Recognition: unknown
Pareto-Optimal Offline Reinforcement Learning via Smooth Tchebysheff Scalarization
Pith reviewed 2026-05-10 14:49 UTC · model grok-4.3
The pith
Smooth Tchebysheff scalarization recovers non-convex Pareto fronts in multi-objective offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating multi-objective RL itself as the object of scalarization and applying smooth Tchebysheff scalarization together with per-reward standardization from observed distributions, STOMP extends direct preference optimization to the multi-objective setting and produces policies whose hypervolumes exceed those of prior baselines in eight of nine protein-engineering tasks under both offline off-policy and generative evaluation.
What carries the argument
Smooth Tchebysheff scalarization applied to the vector-valued RL objective, which replaces linear weighting and enables recovery of non-convex Pareto regions while remaining differentiable.
If this is right
- STOMP supplies a concrete algorithm for simultaneously optimizing multiple conflicting rewards in offline preference data without the coverage gaps of linear scalarization.
- The same standardization-plus-smooth-Tchebysheff procedure can be applied to any offline RL method that already supports vector-valued returns.
- On protein-engineering benchmarks the method improves hypervolume metrics across different base language models and dataset sizes.
- The approach remains compatible with existing direct-preference-optimization training pipelines once the scalarization and normalization steps are inserted.
Where Pith is reading between the lines
- The same framing could be tested in online or on-policy multi-objective RL to check whether the advantages persist when new data can be collected.
- Because the scalarization is applied at the optimization level rather than the reward level, it may combine with other non-linear preference aggregation schemes beyond Tchebysheff.
- The standardization step suggests a general recipe for making any vector reward comparable across tasks whose reward scales differ.
Load-bearing premise
That standardizing individual rewards based on their observed distributions, combined with smooth Tchebysheff scalarization, reliably recovers non-convex regions of the Pareto front in the offline multi-objective RL setting without introducing new biases.
What would settle it
An experiment on a controlled multi-objective task whose true Pareto front contains known non-convex segments, where STOMP policies achieve only the convex hull of attainable points, would falsify the central claim.
Figures

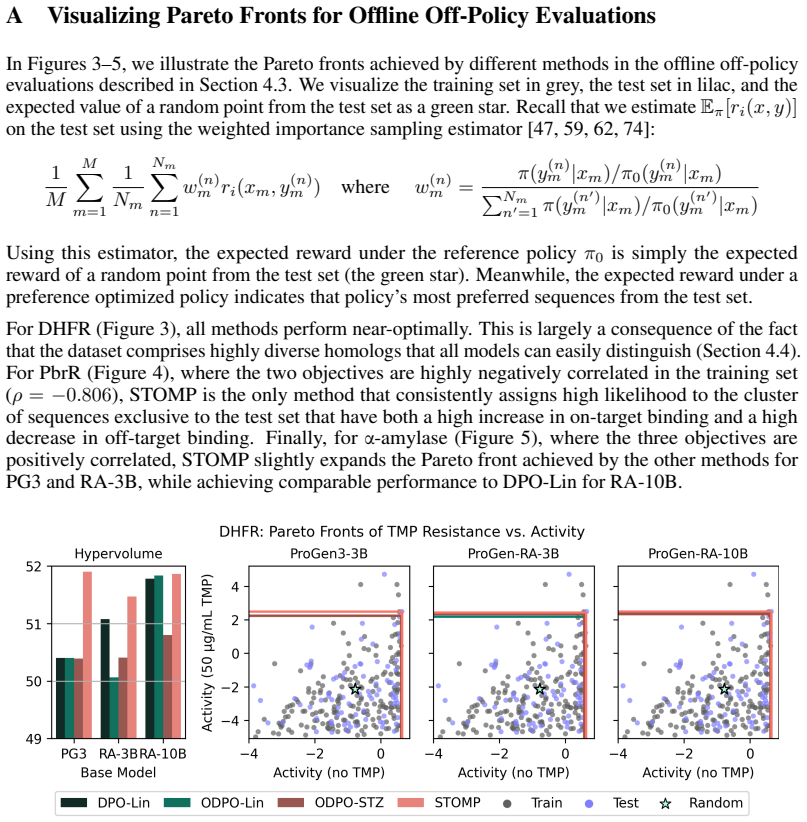
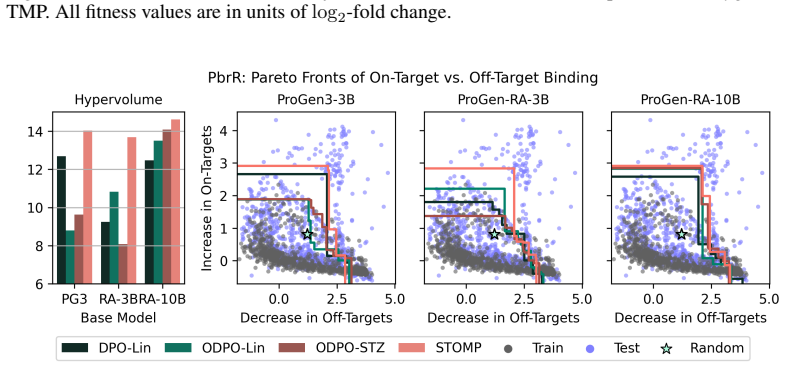

read the original abstract
Large language models can be aligned with human preferences through offline reinforcement learning (RL) on small labeled datasets. While single-objective alignment is well-studied, many real-world applications demand the simultaneous optimization of multiple conflicting rewards, e.g. optimizing both catalytic activity and specificity in protein engineering, or helpfulness and harmlessness for chatbots. Prior work has largely relied on linear reward scalarization, but this approach provably fails to recover non-convex regions of