Recognition: unknown
AtManRL: Towards Faithful Reasoning via Differentiable Attention Saliency
Pith reviewed 2026-05-10 08:05 UTC · model grok-4.3
The pith
Training an attention mask on chain-of-thought tokens supplies a saliency reward that pushes language models to generate reasoning traces which genuinely shape their final answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training an additive attention mask that identifies tokens in the CoT crucial for producing correct answers, we derive a saliency reward signal that encourages the model to generate reasoning traces that genuinely influence its final predictions. We integrate this saliency reward with outcome-based rewards within the GRPO framework to jointly optimize for correctness and interpretability.
What carries the argument
An additive attention mask trained via reinforcement learning on chain-of-thought tokens; the mask singles out those tokens whose attention most affects the model's final prediction and converts that selection into a saliency reward.
If this is right
- The model learns to emit reasoning traces in which the included tokens measurably affect the correctness of the final answer.
- Joint optimization of saliency and outcome rewards produces reasoning that is both accurate and more interpretable.
- The approach surfaces specific influential tokens within the chain-of-thought on GSM8K and MMLU benchmarks.
- The resulting models exhibit more transparent reasoning processes than those trained with outcome rewards alone.
Where Pith is reading between the lines
- The method could be applied at inference time to prune or edit reasoning steps whose tokens show low saliency, potentially cutting unhelpful or misleading explanations.
- If the mask truly isolates causal tokens, the same signal might serve as an audit tool to check whether a model's stated reasoning matches its internal computation.
- Extending the mask learning to longer or multi-step tasks could reveal whether faithfulness scales beyond the short arithmetic and multiple-choice problems tested here.
- The technique opens the possibility of reward shaping that penalizes reasoning tokens the mask deems irrelevant, encouraging more concise and directed chains of thought.
Load-bearing premise
The learned attention mask on chain-of-thought tokens identifies tokens that causally influence the final answer rather than merely correlating with correct outcomes.
What would settle it
Mask or remove the tokens the trained attention mask flags as salient and measure whether the model's final answer changes more often or by a larger amount than when the same number of non-salient tokens are removed.
Figures







read the original abstract
Large language models (LLMs) increasingly rely on chain-of-thought (CoT) reasoning to solve complex tasks. Yet ensuring that the reasoning trace both contributes to and faithfully reflects the processes underlying the model's final answer, rather than merely accompanying it, remains challenging. We introduce AtManRL, a method that leverages differentiable attention manipulation to learn more faithful reasoning through reinforcement learning. By training an additive attention mask that identifies tokens in the CoT crucial for producing correct answers, we derive a saliency reward signal that encourages the model to generate reasoning traces that genuinely influence its final predictions. We integrate this saliency reward with outcome-based rewards within the GRPO framework to jointly optimize for correctness and interpretability. Experiments on GSM8K and MMLU with Llama-3.2-3B-Instruct demonstrate that our approach can identify influential reasoning tokens and enable training more transparent reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AtManRL, which trains an additive attention mask via differentiable manipulation on chain-of-thought tokens to identify those crucial for producing correct answers. A saliency reward is derived from this mask and combined with outcome rewards inside the GRPO reinforcement learning framework to jointly optimize for correctness and faithful reasoning. Experiments are claimed on GSM8K and MMLU using Llama-3.2-3B-Instruct to show that the approach identifies influential reasoning tokens and yields more transparent models.
Significance. If the learned mask reliably isolates causally influential tokens rather than answer-correlated ones, the method would offer a concrete mechanism for enforcing faithfulness in CoT reasoning through RL, addressing a key limitation in current interpretability approaches for LLMs.
major comments (2)
- [Method] The method description states that the attention mask is trained to highlight tokens crucial for correct answers and that the resulting saliency reward is folded into GRPO; however, no explicit causal intervention or counterfactual test is described to distinguish tokens with genuine causal influence on the final prediction from those that are merely statistically associated with correct answers in the data distribution. This distinction is load-bearing for the claim that the reward encourages reasoning traces that 'genuinely influence' predictions.
- [Experiments] The abstract asserts that experiments on GSM8K and MMLU demonstrate identification of influential tokens and more transparent models, yet no quantitative metrics, baselines, ablation studies, or error analysis are referenced. Without these, it is impossible to assess whether the combined saliency-plus-outcome objective improves faithfulness beyond what outcome rewards alone achieve.
minor comments (1)
- [Abstract] The term 'transparent reasoning models' is used without a precise definition or measurement protocol (e.g., human faithfulness ratings, intervention-based metrics, or attention alignment scores).
