Recognition: unknown
Leveraging LLM-GNN Integration for Open-World Question Answering over Knowledge Graphs
Pith reviewed 2026-05-10 13:16 UTC · model grok-4.3
The pith
GLOW lets a GNN propose answer candidates from an incomplete knowledge graph and feeds them in a structured prompt to an LLM for final reasoning without retrieval or fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
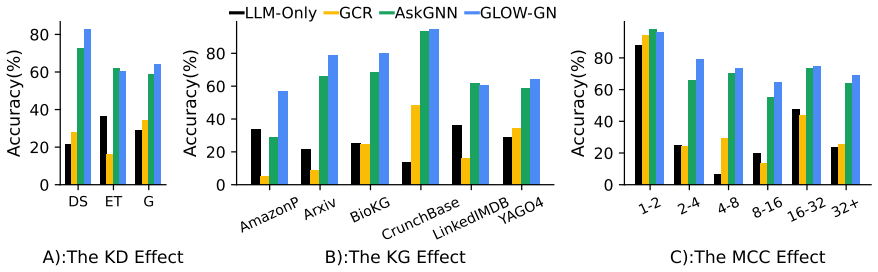
GLOW combines a pre-trained GNN and an LLM for open-world KGQA. The GNN predicts top-k candidate answers from the graph structure. These, along with relevant KG facts, are serialized into a structured prompt to guide the LLM's reasoning. This enables joint reasoning over symbolic and semantic signals, without relying on retrieval or fine-tuning. GLOW outperforms existing LLM-GNN systems on standard benchmarks and GLOW-BENCH, achieving up to 53.3% and an average 38% improvement.
What carries the argument
The GLOW pipeline, in which a GNN generates top-k answer candidates that are serialized with KG triples into a fixed-format prompt for the LLM to perform the final selection and multi-hop inference.
If this is right
- Open-world QA over incomplete KGs becomes practical without assuming observed paths or complete graphs.
- The same GNN-LLM candidate-plus-prompt pattern can be applied across diverse domains as shown by GLOW-BENCH results.
- Performance gains of up to 53.3 percent arise from letting the GNN handle structural ranking while the LLM supplies semantic grounding.
- No fine-tuning or external retrieval is required, so the method deploys with off-the-shelf pre-trained models.
- Existing LLM-GNN hybrids that rely only on embeddings can be upgraded by replacing them with explicit top-k candidate serialization.
Where Pith is reading between the lines
- Varying the number of GNN candidates or the exact serialization format could be tested as a low-cost way to improve robustness on longer reasoning chains.
- The approach may extend naturally to dynamic or streaming KGs where new facts arrive after the GNN is trained.
- Comparing GLOW directly against retrieval-augmented generation baselines on the same incomplete-graph questions would clarify the trade-off between prompt simplicity and external knowledge access.
- If the prompt format proves critical, analogous candidate-list techniques might help LLMs on other structured reasoning tasks such as program synthesis over code graphs.
Load-bearing premise
That feeding an LLM only the top-k GNN candidates plus a few KG facts in a fixed prompt is enough for it to correctly infer answers that require multi-hop reasoning over missing links.
What would settle it
Running GLOW on GLOW-BENCH questions where the true answer is deliberately excluded from the top-k GNN candidates and checking whether accuracy falls to the level of an LLM given only the raw question and graph facts.
Figures



read the original abstract
Open-world Question Answering (OW-QA) over knowledge graphs (KGs) aims to answer questions over incomplete or evolving KGs. Traditional KGQA assumes a closed world where answers must exist in the KG, limiting real-world applicability. In contrast, open-world QA requires inferring missing knowledge based on graph structure and context. Large language models (LLMs) excel at language understanding but lack structured reasoning. Graph neural networks (GNNs) model graph topology but struggle with semantic interpretation. Existing systems integrate LLMs with GNNs or graph retrievers. Some support open-world QA but rely on structural embeddings without semantic grounding. Most assume observed paths or complete graphs, making them unreliable under missing links or multi-hop reasoning. We present GLOW, a hybrid system that combines a pre-trained GNN and an LLM for open-world KGQA. The GNN predicts top-k candidate answers from the graph structure. These, along with relevant KG facts, are serialized into a structured prompt (e.g., triples and candidates) to guide the LLM's reasoning. This enables joint reasoning over symbolic and semantic signals, without relying on retrieval or fine-tuning. To evaluate generalization, we introduce GLOW-BENCH, a 1,000-question benchmark over incomplete KGs across diverse domains. GLOW outperforms existing LLM-GNN systems on standard benchmarks and GLOW-BENCH, achieving up to 53.3% and an average 38% improvement. GitHub code and data are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GLOW, a hybrid system combining a pre-trained GNN and an LLM for open-world question answering over incomplete knowledge graphs. The GNN generates top-k candidate answers from graph structure; these candidates plus serialized KG facts are fed into a fixed prompt for the LLM to perform reasoning without retrieval or fine-tuning. The work also contributes GLOW-BENCH, a 1,000-question benchmark over incomplete KGs across domains, and claims that GLOW outperforms prior LLM-GNN systems on both standard benchmarks and GLOW-BENCH, with gains of up to 53.3% and an average of 38%.
