Recognition: unknown
Geometric Context Transformer for Streaming 3D Reconstruction
Pith reviewed 2026-05-10 13:51 UTC · model grok-4.3
The pith
A geometric context transformer reconstructs 3D scenes from streaming video with stable performance at 20 frames per second over sequences exceeding 10,000 frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from streaming data, built upon a geometric context transformer (GCT) architecture. Its attention mechanism combines an anchor context, a pose-reference window, and a trajectory memory to handle coordinate grounding, dense geometric cues, and long-range drift correction. This keeps the streaming state compact while retaining rich geometric context, supporting stable inference at around 20 FPS on 518 x 378 inputs for sequences over 10,000 frames. Evaluations show superior performance against both streaming and iterative optimization methods.
What carries the argument
Geometric context transformer (GCT) whose attention mechanism integrates anchor context for coordinate grounding, pose-reference window for dense cues, and trajectory memory for drift correction.
If this is right
- Supports efficient inference on long video sequences exceeding 10,000 frames at 20 FPS without requiring iterative optimization.
- Achieves better accuracy and consistency than previous streaming and batch optimization approaches on standard benchmarks.
- Maintains a compact internal state that retains necessary geometric information for continuous reconstruction.
- Provides a foundation model approach that can be applied to various streaming 3D tasks.
Where Pith is reading between the lines
- Such models may allow integration into real-time systems like autonomous vehicles or AR headsets for on-device 3D mapping.
- Future work could explore scaling the approach to higher resolutions or incorporating additional sensor data.
- Replacing iterative SLAM components with transformer-based feed-forward passes might simplify deployment in varied environments.
Load-bearing premise
The specially designed attention mechanism can address coordinate grounding, extract dense cues, and correct long-range drift at the same time without introducing new errors or requiring manual tuning for each sequence.
What would settle it
Running the model on a 15,000-frame video sequence and observing whether pose estimation error exceeds thresholds from competing methods or frame rate falls below 20 FPS on the specified hardware.
Figures

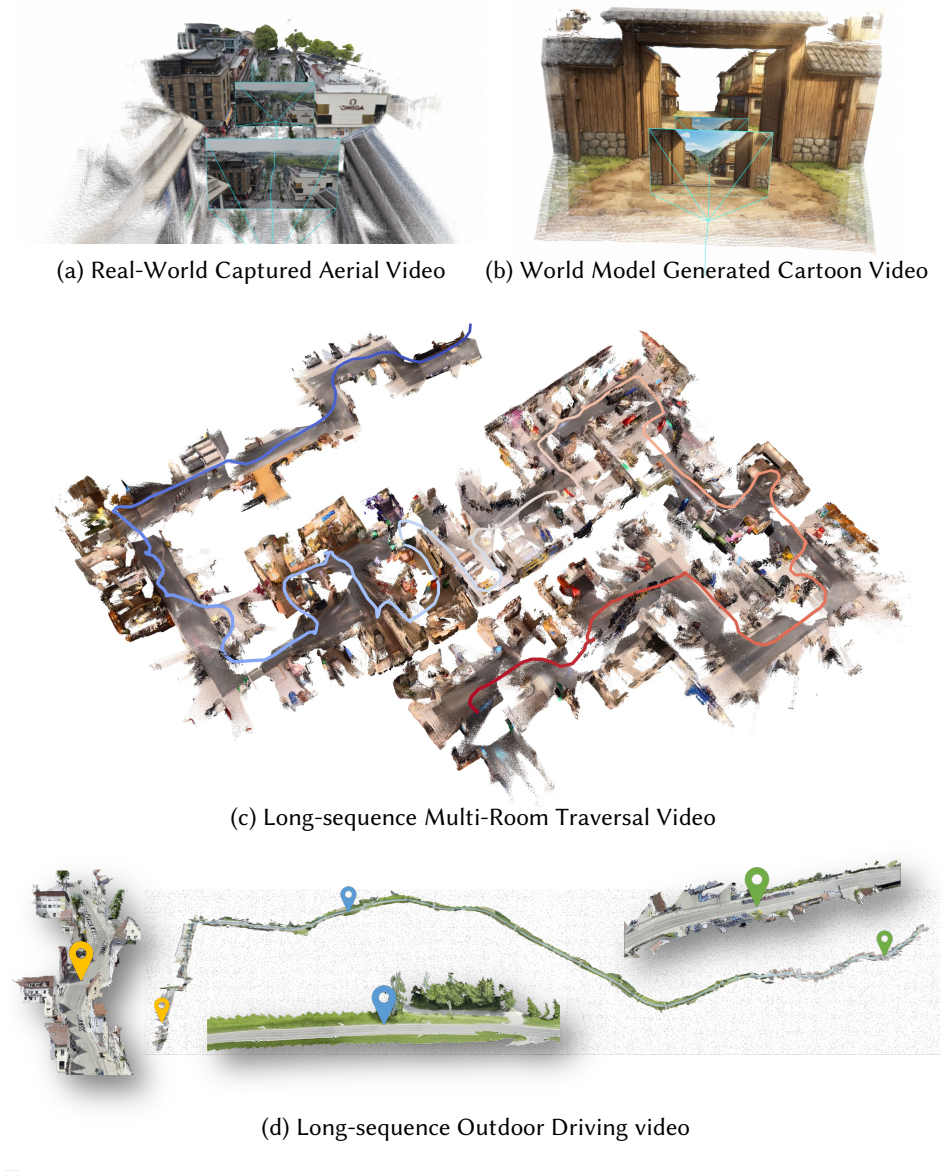
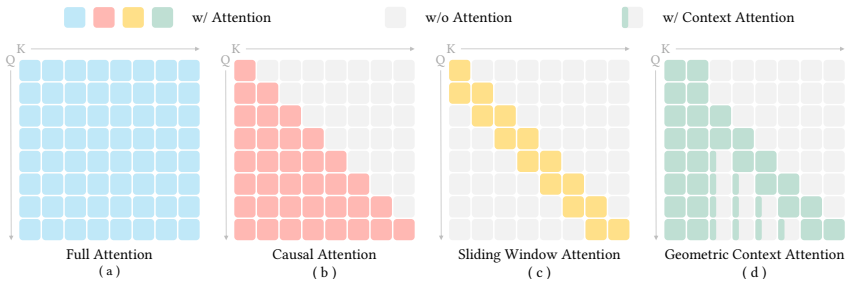