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which help clarify the presentation of our method and experiments. We address each major point below.
read point-by-point responses
-
Referee: [Method] The method description states that the attention mask is trained to highlight tokens crucial for correct answers and that the resulting saliency reward is folded into GRPO; however, no explicit causal intervention or counterfactual test is described to distinguish tokens with genuine causal influence on the final prediction from those that are merely statistically associated with correct answers in the data distribution. This distinction is load-bearing for the claim that the reward encourages reasoning traces that 'genuinely influence' predictions.
Authors: We appreciate the referee's emphasis on rigorously distinguishing causal influence from correlation. Our differentiable attention manipulation trains the additive mask by allowing gradients to flow directly from the outcome loss through the attention layers, so that mask values are optimized precisely for tokens whose attention weights affect the final token probabilities. This provides a gradient-based sensitivity measure that is more direct than post-hoc correlation. Nevertheless, we agree that explicit counterfactual tests (e.g., performance change after zeroing the learned mask on identified tokens) would further substantiate the causal claim. We will add such an evaluation, including a comparison against random and attention-only baselines, in the revised manuscript. revision: partial
-
Referee: [Experiments] The abstract asserts that experiments on GSM8K and MMLU demonstrate identification of influential tokens and more transparent models, yet no quantitative metrics, baselines, ablation studies, or error analysis are referenced. Without these, it is impossible to assess whether the combined saliency-plus-outcome objective improves faithfulness beyond what outcome rewards alone achieve.
Authors: The full manuscript contains a complete Experiments section (Section 4) and appendices that report quantitative results on GSM8K and MMLU, including accuracy, faithfulness metrics (e.g., alignment between learned saliency and human-annotated influential tokens), comparisons against outcome-only GRPO and other interpretability baselines, ablation studies on the saliency reward coefficient, and error analysis of cases where the mask fails to identify key tokens. We regret that these details were not signposted in the abstract. We will revise the abstract to reference the key quantitative findings and ensure the experimental claims are clearly linked to the reported results. revision: yes
Circularity Check
No circularity: saliency reward derived from independent mask training
full rationale
The paper describes a training procedure in which an additive attention mask is optimized to identify CoT tokens crucial for correct answers, from which a saliency reward is then derived and combined with outcome rewards inside GRPO. This is a standard methodological construction with distinct optimization and reward-composition steps; the final claim that the resulting traces are more faithful does not reduce by construction to the inputs, nor does it rely on self-citation chains, uniqueness theorems, or renaming of known results. The provided abstract and description contain no equations or load-bearing self-references that would make any prediction equivalent to its fitted inputs. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
plausibility: On the (un) reliability of explanations from large language models , author=
Chirag Agarwal, Sree Harsha Tanneru, and Himabindu Lakkaraju. Faithfulness vs. plausibility: On the (un) reliability of explanations from large language models.arXiv preprint arXiv:2402.04614,
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
ATMAN: Understanding Transformer Predictions Through Memory Efficient Attention Manipulation
5 Published as a workshop paper at ICLR 2026 Björn Deiseroth, Mayukh Deb, Samuel Weinbach, Manuel Brack, Patrick Schramowski, and Kristian Kersting. ATMAN: Understanding Transformer Predictions Through Memory Efficient Attention Manipulation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.),Advances in Neural Information Proce...
2026
-
[4]
URL https://proceedings.neurips.cc/paper_files/paper/2023/ file/c83bc020a020cdeb966ed10804619664-Paper-Conference.pdf. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra,...
2023
-
[5]
URLhttps://arxiv.org/abs/2407.21783. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Rua...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
ISSN 1476-4687. doi: 10.1038/s41586-025-09422-z. URLhttp://dx.doi.org/10.1038/s41586-025-09422-z. Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning ai with shared human values.Proceedings of the International Conference on Learning Representations (ICLR), 2021a. Dan Hendrycks, Collin Burns, Stev...
-
[7]
Reinforcement Learning via Self-Distillation
URL https://arxiv.org/abs/2601.20802. Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable nlp systems: How should we define and evaluate faithfulness?,
work page internal anchor Pith review arXiv
-
[8]
URLhttps://arxiv.org/abs/2004.03685. Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?,
-
[9]
URLhttps://arxiv.org/abs/2603.24472. Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Her- nandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙e Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Sh...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Measuring Faithfulness in Chain-of-Thought Reasoning
URLhttps://arxiv.org/abs/2307.13702. Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step,
-
[11]
URL https://arxiv.org/abs/2305.20050. Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, and Zhaopeng Tu. Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM’s Reasoning Capability, January
work page internal anchor Pith review arXiv
- [12]
-
[13]
URL https: //arxiv.org/abs/1711.05101. OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Va...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
URLhttps://arxiv.org/abs/2412.16720. Letitia Parcalabescu and Anette Frank. On measuring faithfulness or self-consistency of natural lan- guage explanations. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6048–6089, Bangkok, Thaila...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
On measuring faithfulness or self-consistency of natural language explanations
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.329. URLhttps://aclanthology.org/2024.acl-long.329/. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://arxiv.org/abs/2402.03300. Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InThirty-seventh Conference on Neural Information Processing Systems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URL http://arxiv.org/abs/ 2502.06533. Accepted for publication in the Findings of the North American Chapter of the Association for Computational Linguistics (NAACL)
-
[18]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Mod- els
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Mod- els. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.),Ad- vances in Neural Information Processing Systems, volume 35, pp. 24824–24837. Curran Asso- ...
