Recognition: unknown
C²T: Captioning-Structure and LLM-Aligned Common-Sense Reward Learning for Traffic--Vehicle Coordination
Pith reviewed 2026-05-10 17:10 UTC · model grok-4.3
The pith
C2T distills common-sense knowledge from large language models into intrinsic rewards for multi-agent reinforcement learning in traffic coordination, outperforming hand-crafted reward baselines in efficiency, safety, and energy use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
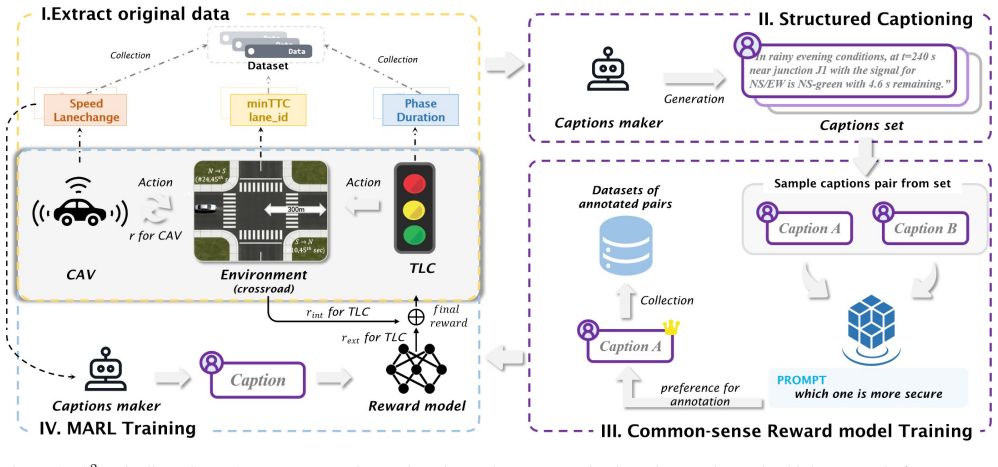
C2T is a framework that learns a common-sense coordination model from traffic-vehicle dynamics. It distills knowledge from a Large Language Model into a learned intrinsic reward function. This reward then guides the cooperative multi-intersection traffic light controller MARL system on CityFlow-based benchmarks, significantly outperforming strong baselines in traffic efficiency, safety, and an energy-related proxy. The framework also demonstrates flexibility by enabling distinct efficiency-focused or safety-focused policies through modifications to the LLM prompt.
What carries the argument
The captioning-structure and LLM-aligned common-sense reward learning, which extracts and aligns high-level knowledge from the LLM to shape the intrinsic reward for multi-agent traffic coordination.
If this is right
- The MARL policies guided by the new reward achieve superior traffic efficiency compared to baselines.
- Safety and energy-related performance metrics improve under the C2T framework.
- Policy behavior can be shifted between efficiency and safety emphases by altering the LLM prompt.
Where Pith is reading between the lines
- This reward learning method may reduce the manual effort needed to design rewards in other multi-agent control problems.
- It could enable more adaptive traffic systems that respond to changing priorities without retraining from scratch.
- Testing the approach in varied simulation environments would help verify if the LLM knowledge generalizes beyond the specific benchmarks used.
Load-bearing premise
Distilling common-sense knowledge from an LLM into a learned intrinsic reward will reliably capture high-level human-centric goals and generalize to traffic-vehicle dynamics without introducing biases or failing to align with simulation outcomes.
What would settle it
Observing no significant outperformance in efficiency, safety, or energy metrics when comparing C2T to strong MARL baselines in the CityFlow multi-intersection simulations would indicate the central claims do not hold.
Figures

read the original abstract
State-of-the-art (SOTA) urban traffic control increasingly employs Multi-Agent Reinforcement Learning (MARL) to coordinate Traffic Light Controllers (TLCs) and Connected Autonomous Vehicles (CAVs). However, the performance of these systems is fundamentally capped by their hand-crafted, myopic rewards (e.g., intersection pressure), which fail to capture high-level, human-centric goals like safety, flow stability, and comfort. To overcome this limitation, we introduce C2T, a novel framework that learns a common-sense coordination model from traffic-vehicle dynamics. C2T distills "common-sense" knowledge from a Large Language Model (LLM) into a learned intrinsic reward function. This new reward is then used to guide the coordination policy of a cooperative multi-intersection TLC MARL system on CityFlow-based multi-intersection benchmarks. Our framework significantly outperforms strong MARL baselines in traffic efficiency, safety, and an energy-related proxy. We further highlight C2T's flexibility in principle, allowing distinct "efficiency-focused" versus "safety-focused" policies by modifying the LLM prompt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces C²T, a framework for multi-agent reinforcement learning (MARL) in urban traffic control that distills common-sense knowledge from a large language model (LLM) via a captioning-structure into an intrinsic reward function. This reward augments standard hand-crafted objectives (e.g., intersection pressure) to guide cooperative policies for traffic light controllers (TLCs) and connected autonomous vehicles (CAVs) on CityFlow multi-intersection benchmarks. The central claims are that C²T yields significant gains over strong MARL baselines in traffic efficiency, safety, and an energy-related proxy, while permitting prompt-based specialization into efficiency-focused versus safety-focused policies.