the Pareto front. In this paper, instead of scalarizing the rewards directly, we frame multi-objective RL itself as an optimization problem to be scalarized via smooth Tchebysheff scalarization, a recent technique that overcomes the shortcomings of linear scalarization. We use this formulation to derive Smooth Tchebysheff Optimization of Multi-Objective Preferences (STOMP), a novel offline RL algorithm that extends direct preference optimization to the multi-objective setting in a principled way by standardizing the individual rewards based on their observed distributions. We empirically validate STOMP on a range of protein engineering tasks by aligning three autoregressive protein language models on three laboratory datasets of protein fitness. Compared to state-of-the-art baselines, STOMP achieves the highest hypervolumes in eight of nine settings according to both offline off-policy and generative evaluations. We thus demonstrate that STOMP is a powerful, robust multi-objective alignment algorithm that can meaningfully improve post-trained models for multi-attribute protein optimization and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STOMP, a novel offline multi-objective RL algorithm that applies smooth Tchebysheff scalarization to standardized rewards (using observed dataset statistics) to extend direct preference optimization beyond linear scalarization. It claims this recovers non-convex Pareto fronts and empirically demonstrates superior performance, achieving the highest hypervolumes in eight of nine settings on three autoregressive protein language models aligned to three laboratory protein fitness datasets, as measured by both offline off-policy and generative evaluations.
Significance. If the central construction holds, the work is significant for multi-objective offline RL and preference alignment, as it provides a principled alternative to linear scalarization that provably fails on non-convex fronts. The focus on protein engineering tasks adds practical value for real-world applications involving conflicting objectives such as activity and specificity.
major comments (1)
- Abstract: The claim that standardizing rewards from the finite offline dataset (via mean/std or min/max) combined with smooth Tchebysheff scalarization reliably recovers non-convex Pareto regions is load-bearing for the hypervolume superiority result, yet the manuscript provides no diagnostic (e.g., comparison of recovered fronts to the convex hull of linear baselines or analysis of coverage gaps) showing that empirical distributions are representative enough to avoid shifting utopia/nadir points and missing non-dominated segments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: The claim that standardizing rewards from the finite offline dataset (via mean/std or min/max) combined with smooth Tchebysheff scalarization reliably recovers non-convex Pareto regions is load-bearing for the hypervolume superiority result, yet the manuscript provides no diagnostic (e.g., comparison of recovered fronts to the convex hull of linear baselines or analysis of coverage gaps) showing that empirical distributions are representative enough to avoid shifting utopia/nadir points and missing non-dominated segments.
