Recognition: unknown
Navigating the Conceptual Multiverse
Pith reviewed 2026-05-10 04:43 UTC · model grok-4.3
The pith
The conceptual multiverse turns hidden decisions in language model answers into an inspectable, changeable space verified against domain reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
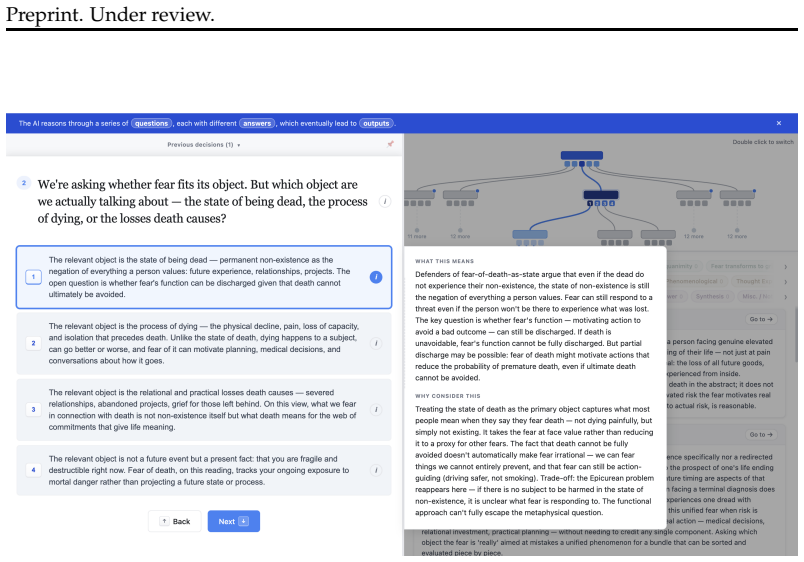
When language models answer open-ended problems they implicitly select among conceptual decisions that shape outputs but remain hidden from users; the conceptual multiverse represents those decisions as a transparent, intervenable space whose structure is checked for unambiguity, completeness, and fidelity to domain reasoning norms, so that users obtain a working map of the problem rather than an uncontextualized answer.
What carries the argument
The conceptual multiverse, an interactive representation of conceptual decisions (framing, values, priorities) as a navigable space that users can inspect, alter, and verify against principled domain reasoning via a general verification framework.
If this is right
- Philosophy students rewrite essays with sharper framings and reversed theses after navigating the multiverse.
- Alignment annotators move from surface-level preferences to explicit reasoning about user intent and potential harm.
- Poets identify compositional patterns that clarify their own taste and guide revisions.
- Users across domains obtain a working map of open-ended problems instead of isolated answers.
Where Pith is reading between the lines
- The same structure could apply to scientific hypothesis exploration or policy option comparison where hidden framing choices similarly shape conclusions.
- Embedding the multiverse into everyday language model interfaces might lower user over-reliance on single outputs by making alternatives visible by default.
- Extending the verification framework to new domains would require domain-specific expert calibration but could reuse the core properties of unambiguity and completeness.
Load-bearing premise
The verification framework calibrated on expert reasoning can reliably enforce unambiguity and completeness so the structure remains rigorous rather than misleading.
What would settle it
A controlled comparison in which participants using the conceptual multiverse produce no measurable improvement in problem mapping, essay revisions, or annotation depth compared with direct language model use would show the system fails to deliver the claimed benefit.
