Recognition: 2 theorem links
· Lean TheoremA Domain-Specific Language for LLM-Driven Trigger Generation in Multimodal Data Collection
Pith reviewed 2026-05-15 11:42 UTC · model grok-4.3
The pith
A domain-specific language lets LLMs translate natural language into verifiable triggers that selectively collect multimodal sensor data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a formally specified DSL for conditional sensor triggers, when generated by LLMs from natural language, yields higher generation consistency and lower execution latency than unconstrained code generation while preserving comparable detection performance on vehicular and robotic tasks; the same structured abstraction further enables modular composition and concurrent execution on resource-limited edge platforms.
What carries the argument
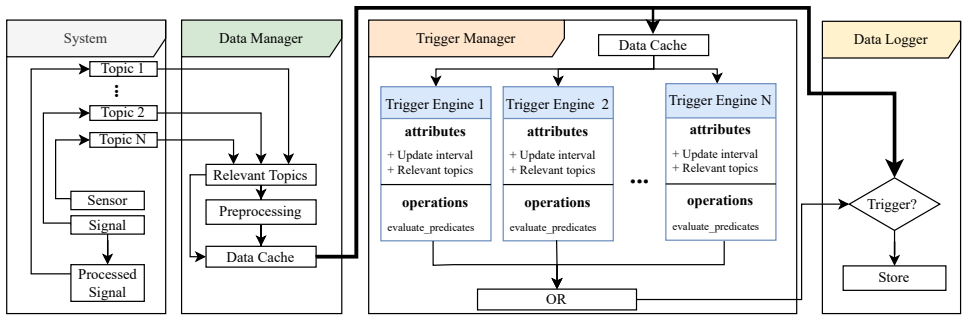
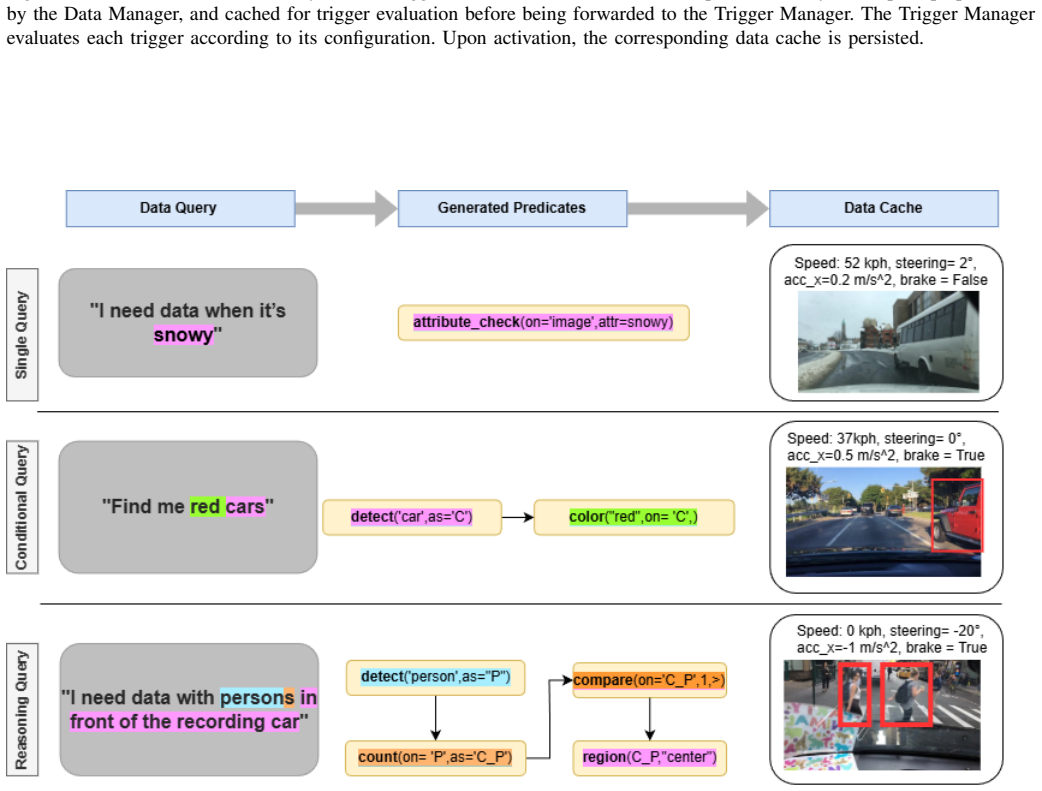
A formally specified domain-specific language (DSL) that defines conditional triggers across heterogeneous sensors (cameras, LiDAR, system telemetry), which LLMs translate from natural-language requests into verifiable and composable programs.