Authors: We agree that the standardization of rewards from the finite offline dataset is central to our claims and that the manuscript would be strengthened by explicit diagnostics demonstrating recovery of non-convex Pareto regions. Our current evidence consists of the superior hypervolume results achieved by STOMP relative to linear scalarization baselines across eight of nine protein engineering settings. To directly address the concern about representativeness of the observed distributions and potential shifts in utopia/nadir points, we will revise the manuscript to include: (i) visualizations of the recovered Pareto fronts compared against the convex hull of solutions from linear baselines, and (ii) analysis of coverage gaps together with sensitivity checks on the choice of standardization (mean/std versus min/max). These additions will be placed in the experimental section and will clarify the conditions under which the approach reliably captures non-dominated segments. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes STOMP as a novel offline RL algorithm that applies smooth Tchebysheff scalarization to multi-objective preferences after standardizing individual rewards using statistics from the observed offline dataset. This construction is presented as an extension of direct preference optimization, with the central result being an empirical demonstration of higher hypervolumes versus baselines on protein tasks under offline and generative evaluations. No equations or steps reduce any claimed performance metric or first-principles result to an input quantity by construction; standardization is an explicit preprocessing choice rather than a fitted parameter whose output is then renamed as a prediction, and no load-bearing self-citations or uniqueness theorems are invoked to force the method. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amini, T
A. Amini, T. Vieira, and R. Cotterell. Direct Preference Optimization with an Offset. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 9954–9972, Bangkok, Thailand, 8 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.findings-acl.592/
2024
-
[2]
C. Armer, H. Kane, D. L. Cortade, H. Redestig, D. A. Estell, A. Yusuf, N. Rollins, A. Spinner, D. Marks, T. J. Brunette, P. J. Kelly, and E. DeBenedictis. Results of the Protein Engineering Tournament: An Open Science Benchmark for Protein Modeling and Design.Proteins: Structure, Function, and Bioinformatics, 93(11):2005–2014, 2025. doi: https://doi.org/1...
-
[3]
A. Auger, J. Bader, D. Brockhoff, and E. Zitzler. Theory of the hypervolume indicator: optimal µ- distributions and the choice of the reference point. InProceedings of the Tenth ACM SIGEVO Workshop on Foundations of Genetic Algorithms, FOGA ’09, page 87–102, New York, NY , USA, 2009. Association for Computing Machinery. ISBN 9781605584140. doi: 10.1145/15...
-
[4]
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighan, N. Joseph, S. Kadavath, J. Kernion, T. Conerly, S. El-Showk, N. Elhage, Z. Hatfield-Dodds, D. Hernandez, T. Hume, S. Johnston, S. Kravec, L. Lovitt, N. Nanda, C. Olsson, D. Amodei, T. Brown, J. Clark, S. McCandlish, C. Olah, B. Mann, and J. Kaplan. ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Balandat, B
M. Balandat, B. Karrer, D. Jiang, S. Daulton, B. Letham, A. G. Wilson, and E. Bakshy. BoTorch: A Framework for Efficient Monte-Carlo Bayesian Optimization. In H. Larochelle, M. Ranzato, R. Had- sell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 21524–21538. Curran Associates, Inc., 2020. URL https://pr...
2020
-
[6]
N. Beume, C. M. Fonseca, M. Lopez-Ibanez, L. Paquete, and J. Vahrenhold. On the Complexity of Computing the Hypervolume Indicator.IEEE Transactions on Evolutionary Computation, 13(5):1075– 1082, Oct 2009. ISSN 1941-0026. doi: 10.1109/TEVC.2009.2015575
-
[7]
Bhatnagar, S
A. Bhatnagar, S. Jain, J. Beazer, S. C. Curran, A. M. Hoffnagle, K. S. Ching, M. Martyn, S. Nayfach, J. A. Ruffolo, and A. Madani. Scaling Unlocks Broader Generation and Deeper Functional Understanding of Proteins. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=yvGL2HP7pU
2025
-
[8]
B. Borremans, J. L. Hobman, A. Provoost, N. L. Brown, and D. van der Lelie. Cloning and Func- tional Analysis of the PbrR Lead Resistance Determinant of Ralstonia metallidurans CH34.Journal of Bacteriology, 183(19):5651–5658, 2001. doi: 10.1128/jb.183.19.5651-5658.2001. URL https: //journals.asm.org/doi/abs/10.1128/jb.183.19.5651-5658.2001
-
[9]
V . J. Bowman. On the Relationship of the Tchebycheff Norm and the Efficient Frontier of Multiple-Criteria Objectives. In H. Thiriez and S. Zionts, editors,Multiple Criteria Decision Making, pages 76–86, Berlin, Heidelberg, 1976. Springer Berlin Heidelberg. ISBN 978-3-642-87563-2
1976
-
[10]
Boyd and L
S. Boyd and L. Vandenberghe.Convex optimization. Cambridge University Press, 2004
2004
- [11]
-
[12]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei...
