Recognition: unknown
Leveraging Weighted Syntactic and Semantic Context Assessment Summary (wSSAS) Towards Text Categorization Using LLMs
Pith reviewed 2026-05-10 15:07 UTC · model grok-4.3
The pith
wSSAS provides a deterministic framework using hierarchical text organization and SNR scoring to enhance LLM-based text categorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that wSSAS, through its two-phased approach of hierarchical classification followed by SNR-based feature prioritization within a Summary-of-Summaries architecture, effectively isolates essential information from background noise, thereby improving clustering integrity, categorization accuracy, and reducing entropy in LLM-driven text analysis.
What carries the argument
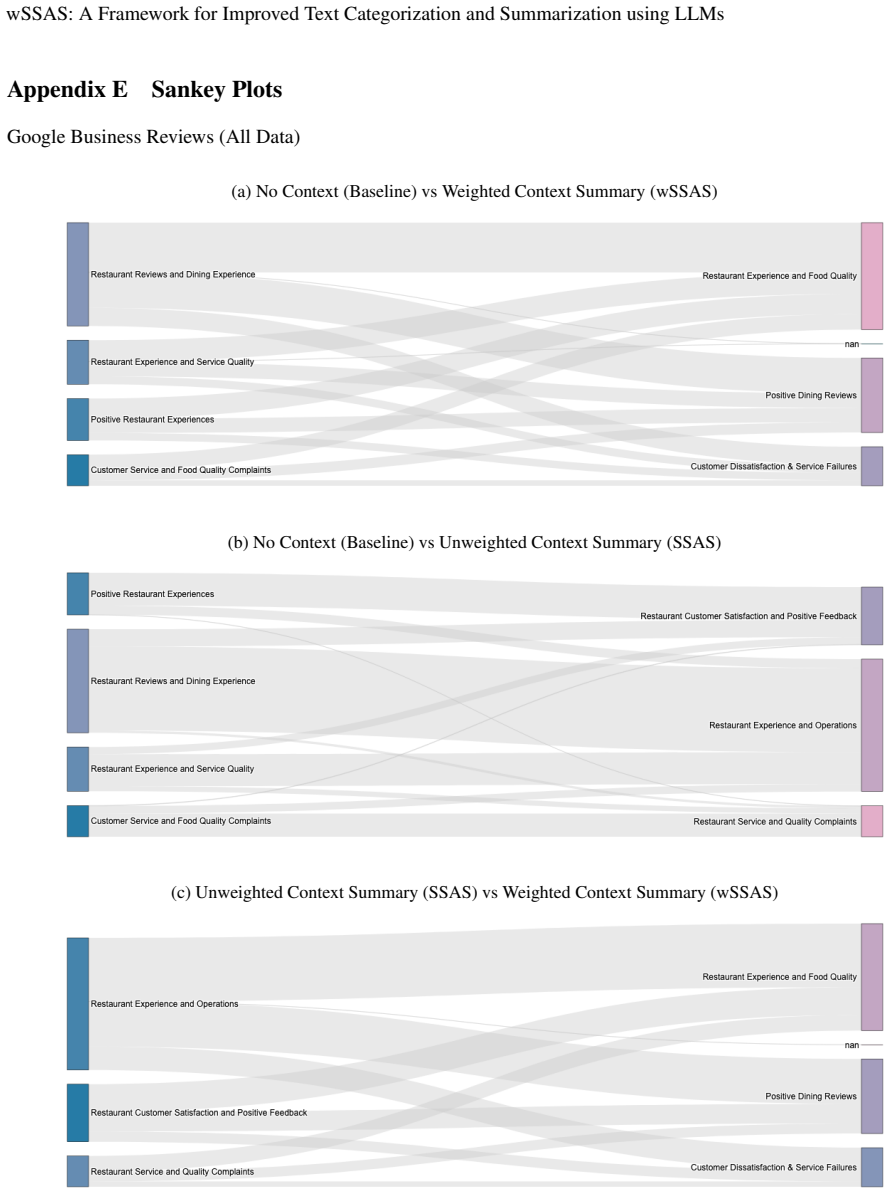
The wSSAS framework, which uses a hierarchical structure of Themes, Stories, and Clusters combined with Signal-to-Noise Ratio scoring to prioritize high-value semantic features for deterministic summarization.
