Recognition: unknown
Privatar: Scalable Privacy-preserving Multi-user VR via Secure Offloading
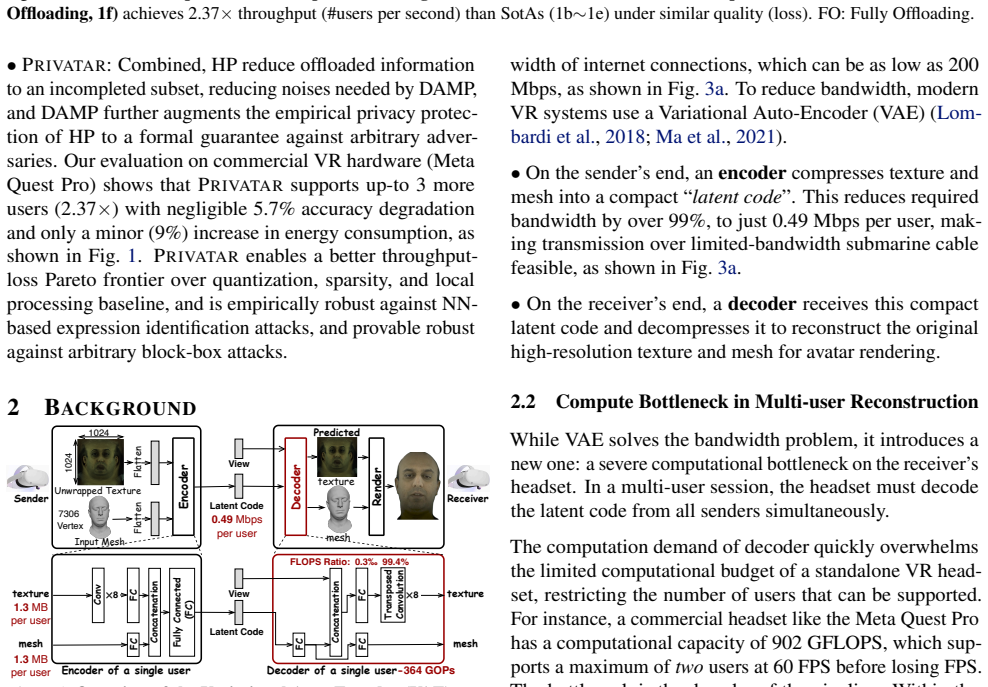
Pith reviewed 2026-05-10 06:15 UTC · model grok-4.3
The pith
Privatar scales multi-user VR by offloading avatar reconstruction to untrusted local devices through frequency partitioning and minimal distribution-aware noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
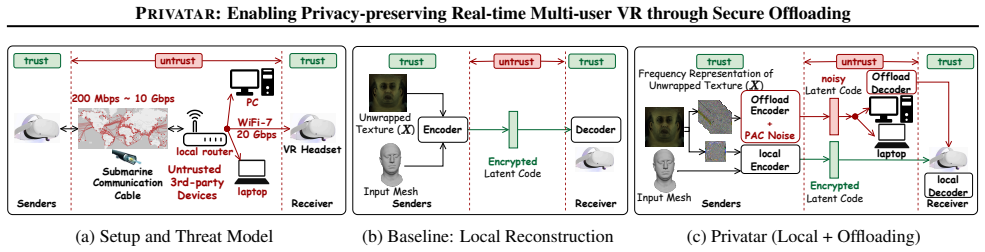
Avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop. Horizontal Partitioning keeps high-energy components on-device and offloads only low-energy subsets, limiting leakage. Distribution-Aware Minimal Perturbation tracks each user's slowly changing expression distribution online and applies the smallest noise that still satisfies formal differential privacy. Together these steps allow safe offloading to untrusted local devices, yielding 2.37x more concurrent users on a Meta Quest Pro at 6.5% higher reconstruction loss and 9% energy overhead while remaining robust to empirical and neural-network attacks.
What carries the argument
Horizontal Partitioning (HP) via BDCT frequency decomposition combined with Distribution-Aware Minimal Perturbation (DAMP) that tailors noise to each user's tracked expression distribution.
If this is right
- Supports 2.37x more concurrent users than local construction baselines.