1901
-
[13]
T. Chen, B. Xu, C. Zhang, and C. Guestrin. Training Deep Nets with Sublinear Memory Cost, 2016. URL https://arxiv.org/abs/1604.06174. 10
work page internal anchor Pith review arXiv 2016
-
[14]
Chennakesavalu, F
S. Chennakesavalu, F. Hu, S. Ibarraran, and G. M. Rotskoff. Aligning Transformers with Continuous Feedback via Energy Rank Alignment. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=SXxlb1miXS
2025
- [15]
-
[16]
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep Reinforcement Learning from Human Preferences. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran As- sociates, Inc., 2017. URL https://proceedings.neurips.c...
2017
-
[17]
I. Das and J. Dennis. A Closer Look at Drawbacks of Minimizing Weighted Sums of Objectives for Pareto Set Generation in Multicriteria Optimization Problems.Structural Optimization, 14:63–69, 01 1997. doi: 10.1007/BF01197559
-
[18]
BERT: Pre-training of deep bidi- rectional transformers for language understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In J. Burstein, C. Doran, and T. Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers...
-
[19]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=YicbFdNTTy
2021
-
[20]
Ehrgott.Multicriteria optimization
M. Ehrgott.Multicriteria optimization. Springer, Berlin, Germany, 2nd ed edition, 2005. ISBN 3540213988. URLhttp://rave.ohiolink.edu/ebooks/ebc/3540276599
-
[21]
Eysenbach and S
B. Eysenbach and S. Levine. Maximum Entropy RL (Provably) Solves Some Robust RL Problems. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum? id=PtSAD3caaA2
2022
-
[22]
Fanton, L
A. Fanton, L. J. Bartie, J. Q. Martins, V . Q. Tran, L. Goudy, C. Kernick, M. G. Durrant, J. Wei, Z. Armour- Garb, A. Pawluk, S. Konermann, A. Marson, L. A. Gilbert, T. L. Roth, and P. D. Hsu. Site-specific DNA in- sertion into the human genome with engineered recombinases.Nature Biotechnology, 11 2025. ISSN 1546-
2025
-
[23]
URLhttps://doi.org/10.1038/s41587-025-02895-3
doi: 10.1038/s41587-025-02895-3. URLhttps://doi.org/10.1038/s41587-025-02895-3
-
[24]
L. Faury, U. Tanielian, E. Dohmatob, E. Smirnova, and F. Vasile. Distributionally Robust Counterfactual Risk Minimization.Proceedings of the AAAI Conference on Artificial Intelligence, 34(04):3850–3857, 4 2020. doi: 10.1609/aaai.v34i04.5797. URL https://ojs.aaai.org/index.php/AAAI/article/ view/5797
-
[25]
Fisch, J
A. Fisch, J. Eisenstein, V . Zayats, A. Agarwal, A. Beirami, C. Nagpal, P. Shaw, and J. Berant. Robust Preference Optimization through Reward Model Distillation.Transactions on Machine Learning Research,
-
[26]
URLhttps://openreview.net/forum?id=E2zKNuwNDc
ISSN 2835-8856. URLhttps://openreview.net/forum?id=E2zKNuwNDc
-
[27]
C. Fonseca, L. Paquete, and M. Lopez-Ibanez. An Improved Dimension-Sweep Algorithm for the Hypervolume Indicator. In2006 IEEE International Conference on Evolutionary Computation, pages 1157–1163, 2006. doi: 10.1109/CEC.2006.1688440
-
[28]
Y . Fu, T. Chen, J. Chai, X. Wang, S. Tu, G. Yin, W. Lin, Q. Zhang, Y . Zhu, and D. Zhao. SRFT: A Single-Stage Method with Supervised and Reinforcement Fine-Tuning for Reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=n6E0r6kQWQ
2026
-
[29]
Z. Gao, J. D. Chang, W. Zhan, O. Oertell, G. Swamy, K. Brantley, T. Joachims, J. A. Bagnell, J. D. Lee, and W. Sun. REBEL: reinforcement learning via regressing relative rewards. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY , USA,
-
[30]
ISBN 9798331314385
Curran Associates Inc. ISBN 9798331314385
-
[31]
A. M. Geoffrion. Solving Bicriterion Mathematical Programs.Operations Research, 15(1):39–54, 2 1967. ISSN 0030-364X. doi: 10.1287/opre.15.1.39. 11
-
[32]
J. L. Goffin. On convergence rates of subgradient optimization methods.Mathematical Programming, 13 (1):329–347, Dec 1977. ISSN 1436-4646. doi: 10.1007/BF01584346
-
[33]
Grathwohl, K
W. Grathwohl, K. Swersky, M. Hashemi, D. Duvenaud, and C. Maddison. Oops I Took A Gradient: Scalable Sampling for Discrete Distributions. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 3831–3841. PMLR, 7 2021. URL https://proceedings.mlr.p...