If this is right
- Clustering integrity and categorization accuracy increase when applied to large review datasets.
- Categorization entropy decreases, supporting more consistent LLM outputs.
- The process becomes more reproducible for enterprise-scale text categorization tasks.
- Model attention stays focused on the most representative data points rather than noise.
Where Pith is reading between the lines
- This could be extended to other LLM tasks involving classification or summarization to achieve greater output stability.
- Integration with different underlying models might show varying degrees of improvement depending on their inherent stochasticity.
- Applying the method to real-time streaming text data could test its scalability beyond static datasets.
- The hierarchical organization might reveal latent structures in text that standard clustering misses.
Load-bearing premise
The proposed hierarchical organization combined with SNR scoring reliably enforces determinism and isolates essential information without introducing selection bias or discarding context that the LLM would use productively.
What would settle it
If applying wSSAS to the same diverse datasets yields no measurable gains in clustering integrity, categorization accuracy, or entropy reduction compared to direct LLM use, the central claims would be falsified.
Figures






read the original abstract
The use of Large Language Models (LLMs) for reliable, enterprise-grade analytics such as text categorization is often hindered by the stochastic nature of attention mechanisms and sensitivity to noise that compromise their analytical precision and reproducibility. To address these technical frictions, this paper introduces the Weighted Syntactic and Semantic Context Assessment Summary (wSSAS), a deterministic framework designed to enforce data integrity on large-scale, chaotic datasets. We propose a two-phased validation framework that first organizes raw text into a hierarchical classification structure containing Themes, Stories, and Clusters. It then leverages a Signal-to-Noise Ratio (SNR) to prioritize high-value semantic features, ensuring the model's attention remains focused on the most representative data points. By incorporating this scoring mechanism into a Summary-of-Summaries (SoS) architecture, the framework effectively isolates essential information and mitigates background noise during data aggregation. Experimental results using Gemini 2.0 Flash Lite across diverse datasets - including Google Business reviews, Amazon Product reviews, and Goodreads Book reviews - demonstrate that wSSAS significantly improves clustering integrity and categorization accuracy. Our findings indicate that wSSAS reduces categorization entropy and provides a reproducible pathway for improving LLM based summaries based on a high-precision, deterministic process for large-scale text categorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Weighted Syntactic and Semantic Context Assessment Summary (wSSAS), a two-phased deterministic framework for LLM-based text categorization. The first phase hierarchically organizes raw text into Themes, Stories, and Clusters; the second applies Signal-to-Noise Ratio (SNR) scoring to prioritize semantic features before aggregation via a Summary-of-Summaries (SoS) architecture. Experiments using Gemini 2.0 Flash Lite on Google Business reviews, Amazon Product reviews, and Goodreads Book reviews are reported to demonstrate improved clustering integrity, higher categorization accuracy, reduced entropy, and a reproducible deterministic process for large-scale tasks.
Significance. If the determinism and performance gains can be substantiated, the work would address a practical barrier to deploying LLMs in enterprise analytics by reducing sensitivity to stochastic attention and noise. A validated method for enforcing reproducibility in hierarchical summarization and categorization could be useful for high-stakes text processing pipelines.
major comments (3)
- [Abstract] Abstract: the central empirical claim of 'significant improvements in clustering integrity and categorization accuracy' and 'reduced categorization entropy' is asserted without any reported quantitative metrics, baselines, statistical tests, ablation studies, or description of how determinism was measured or enforced, so the claim cannot be evaluated.
- [Framework description] Framework description (two-phased validation): the claim of a 'high-precision, deterministic process' relies on LLMs (Gemini 2.0 Flash Lite) for hierarchical organization and feature prioritization, yet no controls such as temperature=0, fixed seeds, or non-LLM deterministic algorithms are specified; this is load-bearing for the reproducibility assertion.