- Achieves a better throughput-loss Pareto frontier than quantization or sparsity methods.
- Delivers formal differential privacy guarantees against arbitrary adversaries.
- Resists both empirical expression-identification attacks and neural-network attacks.
- Adds only 6.5% higher reconstruction loss and 9% energy overhead.
Where Pith is reading between the lines
- The same frequency-partitioning idea could apply to other headset sensor streams such as eye tracking or body motion.
- Rapidly changing expressions would require an online adaptation layer for the perturbation step to preserve the claimed utility.
- Local-device offloading could lower dependence on distant cloud servers for large VR sessions.
- Comparable split-and-perturb methods might transfer to privacy-sensitive offloading in augmented reality or mobile multi-player games.
Load-bearing premise
Users' expression statistical distributions change slowly enough over time to be tracked accurately online.
What would settle it
Run a trial in which participants make sudden, rapid expression changes that invalidate the online-tracked distributions; measure whether reconstruction loss spikes or privacy is violated.
Figures












read the original abstract
Multi-user virtual reality enables immersive interaction. However, rendering avatars for numerous participants on each headset incurs prohibitive computational overhead, limiting scalability. We introduce a framework, Privatar, to offload avatar reconstruction from headset to untrusted devices within the same local network while safeguarding attacks against adversaries capable of intercepting offloaded data. Privatar's key insight is that domain-specific knowledge of avatar reconstruction enables provably private offloading at minimal cost. (1) System level. We observe avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop, and propose Horizontal Partitioning (HP) to keep high-energy frequency components on-device and offloads only low-energy components. HP offloads local computation while reducing information leakage to low-energy subsets only. (2) Privacy level. For individually offloaded, multi-dimensional signals without aggregation, worst-case local Differential Privacy requires prohibitive noise, ruining utility. We observe users' expression statistical distribution are slowly changing over time and trackable online, and hence propose Distribution-Aware Minimal Perturbation. DAMP minimizes noise based on each user's expression distribution to significantly reduce its effects on utility, retaining formal privacy guarantee. Combined, HP provides empirical privacy against expression identification attacks. DAMP further augments it to offer a formal guarantee against arbitrary adversaries. On a Meta Quest Pro, Privatar supports 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, providing a better throughout-loss Pareto frontier over quantization, sparsity and local construction baselines. Privatar provides both provable privacy guarantee and stays robust against both empirical and NN-based attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Privatar, a framework for offloading avatar reconstruction in multi-user VR to untrusted local devices while preserving privacy. It introduces Horizontal Partitioning (HP) using BDCT to retain high-energy frequency components on-device and offload low-energy ones, combined with Distribution-Aware Minimal Perturbation (DAMP) that adds reduced noise based on online-tracked per-user expression distributions. The system claims formal privacy guarantees, robustness to empirical and NN-based attacks, and concrete gains on Meta Quest Pro: 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, outperforming quantization, sparsity, and local baselines on the throughput-loss Pareto frontier.
Significance. If the central claims hold, Privatar could meaningfully advance scalable multi-user VR by addressing computational bottlenecks through secure offloading while providing both empirical and formal privacy. The domain-specific insight of frequency decomposability and distribution-aware perturbation offers a practical alternative to generic local DP, potentially enabling denser VR sessions with acceptable utility loss. The reported performance numbers and attack robustness, if rigorously supported, would strengthen the case for deployment in resource-constrained headsets.
major comments (2)
- [DAMP mechanism (privacy level section)] The formal privacy guarantee of DAMP (abstract and privacy-level description) depends on the assumption that per-user expression distributions change slowly enough to be tracked online without introducing leakage or extra utility cost. The manuscript must provide the concrete protocol for private distribution estimation, its overhead analysis, and either a proof or empirical evidence that tracking does not violate the claimed formal guarantee or force noise levels that erase the reported 6.5% loss advantage; without this, the minimal-perturbation claim is not load-bearing.
