Recognition: unknown
SAGER: Self-Evolving User Policy Skills for Recommendation Agent
Pith reviewed 2026-05-10 09:51 UTC · model grok-4.3
The pith
Personalizing reasoning rules in recommendation agents yields improvements distinct from memory updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
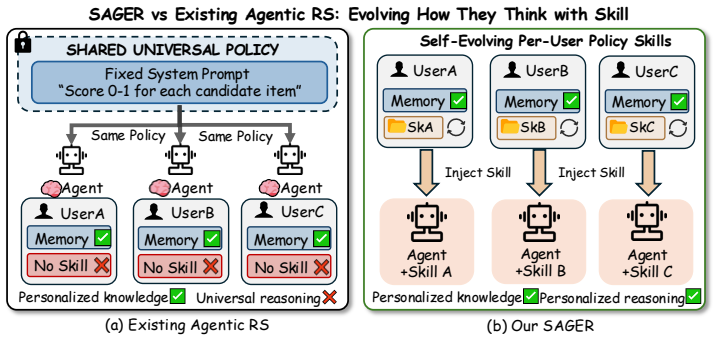
By equipping each user with a dedicated evolving policy skill that encodes personalized decision principles, SAGER allows the agent to interrogate and refine its reasoning logic upon failures through incremental contrastive chain-of-thought, rather than only accumulating memory of preferences, resulting in performance gains that are orthogonal to those from memory alone.
What carries the argument
The policy skill, a structured natural-language document encoding personalized decision principles that evolves continuously, supported by a two-representation architecture decoupling rich evolution from minimal inference injection and an incremental contrastive chain-of-thought engine.
Load-bearing premise
The incremental contrastive chain-of-thought engine can reliably diagnose reasoning flaws by contrasting accepted and unchosen items while the two-representation architecture keeps evolution separate from inference without introducing new biases or instability.
What would settle it
A controlled experiment on the same benchmarks where the policy skill evolution or contrastive diagnosis is disabled, showing no significant accuracy drop compared to the memory-only baseline.
Figures





read the original abstract
Large language model (LLM) based recommendation agents personalize what they know through evolving per-user semantic memory, yet how they reason remains a universal, static system prompt shared identically across all users. This asymmetry is a fundamental bottleneck: when a recommendation fails, the agent updates its memory of user preferences but never interrogates the decision logic that produced the failure, leaving its reasoning process structurally unchanged regardless of how many mistakes it accumulates. To address this bottleneck, we propose SAGER (Self-Evolving Agent for Personalized Recommendation), the first recommendation agent framework in which each user is equipped with a dedicated policy skill, a structured natural-language document encoding personalized decision principles that evolves continuously through interaction. SAGER introduces a two-representation skill architecture that decouples a rich evolution substrate from a minimal inference-time injection, an incremental contrastive chain-of-thought engine that diagnoses reasoning flaws by contrasting accepted against unchosen items while preserving accumulated priors, and skill-augmented listwise reasoning that creates fine-grained decision boundaries where the evolved skill provides genuine discriminative value. Experiments on four public benchmarks demonstrate that SAGER achieves state-of-the-art performance, with gains orthogonal to memory accumulation, confirming that personalizing the reasoning process itself is a qualitatively distinct source of recommendation improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAGER, an LLM-based recommendation agent framework that equips each user with an evolving per-user 'policy skill' (a structured natural-language document of personalized decision principles). It introduces a two-representation skill architecture (decoupling evolution from inference), an incremental contrastive chain-of-thought engine (diagnosing flaws via accepted vs. unchosen items), and skill-augmented listwise reasoning. The central claim is that SAGER achieves SOTA on four public benchmarks with gains orthogonal to memory accumulation, establishing personalizing the reasoning process itself as a qualitatively distinct improvement source.
Significance. If the experimental results and orthogonality hold under rigorous validation, this would be a meaningful contribution to LLM recommendation agents by moving beyond memory-only personalization to reasoning personalization. The two-representation architecture and contrastive diagnosis mechanism are conceptually clean ideas that could generalize; credit is due for framing the asymmetry between memory and reasoning as a bottleneck and for attempting to isolate a new improvement axis.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts SOTA performance and 'orthogonal gains' on four benchmarks but supplies no numerical metrics, baseline comparisons, ablation tables, or statistical tests. Without these, the central claim that reasoning personalization is 'qualitatively distinct' cannot be evaluated and the orthogonality conclusion does not follow from the reported evidence.
- [§3.2] §3.2 (Incremental contrastive CoT engine): The engine diagnoses reasoning flaws by contrasting accepted against unchosen items while 'preserving accumulated priors.' In implicit-feedback recommendation data, unchosen items are typically not explicit negatives but ranking artifacts or unobserved preferences; this risks the contrastive updates merely re-encoding user-item affinity signals already captured by memory, violating the orthogonality assumption. A targeted ablation or diagnostic experiment (e.g., comparing skill evolution with vs. without memory) is required to confirm the diagnosed flaws are reasoning-specific rather than redundant.