- [Methods] Methods / wSSAS definition: the weighting coefficients and SNR threshold/scaling factor are free parameters whose concrete values and selection procedure are not stated, making it impossible to determine whether reported gains are independent of these choices or artifacts of tuning.
minor comments (2)
- The SNR scoring and SoS aggregation steps would benefit from explicit equations or pseudocode to clarify the computation of weights and noise isolation.
- Dataset descriptions and preprocessing steps are referenced but lack sufficient detail on size, labeling, and any preprocessing that could affect clustering integrity.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review, which highlights important areas for strengthening the manuscript's clarity and rigor. We address each major comment below and commit to revisions that will make the empirical claims, determinism controls, and parameter details fully evaluable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim of 'significant improvements in clustering integrity and categorization accuracy' and 'reduced categorization entropy' is asserted without any reported quantitative metrics, baselines, statistical tests, ablation studies, or description of how determinism was measured or enforced, so the claim cannot be evaluated.
Authors: We agree that the abstract would be stronger with explicit quantitative support. The manuscript body reports experimental outcomes on the three review datasets, but we will revise the abstract to include specific metrics (e.g., accuracy gains and entropy reductions relative to baselines), mention the use of statistical tests, and briefly note how determinism is measured and enforced. Ablation results will also be highlighted in the revised abstract where space permits. revision: yes
-
Referee: [Framework description] Framework description (two-phased validation): the claim of a 'high-precision, deterministic process' relies on LLMs (Gemini 2.0 Flash Lite) for hierarchical organization and feature prioritization, yet no controls such as temperature=0, fixed seeds, or non-LLM deterministic algorithms are specified; this is load-bearing for the reproducibility assertion.
Authors: We accept that explicit controls are required to substantiate the determinism claim. In the revised manuscript we will specify the exact configuration of Gemini 2.0 Flash Lite, including temperature set to 0 and fixed seeds for any non-deterministic operations. We will also add a short discussion of how these settings, combined with the deterministic SNR-based prioritization step, produce reproducible outputs across runs. revision: yes
-
Referee: [Methods] Methods / wSSAS definition: the weighting coefficients and SNR threshold/scaling factor are free parameters whose concrete values and selection procedure are not stated, making it impossible to determine whether reported gains are independent of these choices or artifacts of tuning.
Authors: We acknowledge the need for full transparency on these hyperparameters. The revised Methods section will include a new subsection that states the concrete values chosen for the weighting coefficients, SNR threshold, and scaling factor, together with the selection procedure (empirical tuning on a held-out validation subset of each dataset). This will allow readers to assess whether the gains are robust to these choices. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces wSSAS as a descriptive two-phased framework (hierarchical Themes/Stories/Clusters organization followed by SNR scoring and SoS aggregation) and reports experimental outcomes on clustering integrity and entropy reduction using Gemini 2.0 Flash Lite. No equations, parameter-fitting procedures, self-citations, or uniqueness theorems are referenced that would reduce any claimed result to its own inputs by construction. The determinism assertion is presented as a design goal rather than a derived quantity, and the experimental claims rest on external dataset evaluations rather than tautological re-labeling of fitted values.
Axiom & Free-Parameter Ledger
free parameters (2)
- wSSAS weighting coefficients
- SNR threshold or scaling factor
axioms (1)
- domain assumption LLM attention mechanisms can be made effectively deterministic through external hierarchical structuring and SNR-based feature selection.
invented entities (1)
-
wSSAS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Manning, Prabhakar Raghavan, and Hinrich Schütze
Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze. Introduction to Information Retrieval. URL: https://nlp.stanford.edu/IR-book/
-
[2]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Lit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2020
-
[3]
Can llm-generated misinformation be detected?arXiv preprint arXiv:2309.13788, 2023
Canyu Chen and Kai Shu. Can LLM-Generated Misinformation Be Detected?, April 2024. arXiv:2309.13788 [cs]. URL:http://arxiv.org/abs/2309.13788,doi:10.48550/arXiv.2309.13788
-
[4]
Elias Hossain, Rajib Rana, Niall Higgins, Jeffrey Soar, Prabal Datta Barua, Anthony R. Pisani, and Kathryn Turner. Natural Language Processing in Electronic Health Records in relation to healthcare decision-making: A systematic review.Computers in Biology and Medicine, 155:106649, March 2023. URL: https://www.sciencedirect. com/science/article/pii/S001048...