- [Evaluation and results] Evaluation claims (abstract and results section) report 2.37x user scaling, 6.5% reconstruction loss, and 9% energy overhead with better Pareto frontier and robustness to NN-based attacks, but lack error bars, statistical significance tests, attack model specifications (e.g., adversary capabilities, training data), and ablation on distribution-shift scenarios. These details are required to substantiate that the gains are not artifacts of specific test conditions and that robustness holds when the slow-distribution assumption is stressed.
minor comments (2)
- [Abstract] The abstract contains a likely typo: 'throughout-loss Pareto frontier' should read 'throughput-loss Pareto frontier'.
- [System-level description] Notation for BDCT and HP should be defined at first use with a brief equation or reference to the decomposition property to aid readers unfamiliar with frequency-domain avatar techniques.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional detail and rigor will strengthen the manuscript. We address each major comment below and commit to revisions that directly incorporate the requested clarifications and analyses.
read point-by-point responses
-
Referee: [DAMP mechanism (privacy level section)] The formal privacy guarantee of DAMP (abstract and privacy-level description) depends on the assumption that per-user expression distributions change slowly enough to be tracked online without introducing leakage or extra utility cost. The manuscript must provide the concrete protocol for private distribution estimation, its overhead analysis, and either a proof or empirical evidence that tracking does not violate the claimed formal guarantee or force noise levels that erase the reported 6.5% loss advantage; without this, the minimal-perturbation claim is not load-bearing.
Authors: We agree that the current high-level description of online distribution tracking in the DAMP section requires expansion to fully support the formal claims. In the revised manuscript we will add a concrete protocol for private distribution estimation (using per-user local histogram maintenance with periodic, differentially private updates shared via secure aggregation within the local network). We will include a detailed overhead analysis showing that tracking adds less than 2% energy and negligible latency. We will also present empirical measurements from our Meta Quest Pro experiments demonstrating slow distribution drift (changes occur over tens of seconds to minutes), confirming that the calibrated noise remains low enough to retain the 6.5% reconstruction-loss advantage. Finally, we will provide a proof sketch showing that the estimation step itself satisfies local DP and does not leak information beyond what DAMP already accounts for, thereby preserving the overall formal guarantee. revision: yes
-
Referee: [Evaluation and results] Evaluation claims (abstract and results section) report 2.37x user scaling, 6.5% reconstruction loss, and 9% energy overhead with better Pareto frontier and robustness to NN-based attacks, but lack error bars, statistical significance tests, attack model specifications (e.g., adversary capabilities, training data), and ablation on distribution-shift scenarios. These details are required to substantiate that the gains are not artifacts of specific test conditions and that robustness holds when the slow-distribution assumption is stressed.
Authors: We concur that the evaluation would benefit from greater statistical rigor and explicit attack specifications. In the revised manuscript we will add error bars to all throughput, loss, and energy figures, derived from at least ten independent runs per configuration. We will report statistical significance (paired t-tests with p-values) for the key claims, including the 2.37x user scaling. The attack-model subsection will be expanded to detail adversary capabilities, assumed background knowledge, and training-data sources for the NN-based attacks. We will also insert a new ablation subsection that stresses the slow-distribution assumption by injecting controlled distribution shifts at varying rates and measuring resulting privacy-utility trade-offs, thereby demonstrating that the reported gains and robustness remain stable under realistic deviations from the base assumption. revision: yes