Significance. If the LLM-distilled reward reliably transfers to simulator dynamics without introducing misalignment, the approach could enable more flexible, human-centric reward design in MARL traffic systems, reducing reliance on myopic hand-crafted terms. The prompt-modification flexibility is a notable strength for policy specialization. However, the manuscript provides no machine-checked proofs, reproducible code artifacts, or parameter-free derivations, and the empirical claims rest on unverified distillation and alignment steps.
major comments (3)
- [§3.2] §3.2 (LLM-aligned reward definition): The intrinsic reward is constructed by modifying LLM prompts and fitting outputs into the MARL objective, but no alignment loss, simulator-in-the-loop fine-tuning, or bounding argument is supplied to guarantee compatibility with CityFlow's continuous-time kinematics, stochastic arrivals, or pressure calculations. This is load-bearing for the outperformance claim, as textual priors may conflict with actual state transitions.
- [§5] §5 (Experimental results): The abstract and results sections assert significant outperformance in efficiency, safety, and energy proxies, yet no statistical significance tests (p-values, confidence intervals), ablation studies on the captioning-structure component, or details on the distillation/training procedure are reported. Without these, the central empirical claim cannot be verified and appears unsupported.
- [§4.1] §4.1 (Captioning-structure): The mechanism for structuring LLM outputs into a learnable reward is described at a high level, but no analysis shows that the resulting reward function improves coordination on actual vehicle dynamics rather than merely reflecting prompt-tuned textual priors.
minor comments (2)
- [§3] Notation for the intrinsic reward function (e.g., r_intrinsic) is introduced without an explicit equation linking it to the MARL value function; add a clear mathematical definition in §3.
- [Figures in §5] Figure captions for the multi-intersection benchmark results should include error bars or variance across random seeds to aid interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below, providing clarifications where possible and outlining planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2 (LLM-aligned reward definition): The intrinsic reward is constructed by modifying LLM prompts and fitting outputs into the MARL objective, but no alignment loss, simulator-in-the-loop fine-tuning, or bounding argument is supplied to guarantee compatibility with CityFlow's continuous-time kinematics, stochastic arrivals, or pressure calculations. This is load-bearing for the outperformance claim, as textual priors may conflict with actual state transitions.
Authors: We acknowledge that the manuscript does not include an explicit alignment loss, simulator-in-the-loop fine-tuning, or formal bounding argument. The captioning-structure maps LLM outputs to reward terms based on observable CityFlow metrics (e.g., pressure, speeds, gaps), which are directly compatible with the simulator's state transitions by design. Empirical results across benchmarks show consistent gains without evident conflicts. In revision, we will expand §3.2 with a detailed mapping procedure, prompt examples, and a qualitative discussion of compatibility and potential misalignments. revision: partial
-
Referee: [§5] §5 (Experimental results): The abstract and results sections assert significant outperformance in efficiency, safety, and energy proxies, yet no statistical significance tests (p-values, confidence intervals), ablation studies on the captioning-structure component, or details on the distillation/training procedure are reported. Without these, the central empirical claim cannot be verified and appears unsupported.
Authors: We agree these elements are essential for verification. The revised manuscript will add statistical significance tests (p-values and confidence intervals) for all key metrics. We will include ablation studies isolating the captioning-structure's contribution and expand the methods section with full details on the distillation procedure, including prompt templates, hyperparameters, and training protocol to support reproducibility. revision: yes
-
Referee: [§4.1] §4.1 (Captioning-structure): The mechanism for structuring LLM outputs into a learnable reward is described at a high level, but no analysis shows that the resulting reward function improves coordination on actual vehicle dynamics rather than merely reflecting prompt-tuned textual priors.
