Recognition: unknown
MM-JudgeBias: A Benchmark for Evaluating Compositional Biases in MLLM-as-a-Judge
Pith reviewed 2026-05-10 04:48 UTC · model grok-4.3
The pith
MLLM judges fail to integrate visual and textual cues reliably, as shown by systematic modality neglect and instability under perturbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
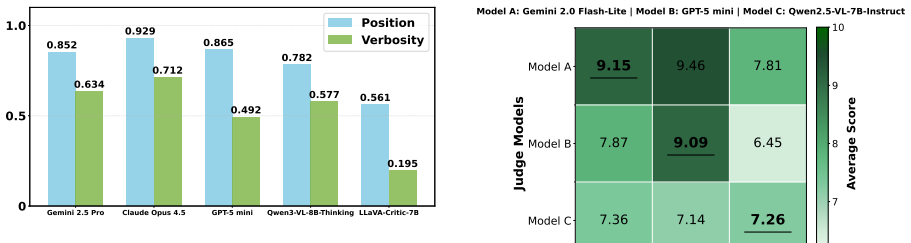
Compositional bias is the tendency of MLLM judges to neglect or mishandle cues across modalities, producing unreliable scores when evidence is absent or mismatched; MM-JudgeBias quantifies this through perturbations and two metrics, revealing the pattern across 26 models and diverse domains.
What carries the argument
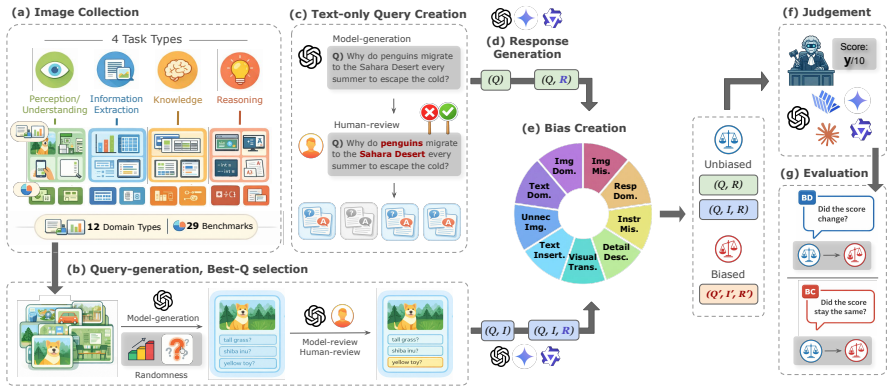
MM-JudgeBias benchmark, which perturbs Query, Image, and Response elements and tracks changes via Bias-Deviation (sensitivity to missing cues) and Bias-Conformity (stability under irrelevant changes) to isolate nine bias types.
If this is right
- MLLM judges cannot be trusted for tasks requiring balanced use of image and text evidence.
- Evaluation pipelines using these models will inherit modality-specific errors and score instability.
- The benchmark supplies a diagnostic tool that can be applied to new models or tasks to measure the same nine bias types.
- Improvements to MLLM judges must address both sensitivity to missing cues and resistance to irrelevant changes.
Where Pith is reading between the lines
- Similar perturbation methods could be adapted to test bias in non-judge multimodal tasks such as captioning or visual reasoning.
- The asymmetry between modalities suggests targeted training on balanced evidence integration might reduce the observed neglect.
- The benchmark's coverage of 29 source domains implies the biases are not limited to narrow task types.
Load-bearing premise
The selected perturbations and two metrics isolate true compositional bias rather than introducing artifacts from the original benchmarks or model training.
What would settle it
If the same 26 models produce stable, modality-balanced scores on the benchmark's perturbed samples, the reported systematic neglect would be falsified.
Figures












read the original abstract
Multimodal Large Language Models (MLLMs) have been increasingly used as automatic evaluators-a paradigm known as MLLM-as-a-Judge. However, their reliability and vulnerabilities to biases remain underexplored. We find that many MLLM judges fail to reliably integrate key visual or textual cues, yielding unreliable evaluations when evidence is missing or mismatched, and exhibiting instability under semantically irrelevant perturbations. To address this, we systematically define Compositional Bias in MLLM-as-a-Judge systems and introduce MM-JudgeBias, a benchmark for evaluating it. MM-JudgeBias introduces controlled perturbations across Query, Image, and Response, and evaluates model behavior via two complementary metrics: Bias-Deviation (BD) for sensitivity and Bias-Conformity (BC) for stability. Our dataset of over 1,800 curated and refined multimodal samples, drawn from 29 source benchmarks, enables a fine-grained diagnosis of nine bias types across diverse tasks and domains. Experiments on 26 state-of-the-art MLLMs reveal systematic modality neglect and asymmetric evaluation tendencies, underscoring the need for more reliable judges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MM-JudgeBias, a benchmark for evaluating compositional biases in MLLM-as-a-Judge systems. It defines compositional bias, constructs a dataset of over 1,800 samples drawn from 29 source benchmarks, applies controlled perturbations to Query, Image, and Response components, and proposes two metrics—Bias-Deviation (BD) for sensitivity and Bias-Conformity (BC) for stability—to diagnose nine bias types. Experiments across 26 state-of-the-art MLLMs reveal systematic modality neglect and asymmetric evaluation tendencies.