Circularity Check
No circularity detected in Privatar derivation chain
full rationale
The paper presents HP as a system-level partitioning based on the observation that avatar reconstruction is frequency-domain decomposable via BDCT, and DAMP as a perturbation scheme based on the observation that user expression distributions change slowly and are trackable online. These are framed as design insights leading to empirical evaluation on Meta Quest Pro hardware against baselines, not as equations or parameters that reduce to their own inputs by construction. No self-citations, uniqueness theorems, fitted inputs renamed as predictions, or self-definitional steps appear in the provided text. The formal privacy claim is conditional on the distribution-stability assumption, but this is an external precondition rather than a circular reduction. The work is self-contained via hardware experiments and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop
- domain assumption Users' expression statistical distributions are slowly changing over time and trackable online
Reference graph
Works this paper leans on
-
[1]
2016 , publisher=
Chen, Yu-Hsin and Krishna, Tushar and Emer, Joel S and Sze, Vivienne , journal=. 2016 , publisher=
2016
-
[2]
Chen, Yu-Hsin and Yang, Tien-Ju and Emer, Joel and Sze, Vivienne , journal=
-
[3]
2025 , eprint=
A Survey on Methodological Approaches to Collaborative Embodiment in Virtual Reality , author=. 2025 , eprint=
2025
-
[4]
Huang, Junkai and Subhajyoti Mallick, Saswat and Amat, Alejandro and Ruiz Olle, Marc and Mosella-Montoro, Albert and Kerbl, Bernhard and Vicente Carrasco, Francisco and De la Torre, Fernando , title =. ACM Trans. Graph. , month = jul, articleno =. 2025 , issue_date =. doi:10.1145/3731214 , abstract =
-
[5]
Audience Amplified: Virtual Audiences in Asynchronously Performed AR Theater , DOI=
Kim, You-Jin and Sra, Misha and Höllerer, Tobias , year=. Audience Amplified: Virtual Audiences in Asynchronously Performed AR Theater , DOI=. 2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR) , publisher=
2024
-
[6]
CrypTen: Secure Multi-Party Computation Meets Machine Learning , volume =
Knott, Brian and Venkataraman, Shobha and Hannun, Awni and Sengupta, Shubho and Ibrahim, Mark and van der Maaten, Laurens , booktitle =. CrypTen: Secure Multi-Party Computation Meets Machine Learning , volume =
-
[7]
31st USENIX Security Symposium (USENIX Security 22) , year =
Jean-Luc Watson and Sameer Wagh and Raluca Ada Popa , title =. 31st USENIX Security Symposium (USENIX Security 22) , year =
-
[8]
Cheddar: A Swift Fully Homomorphic Encryption Library Designed for GPU Architectures , DOI=
Choi, Wonseok and Kim, Jongmin and Ahn, Jung Ho , year=. Cheddar: A Swift Fully Homomorphic Encryption Library Designed for GPU Architectures , DOI=. Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 , publisher=
-
[9]
ACCURATE LOW-DEGREE POLYNOMIAL APPROXIMATION OF NON-POLYNOMIAL OPERATORS FOR FAST PRIVATE INFERENCE IN HOMOMORPHIC ENCRYPTION , volume =
Tong, Jianming and Dang, Jingtian and Golder, Anupam and Raychowdhury, Arijit and Hao, Cong and Krishna, Tushar , booktitle =. ACCURATE LOW-DEGREE POLYNOMIAL APPROXIMATION OF NON-POLYNOMIAL OPERATORS FOR FAST PRIVATE INFERENCE IN HOMOMORPHIC ENCRYPTION , volume =
-
[10]
Edward Suh and Tushar Krishna , title =
Jianming Tong and Tianhao Huang and Jingtian Dang and Leo de Castro and Anirudh Itagi and Anupam Golder and Asra Ali and Jevin Jiang and Jeremy Kun and Arvind and G. Edward Suh and Tushar Krishna , title =. 2026 , publisher =
2026
-
[11]
2007 , publisher=
Recommendation for block cipher modes of operation: Galois/Counter Mode (GCM) and GMAC , author=. 2007 , publisher=
2007
-
[12]