Figures





read the original abstract
When language models answer open-ended problems, they implicitly make hidden decisions that shape their outputs, leaving users with uncontextualized answers rather than a working map of the problem; drawing on multiverse analysis from statistics, we build and evaluate the conceptual multiverse, an interactive system that represents conceptual decisions such as how to frame a question or what to value as a space users can transparently inspect, intervenably change, and check against principled domain reasoning; for this structure to be worth navigating rather than misleading, it must be rigorous and checkable against domain reasoning norms, so we develop a general verification framework that enforces properties of good decision structures like unambiguity and completeness calibrated by expert-level reasoning; across three domains, the conceptual multiverse helped participants develop a working map of the problem, with philosophy students rewriting essays with sharper framings and reversed theses, alignment annotators moving from surface preferences to reasoning about user intent and harm, and poets identifying compositional patterns that clarified their taste.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the conceptual multiverse, an interactive system that externalizes implicit conceptual decisions (e.g., framing, values) made by language models on open-ended problems into an inspectable, intervenable structure. It pairs this with a verification framework enforcing properties such as unambiguity and completeness via expert-calibrated domain reasoning. The central claim is that navigation of this structure produces observable benefits: philosophy students produce sharper essay framings with reversed theses, alignment annotators shift from surface preferences to intent/harm reasoning, and poets identify compositional patterns clarifying their taste.
Significance. If the evaluation were rigorous, the work would offer a concrete HCI contribution for making LLM decision spaces transparent and checkable, with potential value in education, AI alignment, and creative domains. The cross-domain qualitative examples illustrate the idea's breadth, and the verification framework concept addresses a real risk of misleading structures. However, the absence of controlled evidence means the significance remains prospective rather than demonstrated.
major comments (2)
- [Evaluation / user studies] The evaluation (described in the abstract and user-study sections) reports positive shifts across three participant groups but provides no sample sizes, recruitment details, pre/post measures, control conditions, blinding procedures, or quantitative metrics. This directly undermines attribution of the observed changes (sharper framings, deeper reasoning, clarified taste) to the conceptual multiverse's specific affordances rather than generic reflection or guidance.
- [Verification framework] The verification framework is introduced as enforcing unambiguity and completeness 'calibrated by expert-level reasoning,' yet no formal definition, algorithm, or independent validation is supplied showing that the resulting structures are non-misleading. Without this, the claim that the navigable space is 'rigorous and checkable' rests on an untested assumption.
minor comments (2)
- [Introduction] The abstract and introduction use the term 'multiverse' without clarifying its precise relation to statistical multiverse analysis; a short comparison paragraph would help readers from outside HCI.
- [System description] Figure captions and system diagrams would benefit from explicit labels indicating which elements correspond to decision nodes versus verification checks.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We agree that the evaluation and verification framework require greater clarity and detail to substantiate the claims. We address each major comment below and will revise the manuscript to incorporate these points.
read point-by-point responses
-
Referee: [Evaluation / user studies] The evaluation (described in the abstract and user-study sections) reports positive shifts across three participant groups but provides no sample sizes, recruitment details, pre/post measures, control conditions, blinding procedures, or quantitative metrics. This directly undermines attribution of the observed changes (sharper framings, deeper reasoning, clarified taste) to the conceptual multiverse's specific affordances rather than generic reflection or guidance.
Authors: The evaluation in the manuscript consists of qualitative case studies demonstrating the system's use in three domains, rather than a controlled experimental study. These examples show how participants interacted with the conceptual multiverse to externalize decisions and arrive at the described outcomes, but we did not design the work as a comparative evaluation with controls, blinding, or quantitative metrics. To strengthen the presentation, we will add explicit details on participant numbers, recruitment (e.g., via university philosophy courses, alignment research networks, and poetry communities), and any documented pre/post observations. We will also revise the abstract and relevant sections to clearly frame the evidence as illustrative of the system's affordances in authentic contexts, without implying statistical attribution, and will note the exploratory nature as a limitation. revision: partial
-
Referee: [Verification framework] The verification framework is introduced as enforcing unambiguity and completeness 'calibrated by expert-level reasoning,' yet no formal definition, algorithm, or independent validation is supplied showing that the resulting structures are non-misleading. Without this, the claim that the navigable space is 'rigorous and checkable' rests on an untested assumption.
