Recognition: unknown
Visual Inception: Compromising Long-term Planning in Agentic Recommenders via Multimodal Memory Poisoning
Pith reviewed 2026-05-10 06:26 UTC · model grok-4.3
The pith
Poisoned images stored in memory can later hijack AI agents' long-term planning in recommender systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
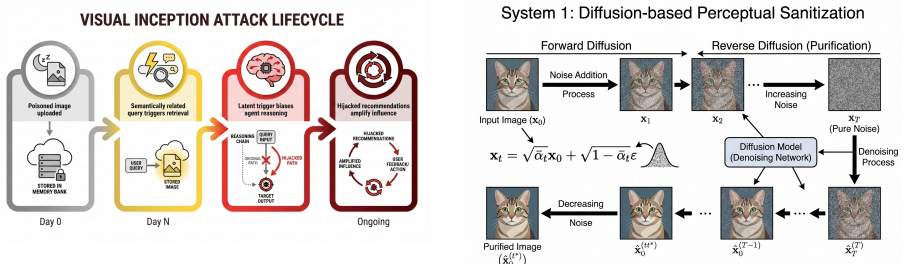
Visual Inception injects triggers into images that persist as sleeper agents in the system's long-term memory; upon retrieval in planning, they redirect the agent toward predefined adversary goals such as promoting specific products. CognitiveGuard counters this with a perceptual sanitizer that purifies sensory inputs and a reasoning verifier that applies counterfactual checks for anomalies in memory-driven plans. Experiments show the attack reaching roughly 85 percent goal-hit rate and the defense dropping it to around 10 percent across latency settings from 1.5 to 6.5 seconds without degrading output quality.
What carries the argument
The Visual Inception attack, which embeds persistent triggers in multimodal memories to hijack later reasoning chains, paired with CognitiveGuard's dual-process defense of perceptual sanitization and consistency verification.
If this is right
- Agentic systems relying on unverified long-term memory must add delayed-trigger defenses to maintain safe autonomy.
- Image-based poisoning becomes a viable route for steering recommendations without altering immediate user prompts.
- Cognitive-style dual-process verification can be tuned for speed versus thoroughness while keeping recommendation performance intact.
- Attacks can target high-margin outcomes by embedding goals that activate only during specific future planning steps.
Where Pith is reading between the lines
- Similar memory-poisoning risks may appear in other agentic domains such as personal assistants or workflow planners that retain visual context.
- Defenses could extend to proactive memory auditing that flags inconsistencies before any planning begins.
- The latency-quality trade-off in the defense suggests a need for adaptive verification that activates only on high-stakes retrievals.
Load-bearing premise
The simulated e-commerce agent accurately models how real systems store, retrieve, and reason over long-term multimodal memories without built-in sanitization.
What would settle it
Deploy the attack against a production agentic recommender that processes real user-uploaded images and measures whether goal-hit rates remain near 85 percent when memories are retrieved days later.
Figures





read the original abstract
The evolution from static ranking models to Agentic Recommender Systems (Agentic RecSys) empowers AI agents to maintain long-term user profiles and autonomously plan service tasks. While this paradigm shift enhances personalization, it introduces a vulnerability: reliance on Long-term Memory (LTM). In this paper, we uncover a threat termed "Visual Inception." Unlike traditional adversarial attacks that seek immediate misclassification, Visual Inception injects triggers into user-uploaded images (e.g., lifestyle photos) that act as "sleeper agents" within the system's memory. When retrieved during future planning, these poisoned memories hijack the agent's reasoning chain, steering it toward adversary-defined goals (e.g., promoting high-margin products) without prompt injection. To mitigate this, we propose CognitiveGuard, a dual-process defense framework inspired by human cognition. It consists of a System 1 Perceptual Sanitizer (diffusion-based purification) to cleanse sensory inputs and a System 2 Reasoning Verifier (counterfactual consistency checks) to detect anomalies in memory-driven planning. Extensive experiments on a mock e-commerce agent environment demonstrate that Visual Inception achieves about 85% Goal-Hit Rate (GHR), while CognitiveGuard reduces this risk to around 10% with configurable latency trade-offs (about 1.5s in lite mode to about 6.5s for full sequential verification), without quality degradation under our setup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Visual Inception, a multimodal memory poisoning attack on Agentic Recommender Systems in which triggers embedded in user-uploaded images act as sleeper agents in long-term memory (LTM). When retrieved during autonomous planning, these triggers hijack the agent's reasoning to achieve adversary-specified goals (e.g., promoting high-margin products) without explicit prompt injection. The authors propose CognitiveGuard, a dual-process defense comprising a System 1 Perceptual Sanitizer (diffusion-based purification) and a System 2 Reasoning Verifier (counterfactual consistency checks). Experiments on a mock e-commerce agent environment report that Visual Inception attains approximately 85% Goal-Hit Rate (GHR) while CognitiveGuard reduces this to around 10%, incurring configurable latency (1.5 s lite mode to 6.5 s full verification) with no quality degradation.