-
[5]
Large lan- guage models are few-shot clinical information extractors
Monica Agrawal, Stefan Hegselmann, Hunter Lang, Yoon Kim, and David Sontag. Large language models are few-shot clinical information extractors. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1998– 2022, Abu Dhabi, United Arab Emirates, December 2022...
-
[6]
Calibrate Before Use: Improving Few-shot Performance of Language Models
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. Calibrate Before Use: Improving Few-shot Performance of Language Models. InProceedings of the 38th International Conference on Machine Learning, pages 12697–12706. PMLR, July 2021. URL:https://proceedings.mlr.press/v139/zhao21c.html
2021
-
[7]
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A Survey on In-context Learning, October 2024. arXiv:2301.00234 [cs]. URL:http://arxiv.org/abs/2301.00234,doi:10.48550/arXiv.2301.00234
work page internal anchor Pith review doi:10.48550/arxiv.2301.00234 2024
-
[8]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amand...
work page internal anchor Pith review doi:10.48550/arxiv.2206.04615 2023
-
[9]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, August 2023. arXiv:1706.03762 [cs]. URL: http://arxiv.org/ abs/1706.03762,doi:10.48550/arXiv.1706.03762
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762 2023
-
[10]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, pages 610–623, New York, NY , USA, March
2021
-
[11]
Association for Computing Machinery. URL: https://dl.acm.org/doi/10.1145/3442188.3445922, doi:10.1145/3442188.3445922
-
[12]
Chi, Nathanael Schärli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large Language Models Can Be Easily Distracted by Irrelevant Context. InProceedings of the 40th International Conference on Machine Learning, pages 31210–31227. PMLR, July 2023. URL: https: //proceedings.mlr.press/v202/shi23a.html
2023
-
[13]
Andrew Kreek and Emilia Apostolova
R. Andrew Kreek and Emilia Apostolova. Training and Prediction Data Discrepancies: Challenges of Text Classification with Noisy, Historical Data. In Wei Xu, Alan Ritter, Tim Baldwin, and Afshin Rahimi, editors, Proceedings of the 2018 EMNLP Workshop W-NUT: The 4th Workshop on Noisy User-generated Text, pages 104–109, Brussels, Belgium, November 2018. Asso...
-
[14]
Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing.ACM Comput. Surv., 15 wSSAS: A Framework for Improved Text Categorization and Summarization using LLMs 55(9):195:1–195:35, January 2023. URL: https://dl.acm.org/doi...
-
[15]
Syntactic and Semantic Attention Summary (SSAS): An Approach to Improve LLM Summary Generation, October 2024
Nitin Mayande, Sharookh Daruwalla, Sumedh Khodke, Nitin Joglekar, and Charles Weber. Syntactic and Semantic Attention Summary (SSAS): An Approach to Improve LLM Summary Generation, October 2024
2024
-
[16]
Leveraging Weighted Syntactic and Semantic Attention Summary (wSSAS) Towards Text Categorization Using LLMs, October 2025
Nitin Mayande, Sharookh Daruwalla, Shreeya Verma Kathuria, Nitin Joglekar, and Weber Charles. Leveraging Weighted Syntactic and Semantic Attention Summary (wSSAS) Towards Text Categorization Using LLMs, October 2025
2025
-
[17]
Deep Learning and the Information Bottleneck Principle
Naftali Tishby and Noga Zaslavsky. Deep Learning and the Information Bottleneck Principle, March 2015. arXiv:1503.02406 [cs]. URL:http://arxiv.org/abs/1503.02406,doi:10.48550/arXiv.1503.02406
-
[18]
Davenport and Nitin Mittal.All-in On AI: How Smart Companies Win Big with Artificial Intelligence
Thomas H. Davenport and Nitin Mittal.All-in On AI: How Smart Companies Win Big with Artificial Intelligence. January 2023
2023
-
[19]
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection, March 2023
Jiawei Ma, Yulei Niu, Jincheng Xu, Shiyuan Huang, Guangxing Han, and Shih-Fu Chang. DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection, March 2023. arXiv:2303.09674 [cs]. URL:http://arxiv.org/abs/2303.09674,doi:10.48550/arXiv.2303.09674