Authors: We will revise the verification framework section to include a formal definition of the enforced properties (unambiguity, completeness, and related criteria) along with the operationalization of expert-level calibration, such as through structured review steps aligned with domain norms. The framework is presented as a design mechanism to make structures checkable against principled reasoning, supported by the cross-domain examples. We acknowledge that no separate empirical validation study has been performed to confirm non-misleading outcomes beyond these cases. The revised manuscript will add this as an explicit limitation and outline directions for future validation work. revision: partial
Circularity Check
No circularity in the conceptual multiverse derivation
full rationale
The paper constructs an interactive system for representing conceptual decisions in LM outputs, drawing on external multiverse analysis from statistics and introducing a verification framework calibrated by expert reasoning to enforce properties such as unambiguity and completeness. Evaluation proceeds via qualitative participant examples across domains rather than any quantitative predictions, fitted parameters, or self-referential metrics. No equations, self-citations, or ansatzes are invoked in a load-bearing way that reduces outputs to inputs by construction; the claimed benefits are presented as observed changes in user reasoning, independent of the system's internal definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multiverse analysis concepts from statistics can be productively adapted to represent conceptual decisions in language models
- domain assumption Good decision structures are defined by properties such as unambiguity and completeness that can be calibrated against expert-level domain reasoning
invented entities (2)
-
conceptual multiverse
no independent evidence
-
verification framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
URL https://arxiv.org/abs/1606.06565. Anthropic. Introducing agent skills,
work page internal anchor Pith review arXiv
- [2]
-
[3]
Blog post
URL https://davidbau.com/archives/2026/01/ 17/the_art_of_wanting.html. Blog post. Joachim Baumann, Paul R¨ottger, Aleksandra Urman, Albert Wendsj¨o, Flor Miriam Plaza del Arco, Johannes B. Gruber, and Dirk Hovy. Large language model hacking: Quantifying the hidden risks of using llms for text annotation,
2026
-
[4]
URL https://arxiv.org/abs/ 2509.08825. Martin Bertran, Riccardo Fogliato, and Zhiwei Steven Wu. Many AI analysts, one dataset: Navigating the agentic data science multiverse.arXiv preprint arXiv:2602.18710,
-
[5]
Leonardo de Moura and Sebastian Ullrich
URLhttps://arxiv.org/abs/2510.16380. Leonardo de Moura and Sebastian Ullrich. The Lean 4 theorem prover and programming language. InAutomated Deduction – CADE 28, volume 12699 ofLecture Notes in Computer Science, pp. 625–635. Springer,
-
[6]
URL https://arxiv.org/abs/2512.03399. Linda Flower and John R. Hayes. A cognitive process theory of writing.College Composition and Communication, 32(4):365–387,
-
[7]
A., Rieser, V ., Iqbal, H., Tomašev, N., Ktena, I., Kenton, Z., Rodriguez, M., et al
URLhttps://arxiv.org/abs/2404.16244. Andrew Gelman and Eric Loken. The garden of forking paths: Why multiple comparisons can be a problem, even when there is no “fishing expedition” or “p-hacking” and the research hypothesis was posited ahead of time. Department of Statistics, Columbia Uni- versity,
-
[8]
Mitchell L
URL http://www.stat.columbia.edu/~gelman/research/unpublished/ p_hacking.pdf. Mitchell L. Gordon, Michelle S. Lam, Joon Sung Park, Kayur Patel, Jeffrey T. Hancock, Tatsunori Hashimoto, and Michael S. Bernstein. Jury learning: Integrating dissenting voices into machine learning models. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems,
2022
-
[9]
edu/jol/2026/01/24/generative-misinterpretation/
URL https://journals.law.harvard. edu/jol/2026/01/24/generative-misinterpretation/. Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness,
2026
-
[10]
Counterfactual simulation training for chain-of-thought faithfulness
URLhttps://arxiv.org/abs/2602.20710. Martin Heidegger.Being and Time. Harper & Row,
-
[11]