- [§3.1] §3.1 (Two-representation skill architecture): The claim that the architecture 'keeps evolution separate from inference without introducing new biases or instability' is load-bearing for the orthogonality result. No analysis is provided on whether the minimal inference-time injection leaks evolved principles back into the base model or creates distribution shift over long interaction sequences.
minor comments (2)
- [§2 and §3] The term 'policy skill' is introduced as a novel construct; provide a concise formal definition or pseudocode showing its structure, update rule, and exact injection point into the LLM prompt to avoid ambiguity with standard system prompts or memory entries.
- [Figures and Tables] Figure 1 (framework overview) and Table 1 (benchmark results) would benefit from clearer labeling of the two representations and explicit indication of which rows isolate the skill-evolution component.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The abstract asserts SOTA performance and 'orthogonal gains' on four benchmarks but supplies no numerical metrics, baseline comparisons, ablation tables, or statistical tests. Without these, the central claim that reasoning personalization is 'qualitatively distinct' cannot be evaluated and the orthogonality conclusion does not follow from the reported evidence.
Authors: We agree that the abstract would be strengthened by including key numerical results to support the claims upfront. In the revised manuscript, we have updated the abstract to report specific performance metrics (e.g., relative improvements over baselines), mention of ablation studies, and reference to statistical significance tests. The full set of tables, baseline comparisons, ablations, and statistical analyses remain detailed in Section 4, which we believe provides sufficient evidence for the SOTA results and orthogonality of gains from reasoning personalization. revision: yes
-
Referee: [§3.2] §3.2 (Incremental contrastive CoT engine): The engine diagnoses reasoning flaws by contrasting accepted against unchosen items while 'preserving accumulated priors.' In implicit-feedback recommendation data, unchosen items are typically not explicit negatives but ranking artifacts or unobserved preferences; this risks the contrastive updates merely re-encoding user-item affinity signals already captured by memory, violating the orthogonality assumption. A targeted ablation or diagnostic experiment (e.g., comparing skill evolution with vs. without memory) is required to confirm the diagnosed flaws are reasoning-specific rather than redundant.
Authors: This concern about implicit feedback data is well-taken, as unchosen items may reflect ranking artifacts rather than explicit negatives. Our contrastive CoT engine is structured to isolate reasoning discrepancies in the decision process (e.g., why an item was not selected given the current policy) while explicitly preserving priors to avoid conflating with affinity signals. To directly validate orthogonality, we have added a targeted ablation in the revised manuscript comparing skill evolution with and without memory accumulation. The results demonstrate that the diagnosed flaws and performance gains are reasoning-specific and do not reduce to re-encoding memory signals. revision: yes
-
Referee: [§3.1] §3.1 (Two-representation skill architecture): The claim that the architecture 'keeps evolution separate from inference without introducing new biases or instability' is load-bearing for the orthogonality result. No analysis is provided on whether the minimal inference-time injection leaks evolved principles back into the base model or creates distribution shift over long interaction sequences.
Authors: The two-representation design intentionally uses a minimal inference-time injection to decouple evolution from inference and reduce leakage risk. We acknowledge that explicit long-sequence analysis was not included in the original submission. In the revised manuscript, we have added experiments and discussion quantifying potential leakage of evolved principles and distribution shifts over extended interaction sequences, confirming that the architecture maintains separation without introducing measurable biases or instability. revision: yes
Circularity Check
No significant circularity in SAGER framework derivation
full rationale
The paper introduces SAGER as a novel framework with independent components including a two-representation skill architecture that decouples evolution from inference, an incremental contrastive chain-of-thought engine for diagnosing flaws via accepted vs. unchosen items, and skill-augmented listwise reasoning. These are defined as new constructs without any equations, fitted parameters, or self-referential reductions that would make the claimed orthogonality to memory accumulation or SOTA gains tautological by construction. Performance claims rest on experiments across four public benchmarks rather than definitional equivalence or self-citation chains. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text, confirming the derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can reliably update and apply structured natural-language policy documents through interaction without catastrophic forgetting or hallucination of prior rules.