2021
-
[34]
A. P. Guerreiro and C. M. Fonseca. Computing and Updating Hypervolume Contributions in Up to Four Dimensions.IEEE Transactions on Evolutionary Computation, 22(3):449–463, 2018. doi: 10.1109/TEVC. 2017.2729550
-
[35]
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. Källström, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, E. Howley, A. A. Irissappane, P. Mannion, A. Nowé, G. Ramos, M. Restelli, P. Vamplew, and D. M. Roijers. A practical guide to multi-objective reinforcement learning and planning.Autonomous Agents and Multi-Agent Syste...
-
[36]
Holtzman, J
A. Holtzman, J. Buys, L. Du, M. Forbes, and Y . Choi. The Curious Case of Neural Text Degeneration. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum? id=rygGQyrFvH
2020
-
[37]
Hvarfner, E
C. Hvarfner, E. O. Hellsten, and L. Nardi. Vanilla Bayesian Optimization Performs Great in High Dimensions. InForty-first International Conference on Machine Learning, 2024. URL https:// openreview.net/forum?id=OfT8MgIqHT
2024
-
[38]
Ibarraran, S
S. Ibarraran, S. Chennakesavalu, F. Hu, and G. M. Rotskoff. Efficient, Few-shot Directed Evolution with Energy Rank Alignment. InICLR 2026 Workshop on Generative and Experimental Perspectives for Biomolecular Design, 2026. URLhttps://openreview.net/forum?id=2Y6A9oyovP
2026
-
[39]
S. Jain, J. Beazer, J. A. Ruffolo, A. Bhatnagar, and A. Madani. E1: Retrieval-Augmented Protein Encoder Models.bioRxiv, 2025. doi: 10.1101/2025.11.12.688125. URL https://www.biorxiv.org/content/ early/2025/11/13/2025.11.12.688125
-
[40]
X. Jia, Y . Ma, R. Bu, T. Zhao, and K. Wu. Directed evolution of a transcription factor PbrR to im- prove lead selectivity and reduce zinc interference through dual selection.AMB Express, 10(1):67, Apr 2020. ISSN 2191-0855. doi: 10.1186/s13568-020-01004-8. URL https://doi.org/10.1186/ s13568-020-01004-8
-
[41]
D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. InInternational Conference on Learning Representations, 2015. URLhttps://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
S. H. Lee, Y . Li, J. Ke, I. Yoo, H. Zhang, J. Yu, Q. Wang, F. Deng, G. Entis, J. He, G. Li, S. Kim, I. Essa, and F. Yang. Parrot: Pareto-optimal multi-reward reinforcement learning framework for text-to-image generation. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XXXVIII, page 46...
-
[43]
K. Li, T. Zhang, and R. Wang. Deep Reinforcement Learning for Multiobjective Optimization.IEEE Transactions on Cybernetics, 51(6):3103–3114, 2021. doi: 10.1109/TCYB.2020.2977661
-
[44]
T-VSL: text-guided visual sound source localization in mixtures
Y . Liang, J. He, G. Li, P. Li, A. Klimovskiy, N. Carolan, J. Sun, J. Pont-Tuset, S. Young, F. Yang, J. Ke, K. D. Dvijotham, K. M. Collins, Y . Luo, Y . Li, K. J. Kohlhoff, D. Ramachandran, and V . Navalpakkam. Rich Human Feedback for Text-to-Image Generation . In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19401–19411...