-
[20]
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. MetaICL: Learning to Learn In Context, May 2022. arXiv:2110.15943 [cs]. URL: http://arxiv.org/abs/2110.15943, doi:10.48550/arXiv. 2110.15943
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[21]
A review on the attention mechanism of deep learning , journal =
Zhaoyang Niu, Guoqiang Zhong, and Hui Yu. A review on the attention mechanism of deep learning.Neuro- computing, 452:48–62, September 2021. URL: https://www.sciencedirect.com/science/article/pii/ S092523122100477X,doi:10.1016/j.neucom.2021.03.091
-
[22]
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation, June 2024
Tejpalsingh Siledar, Swaroop Nath, Sankara Sri Raghava Ravindra Muddu, Rupasai Rangaraju, Swaprava Nath, Pushpak Bhattacharyya, Suman Banerjee, Amey Patil, Sudhanshu Shekhar Singh, Muthusamy Chelliah, and Nikesh Garera. One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation, June 2024. arXiv:2402.11683 [cs]. URL:http://arxiv.org/abs/2402.11683,d...
-
[23]
arXiv preprint arXiv:2308.15022 , year=
Qingyue Wang, Yanhe Fu, Yanan Cao, Shuai Wang, Zhiliang Tian, and Liang Ding. Recursively Summarizing Enables Long-Term Dialogue Memory in Large Language Models, August 2025. arXiv:2308.15022 [cs]. URL: http://arxiv.org/abs/2308.15022,doi:10.48550/arXiv.2308.15022
-
[24]
SangHun Im, GiBaeg Kim, Heung-Seon Oh, Seongung Jo, and Dong Hwan Kim. Hierarchical Text Classifi- cation as Sub-hierarchy Sequence Generation.Proceedings of the AAAI Conference on Artificial Intelligence, 37(11):12933–12941, June 2023. URL: https://ojs.aaai.org/index.php/AAAI/article/view/26520, doi:10.1609/aaai.v37i11.26520
-
[25]
Hierarchical Summarization: Scaling Up Multi-Document Summarization
Janara Christensen, Stephen Soderland, Gagan Bansal, and Mausam. Hierarchical Summarization: Scaling Up Multi-Document Summarization. In Kristina Toutanova and Hua Wu, editors,Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 902–912, Baltimore, Maryland, June 2014. Association for Compu...
-
[26]
Structural Sentence Similarity Estimation for Short Texts
Weicheng Ma and Torsten Suel. Structural Sentence Similarity Estimation for Short Texts. URL: https: //aaai.org/papers/232-flairs-2016-12940/
2016
-
[27]
Martin.Speech and Language Processing
Daniel Jurafsky and James H. Martin.Speech and Language Processing. Pearson Education, December 2014. Google-Books-ID: Cq2gBwAAQBAJ
2014
-
[28]
Chengyu Nan. Semantic Map and HBV in English, Chinese and Korean—A Case Study of hand,Shou and Son.Journal of Language Teaching and Research, 7(6):1216, November 2016. URL: http://www. academypublication.com/issues2/jltr/vol07/06/21.pdf,doi:10.17507/jltr.0706.21
-
[29]
Recent Trends in Named Entity Recognition (NER), January 2021
Arya Roy. Recent Trends in Named Entity Recognition (NER), January 2021. arXiv:2101.11420 [cs]. URL: http://arxiv.org/abs/2101.11420,doi:10.48550/arXiv.2101.11420
-
[30]
Hamed Jelodar, Yongli Wang, Chi Yuan, Xia Feng, Xiahui Jiang, Yanchao Li, and Liang Zhao. Latent Dirichlet allocation (LDA) and topic modeling: models, applications, a survey.Multimedia Tools Appl., 78(11):15169– 15211, June 2019.doi:10.1007/s11042-018-6894-4
-
[31]
Topic Discovery for Short Texts Using Word Embeddings
Guangxu Xun, Vishrawas Gopalakrishnan, Fenglong Ma, Yaliang Li, Jing Gao, and Aidong Zhang. Topic Discovery for Short Texts Using Word Embeddings. pages 1299–1304, December 2016. doi:10.1109/ICDM. 2016.0176
-
[32]
Robert Desimone and John Duncan. Neural Mechanisms of Selective Visual Attention.Annual Review of Neu- roscience, 18(V olume 18, 1995):193–222, March 1995. URL:https://www.annualreviews.org/content/ journals/10.1146/annurev.ne.18.030195.001205,doi:10.1146/annurev.ne.18.030195.001205. 16 wSSAS: A Framework for Improved Text Categorization and Summarization...