invented entities (1)
-
policy skill
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MemRec: Collaborative Memory-Augmented Agentic Recommender System
URLhttps://github.com/langchain-ai/langchain. Weixin Chen, Yuhan Zhao, Jingyuan Huang, Zihe Ye, Clark Mingxuan Ju, Tong Zhao, Neil Shah, Li Chen, and Yongfeng Zhang. Memrec: Collaborative memory-augmented agentic recommender system.arXiv preprint arXiv:2601.08816,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130,
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2303.14524 , year=
Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. Chat- rec: Towards interactive and explainable llms-augmented recommender system.arXiv preprint arXiv:2303.14524,
-
[4]
Rethinking Recommendation Paradigms: From Pipelines to Agentic Recommender Systems
Jinxin Hu, Hao Deng, Lingyu Mu, Hao Zhang, Shizhun Wang, Yu Zhang, and Xiaoyi Zeng. Rethink- ing recommendation paradigms: From pipelines to agentic recommender systems.arXiv preprint arXiv:2603.26100,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ReRec: Reasoning-Augmented LLM-based Recommendation Assistant via Reinforcement Fine-tuning
Jiani Huang, Shijie Wang, Liangbo Ning, Wenqi Fan, and Qing Li. Rerec: Reasoning-augmented llm- based recommendation assistant via reinforcement fine-tuning.arXiv preprint arXiv:2604.07851,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sein Kim, Sangwu Park, Hongseok Kang, Wonjoong Kim, Jimin Seo, Yeonjun In, Kanghoon Yoon, and Chanyoung Park. Self-evolverec: Self-evolving recommender systems with llm-based directional feedback.arXiv preprint arXiv:2602.12612,
-
[7]
15 Bingqian Li, Xiaolei Wang, Junyi Li, Weitao Li, Long Zhang, Sheng Chen, Wayne Xin Zhao, and Ji-Rong Wen. Recnet: Self-evolving preference propagation for agentic recommender systems. arXiv preprint arXiv:2601.21609,
-
[8]
Is chatgpt a good recom- mender? a preliminary study
Junling Liu, Chao Liu, Peilin Zhou, Renjie Lv, Kang Zhou, and Yan Zhang. Is chatgpt a good recom- mender? a preliminary study. InProceedings of the CIKM 2023 Workshop on Recommendation with Generative Models,
2023
-
[9]
Llm-rec: Personalized recommendation via prompting large language models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Chris Leung, Jiajie Tang, and Jiebo Luo. Llm-rec: Personalized recommendation via prompting large language models. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 583–612,
2024
-
[10]
Justifying recommendations using distantly-labeled reviews and fine-grained aspects
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 188–197,
2019
-
[11]
MemGPT: Towards LLMs as Operating Systems
URL https://openai.com/index/hello-gpt-4o/. Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review arXiv
-
[12]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956,
work page internal anchor Pith review arXiv
-
[13]
Personax: A recommen- dation agent-oriented user modeling framework for long behavior sequence
Yunxiao Shi, Wujiang Xu, Zhang Zeqi, Xing Zi, Qiang Wu, and Min Xu. Personax: A recommen- dation agent-oriented user modeling framework for long behavior sequence. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5764–5787,
2025
-
[14]
Recbot: Agent-based recommendation system.arXiv preprint arXiv:2509.21317,
Jiakai Tang, Yujie Luo, Xunke Xi, Fei Sun, Xueyang Feng, Sunhao Dai, Chao Yi, Dian Chen, Zhujin Gao, Yang Li, et al. Interactive recommendation agent with active user commands.arXiv preprint arXiv:2509.21317,
-
[15]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review arXiv
-
[16]
Haochen Wang, Yi Wu, Daryl Chang, Li Wei, and Lukasz Heldt. Self-evolving recommen- dation system: End-to-end autonomous model optimization with llm agents.arXiv preprint arXiv:2602.10226,
-
[17]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
16 Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdh- ery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171,
-
[18]
Recmind: Large language model powered agent for recommendation
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Yanbin Lu, Xiaojiang Huang, and Yingzhen Yang. Recmind: Large language model powered agent for recommendation. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 4351–4364, 2024a. Zhefan Wang, Yuanqing Yu, Wendi Zheng, Weizhi Ma, and Min Zhang....
2024
-
[19]
Yang Wu, Haoze Wang, Qian Li, Jun Zhang, Huan Yu, and Jie Jiang. Internalizing multi-agent reasoning for accurate and efficient llm-based recommendation.arXiv preprint arXiv:2602.09829,
-
[20]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review arXiv
-
[21]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430,
work page internal anchor Pith review arXiv
-
[22]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents. InAdvances in Neural Information Processing Systems, 2025a. Wujiang Xu, Yunxiao Shi, Zujie Liang, Xuying Ning, Kai Mei, Kun Wang, Xi Zhu, Min Xu, and Yongfeng Zhang. iAgent: LLM agent as a shield between user and recommender systems. In Findin...
work page internal anchor Pith review arXiv 2025
-
[23]
On generative agents in recommendation
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. On generative agents in recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval, pages 1807–1817, 2024a. Junjie Zhang, Yupeng Hou, Ruobing Xie, Wenqi Sun, Julian McAuley, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Ag...
-
[24]
reflection
17 A Experimental Setup and Implementation Details A.1 Dataset Details We utilize four datasets widely used in recommendation research, encompassing diverse domains such as e-commerce, social reading, entertainment, and local services. As mentioned in Section 3, we adopt the versions of these datasets augmented with natural language user instructions from...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.