Authors: The captioning-structure extracts traffic concepts from LLM outputs and maps them to quantitative simulator observables (e.g., queue lengths, velocities) to influence policy learning on real dynamics. Our results demonstrate improved coordination metrics in the simulator, indicating effects beyond text. We will add an analysis in the revision comparing reward signals and policy behaviors on sampled trajectories with and without the structure to explicitly demonstrate the dynamic impact. revision: partial
Circularity Check
No circularity detected in derivation chain
full rationale
The provided abstract and context describe a framework that distills LLM knowledge into an intrinsic reward for MARL on CityFlow benchmarks, then reports empirical outperformance. No equations, self-definitions, fitted parameters renamed as predictions, or self-citation chains are visible that would reduce any claimed result to its inputs by construction. The central claim rests on the empirical transfer from LLM prompts to simulator performance, which is an external, falsifiable step rather than a definitional loop. This is the expected non-finding for a methods paper whose load-bearing content is the combination and benchmarking rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM prompt template
invented entities (1)
-
LLM-aligned common-sense reward function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Toward a thousand lights: Decentralized deep reinforcement learning for large-scale traffic signal control
Chacha Chen, Hua Wei, Nan Xu, Guanjie Zheng, Ming Yang, Yuanhao Xiong, Kai Xu, and Zhenhui Li. Toward a thousand lights: Decentralized deep reinforcement learning for large-scale traffic signal control. InProceedings of the AAAI Conference on Artificial Intelligence, 2020. 2, 6
2020
-
[2]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Mar- tic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017. 1, 2
2017
-
[3]
Learning robust rewards with adversarial inverse reinforcement learning
Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adversarial inverse reinforcement learning. In Proceedings of the International Conference on Learning Representations, 2018. 2
2018
-
[4]
Jiaying Guo, Long Cheng, and Shen Wang. CoTV: Co- operative control for traffic light signals and connected au- tonomous vehicles using deep reinforcement learning.arXiv preprint arXiv:2201.13143, 2023. 1, 2
-
[5]
Generative adversarial im- itation learning
Jonathan Ho and Stefano Ermon. Generative adversarial im- itation learning. InAdvances in Neural Information Process- ing Systems, 2016. 2
2016
-
[6]
NuScenes-MQA: Integrated evaluation of captions and QA for autonomous driving datasets using markup anno- tations
Yuichi Inoue, Yuki Yada, Kotaro Tanahashi, and Yu Yam- aguchi. NuScenes-MQA: Integrated evaluation of captions and QA for autonomous driving datasets using markup anno- tations. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), pages 586–595, 2024. 3
2024
-
[7]
Siqi Lai, Zheyuan Xu, Wenjun Zhang, Haoran Liu, and Hui Xiong. LLMLight: Large language models as traffic signal control agents.arXiv preprint arXiv:2312.16044, 2023. 3, 6, 7
-
[8]
Snyder, Reza Samadi, and Bo Zeng
Mehdi Oroojlooy, Lawrence V . Snyder, Reza Samadi, and Bo Zeng. Attendlight: Universal attention-based reinforce- ment learning for traffic signal control. InProceedings of the International Conference on Autonomous Agents and Multi- agent Systems (AAMAS), 2020. 2, 6
2020
-
[9]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, et al. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155, 2022. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Jordan, and Pieter Abbeel
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation. InInter- national Conference on Learning Representations (ICLR),
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beisswenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. InProceedings of the Eu- ropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[13]
Al- varez
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M. Al- varez. OmniDrive: A holistic vision–language dataset for autonomous driving with counterfactual reasoning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[14]
BILE: An effective behavior-based latent exploration scheme for deep reinforcement learning
Yiming Wang, Kaiyan Zhao, Yan Li, and Leong Hou U. BILE: An effective behavior-based latent exploration scheme for deep reinforcement learning. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI), pages 6497–6505, 2025. 2
2025
-
[15]
Explore to learn: Latent exploration through disentangled synergy patterns for rein- forcement learning in overactuated control