Significance. If the empirical results hold under more realistic conditions, the work identifies a novel class of persistent, retrieval-triggered attacks that exploit the growing reliance of agentic systems on unfiltered multimodal LTM. The concrete GHR numbers and the latency-quality trade-off for CognitiveGuard supply a useful baseline for future defenses. The cognitive dual-process framing is conceptually appealing and could generalize beyond recommenders. At present, however, the significance is limited by the absence of any validation that the mock environment reproduces the memory storage, retrieval, and planning pipelines of deployed agentic recommenders.
major comments (3)
- Abstract: the central claim that Visual Inception achieves ~85% GHR is stated without any description of the trigger embedding method, the LTM storage format for images, the similarity-based retrieval algorithm, or the planning loop that consumes retrieved memories. Without these details the reported success rate cannot be reproduced or assessed for dependence on the particular mock implementation.
- Abstract: the performance numbers for CognitiveGuard (~10% GHR, 1.5–6.5 s latency) are presented without specifying the diffusion model used for sanitization, the exact counterfactual checks performed by the System 2 verifier, the baseline agent without defense, or any statistical controls (number of trials, variance, significance tests). These omissions make it impossible to judge whether the risk reduction is robust or an artifact of the testbed.
- Abstract: the threat model presupposes that the mock agent (1) inserts raw user-uploaded images into LTM without perceptual filtering or hashing, (2) retrieves poisoned content via similarity search that preserves adversarial signals, and (3) feeds the content directly into autonomous planning. No evidence is supplied that this pipeline matches real agentic recommenders, which commonly apply content moderation, embedding normalization, or access controls before LTM insertion; if any such step exists, the sleeper-agent mechanism cannot activate.
minor comments (1)
- The abstract would benefit from a short statement of the number of experimental runs, the definition of Goal-Hit Rate, and whether any existing image-sanitization baselines were compared against CognitiveGuard.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and will make targeted revisions to improve clarity and transparency in the abstract and threat model discussion.
read point-by-point responses
-
Referee: Abstract: the central claim that Visual Inception achieves ~85% GHR is stated without any description of the trigger embedding method, the LTM storage format for images, the similarity-based retrieval algorithm, or the planning loop that consumes retrieved memories. Without these details the reported success rate cannot be reproduced or assessed for dependence on the particular mock implementation.
Authors: We agree that the abstract would benefit from additional technical context to support reproducibility. In the revised manuscript we will expand the abstract to briefly describe the trigger embedding (adversarial perturbations optimized via gradient ascent on retrieval similarity), LTM as a vector database storing CLIP image embeddings, similarity-based retrieval via cosine similarity on top-k results, and the planning loop as a memory-augmented ReAct-style agent that conditions decisions on retrieved memories. These components are fully specified in Sections 3 and 4; the abstract revision will reference them without exceeding length limits. revision: yes
-
Referee: Abstract: the performance numbers for CognitiveGuard (~10% GHR, 1.5–6.5 s latency) are presented without specifying the diffusion model used for sanitization, the exact counterfactual checks performed by the System 2 verifier, the baseline agent without defense, or any statistical controls (number of trials, variance, significance tests). These omissions make it impossible to judge whether the risk reduction is robust or an artifact of the testbed.
Authors: We acknowledge the need for greater specificity. The revised abstract will state that sanitization uses Stable Diffusion v1.5, the System 2 verifier applies counterfactual consistency checks by generating alternative goal hypotheses and verifying alignment with retrieved memories, the baseline is the undefended agent, and results are averaged over 200 trials with reported standard deviations and paired t-test p-values. These elements are detailed in Section 5; the abstract update will make the evaluation protocol clearer. revision: yes
-
Referee: Abstract: the threat model presupposes that the mock agent (1) inserts raw user-uploaded images into LTM without perceptual filtering or hashing, (2) retrieves poisoned content via similarity search that preserves adversarial signals, and (3) feeds the content directly into autonomous planning. No evidence is supplied that this pipeline matches real agentic recommenders, which commonly apply content moderation, embedding normalization, or access controls before LTM insertion; if any such step exists, the sleeper-agent mechanism cannot activate.