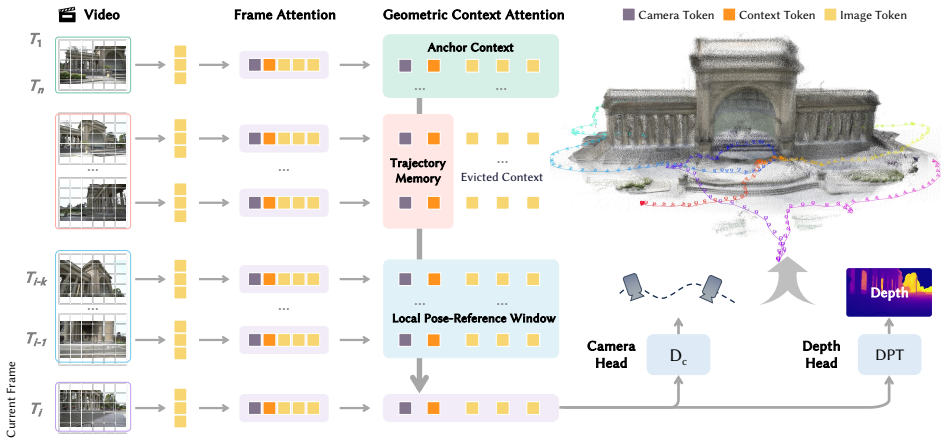


read the original abstract
Streaming 3D reconstruction aims to recover 3D information, such as camera poses and point clouds, from a video stream, which necessitates geometric accuracy, temporal consistency, and computational efficiency. Motivated by the principles of Simultaneous Localization and Mapping (SLAM), we introduce LingBot-Map, a feed-forward 3D foundation model for reconstructing scenes from streaming data, built upon a geometric context transformer (GCT) architecture. A defining aspect of LingBot-Map lies in its carefully designed attention mechanism, which integrates an anchor context, a pose-reference window, and a trajectory memory to address coordinate grounding, dense geometric cues, and long-range drift correction, respectively. This design keeps the streaming state compact while retaining rich geometric context, enabling stable efficient inference at around 20 FPS on 518 x 378 resolution inputs over long sequences exceeding 10,000 frames. Extensive evaluations across a variety of benchmarks demonstrate that our approach achieves superior performance compared to both existing streaming and iterative optimization-based approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LingBot-Map, a feed-forward 3D foundation model for streaming 3D reconstruction built on a Geometric Context Transformer (GCT). The GCT employs a custom attention mechanism integrating anchor context for coordinate grounding, a pose-reference window for dense geometric cues, and trajectory memory for long-range drift correction. The design is presented as maintaining a compact state while delivering superior accuracy and temporal consistency compared to both streaming and iterative optimization-based SLAM methods, with stable inference at ~20 FPS on 518×378 inputs for sequences exceeding 10,000 frames.
Significance. If the empirical claims hold under rigorous validation, the work could advance streaming 3D reconstruction by demonstrating that a learned feed-forward transformer with carefully factored geometric context can replace iterative optimization while preserving accuracy and efficiency over very long sequences. The compact state design and explicit handling of grounding, cues, and drift represent a coherent architectural contribution that, if substantiated, would be of interest to the SLAM and real-time vision communities.
major comments (2)