Shamir, Adi , title =. Commun. ACM , month = nov, pages =. 1979 , issue_date =. doi:10.1145/359168.359176 , abstract =
-
[13]
Dwork, Cynthia and McSherry, Frank and Nissim, Kobbi and Smith, Adam , title =. Proceedings of the Third Conference on Theory of Cryptography , pages =. 2006 , isbn =. doi:10.1007/11681878_14 , abstract =
-
[14]
2021 , eprint=
Pixel Codec Avatars , author=. 2021 , eprint=
2021
-
[15]
ASIACRYPT: 23rd international conference on the theory and applications of cryptology and information security , pages=
Homomorphic encryption for arithmetic of approximate numbers , author=. ASIACRYPT: 23rd international conference on the theory and applications of cryptology and information security , pages=. 2017 , organization=
2017
-
[16]
Kwon, Hyoukjun and Samajdar, Ananda and Krishna, Tushar , booktitle=
-
[17]
2021 , eprint=
Does Fully Homomorphic Encryption Need Compute Acceleration? , author=. 2021 , eprint=
2021
-
[18]
Lattice Signatures without Trapdoors
Lyubashevsky, Vadim. Lattice Signatures without Trapdoors. Advances in Cryptology -- EUROCRYPT 2012. 2012
2012
-
[19]
NVIDIA H100 Tensor Core GPU Architecture Overview , author=
-
[20]
2017 , publisher=
Chen, Yu-Hsin and Emer, Joel and Sze, Vivienne , journal=. 2017 , publisher=
2017
-
[21]
Kwon, Hyoukjun and Chatarasi, Prasanth and Pellauer, Michael and Parashar, Angshuman and Sarkar, Vivek and Krishna, Tushar , booktitle=
-
[22]
Parashar, Angshuman and Raina, Priyanka and Shao, Yakun Sophia and Chen, Yu-Hsin and Ying, Victor A and Mukkara, Anurag and Venkatesan, Rangharajan and Khailany, Brucek and Keckler, Stephen W and Emer, Joel , booktitle=
-
[23]
Zhao, Zhongyuan and Kwon, Hyoukjun and Kuhar, Sachit and Sheng, Weiguang and Mao, Zhigang and Krishna, Tushar , booktitle=
-
[24]
Cong, Jason and Xiao, Bingjun , booktitle=
-
[25]
Yu, Fisher and Koltun, Vladlen , journal=
-
[26]
Samajdar, Ananda and Zhu, Yuhao and Whatmough, Paul and Mattina, Matthew and Krishna, Tushar , journal=
-
[27]
Proceedings of the Neural Information Processing Systems (NIPS) , year=
Imagenet classification with deep convolutional neural networks , author=. Proceedings of the Neural Information Processing Systems (NIPS) , year=
-
[28]
Yang, Tien-Ju and Chen, Yu-Hsin and Sze, Vivienne , booktitle=
-
[29]
Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian , booktitle=
-
[30]
Proceedings of the International Conference on Computer Vision , year=
Searching for mobilenetv3 , author=. Proceedings of the International Conference on Computer Vision , year=
-
[31]
Hong, Shenda and Xu, Yanbo and Khare, Alind and Priambada, Satria and Maher, Kevin and Aljiffry, Alaa and Sun, Jimeng and Tumanov, Alexey , booktitle=
-
[32]
Deep Residual Learning for Image Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. CoRR , volume =. 2015 , url =. 1512.03385 , timestamp =
work page internal anchor Pith review arXiv 2015
-
[33]
Once-for-all: Train one network and specialize it for efficient deployment,
Han Cai and Chuang Gan and Song Han , title =. CoRR , volume =. 2019 , url =. 1908.09791 , timestamp =
-
[34]
Hasan Genc and Ameer Haj. Gemmini: An Agile Systolic Array Generator Enabling Systematic Evaluations of Deep-Learning Architectures , journal =. 2019 , url =. 1911.09925 , timestamp =
-
[35]
and Tumeo, Antonino , booktitle=
Tan, Cheng and Xie, Chenhao and Li, Ang and Barker, Kevin J. and Tumeo, Antonino , booktitle=. OpenCGRA: An Open-Source Unified Framework for Modeling, Testing, and Evaluating CGRAs , year=
-
[36]
Cota and Michele Petracca and Christian Pilato and Luca P
Paolo Mantovani and Davide Giri and Giuseppe Di Guglielmo and Luca Piccolboni and Joseph Zuckerman and Emilio G. Cota and Michele Petracca and Christian Pilato and Luca P. Carloni , title =. CoRR , volume =. 2020 , url =. 2009.01178 , timestamp =
-
[37]
Rethinking the Inception Architecture for Computer Vision
Christian Szegedy and Vincent Vanhoucke and Sergey Ioffe and Jonathon Shlens and Zbigniew Wojna , title =. CoRR , volume =. 2015 , url =. 1512.00567 , timestamp =
work page Pith review arXiv 2015
-
[38]