-
[45]
X. Lin, X. Zhang, Z. Yang, F. Liu, Z. Wang, and Q. Zhang. Smooth Tchebycheff scalarization for multi-objective optimization. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[46]
Z. Liu, M. Lu, S. Zhang, B. Liu, H. Guo, Y . Yang, J. Blanchet, and Z. Wang. Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/ forum?id=2cQ3lPhkeO. 12
2024
-
[47]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[48]
López-Ibáñez.moocore: Core Mathematical Functions for Multi-Objective Optimization, 2026
M. López-Ibáñez.moocore: Core Mathematical Functions for Multi-Objective Optimization, 2026. URL https://multi-objective.github.io/moocore/r/. R package version 0.2.0.900
2026
-
[49]
A. Madani, B. Krause, E. R. Greene, S. Subramanian, B. P. Mohr, J. M. Holton, J. L. Olmos, C. Xiong, Z. Z. Sun, R. Socher, J. S. Fraser, and N. Naik. Large language models generate functional protein sequences across diverse families.Nature Biotechnology, 41(8):1099–1106, Aug 2023. ISSN 1546-1696. doi: 10.1038/s41587-022-01618-2. URLhttps://doi.org/10.103...
-
[50]
A. R. Mahmood, H. van Hasselt, and R. S. Sutton. Weighted importance sampling for off-policy learn- ing with linear function approximation. In Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, editors,Advances in Neural Information Processing Systems, volume 27. Curran As- sociates, Inc., 2014. URL https://proceedings.neurips.cc/paper_...
2014
-
[51]
Mao, F.-L
X. Mao, F.-L. Li, H. Xu, W. Zhang, W. Chen, and A. T. Luu. Don’t Forget Your Reward Values: Language Model Alignment via Value-based Calibration. In Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17622–17642, Miami, Florida, USA, 11 2024. Association for Com...
2024
-
[52]
How to make the most of your masked language model for protein engineering
C. McCarter, N. Bhattacharya, S. W. Ober, and H. Elliott. How to make the most of your masked language model for protein engineering, 2026. URLhttps://arxiv.org/abs/2603.10302
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Meier, R
J. Meier, R. Rao, R. Verkuil, J. Liu, T. Sercu, and A. Rives. Language models enable zero-shot pre- diction of the effects of mutations on protein function. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 29287–29303. Curran Associates, Inc., 2021. URL htt...
2021
-
[54]
Y . Meng, M. Xia, and D. Chen. SimPO: Simple Preference Optimization with a Reference-Free Reward. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=3Tzcot1LKb
2024
-
[55]
Micikevicius, S
P. Micikevicius, S. Narang, J. Alben, G. Diamos, E. Elsen, D. Garcia, B. Ginsburg, M. Houston, O. Kuchaiev, G. Venkatesh, and H. Wu. Mixed Precision Training. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=r1gs9JgRZ
2018
-
[56]
Miettinen.Nonlinear multiobjective optimization
K. Miettinen.Nonlinear multiobjective optimization. Kluwer, Boston, MA, USA, 1999
1999
-
[57]
M. Mirdita, K. Schütze, Y . Moriwaki, L. Heo, S. Ovchinnikov, and M. Steinegger. Colabfold: making protein folding accessible to all.Nature Methods, 19(6):679–682, Jun 2022. ISSN 1548-7105. doi: 10.1038/s41592-022-01488-1. URLhttps://doi.org/10.1038/s41592-022-01488-1
-
[58]
E. Nijkamp, J. A. Ruffolo, E. N. Weinstein, N. Naik, and A. Madani. ProGen2: Exploring the boundaries of protein language models.Cell Systems, 14(11):968–978.e3, Nov 2023. ISSN 2405-4712. doi: 10.1016/j.cels.2023.10.002. URLhttps://doi.org/10.1016/j.cels.2023.10.002
-
[59]
Notin, A
P. Notin, A. Kollasch, D. Ritter, L. van Niekerk, S. Paul, H. Spinner, N. Rollins, A. Shaw, R. Orenbuch, R. Weitzman, J. Frazer, M. Dias, D. Franceschi, Y . Gal, and D. Marks. Pro- teinGym: Large-Scale Benchmarks for Protein Fitness Prediction and Design. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural In...
2023
-
[60]
Notin, R
P. Notin, R. Weitzman, D. Marks, and Y . Gal. ProteinNPT: Improving Protein Property Prediction and Design with Non-Parametric Transformers. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 33529–33563. Curran Associates, Inc., 2023. URL https://proceedings....
2023
-
[61]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neur...
2022
-
[62]
A. B. Owen.Practical Quasi-Monte Carlo Integration. https://artowen.su.domains/mc/ practicalqmc.pdf, 2023
2023
-
[63]
R. Y . Pang, W. Yuan, H. He, K. Cho, S. Sukhbaatar, and J. Weston. Iterative Reasoning Preference Optimization. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 116617–116637. Cur- ran Associates, Inc., 2024. URL https://proceedings.neurips.cc/...
