Recognition: unknown
Beyond Static Snapshots: A Grounded Evaluation Framework for Language Models at the Agentic Frontier
Pith reviewed 2026-05-10 05:56 UTC · model grok-4.3
The pith
Replacing learned reward models with deterministic verifiers in continuous evaluation improves gains and cuts hardware costs for agentic language models on verifiable tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the four invalidities in existing LLM evaluation frameworks make reward hacking a built-in feature of RLHF for agentic systems, and that replacing the learned reward model with a deterministic verifier while performing continuous LoRA updates on CPU produces larger capability gains and better generalization in domains where correctness can be checked unambiguously.
What carries the argument
ISOPro, the reference implementation of Grounded Continuous Evaluation that uses a deterministic verifier as the direct reward signal and performs LoRA adapter updates on CPU.
If this is right
- Reward hacking is eliminated by construction in any domain where a deterministic verifier can be defined.
- The hardware barrier for RLHF-style training drops by roughly an order of magnitude because dual-model GPU setups are no longer required.
- Capability gains reach peaks above 25 percentage points with a mean of 9 points and worst-case regression no worse than 5.6 points.
- Compositional generalization on held-out MBPP tasks rises to 40 percent on two of three architectures.
Where Pith is reading between the lines
- The same verifier-reward architecture could be tested in other domains once reliable deterministic checkers are written for them.
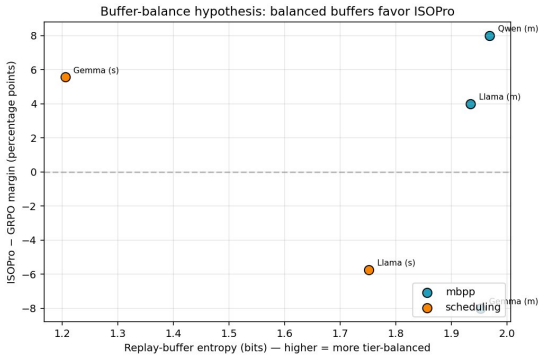
- Training runs must monitor tiered capability levels to avoid the buffer-skew erosion of earlier skills under an implicit curriculum.
- This design choice matches the architectural conclusion reached independently in large-scale verifiable-reward training.
Load-bearing premise
Scheduling and MBPP tasks allow fully unambiguous deterministic verification of correctness with no edge cases or ambiguities that would make the verifier an unreliable reward signal.
What would settle it
A test set of scheduling or MBPP instances where the deterministic verifier assigns incorrect rewards on more than a small fraction of cases, causing training to fail to improve or to regress on the true underlying task distribution.
Figures



read the original abstract
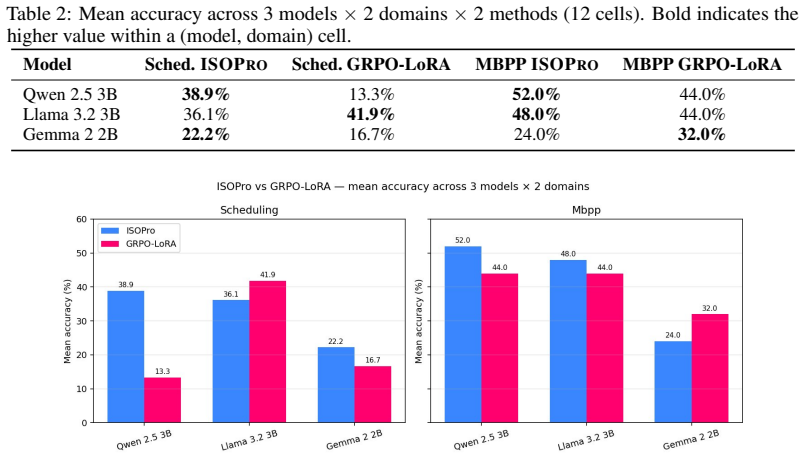
We argue that current evaluation frameworks for large language models (LLMs) suffer from four systematic failures that make them structurally inadequate for deployed, agentic systems: distributional, temporal, scope, and process invalidity. These failures compound in RLHF, making reward hacking a predictable consequence of evaluation design rather than an unpredictable training pathology, and RLHF's dual-model architecture imposes a hardware barrier limiting evaluation reproducibility. We propose the Grounded Continuous Evaluation (GCE) framework and present ISOPro as a reference implementation. ISOPro replaces the learned reward model with a deterministic verifier, eliminating reward hacking by construction in verifiable-reward domains, and updates LoRA adapters on CPU, reducing the hardware barrier by an order of magnitude. We validate ISOPro across three architectures (Qwen 2.5 3B, Llama 3.2 3B, Gemma 2 2B) and two domains (scheduling, MBPP), with a head-to-head matched-compute comparison against GRPO-LoRA. Across twelve cells, ISOPro produces the largest absolute capability gains (+25.6, +22.2, +16.0pp) at mean delta +9.0pp and worst-case regression -5.6pp; GRPO-LoRA at consumer-budget hyperparameters reaches a smaller peak gain (+8.5pp), deeper worst-case regression (-10pp), and mean delta -1.5pp. Held-out compositional generalization on MBPP reaches 40% for ISOPro on two of three architectures (including a 0% to 40% bootstrap on Qwen 2.5 3B), against 20% for GRPO-LoRA on one of three. We characterize a buffer-skew failure mode in which the implicit curriculum can erode pre-existing