SIGMA: A Sparse and Irregular GEMM Accelerator with Flexible Interconnects for DNN Training , year=
Qin, Eric and Samajdar, Ananda and Kwon, Hyoukjun and Nadella, Vineet and Srinivasan, Sudarshan and Das, Dipankar and Kaul, Bharat and Krishna, Tushar , booktitle=. SIGMA: A Sparse and Irregular GEMM Accelerator with Flexible Interconnects for DNN Training , year=
-
[39]
Proceedings of the 44th annual international symposium on computer architecture , pages=
In-datacenter performance analysis of a tensor processing unit , author=. Proceedings of the 44th annual international symposium on computer architecture , pages=
-
[40]
2021 International Conference on Field-Programmable Technology (ICFPT) , pages=
ac 2 SLAM: FPGA Accelerated High-Accuracy SLAM with Heapsort and Parallel Keypoint Extractor , author=. 2021 International Conference on Field-Programmable Technology (ICFPT) , pages=. 2021 , organization=
2021
-
[41]
Manas Sahni and Shreya Varshini and Alind Khare and Alexey Tumanov , booktitle=. Comp. 2021 , url=
2021
-
[42]
2017 , eprint=
Communication-Efficient Learning of Deep Networks from Decentralized Data , author=. 2017 , eprint=
2017
-
[43]
Williams, Samuel and Waterman, Andrew and Patterson, David , title =. Commun. ACM , month =. 2009 , issue_date =
2009
-
[44]
: A Document Preparation System
Leslie Lamport. : A Document Preparation System. 1994
1994
-
[45]
A Very Nice Paper To Cite
Firstname1 Lastname1 and Firstname2 Lastname2. A Very Nice Paper To Cite. Proceedings of the 26th IEEE International Symposium on High Performance Computer Architecture. 2016
2016
-
[46]
Another Very Nice Paper to Cite
Firstname1 Lastname1 and Firstname2 Lastname2 and Firstname3 Lastname3. Another Very Nice Paper to Cite. Proceedings of the 48th Annual IEEE/ACM International Symposium on Microarchitecture. 2015
2015
-
[47]
Yet Another Very Nice Paper To Cite, With Many Author Names All Spelled Out
Firstname1 Lastname1 and Firstname2 Lastname2 and Firstname3 Lastname3 and Firstname4 Lastname4 and Firstname5 Lastname5 and Firstname6 Lastname6 and Firstname7 Lastname7 and Firstname8 Lastname8 and Firstname9 Lastname9 and Firstname10 Lastname10 and Firstname11 Lastname11 and Firstname12 Lastname12. Yet Another Very Nice Paper To Cite, With Many Author ...
2011
-
[48]
Advances in Neural Information Processing Systems , volume=
Federated hyperparameter tuning: Challenges, baselines, and connections to weight-sharing , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[50]
IEEE Transactions on Neural Networks and Learning Systems , year=
PWSNAS: Powering Weight Sharing NAS With General Search Space Shrinking Framework , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Apq: Joint search for network architecture, pruning and quantization policy , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
Reiter, Michael K. and Rubin, Aviel D. , title =. ACM Trans. Inf. Syst. Secur. , month =. 1998 , issue_date =. doi:10.1145/290163.290168 , abstract =
-
[53]
Hegde, Kartik and Asghari-Moghaddam, Hadi and Pellauer, Michael and Crago, Neal and Jaleel, Aamer and Solomonik, Edgar and Emer, Joel and Fletcher, Christopher W. , title =. Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture , pages =. 2019 , isbn =. doi:10.1145/3352460.3358275 , abstract =
-
[54]
Parashar, Angshuman and Rhu, Minsoo and Mukkara, Anurag and Puglielli, Antonio and Venkatesan, Rangharajan and Khailany, Brucek and Emer, Joel and Keckler, Stephen W. and Dally, William J. , title =. Proceedings of the 44th Annual International Symposium on Computer Architecture , pages =. 2017 , isbn =. doi:10.1145/3079856.3080254 , abstract =
-
[55]
2022 , eprint=
FLAT: An Optimized Dataflow for Mitigating Attention Bottlenecks , author=. 2022 , eprint=
2022
-
[56]
DiGamma: Domain-aware Genetic Algorithm for HW-Mapping Co-optimization for DNN Accelerators , year=
Kao, Sheng-Chun and Pellauer, Michael and Parashar, Angshuman and Krishna, Tushar , booktitle=. DiGamma: Domain-aware Genetic Algorithm for HW-Mapping Co-optimization for DNN Accelerators , year=
-
[57]