Significance. If the empirical results are robust, the approach offers a lightweight integration strategy that avoids retrieval and fine-tuning while attempting to combine structural prediction with semantic reasoning. The new benchmark addresses an important evaluation gap for open-world settings. However, the significance is limited by the absence of evidence that the prompt-based component reliably supports multi-hop inference when answers are missing from the provided facts.
major comments (2)
- [Method] Method section: The central mechanism serializes GNN top-k candidates and KG facts into a fixed prompt for the LLM to handle open-world inference. No ablation studies or targeted analysis are described that isolate the LLM's multi-hop reasoning performance on hard cases (e.g., 2+ hop questions with deliberately removed edges), which directly underpins the reported outperformance.
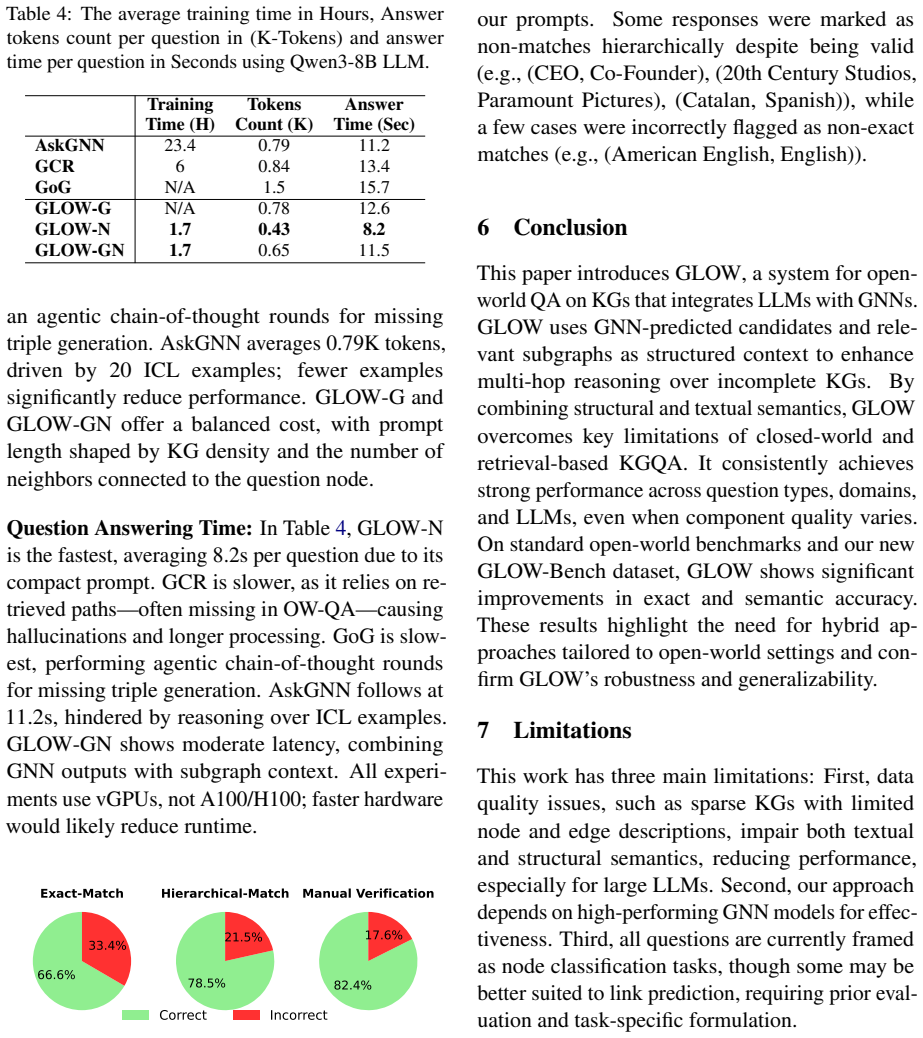
- [Experiments] Experiments section: Performance claims of up to 53.3% and average 38% improvement are stated without accompanying details on baseline implementations, statistical significance testing, error analysis, or construction specifics of GLOW-BENCH to confirm it evaluates missing-link scenarios. This prevents assessment of whether gains stem from the proposed integration.
minor comments (1)
- The abstract states that GitHub code and data are available, but no explicit link or repository identifier is provided in the text.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each of the major comments below, providing clarifications and committing to revisions that will enhance the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: [Method] Method section: The central mechanism serializes GNN top-k candidates and KG facts into a fixed prompt for the LLM to handle open-world inference. No ablation studies or targeted analysis are described that isolate the LLM's multi-hop reasoning performance on hard cases (e.g., 2+ hop questions with deliberately removed edges), which directly underpins the reported outperformance.