-
[33]
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S. Ryoo, and Tsung-Yu Lin. Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs, April 2024. arXiv:2404.07449 [cs]. URL: http://arxiv.org/abs/2404.07449,doi:10.48550/arXiv.2404.07449
-
[34]
Generative Question Answering: Learning to Answer the Whole Question
Mike Lewis and Angela Fan. Generative Question Answering: Learning to Answer the Whole Question. September
-
[35]
URL:https://openreview.net/forum?id=Bkx0RjA9tX
-
[36]
Efficient Estimation of Word Representations in Vector Space
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space, September 2013. arXiv:1301.3781 [cs]. URL: http://arxiv.org/abs/1301.3781, doi: 10.48550/arXiv.1301.3781
work page internal anchor Pith review doi:10.48550/arxiv.1301.3781 2013
-
[37]
Barbara H. Partee. Lexical Semantics and Compositionality. 1995. URL: https://direct.mit.edu/books/ edited-volume/4671/chapter/214107/Lexical-Semantics-and-Compositionality , doi:10.7551/ mitpress/3964.001.0001
1995
-
[38]
arXiv preprint arXiv:2310.06201 , year=
Yucheng Li, Bo Dong, Chenghua Lin, and Frank Guerin. Compressing Context to Enhance Inference Efficiency of Large Language Models, October 2023. arXiv:2310.06201 [cs]. URL: http://arxiv.org/abs/2310.06201, doi:10.48550/arXiv.2310.06201
-
[39]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalk- wyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[40]
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL: https: //aclanthology.org/W04-1013/
2004
-
[41]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG Eval- uation using Gpt-4 with Better Human Alignment. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, Singapore, December 2023. Association for Computation...
-
[42]
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Computa...
-
[43]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, ...
-
[44]
Peter J. Rousseeuw. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis.Journal of Computational and Applied Mathematics, 20:53–65, November 1987. URL: https://www.sciencedirect. com/science/article/pii/0377042787901257,doi:10.1016/0377-0427(87)90125-7
-
[45]
IEEE Transactions on Pattern Analysis and Machine Intelligence PAMI-1(2), 224-227 (1979)
David L. Davies and Donald W. Bouldin. A Cluster Separation Measure.IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-1(2):224–227, April 1979. URL: https://ieeexplore.ieee.org/ document/4766909,doi:10.1109/TPAMI.1979.4766909
-
[46]
T. Cali´nski and J Harabasz. A dendrite method for cluster analysis.Communications in Statistics, 3(1):1–27, January 1974. _eprint: https://doi.org/10.1080/03610927408827101.doi:10.1080/03610927408827101. 20 wSSAS: A Framework for Improved Text Categorization and Summarization using LLMs
work page doi:10.1080/03610927408827101.doi:10.1080/03610927408827101 1974
-
[47]
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (...
-
[48]
Lower scores indicate better separation between thematic groups
Davies-Bouldin Index:Measures the average similarity between clusters. Lower scores indicate better separation between thematic groups
-
[49]
Calinski-Harabasz (CH) Index:Evaluates the ratio of between-cluster dispersion to within-cluster dispersion (the Variance Ratio Criterion). 36
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.