If this is right
- Selective, condition-based collection replaces continuous logging and reduces storage demands for multimodal streams.
- Modular trigger composition allows complex rules to be assembled from simpler verified parts without rewriting code.
- Structured programs support concurrent deployment across multiple sensors on resource-constrained edge devices.
- Verifiable triggers provide a mechanism for intent-driven data collection that remains auditable in real-time systems.
Where Pith is reading between the lines
- The same DSL-plus-LLM pattern could be applied to other sensor-rich domains such as industrial monitoring or environmental sensing.
- Runtime feedback loops might later allow the system to suggest refinements to existing DSL triggers based on collected data quality.
- Teams without deep programming expertise could define data-collection policies directly in natural language while still obtaining machine-checkable programs.
Load-bearing premise
Large language models can reliably translate high-level natural language requests into correct, verifiable, and complete DSL programs without logical errors or missing conditions across all relevant scenarios.
What would settle it
An experiment in which an LLM produces a DSL program that omits a critical condition (for example, failing to trigger data capture when an obstacle appears under specific lighting), causing measurable missed detections that the DSL syntax cannot prevent.
Figures




read the original abstract
Data-driven systems depend on task-relevant data, yet data collection pipelines remain passive and indiscriminate. Continuous logging of multimodal sensor streams incurs high storage costs and captures irrelevant data. This paper proposes a declarative framework for intent-driven, on-device data collection that enables selective collection of multimodal sensor data based on high-level user requests. The framework combines natural language interaction with a formally specified domain-specific language (DSL). Large language models translate user-defined requirements into verifiable and composable DSL programs that define conditional triggers across heterogeneous sensors, including cameras, LiDAR, and system telemetry. Empirical evaluation on vehicular and robotic perception tasks shows that the DSL-based approach achieves higher generation consistency and lower execution latency than unconstrained code generation while maintaining comparable detection performance. The structured abstraction supports modular trigger composition and concurrent deployment on resource-constrained edge platforms. This approach replaces passive logging with a verifiable, intent-driven mechanism for multimodal data collection in real-time systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a declarative framework for intent-driven, on-device multimodal data collection that uses LLMs to translate high-level natural language user requests into programs in a formally specified domain-specific language (DSL). The DSL defines conditional triggers across heterogeneous sensors (cameras, LiDAR, telemetry) to enable selective logging instead of continuous passive collection. The central claim is that this DSL-based approach yields higher generation consistency and lower execution latency than unconstrained code generation while preserving comparable detection performance, with additional benefits in modular composition and edge deployment, as demonstrated in empirical evaluation on vehicular and robotic perception tasks.
Significance. If substantiated, the work addresses a practical bottleneck in real-time multimodal systems by replacing indiscriminate logging with verifiable, intent-driven triggers, potentially reducing storage overhead in resource-constrained environments such as autonomous vehicles and robotics. The emphasis on a formally specified DSL to constrain LLM outputs and enable verification is a constructive step toward reliable code generation for edge platforms. The modular and composable nature of the DSL could support broader reuse, but the overall significance remains difficult to gauge without the missing experimental details, baselines, and verification mechanisms needed to interpret the reported consistency and latency gains.
major comments (2)
- [Abstract] Abstract: The manuscript asserts that 'empirical evaluation on vehicular and robotic perception tasks shows that the DSL-based approach achieves higher generation consistency and lower execution latency than unconstrained code generation while maintaining comparable detection performance,' yet supplies no experimental details whatsoever—no datasets, task definitions, trial counts, concrete metrics for consistency/latency/detection, statistical tests, error taxonomy, or per-scenario success rates. This absence renders the central empirical claim impossible to evaluate and directly undermines the soundness assessment.
