13]
Junfeng Fan and Frederik Vercauteren. 2012. Somewhat Practical Fully Homomorphic Encryption. Cryptology Archive, 2012/144
2012
-
[14]
Shengyu Fan, Zhiwei Wang, Weizhi Xu, Rui Hou, Dan Meng, and Mingzhe Zhang. 2023. TensorFHE: Achieving Practical Computation on Encrypted Data Using GPGPU. In2023 IEEE International Sympo- sium on High-Performance Computer Architecture (HPCA). 922–934
2023
-
[15]
Aidan Ferguson, Perry Gibson, Lara D’Agata, Parker McLeod, Ferhat Yaman, Amitabh Das, Ian Colbert, and José Cano. 2025. Exploiting Unstructured Sparsity in Fully Homomorphic Encrypted DNNs. In5th Workshop on Machine Learning and Systems (EuroMLSys ’25). 31–38
2025
-
[16]
Craig Gentry. 2010. Computing arbitrary functions of encrypted data. Commun. ACM53, 3 (March 2010), 97–105
2010
-
[17]
Perry Gibson, Jose Cano, Elliot Crowley, Amos Storkey, and Michael O’boyle. 2025. DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration.ACM Trans. Archit. Code Optim.(2025)
2025
-
[18]
Shai Halevi and Victor Shoup. 2015. Bootstrapping for HElib. InAd- vances in Cryptology – EUROCRYPT 2015. Springer Berlin Heidelberg
2015
- [19]
-
[20]
Ming-Chien Ho, Yu-Te Ku, Yu Xiao, Feng-Hao Liu, Chih-Fan Hsu, Ming-Ching Chang, Shih-Hao Hung, and Wei-Chao Chen. 2025. In- vited Paper: Efficient Design of FHEW/TFHE Bootstrapping Imple- mentation with Scalable Parameters. In43rd IEEE/ACM International Conference on Computer-Aided Design
2025
-
[21]
Hengyuan Hu, Rui Peng, Yu-Wing Tai, and Chi-Keung Tang. 2016. Net- work Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures. arXiv:1607.03250
work page Pith review arXiv 2016
-
[22]
Elmira Karimi, Nicolas Bohm Agostini, Shi Dong, and David Kaeli
-
[23]
Parallel Distrib
VCSR: An Efficient GPU Memory-Aware Sparse Format.IEEE Trans. Parallel Distrib. Syst.33, 12 (Dec. 2022), 3977–3989
2022
- [24]
-
[25]
Abellán, Manuel E
Francisco Muñoz Martínez, Raveesh Garg, Michael Pellauer, José L. Abellán, Manuel E. Acacio, and Tushar Krishna. 2023. Flexagon: A Multi-dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing. In28th ACM Int. Conference on Architectural Support for Programming Languages and Operating Systems
2023
- [26]
-
[27]
T Thammi Reddy, Silpakesav Velagaleti, BVV Satyanarayana, and G Prasanna Kumar. 2025. Hardware efficient arithmetic reconfigurable fully homomorphic encryption (ARFHE) accelerator of low power IoT based RISC-V processor.Analog Integrated Circuits and Signal Processing124, 1 (2025), 20
2025
-
[28]
Abellán, John Kim, Ajay Joshi, and David Kaeli
Kaustubh Shivdikar, Yuhui Bao, Rashmi Agrawal, Michael Shen, Gilbert Jonatan, Evelio Mora, Alexander Ingare, Neal Livesay, José L. Abellán, John Kim, Ajay Joshi, and David Kaeli. 2023. GME: GPU-based Microarchitectural Extensions to Accelerate Homomorphic Encryp- tion. In56th Annual IEEE/ACM International Symposium on Microar- chitecture
2023
-
[29]
Emmanuel Vintimilla-Tapia, Alexander Rojas, Marco Sigüenza, An- drea Paulina Rodríguez Zúñiga, and Priscila Cedillo. 2026. A Sys- tematic Literature Review on the Security Weaknesses of Fully Ho- momorphic Encryption Schemes. InInformation and Communication Technologies. Springer Nature Switzerland, Cham, 312–328
2026
-
[30]
Qingfeng Wang and Li-Ping Wang. 2025. A Novel Asymmetric BSGS Polynomial Evaluation Algorithm under Homomorphic Encryption. In 20th ACM Asia Conference on Computer and Communications Security
2025
-
[31]
Yannan Nellie Wu, Po-An Tsai, Saurav Muralidharan, Angshuman Parashar, Vivienne Sze, and Joel Emer. 2023. HighLight: Efficient and Flexible DNN Acceleration with Hierarchical Structured Sparsity. In 56th Annual IEEE/ACM International Symposium on Microarchitecture
2023
-
[32]
Weizhi Xu, Yintai Sun, Shengyu Fan, Hui Yu, and Xin Fu. 2023. Ac- celerating Convolutional Neural Network by Exploiting Sparsity on GPUs.ACM Trans. Archit. Code Optim.20, 3, Article 36 (July 2023)
2023
-
[33]
Keren Zhou, Karthik Ganapathi Subramanian, Po-Hsun Lin, Matthias Fey, Binqian Yin, and Jiajia Li. 2024. FASTEN: Fast GPU-accelerated Segmented Matrix Multiplication for Heterogenous Graph Neural Networks. In38th ACM International Conference on Supercomputing
2024
-
[34]
Ali Şah Özcan and Erkay Savaş. 2024. HEonGPU: a GPU-based Fully Homomorphic Encryption Library 1.0. Cryptology Archive, 2024/1543
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.