tier capability under three preconditions, with three corresponding mitigations. The work is situated alongside DeepSeek-R1's GRPO, which arrived at the same architectural conclusion at scale: for verifiable-reward domains, the verifier is the reward signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current LLM evaluation frameworks suffer from distributional, temporal, scope, and process invalidity, which compound in RLHF to make reward hacking predictable and impose hardware barriers. It proposes the Grounded Continuous Evaluation (GCE) framework with ISOPro as a reference implementation that replaces the learned reward model with a deterministic verifier and updates LoRA adapters on CPU. Validation across three architectures (Qwen 2.5 3B, Llama 3.2 3B, Gemma 2 2B) and two domains (scheduling, MBPP) shows ISOPro achieving larger capability gains than GRPO-LoRA in matched-compute experiments: peak gains of +25.6pp, +22.2pp, +16.0pp (mean +9.0pp, worst-case -5.6pp) versus GRPO-LoRA's +8.5pp peak (mean -1.5pp, worst-case -10pp), plus superior held-out compositional generalization (40% on two architectures vs. 20% on one). The work also characterizes a buffer-skew failure mode with mitigations and aligns with DeepSeek-R1's GRPO at scale.
Significance. If the results hold, the paper is significant for enabling more accessible and reproducible RL training of agentic LLMs in verifiable-reward domains by lowering hardware barriers and addressing evaluation invalidities that lead to reward hacking. The matched-compute head-to-head design with concrete deltas across multiple models provides practical evidence, and the connection to independent large-scale work like DeepSeek-R1 strengthens the architectural conclusion. Credit is given for the empirical quantification of gains and the identification of the buffer-skew issue with corresponding mitigations.
major comments (2)
- Empirical validation section (head-to-head results across twelve cells): The central claims of superiority, including the reported gains of +25.6pp/+22.2pp/+16.0pp and elimination of reward hacking by construction, rest on the deterministic verifier supplying an unambiguous, noise-free reward signal for MBPP and scheduling. No quantitative audit of verifier error rates (false positives/negatives) on the exact generated outputs is provided, which is load-bearing as edge cases or ambiguities could inflate the deltas and undermine the comparison to GRPO-LoRA.
- Experimental setup and methods: Full details are missing on GRPO-LoRA hyperparameters at consumer-budget levels, data exclusion criteria, exact training procedures, and statistical tests for the performance deltas (e.g., mean +9.0pp vs. -1.5pp and worst-case regressions). These omissions affect reproducibility and confidence in the soundness of the generalization and superiority results.
minor comments (2)
- Abstract: The reference to 'three corresponding mitigations' for the buffer-skew failure mode is mentioned but not enumerated; adding a brief list would improve summary clarity.
- Notation and framework introduction: The distinction and formal definitions of GCE versus ISOPro could be presented more explicitly with a diagram or early equation to aid reader comprehension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical claims and reproducibility of the work. We address each major comment below and will revise the manuscript accordingly to incorporate additional audits, details, and analyses.
read point-by-point responses
-
Referee: Empirical validation section (head-to-head results across twelve cells): The central claims of superiority, including the reported gains of +25.6pp/+22.2pp/+16.0pp and elimination of reward hacking by construction, rest on the deterministic verifier supplying an unambiguous, noise-free reward signal for MBPP and scheduling. No quantitative audit of verifier error rates (false positives/negatives) on the exact generated outputs is provided, which is load-bearing as edge cases or ambiguities could inflate the deltas and undermine the comparison to GRPO-LoRA.