- [Abstract] Abstract: The DSL is repeatedly characterized as 'formally specified' and its programs as 'verifiable,' but the manuscript provides neither the grammar, syntax, semantics, nor any verification algorithm or procedure. Without these artifacts, it is impossible to determine whether the claimed consistency advantage arises from correct, complete programs or merely from shorter (potentially incomplete) outputs, and the latency comparison cannot be interpreted.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the critical gaps in experimental reporting and formal specification. We agree that both issues must be addressed for the claims to be evaluable and will revise the manuscript substantially.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that 'empirical evaluation on vehicular and robotic perception tasks shows that the DSL-based approach achieves higher generation consistency and lower execution latency than unconstrained code generation while maintaining comparable detection performance,' yet supplies no experimental details whatsoever—no datasets, task definitions, trial counts, concrete metrics for consistency/latency/detection, statistical tests, error taxonomy, or per-scenario success rates. This absence renders the central empirical claim impossible to evaluate and directly undermines the soundness assessment.
Authors: We agree that the abstract (and, by extension, the current manuscript) lacks the concrete experimental details needed to assess the central claims. In the revised version we will expand the abstract to report the specific datasets, number of trials, concrete metrics (consistency rate, latency in milliseconds, detection F1), statistical tests, and per-scenario results. The main body will be augmented with full experimental setup, baselines, error taxonomy, and tables so that the reported gains can be independently verified. revision: yes
-
Referee: [Abstract] Abstract: The DSL is repeatedly characterized as 'formally specified' and its programs as 'verifiable,' but the manuscript provides neither the grammar, syntax, semantics, nor any verification algorithm or procedure. Without these artifacts, it is impossible to determine whether the claimed consistency advantage arises from correct, complete programs or merely from shorter (potentially incomplete) outputs, and the latency comparison cannot be interpreted.
Authors: We acknowledge that the manuscript currently omits the formal grammar, syntax, semantics, and verification procedure for the DSL. This is a substantive omission that prevents readers from judging the source of the consistency and latency benefits. In the revision we will add a dedicated section presenting the DSL grammar (in BNF), operational semantics, and the verification algorithm, together with a brief proof sketch or argument that the verification step guarantees well-formed programs. This will allow direct comparison of the constrained versus unconstrained generation pipelines. revision: yes
Circularity Check
No circularity: empirical claims rest on external baseline comparison
full rationale
The paper presents an empirical evaluation of a DSL for LLM-generated triggers, claiming higher consistency and lower latency than unconstrained code generation on vehicular/robotic tasks. No equations, fitted parameters, self-citations, or derivations are shown that reduce any result to the paper's own inputs by construction. The DSL is called 'formally specified' and programs 'verifiable,' but the central performance claims are measured against an independent external baseline without self-referential definitions or load-bearing prior work by the same authors. This is a standard non-circular empirical setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can translate natural language user requirements into correct and verifiable DSL programs
invented entities (1)
-
Domain-specific language for trigger generation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the syntax of our domain-specific language for trigger specification using Extended Backus-Naur Form (EBNF). ... Predicate::=PREDICATE(PredicateType [PredicateArgs]) ... Trigger::=TRIGGER Identifier ... ConditionExpr::=AtomicExpr +
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Empirical evaluation ... higher generation consistency and lower execution latency than unconstrained code generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Rigollet al., “Unveiling objects with sola: An annotation-free image search on the object level for automotive data sets,” in2024 IEEE Intell. Vehicles Symposium (IV), Jeju Island, 2nd-5th June 2024. Institute of Electrical and Electronics Engineers (IEEE), 2024, p. 10531059
work page 2024
-
[2]