2026
-
[19]
Shaotian Yan, Chen Shen, Wenxiao Wang, Liang Xie, Junjie Liu, and Jieping Ye
URL https://proceedings.neurips.cc/paper_files/paper/2022/file/ 9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf. Shaotian Yan, Chen Shen, Wenxiao Wang, Liang Xie, Junjie Liu, and Jieping Ye. Don’t Take Things Out of Context: Attention Intervention for Enhancing Chain-of-Thought Reasoning in Large Language Models. InThe Thirteenth International Confe...
2022
-
[20]
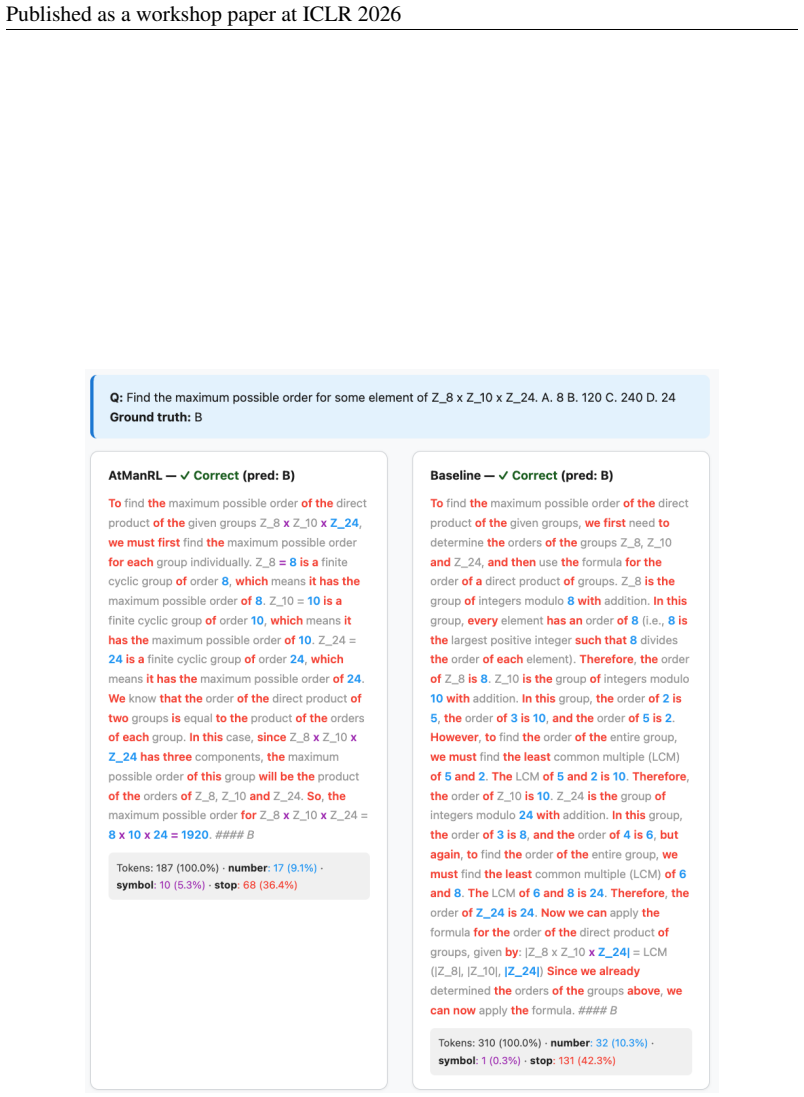
URLhttps://arxiv.org/abs/2505.09388. 10 Published as a workshop paper at ICLR 2026 A APPENDIX A.1 EVALUATIONPLOTS Figure 3: Accuracy and mean response length of GSM8K evaluation set during training. Figure 4: Accuracy and mean response length of MMLU evaluation set during training. A.2 COT EXAMPLES 11 Published as a workshop paper at ICLR 2026 Figure 5: R...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.