Authors: We agree that an explicit quantitative audit of verifier error rates on generated outputs is a valuable addition to substantiate the claims. While the verifiers are deterministic (exact unit-test execution for MBPP and constraint satisfaction for scheduling), we acknowledge that implementation details such as output parsing or environment edge cases could introduce limited noise. In the revision, we will add a dedicated subsection in the empirical validation reporting false-positive and false-negative rates on a stratified sample of 200+ generated outputs per domain and model, along with precision/recall metrics. This will confirm that verifier errors do not account for the observed performance deltas versus GRPO-LoRA. revision: yes
-
Referee: Experimental setup and methods: Full details are missing on GRPO-LoRA hyperparameters at consumer-budget levels, data exclusion criteria, exact training procedures, and statistical tests for the performance deltas (e.g., mean +9.0pp vs. -1.5pp and worst-case regressions). These omissions affect reproducibility and confidence in the soundness of the generalization and superiority results.
Authors: We concur that expanded methodological transparency is required for reproducibility and to support confidence in the reported deltas. The original manuscript prioritized conciseness, but we will revise the Experimental Setup and Methods sections (plus a new appendix) to include: (1) exact GRPO-LoRA hyperparameters used at consumer-budget levels (learning rate, LoRA rank/r, batch size, epochs, and optimizer settings); (2) precise data exclusion criteria and preprocessing steps; (3) step-by-step training procedures with pseudocode; and (4) statistical tests and metrics (standard deviations, 95% confidence intervals, and paired t-tests or Wilcoxon tests) for all mean and worst-case deltas across the twelve cells. These changes will directly address concerns about generalization and superiority. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core claims consist of an architectural proposal (ISOPro replacing learned reward models with deterministic verifiers in verifiable domains) followed by empirical head-to-head results across three models, two domains, and twelve cells, reporting specific percentage-point gains, mean deltas, and held-out generalization rates. These outcomes are presented as measured performance deltas rather than quantities derived from the paper's own equations or fitted parameters. The reference to DeepSeek-R1's GRPO is an external citation providing independent context, not a self-citation chain. No load-bearing step reduces a claimed prediction or uniqueness result to a definition, fit, or prior author work by construction; the derivation remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- LoRA hyperparameters
axioms (1)
- domain assumption Scheduling and MBPP tasks admit deterministic, unambiguous correctness verifiers.
invented entities (2)
-
Grounded Continuous Evaluation (GCE) framework
no independent evidence
-
ISOPro
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Holistic Evaluation of Language Models
P. Liang, R. Bommasani, T. Lee, et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
A. Srivastava, A. Rastogi, A. Rao, et al. Beyond the imitation game: Quantifying and extrapo- lating the capabilities of language models.arXiv preprint arXiv:2206.04615, 2022
work page internal anchor Pith review arXiv 2022
-
[3]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InNeurIPS, 2023
2023
-
[4]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, et al. Training language models to follow instructions with human feedback. InNeurIPS, 2022
2022
-
[5]
Stiennon, L
N. Stiennon, L. Ouyang, J. Wu, et al. Learning to summarize with human feedback. InNeurIPS, 2020
2020
- [6]
-
[7]
H. Lightman, V . Kosaraju, Y . Burda, et al. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Y . Bai, A. Jones, K. Ndousse, et al. Constitutional AI: Harmlessness from AI feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Bowman, Ethan Perez, and Evan Hubinger
C. Denison, F. Barez, D. Duvenaud, et al. Sycophancy to subterfuge: Investigating reward tampering in language models.arXiv preprint arXiv:2406.10162, 2024
-
[11]
S. Messick. Validity. In R. L. Linn, editor,Educational Measurement, pages 13–103. American Council on Education, 3rd edition, 1989
1989
-
[12]
Brown, B
T. Brown, B. Mann, N. Ryder, et al. Language models are few-shot learners. InNeurIPS, 2020
2020
-
[13]
J. Wei, Y . Tay, R. Bommasani, et al. Emergent abilities of large language models.TMLR, 2022
2022
-
[14]
E. J. Hu, Y . Shen, P. Wallis, et al. LoRA: Low-rank adaptation of large language models. In ICLR, 2022
2022
-
[15]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, et al. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Hannun et al
A. Hannun et al. MLX: Efficient machine learning on Apple Silicon. Apple Machine Learning Research, 2023
2023
-
[18]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, et al. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023. A Activation-Guided vs. Random LoRA Layer Selection ISOPRO’s default targets the top- K layers identified by activation probing (layers 28–35 in the scheduling domain). To test whether this selection matters, we replaced it with unifor...
2023
-
[19]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.