J. Langneret al., “Estimating the uniqueness of test scenarios derived from recorded real-world-driving-data using autoencoders,” in2018 IEEE Intell. Vehicles Symposium (IV), 2018, pp. 1860–1866
work page 2018
-
[3]
C. M. S. Collaboration, “The CMS trigger system,” vol. 12, no. 01, Jan. 2017, arXiv:1609.02366 [physics]. [Online]. Available: http://arxiv.org/abs/1609.02366
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Towards scenario retrieval of real driving data with large vision-language models,
T. S. Sohnet al., “Towards scenario retrieval of real driving data with large vision-language models,” inProceedings of the 10th Int. Conf. on Vehicle Technology and Intell. Transport Systems. SciTePress, 2024, p. 496 505
work page 2024
-
[5]
Vipergpt: Visual inference via python execution for reasoning,
D. Surs, S. Menon, and C. V ondrick, “Vipergpt: Visual inference via python execution for reasoning,” 2023. [Online]. Available: https://arxiv.org/abs/2303.08128
-
[6]
P. Elspaset al., “Towards a scenario database from recorded driving data with regular expressions for scenario detection,” in8th Int. Conf. on Vehicle Technology and Intell. Transport Systems (VEHITS 2022) : Proceedings. Ed.: J. Ploeg. Vol. 1. SciTePress, 2022, pp. 400–409
work page 2022
-
[7]
Mcity data engine: Iterative model improvement through open-vocabulary data selection,
D. Bogdollet al., “Mcity data engine: Iterative model improvement through open-vocabulary data selection,” 2025. [Online]. Available: https://arxiv.org/abs/2504.21614
-
[8]
Z. Yanget al., “Doraemongpt: Toward understanding dynamic scenes with large language models (exemplified as a video agent),” 2025. [Online]. Available: https://arxiv.org/abs/2401.08392
-
[9]
Data-driven development, a complementing approach for automotive systems eng
J. Bachet al., “Data-driven development, a complementing approach for automotive systems eng.” in2017 IEEE Int. Systems Eng. Symposium (ISSE), 2017, pp. 1–6
work page 2017
-
[10]
Systematization of corner cases for visual per- ception in automated driving,
J. Breitensteinet al., “Systematization of corner cases for visual per- ception in automated driving,” in2020 IEEE Intell. Vehicles Symposium (IV), 2020
work page 2020
-
[11]
Anomaly Detection in Autonomous Driving: A Survey,
D. Bogdoll, M. Nitsche, and J. M. Zollner, “Anomaly Detection in Autonomous Driving: A Survey,” pp. 4487–4498, Jun. 2022. [Online]. Available: https://ieeexplore.ieee.org/document/9857500/
-
[12]
A data-driven novelty score for diverse in-vehicle data recording,
P. Reiset al., “A data-driven novelty score for diverse in-vehicle data recording,” 2025. [Online]. Available: https://arxiv.org/abs/2507.04529
-
[13]
A feedback-control framework for efficient dataset collection from in-vehicle data streams,
——, “A feedback-control framework for efficient dataset collection from in-vehicle data streams,” 2025. [Online]. Available: https: //arxiv.org/abs/2511.03239
-
[14]
An application-driven conceptualization of corner cases for perception in highly automated driving,
F. Heideckeret al., “An application-driven conceptualization of corner cases for perception in highly automated driving,” in2021 IEEE Intell. Vehicles Symposium (IV), 2021
work page 2021
-
[15]
Shadow testing in autonomous vehicles : A novel approach to validating full self-driving ai systems,
R. Pathuri, “Shadow testing in autonomous vehicles : A novel approach to validating full self-driving ai systems,” vol. 10, no. 6, p. 308320, Nov. 2024
work page 2024
-
[16]
Vipergpt: Visual inference via python execution for reasoning,
D. Sur ´ıs, S. Menon, and C. V ondrick, “Vipergpt: Visual inference via python execution for reasoning,” inProceedings of the IEEE/CVF Int. Conf. on Comput. Vision (ICCV), October 2023, pp. 11 888–11 898
work page 2023
-
[17]
Defining and substantiating the terms scene, situation, and scenario for automated driving,
S. Ulbrichet al., “Defining and substantiating the terms scene, situation, and scenario for automated driving,” inProceedings of the 2015 IEEE 18th Int. Conf. on Intell. Transportation Systems (ITSC). USA: IEEE Comput. Society, 2015, p. 982988. [Online]. Available: https://doi.org/10.1109/ITSC.2015.164
-
[18]
T. S. Sohnet al., “A framework for a capability-driven evaluation of scenario understanding for multimodal large language models in autonomous driving,” 2025. [Online]. Available: https://arxiv.org/abs/25 03.11400
work page 2025
-
[19]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAIet al., “gpt-oss-120b & gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
G. Teamet al., “Gemma 3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Bdd100k: A diverse driving dataset for heterogeneous multitask learning,
F. Yuet al., “Bdd100k: A diverse driving dataset for heterogeneous multitask learning,” pp. 2633–2642, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.