- [Evaluation / Experiments] The central performance claim (superior accuracy plus stable 20 FPS inference on sequences >10,000 frames) is load-bearing yet unsupported by any quantitative tables, ablation studies, cumulative drift curves, or hardware timing breakdowns in the evaluation section. Without these data the assertion that the three-part attention simultaneously solves grounding, cue extraction, and drift without new instabilities cannot be assessed.
- [§3] §3 (Architecture): the trajectory memory component is described only at a high level; no equations, update rules, or capacity analysis are supplied to show how it bounds drift accumulation over >10k frames, leaving the weakest assumption untested.
minor comments (2)
- [Abstract] The abstract states 'extensive evaluations across a variety of benchmarks' without naming the datasets or reporting key metrics (ATE, RPE, etc.), which would improve immediate readability.
- [§3] Notation for the attention modules (anchor context, pose-reference window, trajectory memory) is introduced without a compact summary table or diagram legend, making cross-references in later sections harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below and commit to substantial revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Experiments] The central performance claim (superior accuracy plus stable 20 FPS inference on sequences >10,000 frames) is load-bearing yet unsupported by any quantitative tables, ablation studies, cumulative drift curves, or hardware timing breakdowns in the evaluation section. Without these data the assertion that the three-part attention simultaneously solves grounding, cue extraction, and drift without new instabilities cannot be assessed.
Authors: We acknowledge that the current evaluation section relies primarily on qualitative demonstrations and high-level benchmark statements rather than the requested quantitative breakdowns. In the revised manuscript we will add (i) comprehensive accuracy tables on standard streaming and SLAM benchmarks, (ii) ablation studies isolating the contribution of each GCT component, (iii) cumulative drift curves plotted over sequences longer than 10,000 frames, and (iv) hardware-specific timing profiles confirming stable ~20 FPS inference. These additions will allow direct verification of the performance claims. revision: yes
-
Referee: [§3] §3 (Architecture): the trajectory memory component is described only at a high level; no equations, update rules, or capacity analysis are supplied to show how it bounds drift accumulation over >10k frames, leaving the weakest assumption untested.