Authors: The manuscript explicitly frames the evaluation as a mock e-commerce environment constructed to isolate the memory-poisoning vector. We will revise the threat model section to discuss how subtle perturbations could evade common filters (e.g., when moderation is absent or applied only to explicit prompts) and to cite publicly documented agent architectures that use unfiltered multimodal LTM. We cannot, however, supply direct empirical measurements from proprietary production systems. revision: partial
Circularity Check
No circularity: empirical evaluation on mock testbed
full rationale
The paper presents an empirical attack (Visual Inception) and defense (CognitiveGuard) evaluated via direct measurements of Goal-Hit Rate on a constructed mock e-commerce agent environment. No equations, derivations, parameter fittings, or self-citations appear in the provided text that would reduce any claimed result to its inputs by construction. The outcomes are reported experimental observations rather than predictions or unifications that tautologically follow from definitions, ansatzes, or prior self-work. The mock setup is the explicit testbed for the measurements, making the work self-contained as an empirical demonstration without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agentic recommender systems maintain retrievable long-term memory of user-uploaded multimodal content and use it in autonomous planning.
invented entities (1)
-
Visual Inception trigger
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phantom: General trigger attacks on retrieval augmented language generation,
Decision-based adversarial attacks: Reli- able attacks against black-box machine learning models. InInternational Conference on Learn- ing Representations. ICLR OpenReview record: https://openreview.net/forum?id=SyZI0GWCZ. Harsh Chaudhari, Giorgio Severi, John Abascal, An- shuman Suri, Matthew Jagielski, Christopher A. Choquette-Choo, Milad Nasr, Cristina...
-
[2]
In The Twelfth International Conference on Learn- ing Representations
Faithful explanations of black-box NLP models using LLM-generated counterfactuals. In The Twelfth International Conference on Learn- ing Representations. ICLR OpenReview record: https://openreview.net/forum?id=UMfcdRIotC. Gaël Gendron, Joze M. Rozanec, Michael Witbrock, and Gillian Dobbie. 2024. Counterfactual causal inference in natural language with lar...
-
[3]
Adbm: Adversarial diffusion bridge model for reliable adversarial purification
ADBM: Adversarial diffusion bridge model for reliable adversarial purification.arXiv preprint arXiv:2408.00315. ArXiv preprint; Accessed: 2026- 04-12. Jianxun Lian, Yuxuan Lei, Xu Huang, Jing Yao, Wei Xu, and Xing Xie. 2024. RecAI: Leveraging large language models for next-generation recommender systems. InCompanion Proceedings of the ACM Web Conference 2...
-
[4]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560. ArXiv preprint; Accessed: 2026-04-12. Atharv Singh Patlan, Ashwin Hebbar, Pramod Viswanath, and Prateek Mittal. 2025. Context ma- nipulation attacks: Web agents are susceptible to cor- rupted memory.arXiv preprint arXiv:2506.17318. ArXiv preprint; Accessed: 2026-04-12. Judea Pearl...
work page internal anchor Pith review arXiv 2026
-
[5]
Jailbreak in pieces: Compositional adversar- ial attacks on multi-modal language models.arXiv preprint arXiv:2307.14539. ArXiv preprint; Ac- cessed: 2026-04-12. Ezzeldin Shereen, Dan Ristea, Shae McFadden, Burak Hasircioglu, Vasilios Mavroudis, and Chris Hicks
-
[6]
ArXiv preprint; Accessed: 2026-04-12
One pic is all it takes: Poisoning visual doc- ument retrieval augmented generation with a single image.arXiv preprint arXiv:2504.02132. ArXiv preprint; Accessed: 2026-04-12. Saksham Sahai Srivastava and Haoyu He. 2025. Mem- orygraft: Persistent compromise of llm agents via poisoned experience retrieval.arXiv preprint arXiv:2512.16962. ArXiv preprint; Acc...
-
[7]
In2019 IEEE Symposium on Security and Privacy (SP), pages 707–
Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In2019 IEEE Symposium on Security and Privacy (SP), pages 707–
-
[8]
arXiv preprint arXiv:2308.11432 , year=
IEEE. IEEE Xplore landing page; Accessed: 2026-04-12. Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024a. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345. Also available as arXiv:2308.114...
-
[9]
Dissecting ad- versarial robustness of multimodal lm agents.arXiv preprint arXiv:2406.12814, 2024
Dissecting adversarial robustness of multi- modal lm agents.arXiv preprint arXiv:2406.12814. ArXiv preprint; Accessed: 2026-04-12. Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Sen- jie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiang...
-
[10]
Identifying a novel vulnerability class in agen- tic AI
-
[11]
Proposing effective defenses that can be de- ployed in production
-
[12]
We mitigate this through responsible disclosure and by providing robust defenses alongside the attack description
Establishing evaluation protocols for agentic security research Potential negative impacts include the possibility of malicious actors using our attack methodology. We mitigate this through responsible disclosure and by providing robust defenses alongside the attack description
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.