MAGMA: An Optimization Framework for Mapping Multiple DNNs on Multiple Accelerator Cores , year=
Kao, Sheng-Chun and Krishna, Tushar , booktitle=. MAGMA: An Optimization Framework for Mapping Multiple DNNs on Multiple Accelerator Cores , year=
-
[58]
Chatarasi, Prasanth and Kwon, Hyoukjun and Parashar, Angshuman and Pellauer, Michael and Krishna, Tushar and Sarkar, Vivek , title =. ACM Trans. Archit. Code Optim. , month =. 2021 , issue_date =. doi:10.1145/3485137 , abstract =
-
[59]
Communications of the ACM , year=
Domain-specific hardware accelerators , author=. Communications of the ACM , year=
-
[60]
and Sze, Vivienne , journal=
Chen, Yu-Hsin and Krishna, Tushar and Emer, Joel S. and Sze, Vivienne , journal=. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks , year=
-
[61]
MAESTRO: A Data-Centric Approach to Understand Reuse, Performance, and Hardware Cost of DNN Mappings , year=
Kwon, Hyoukjun and Chatarasi, Prasanth and Sarkar, Vivek and Krishna, Tushar and Pellauer, Michael and Parashar, Angshuman , journal=. MAESTRO: A Data-Centric Approach to Understand Reuse, Performance, and Hardware Cost of DNN Mappings , year=
-
[62]
AI and ML Accelerator Survey and Trends , publisher =
Reuther, Albert and Michaleas, Peter and Jones, Michael and Gadepally, Vijay and Samsi, Siddharth and Kepner, Jeremy , keywords =. AI and ML Accelerator Survey and Trends , publisher =. 2022 , copyright =. doi:10.48550/ARXIV.2210.04055 , url =
-
[63]
Deep Residual Learning for Image Recognition
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , keywords =. Deep Residual Learning for Image Recognition , publisher =. 2015 , copyright =. doi:10.48550/ARXIV.1512.03385 , url =
work page internal anchor Pith review doi:10.48550/arxiv.1512.03385 2015
-
[64]
and Adam, Hartwig , title =
Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and Le, Quoc V. and Adam, Hartwig , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
-
[65]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[66]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[67]
M. J. Kearns , title =
-
[68]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[69]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[70]
Suppressed for Anonymity , author=
-
[71]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[72]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[73]
IEEE journal of solid-state circuits , volume=
Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks , author=. IEEE journal of solid-state circuits , volume=. 2016 , publisher=
2016
-
[74]
2019 56th ACM/IEEE Design Automation Conference (DAC) , pages=
Overcoming data transfer bottlenecks in FPGA-based DNN accelerators via layer conscious memory management , author=. 2019 56th ACM/IEEE Design Automation Conference (DAC) , pages=. 2019 , organization=
2019
-
[75]
2019 29th International Conference on Field Programmable Logic and Applications (FPL) , pages=
A data-center FPGA acceleration platform for convolutional neural networks , author=. 2019 29th International Conference on Field Programmable Logic and Applications (FPL) , pages=. 2019 , organization=
2019
-
[76]
2022 , eprint=
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain , author=. 2022 , eprint=
2022
-
[77]
IEEE Embedded Systems Letters , volume=
Improving memory utilization in convolutional neural network accelerators , author=. IEEE Embedded Systems Letters , volume=. 2020 , publisher=
2020
-
[78]
2018 IEEE International Symposium on Workload Characterization (IISWC) , pages=
Memory requirements for convolutional neural network hardware accelerators , author=. 2018 IEEE International Symposium on Workload Characterization (IISWC) , pages=. 2018 , organization=
2018
-
[79]
arXiv preprint arXiv:1907.10701 , year=
Benchmarking TPU, GPU, and CPU platforms for deep learning , author=. arXiv preprint arXiv:1907.10701 , year=
-
[80]
arXiv preprint arXiv:2204.08279 , year=
Communication Bounds for Convolutional Neural Networks , author=. arXiv preprint arXiv:2204.08279 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.