Authors: We agree that the trajectory memory requires a more rigorous treatment. In the revised §3 we will supply the missing mathematical formulation, including explicit update equations, attention integration rules, and a capacity analysis that explains how the compact memory state bounds drift accumulation. We will also add supporting analysis or experiments demonstrating long-range stability. revision: yes
Circularity Check
No circularity: new architecture with independent design claims
full rationale
The paper presents LingBot-Map as a novel feed-forward model using a custom geometric context transformer (GCT) with three-part attention (anchor context, pose-reference window, trajectory memory). No equations, fitted parameters, or predictions are described that reduce claimed performance or stability to the inputs by construction. The design is motivated by SLAM principles but introduced as an original construction; performance claims rest on empirical evaluation rather than self-referential derivation. No self-citation chains or ansatzes are load-bearing in the provided text. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention mechanisms can be extended with custom geometric contexts to maintain coordinate grounding, dense cues, and drift correction simultaneously
invented entities (4)
-
Geometric Context Transformer (GCT)
no independent evidence
-
anchor context
no independent evidence
-
pose-reference window
no independent evidence
-
trajectory memory
no independent evidence
Forward citations
Cited by 2 Pith papers
-
NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down Maps
NavOne reformulates vision-language navigation as single-step global path planning on top-down maps, delivering state-of-the-art results and 8x-80x speedups over prior map-based and egocentric baselines.
-
NavOne: One-Step Global Planning for Vision-Language Navigation on Top-Down Maps
NavOne enables one-step global navigation planning on top-down maps using a unified multi-modal framework, achieving state-of-the-art results and up to 80x speedup on the new R2R-TopDown dataset.
Reference graph
Works this paper leans on
-
[1]
Map-free visual relocalization: Metric pose relative to a single image
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Daniyar Turmukhambetov, and Eric Brachmann. Map-free visual relocalization: Metric pose relative to a single image. InEur. Conf. Comput. Vis., pages 690–708. Springer, 2022
2022
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi ´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6290–6301, 2022
2022
-
[3]
Yohann Cabon, Naila Murray, and Martin Humenberger. Virtual kitti 2.arXiv preprint arXiv:2001.10773, 2020
work page internal anchor Pith review arXiv 2001
-
[4]
Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
Carlos Campos, Richard Elvira, Juan J Gómez Rodríguez, José MM Montiel, and Juan D Tardós. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
2021
-
[5]
Matterport3d: Learning from RGB-D data in indoor environments
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from RGB-D data in indoor environments. InInternational Conference on 3D Vision (3DV), 2017
2017
-
[6]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InInt. Conf. Comput. Vis., pages 9158–9168, 2025
2025
-
[7]
Ttt3r: 3d reconstruction as test-time training.Int
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Ttt3r: 3d reconstruction as test-time training.Int. Conf. Learn. Represent., 2026
2026
-
[8]
Long3r: Long sequence streaming 3d reconstruction
Zhuoguang Chen, Minghui Qin, Tianyuan Yuan, Zhe Liu, and Hang Zhao. Long3r: Long sequence streaming 3d reconstruction. InInt. Conf. Comput. Vis., pages 5273–5284, 2025
2025
-
[9]
Scannet: Richly- annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InIEEE Conf. Comput. Vis. Pattern Recog., pages 5828–5839, 2017
2017
-
[10]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InIEEE Conf. Comput. Vis. Pattern Recog., pages 13142–13153, 2023
2023
-
[11]
Kai Deng, Zexin Ti, Jiawei Xu, Jian Yang, and Jin Xie. Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences.arXiv preprint arXiv:2507.16443, 2025. 19
-
[12]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018
2018
-
[13]
St4rtrack: Simultaneous 4d reconstruction and tracking in the world