Karin Knorr-Cetina.Epistemic Cultures: How the Sciences Make Knowledge
URLhttps://arxiv.org/abs/2404.10636. Karin Knorr-Cetina.Epistemic Cultures: How the Sciences Make Knowledge. Harvard University Press,
-
[12]
URLhttps://arxiv.org/abs/2305.20050. Matthew Lipman.Thinking in Education. Cambridge University Press, 2nd edition,
work page internal anchor Pith review arXiv
-
[13]
Normative conflicts and shallow AI alignment.Philosophical Studies, 182: 2035–2078,
Rapha¨el Milli`ere. Normative conflicts and shallow AI alignment.Philosophical Studies, 182: 2035–2078,
2035
-
[14]
Normative conflicts and shallow AI alignment
doi: 10.1007/s11098-025-02347-3. URL https://doi.org/10.1007/ s11098-025-02347-3. N¯ag¯arjuna.M¯ ulamadhyamakak¯ arik¯ a. Oxford University Press, c. 150 CE. Translated by Jay L. Garfield asThe Fundamental Wisdom of the Middle Way,
-
[15]
URLhttps://arxiv.org/abs/2506.23678
doi: 10.1145/3742413.3789091. URLhttps://arxiv.org/abs/2506.23678. Plato.Phaedo. Cambridge University Press, c. 380 BCE. Edited by C. J. Rowe,
-
[16]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G
URLhttps://arxiv.org/abs/2301.01751. Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. DocETL: Agentic query rewriting and evaluation for complex document processing,
-
[17]
Jocelyn Shen, Nicolai Marquardt, Hugo Romat, Ken Hinckley, Nathalie Riche, and Fanny Chevalier
URLhttps://arxiv.org/abs/2410.12189. Jocelyn Shen, Nicolai Marquardt, Hugo Romat, Ken Hinckley, Nathalie Riche, and Fanny Chevalier. Texterial: A text-as-material interaction paradigm for LLM-mediated writing. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. ACM,
-
[18]
Sangho Suh, Bryan Min, Srishti Palani, and Haijun Xia
doi: 10.1177/1745691616658637. Sangho Suh, Bryan Min, Srishti Palani, and Haijun Xia. Sensecape: Enabling multilevel exploration and sensemaking with large language models. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST),
-
[19]
Luminate: Structured generation and exploration of design space with large language models for human-AI co-creation
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. Luminate: Structured generation and exploration of design space with large language models for human-AI co-creation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. ACM,
2024
-
[20]
Write a recipe for chocolate cake
URLhttps://arxiv.org/abs/2305.04388. Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback,
-
[21]
Solving math word problems with process- and outcome-based feedback
URL https://arxiv.org/abs/2211.14275. Amelia Wattenberger. Why chatbots are not the future of interfaces,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URLhttps://arxiv.org/abs/2201.11903. Sterling Williams-Ceci, Maurice Jakesch, Advait Bhat, Kowe Kadoma, Lior Zalmanson, and Mor Naaman. Biased ai writing assistants shift users’ attitudes on societal issues. Science Advances, 12(11):eadw5578,
work page internal anchor Pith review arXiv
-
[23]
Biased AI writing assistants shift users’ attitudes on societal issues
doi: 10.1126/sciadv.adw5578. URL https: //www.science.org/doi/abs/10.1126/sciadv.adw5578. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models,
-
[24]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
URLhttps://arxiv.org/abs/2305.10601. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P . Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS),
work page internal anchor Pith review arXiv
-
[25]
misleaded
14 Preprint. Under review. A Study Details All studies were conducted under IRB-approved protocol. Participants were compensated $20 USD and provided informed consent for their interviews, written artifacts, and behav- ioral data to be recorded and presented in this paper. Each domain section covers study procedure, per-participant quantitative results, a...
2025
-
[26]
Stalin was a good leader
⋄Question :What angle makes the strongest argument for Stalin as a good leader? →strongest combined: Combine industrialization and wartime leadership into one con- centrated argument for maximum persuasive force. ⋄Transformation : The path identified no problem, so the argument can be direct and unhedged. Combine industrialization and wartime into one arg...
1941
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.