Yiming Wang, Kaiyan Zhao, Xu Li, Yan Li, Jiayu Chen, Steven Morad, and Leong Hou U. Explore to learn: Latent exploration through disentangled synergy patterns for rein- forcement learning in overactuated control. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 26670–26678, 2026. 2
2026
-
[16]
DSAP: Enhancing general- ization in goal-conditioned reinforcement learning
Yiming Wang, Kaiyan Zhao, Ming Yang, Yan Li, Furui Liu, Jiayu Chen, and Leong Hou U. DSAP: Enhancing general- ization in goal-conditioned reinforcement learning. InPro- ceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 26679–26687, 2026. 2
2026
-
[17]
Latent state-predictive exploration for deep reinforcement learning
Yiming Wang, Kaiyan Zhao, Borong Zhang, Yan Li, and Leong Hou U. Latent state-predictive exploration for deep reinforcement learning. InProceedings of the AAAI Confer- ence on Artificial Intelligence (AAAI), pages 26661–26669,
-
[18]
In- telliLight: A reinforcement learning approach for intelli- gent traffic light control
Hua Wei, Guanjie Zheng, Huaxiu Yao, and Zhenhui Li. In- telliLight: A reinforcement learning approach for intelli- gent traffic light control. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2018. 1, 2
2018
-
[19]
Presslight: Learning max pressure control to coordinate traffic signals in arterial net- work
Hua Wei, Chacha Chen, Guanjie Zheng, Kan Wu, Vikash Gayah, Kai Xu, and Zhenhui Li. Presslight: Learning max pressure control to coordinate traffic signals in arterial net- work. InProceedings of the 25th ACM SIGKDD Interna- tional Conference on Knowledge Discovery and Data Min- ing, 2019. 1, 2, 6
2019
-
[20]
CoLight: Learning network-level cooper- ation for traffic signal control
Hua Wei, Nan Xu, Huichu Zhang, Guanjie Zheng, Xinshi Zang, Chacha Chen, Weinan Zhang, Yanmin Zhu, Kai Xu, and Zhenhui Li. CoLight: Learning network-level cooper- ation for traffic signal control. InProceedings of the 28th ACM International Conference on Information and Knowl- edge Management, pages 1913–1922, 2019. 2, 3, 6
1913
-
[21]
Efficient-CoLight: Learning efficient pressure rep- resentation for network-level traffic signal control
Kan Wu, Hua Wei, Chacha Chen, Guanjie Zheng, and Zhen- hui Li. Efficient-CoLight: Learning efficient pressure rep- resentation for network-level traffic signal control. InPro- ceedings of the ACM International Conference on Informa- tion and Knowledge Management, pages 2060–2069, 2021. 2, 6
2060
-
[22]
Ask a strong LLM judge when your reward model is uncertain
Zhenghao Xu, Qin Lu, Qingru Zhang, Liang Qiu, Ilgee Hong, Changlong Yu, Wenlin Yao, Yao Liu, Haoming Jiang, Lihong Li, Hyokun Yun, and Tuo Zhao. Ask a strong LLM judge when your reward model is uncertain. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 3
2025
-
[23]
MetaLight: Value-based meta- reinforcement learning for traffic signal control
Xinshi Zang, Huaxiu Yao, Guanjie Zheng, Nan Xu, Kai Xu, and Zhenhui Li. MetaLight: Value-based meta- reinforcement learning for traffic signal control. InProceed- ings of the AAAI Conference on Artificial Intelligence, 2020. 2
2020
-
[24]
Cityflow: A multi-agent reinforce- ment learning environment for large scale city traffic sce- nario
Huichu Zhang, Siyuan Feng, Chang Liu, Yaoyao Ding, Yichen Zhu, Zihan Zhou, Weinan Zhang, Yong Yu, Haim- ing Jin, and Zhenhui Li. Cityflow: A multi-agent reinforce- ment learning environment for large scale city traffic sce- nario. InProceedings of the World Wide Web Conference, pages 3620–3624. ACM, 2019. 2, 6
2019
-
[25]
Expression might be enough: Representing pressure and demand for reinforcement learning-based traffic signal control
Liang Zhang, Qiang Wu, Jun Shen, Linyuan L ¨u, Bo Du, and Jianqing Wu. Expression might be enough: Representing pressure and demand for reinforcement learning-based traffic signal control. InProceedings of the 39th International Con- ference on Machine Learning (ICML), pages 26645–26654. PMLR, 2022. 2, 6
2022
-
[26]
Efficient diversity-based experience replay for deep reinforcement learning
Kaiyan Zhao, Yiming Wang, Yuyang Chen, Yan Li, Leong Hou U, and Xiaoguang Niu. Efficient diversity-based experience replay for deep reinforcement learning. InPro- ceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI), pages 7083–7091, 2025. 2
2025
-
[27]
Learning phase competition for traffic signal control with FRAP
Guanjie Zheng, Yuanhao Xiong, Xinshi Zang, Jie Feng, Hua Wei, Huichu Zhang, Yong Li, Kai Xu, and Zhenhui Li. Learning phase competition for traffic signal control with FRAP. InProceedings of the 28th ACM International Con- ference on Information and Knowledge Management, 2019. 2, 3 Acknowledgments This work was supported by the Science and Tech- nology De...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.