Authors: We recognize that the manuscript lacks explicit ablation studies isolating the LLM's multi-hop reasoning capabilities on challenging cases involving missing edges. The GLOW-BENCH was constructed to emphasize such scenarios, and the overall performance improvements suggest the value of the joint reasoning. To directly address this, we will include in the revised version a new subsection with ablation experiments. Specifically, we will evaluate GLOW against a GNN-only baseline on a subset of 2+ hop questions where edges have been removed to simulate open-world conditions. This will provide targeted evidence for the LLM's contribution to inferring missing knowledge. revision: yes
-
Referee: [Experiments] Experiments section: Performance claims of up to 53.3% and average 38% improvement are stated without accompanying details on baseline implementations, statistical significance testing, error analysis, or construction specifics of GLOW-BENCH to confirm it evaluates missing-link scenarios. This prevents assessment of whether gains stem from the proposed integration.
Authors: We agree that the current presentation of experimental results would benefit from greater transparency. In the revised manuscript, we will augment the Experiments section with comprehensive details: full specifications of baseline implementations (including any adaptations for open-world QA), statistical significance tests (such as Wilcoxon signed-rank tests) to validate the reported improvements, a detailed error analysis categorizing errors by factors like question complexity and degree of KG incompleteness, and explicit documentation of the GLOW-BENCH creation process, including question generation methods and verification that they target missing-link inference across domains. These enhancements will enable a clearer assessment of the integration's effectiveness. revision: yes
Circularity Check
No circularity: empirical system description with pre-trained components and benchmark results
full rationale
The paper presents GLOW as a hybrid integration of pre-trained GNN (for top-k candidate prediction) and LLM (via fixed prompt serialization of facts and candidates), evaluated empirically on existing benchmarks plus a new GLOW-BENCH. No equations, derivations, fitted parameters, or self-citations appear as load-bearing steps in the provided description. The outperformance claims rest on reported experimental results rather than any reduction of outputs to inputs by construction, self-definition, or imported uniqueness theorems. This is a standard empirical contribution whose central claims are externally falsifiable via replication on the released code and data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A linked data wrapper for crunchbase.Seman- tic Web, 9(4):505–515. Xiou Ge, Yun Cheng Wang, Bin Wang, C-C Jay Kuo, and 1 others. 2024. Knowledge graph embedding: An overview.APSIPA Transactions on Signal and Information Processing, 13(1). Jiawei Gu, Xuhui Jiang, and et.al. 2024. A survey on llm-as-a-judge.CoRR, abs/2411.15594. Oktie Hassanzadeh and Marian...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
SAFRAN: an interpretable, rule-based link prediction method outperforming embedding models. InAKBC. Andrea Rossi, Denilson Barbosa, and et.al. 2021a. Knowledge graph embedding for link prediction: A comparative analysis.ACM Trans. Knowl. Discov. Data, 15(2):14:1–14:49. Andrea Rossi, Denilson Barbosa, Donatella Firmani, Antonio Matinata, and Paolo Merialdo...
-
[3]
InESWC, volume 10843, pages 593–607
Modeling relational data with graph convo- lutional networks. InESWC, volume 10843, pages 593–607. Dong Shu, Tianle Chen, Mingyu Jin, Chong Zhang, Mengnan Du, and Yongfeng Zhang. 2024. Knowl- edge graph large language model (KG-LLM) for link prediction. InACML, volume 260 ofProceedings of Machine Learning Research, pages 143–158. PMLR. Jiashuo Sun, Chengj...
2024
-
[4]
BioRAG: A RAG-LLM Framework for Biological question Reasoning,
Biokg: A knowledge graph for relational learn- ing on biological data. InProceedings of the 29th ACM Conference on Information Knowledge Man- agement, page 3173–3180, New York, NY , USA. Association for Computing Machinery. Bo Wang, Tao Shen, Guodong Long, Tianyi Zhou, Ying Wang, and Yi Chang. 2021. Structure-augmented text representation learning for eff...
-
[5]
Stark: Benchmarking llm retrieval on tex- tual and relational knowledge bases. InAdvances in Neural Information Processing Systems, volume 37, pages 127129–127153. Curran Associates, Inc. Yuchen Xia, Jiho Kim, and et.al. 2024. Understanding the performance and estimating the cost of LLM fine- tuning. InIISWC, pages 210–223. IEEE. Yao Xu, Shizhu He, Jiabei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2504.05163 , year=
Decoupling the depth and scope of graph neu- ral networks. InNeurIPS, pages 19665–19679. Hanqing Zeng, Hongkuan Zhou, and et.al. 2020. Graphsaint: Graph sampling based inductive learn- ing method. InICLR. , GitHub Code: https:// github.com/snap-stanford/ogb/blob/master/ examples/nodeproppred/mag/graph_saint.py. Yuyu Zhang, Hanjun Dai, Alexander J Smola, a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.