Haiwen Feng, Junyi Zhang, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J Black, Trevor Darrell, and Angjoo Kanazawa. St4rtrack: Simultaneous 4d reconstruction and tracking in the world. InInt. Conf. Comput. Vis., pages 8503–8513, 2025
2025
-
[14]
Mid-air: A multi-modal dataset for extremely low altitude drone flights
Michael Fonder and Marc Van Droogenbroeck. Mid-air: A multi-modal dataset for extremely low altitude drone flights. In Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), June 2019
2019
-
[15]
Accurate, dense, and robust multiview stereopsis.IEEE transactions on pattern analysis and machine intelligence, 32(8):1362–1376, 2009
Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multiview stereopsis.IEEE transactions on pattern analysis and machine intelligence, 32(8):1362–1376, 2009
2009
-
[16]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InIEEE Conf. Comput. Vis. Pattern Recog., pages 3749–3761, 2022
2022
-
[17]
LRM: Large reconstruction model for single image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3D. InInt. Conf. Learn. Represent., 2024
2024
-
[18]
Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, et al. Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
-
[19]
Deepmvs: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. Deepmvs: Learning multi-view stereopsis. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2821–2830, 2018
2018
-
[20]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models. arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors
Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, and Jerome Revaud. Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors. InIEEE Conf. Comput. Vis. Pattern Recog., pages 1071–1081, 2025
2025
-
[22]
Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Trans
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.ACM Trans. Graph., 44(6):1–16, 2025
2025
-
[23]
Barron, Noah Snavely, and Aleksander Hoły´nski
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, and Aleksander Hoły´nski. Zipmap: Linear-time stateful 3d reconstruction via test-time training. InIEEE Conf. Comput. Vis. Pattern Recog., 2026
2026
-
[24]
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos. InIEEE Conf. Comput. Vis. Pattern Recog., 2025
2025
-
[25]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Trans
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Trans. Graph., 36(4), 2017
2017
-
[27]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[28]
STream3R: Scalable sequential 3D reconstruction with causal transformer
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. STream3R: Scalable sequential 3D reconstruction with causal transformer. InInt. Conf. Learn. Represent., 2026
2026
-
[29]
Instant3d: Fast text-to-3D with sparse-view generation and large reconstruction model
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3D with sparse-view generation and large reconstruction model. InInt. Conf. Learn. Represent., 2024
2024
-
[30]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, and Bo Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. InInt. Conf. Comput. Vis., pages 3205–3215, 2023
2023
-
[31]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2041–2050, 2018. 20
2041
-
[32]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10486–10496, 2025
2025
-
[33]
Wint3r: Window-based streaming reconstruction with camera token pool
Zizun Li, Jianjun Zhou, Yifan Wang, Haoyu Guo, Wenzheng Chang, Yang Zhou, Haoyi Zhu, Junyi Chen, Chunhua Shen, and Tong He. Wint3r: Window-based streaming reconstruction with camera token pool. InInt. Conf. Learn. Represent., 2026
2026
-
[34]
Torchtitan: One-stop pytorch native solution for production ready LLM pretraining
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. Torchtitan: One-stop pytorch native solution for production ready LLM pretraining. InInt. Conf. Learn. Represent., 2025
2025
-
[35]
Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Trans
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.IEEE Trans. Pattern Anal. Mach. Intell., 45(3):3292–3310, 2022
2022
-
[36]
Longsplat: Robust unposed 3d gaussian splatting for casual long videos
Chin-Yang Lin, Cheng Sun, Fu-En Yang, Min-Hung Chen, Yen-Yu Lin, and Yu-Lun Liu. Longsplat: Robust unposed 3d gaussian splatting for casual long videos. InInt. Conf. Comput. Vis., pages 27412–27422, 2025