2024
-
[64]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In H. Wallach, H. Larochelle, A. Beygelzimer, F....
2019
-
[65]
Precup, R
D. Precup, R. S. Sutton, and S. Dasgupta. Off-Policy Temporal Difference Learning with Function Approximation. InProceedings of the Eighteenth International Conference on Machine Learning, ICML ’01, page 417–424, San Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc. ISBN 1558607781
2001
-
[66]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learni...
2021
-
[67]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=HPuSIXJaa9
2023
-
[68]
C. E. Rasmussen and C. K. I. Williams.Gaussian Processes for Machine Learning. The MIT Press, 11
-
[69]
Adaptive Computation and Machine Learning, The MIT Press (2006)
ISBN 9780262256834. doi: 10.7551/mitpress/3206.001.0001. URL https://doi.org/10.7551/ mitpress/3206.001.0001
-
[70]
D. M. Roijers, P. Vamplew, S. Whiteson, and R. Dazeley. A survey of multi-objective sequential decision- making.J. Artif. Int. Res., 48(1):67–113, 10 2013. ISSN 1076-9757
2013
-
[71]
K. J. Romanowicz, C. Resnick, S. R. Hinton, and C. Plesa. Exploring antibiotic resistance in diverse homologs of the dihydrofolate reductase protein family through broad mutational scanning.Science Advances, 11(33):eadw9178, 2025. doi: 10.1126/sciadv.adw9178. URL https://www.science.org/ doi/abs/10.1126/sciadv.adw9178
-
[72]
Schulman, S
J. Schulman, S. Levine, P. Abbeel, M. Jordan, and P. Moritz. Trust Region Policy Optimization. In F. Bach and D. Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1889–1897, Lille, France, 7 2015. PMLR. URL https://proceedings.mlr.press/v37/schulman15.html
2015
-
[73]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal Policy Optimization Algorithms. CoRR, abs/1707.06347, 2017. URLhttp://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[74]
doi: 10.1109/JPROC.2015.2494218
B. Shahriari, K. Swersky, Z. Wang, R. P. Adams, and N. de Freitas. Taking the Human Out of the Loop: A Review of Bayesian Optimization.Proceedings of the IEEE, 104(1):148–175, 2016. doi: 10.1109/JPROC.2015.2494218
-
[75]
MMseqs 2 enables sensitive protein sequence searching for the analysis of massive data sets
M. Steinegger and J. Söding. Mmseqs2 enables sensitive protein sequence searching for the analysis of massive data sets.Nature Biotechnology, 35(11):1026–1028, Nov 2017. ISSN 1546-1696. doi: 10.1038/nbt.3988. URLhttps://doi.org/10.1038/nbt.3988
-
[76]
R. E. Steuer and E.-U. Choo. An interactive weighted Tchebycheff procedure for multiple objective programming.Mathematical Programming, 26(3):326–344, Oct 1983. ISSN 1436-4646. doi: 10.1007/ BF02591870
1983
-
[77]
N. Sun, S. Zou, T. Tao, S. Mahbub, D. Li, Y . Zhuang, H. Wang, X. Cheng, L. Song, and E. P. Xing. Mixture of Experts Enable Efficient and Effective Protein Understanding and Design.bioRxiv, 2024. doi: 10.1101/2024.11.29.625425. URL https://www.biorxiv.org/content/early/2024/12/03/2024. 11.29.625425. 14
-
[78]
R. S. Sutton and A. G. Barto.Reinforcement learning - an introduction. Adaptive computation and machine learning. MIT Press, 1998. ISBN 978-0-262-19398-6. URL http://www.incompleteideas. net/book/first/the-book.html
1998
-
[79]
Tesauro, R
G. Tesauro, R. Das, H. Chan, J. Kephart, D. Levine, F. Rawson, and C. Lefurgy. Managing Power Con- sumption and Performance of Computing Systems Using Reinforcement Learning. In J. Platt, D. Koller, Y . Singer, and S. Roweis, editors,Advances in Neural Information Processing Systems, volume 20. Cur- ran Associates, Inc., 2007. URL https://proceedings.neur...
2007
-
[80]
Toussaint
M. Toussaint. Robot trajectory optimization using approximate inference. InProceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, page 1049–1056, New York, NY , USA,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.