2025
-
[37]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InIEEE Conf. Comput. Vis. Pattern Recog., pages 22160–22169, 2024
2024
-
[39]
Slam3r: Real-time dense scene reconstruction from monocular rgb videos
Yuzheng Liu, Siyan Dong, Shuzhe Wang, Yingda Yin, Yanchao Yang, Qingnan Fan, and Baoquan Chen. Slam3r: Real-time dense scene reconstruction from monocular rgb videos. InIEEE Conf. Comput. Vis. Pattern Recog., pages 16651–16662, 2025
2025
-
[40]
Align3r: Aligned monocular depth estimation for dynamic videos
Jiahao Lu, Tianyu Huang, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, and Yuan Liu. Align3r: Aligned monocular depth estimation for dynamic videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22820–22830, 2025
2025
-
[41]
Matrix3d: Large photogrammetry model all-in-one
Yuanxun Lu, Jingyang Zhang, Tian Fang, Jean-Daniel Nahmias, Yanghai Tsin, Long Quan, Xun Cao, Yao Yao, and Shiwei Li. Matrix3d: Large photogrammetry model all-in-one. InIEEE Conf. Comput. Vis. Pattern Recog., pages 11250–11263, 2025
2025
-
[42]
Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.Adv
Dominic Maggio, Hyungtae Lim, and Luca Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.Adv. Neural Inform. Process. Syst., 39, 2025
2025
-
[43]
Scenenet rgb-d: Can 5m synthetic images beat generic imagenet pre-training on indoor segmentation? InInt
John McCormac, Ankur Handa, Stefan Leutenegger, and Andrew J.Davison. Scenenet rgb-d: Can 5m synthetic images beat generic imagenet pre-training on indoor segmentation? InInt. Conf. Comput. Vis., 2017
2017
-
[44]
Orb-slam: A versatile and accurate monocular slam system
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: A versatile and accurate monocular slam system. IEEE transactions on robotics, 31(5):1147–1163, 2015
2015
-
[45]
Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE transactions on robotics, 33(5):1255–1262, 2017
Raul Mur-Artal and Juan D Tardós. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras.IEEE transactions on robotics, 33(5):1255–1262, 2017
2017
-
[46]
Mast3r-slam: Real-time dense slam with 3d reconstruction priors
Riku Murai, Eric Dexheimer, and Andrew J Davison. Mast3r-slam: Real-time dense slam with 3d reconstruction priors. In IEEE Conf. Comput. Vis. Pattern Recog., pages 16695–16705, 2025
2025
-
[47]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
2023
-
[48]
Global structure-from-motion revisited
Linfei Pan, Dániel Baráth, Marc Pollefeys, and Johannes L Schönberger. Global structure-from-motion revisited. InEuropean Conference on Computer Vision, pages 58–77. Springer, 2024
2024
-
[49]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Peters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng Carl Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. InInt. Conf. Comput. Vis., pages 20133–20143, 2023
2023
-
[50]
Tartanground: A large-scale dataset for ground robot perception and navigation
Manthan Patel, Fan Yang, Yuheng Qiu, Cesar Cadena, Sebastian Scherer, Marco Hutter, and Wenshan Wang. Tartanground: A large-scale dataset for ground robot perception and navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 20524–20531. IEEE, 2025. 21
2025
-
[51]
Chang, Manolis Savva, Yili Zhao, and Dhruv Batra
Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X. Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. Habitat- matterport 3D dataset (HM3D): 1000 large-scale 3D environments for embodied AI. InAdv. Neural Inform. Process. Syst., 2021
2021
-
[52]
Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Common objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InInt. Conf. Comput. Vis., pages 10901–10911, 2021
2021
-
[53]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InInt. Conf. Comput. Vis., pages 10912–10922, 2021
2021
-
[54]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020
2020
-
[55]
Habitat: A platform for embodied ai research
Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, et al. Habitat: A platform for embodied ai research. InInt. Conf. Comput. Vis., pages 9339–9347, 2019
2019
-
[56]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[57]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision, pages 501–518. Springer, 2016
2016
-
[58]
A multi-view stereo benchmark with high-resolution images and multi-camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InIEEE Conf. Comput. Vis. Pattern Recog., pages 3260–3269, 2017
2017
-
[59]
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, and Liujuan Cao. Fastvggt: Training-free acceleration of visual geometry transformer.arXiv preprint arXiv:2509.02560, 2025
-
[60]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2930–2937, 2013
2013
-
[61]
Brandon Smart, Chuanxia Zheng, Iro Laina, and Victor Adrian Prisacariu. Splatt3r: Zero-shot gaussian splatting from uncalibrated image pairs.arXiv preprint arXiv:2408.13912, 2024
-
[62]
Seitz, and Richard Szeliski
Noah Snavely, Steven M. Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d.ACM Trans. Graph., 25(3):835–846, 2006
2006
-
[63]
The Replica Dataset: A Digital Replica of Indoor Spaces
Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, et al. The replica dataset: A digital replica of indoor spaces.arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review arXiv 1906
-
[64]
Dynamic point maps: A versatile representation for dynamic 3d reconstruction
Edgar Sucar, Zihang Lai, Eldar Insafutdinov, and Andrea Vedaldi. Dynamic point maps: A versatile representation for dynamic 3d reconstruction. InInt. Conf. Comput. Vis., pages 7295–7305, 2025
2025
-
[65]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8922–8931, 2021
2021
-
[66]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InIEEE Conf. Comput. Vis. Pattern Recog., pages 2446–2454, 2020
2020
-
[67]
LGM: Large multi-view gaussian model for high-resolution 3D content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. LGM: Large multi-view gaussian model for high-resolution 3D content creation. InEur. Conf. Comput. Vis., 2024
2024
-
[68]
The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods.International Journal of Robotics Research, 2025
Yifu Tao, Miguel Ángel Muñoz-Bañón, Lintong Zhang, Jiahao Wang, Lanke Frank Tarimo Fu, and Maurice Fallon. The oxford spires dataset: Benchmarking large-scale lidar-visual localisation, reconstruction and radiance field methods.International Journal of Robotics Research, 2025
2025
-
[69]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Adv
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Adv. Neural Inform. Process. Syst., 34:16558–16569, 2021. 22
2021
-
[70]
Smd-nets: Stereo mixture density networks
Fabio Tosi, Yiyi Liao, Carolin Schmitt, and Andreas Geiger. Smd-nets: Stereo mixture density networks. InIEEE Conf. Comput. Vis. Pattern Recog., pages 8942–8952, 2021
2021
-
[71]
Least-squares estimation of transformation parameters between two point patterns.IEEE Trans
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Trans. Pattern Anal. Mach. Intell., 13(4):376–380, 2002
2002
-
[72]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
3d reconstruction with spatial memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory. In3DV, pages 78–89. IEEE, 2025
2025
-
[74]
Spatialvid: A large-scale video dataset with spatial annotations
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations. InIEEE Conf. Comput. Vis. Pattern Recog., 2026
2026
-
[75]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InIEEE Conf. Comput. Vis. Pattern Recog., 2025
2025
-
[76]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21686–21697, 2024
2024
-
[77]
Flow-motion and depth network for monocular stereo and beyond.IEEE Robotics and Automation Letters, 5(2):3307–3314, 2020
Kaixuan Wang and Shaojie Shen. Flow-motion and depth network for monocular stereo and beyond.IEEE Robotics and Automation Letters, 5(2):3307–3314, 2020
2020
-
[78]
PF-LRM: Pose-free large reconstruction model for joint pose and shape prediction
Peng Wang, Hao Tan, Sai Bi, Yinghao Xu, Fujun Luan, Kalyan Sunkavalli, Wenping Wang, Zexiang Xu, and Kai Zhang. PF-LRM: Pose-free large reconstruction model for joint pose and shape prediction. InInt. Conf. Learn. Represent., 2024
2024
-
[79]
Efros, and Angjoo Kanazawa
Qianqian Wang*, Yifei Zhang*, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InIEEE Conf. Comput. Vis. Pattern Recog., 2025
2025
-
[80]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InIEEE Conf. Comput. Vis. Pattern Recog., pages 10510–10522, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.