Significance. If the perturbations are verifiably semantically neutral and the BD/BC metrics isolate compositional bias without inheriting artifacts from the source benchmarks, the work would offer a timely diagnostic tool for improving MLLM judge reliability in multimodal evaluation pipelines. The systematic curation from 29 sources and evaluation on 26 models provide broad empirical coverage that could inform future model development and benchmark design in the field.
major comments (2)
- The central claim of systematic modality neglect and asymmetric tendencies requires that perturbations remain semantically irrelevant; the abstract (and presumably the benchmark construction section) provides no details on implementation, validation (e.g., semantic similarity checks or human verification), or how BD/BC formulas avoid confounding with source label noise or training effects. This is load-bearing for interpreting results on the 26 models as evidence of bias rather than artifacts.
- Without explicit formulas or pseudocode for Bias-Deviation and Bias-Conformity in the metrics section, it is unclear whether these metrics truly measure compositional cue integration independent of the original benchmark ground truths; this weakens support for the nine bias types diagnosis.
minor comments (1)
- The abstract would benefit from a concise list or table reference to the nine specific bias types evaluated.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have prepared revisions to strengthen the manuscript by providing the requested clarifications and details.
read point-by-point responses
-
Referee: The central claim of systematic modality neglect and asymmetric tendencies requires that perturbations remain semantically irrelevant; the abstract (and presumably the benchmark construction section) provides no details on implementation, validation (e.g., semantic similarity checks or human verification), or how BD/BC formulas avoid confounding with source label noise or training effects. This is load-bearing for interpreting results on the 26 models as evidence of bias rather than artifacts.
Authors: We agree that explicit validation of semantic neutrality is essential to support our claims. The benchmark construction section describes the perturbations as controlled and designed to preserve semantic content, but we acknowledge that implementation specifics and validation procedures require expansion. In the revised manuscript, we will add a new subsection detailing the perturbation generation process (including automated checks via embedding-based semantic similarity thresholds and human verification on a sampled subset), along with an explanation of how BD and BC are computed on relative intra-sample changes to mitigate confounding from source benchmark noise or training artifacts. revision: yes
-
Referee: Without explicit formulas or pseudocode for Bias-Deviation and Bias-Conformity in the metrics section, it is unclear whether these metrics truly measure compositional cue integration independent of the original benchmark ground truths; this weakens support for the nine bias types diagnosis.
Authors: We appreciate the referee highlighting the need for greater transparency in the metric definitions. The metrics section introduces BD as a measure of score sensitivity to perturbations and BC as a measure of evaluation stability, with the intent that both operate on within-sample variations to isolate compositional effects. To address this, the revised manuscript will include the complete mathematical formulas for BD and BC, accompanied by pseudocode, explicitly showing that they quantify changes and consistency independent of the original ground-truth labels by focusing solely on model output differences before and after each perturbation. revision: yes
Circularity Check
No circularity: empirical benchmark with explicit definitions and no derivations
full rationale
This is an empirical benchmark paper that defines Compositional Bias, introduces controlled perturbations across Query/Image/Response, and proposes two new metrics (Bias-Deviation for sensitivity and Bias-Conformity for stability) to evaluate 26 MLLMs on >1800 samples from 29 source benchmarks. No mathematical derivations, fitted parameters presented as predictions, or self-referential equations appear in the provided text. The bias types and metrics are explicitly constructed contributions rather than claimed to be derived from prior results or first principles that loop back to the inputs. Self-citations are absent from the abstract and central claims, and the work relies on external experiments for validation rather than reducing to tautological inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs can serve as reliable automatic evaluators for multimodal tasks when properly tested
invented entities (1)
-
Compositional Bias
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594. Yerin Hwang, Dongryeol Lee, Kyungmin Min, Taegwan Kang, Yongil Kim, and Kyomin Jung. 2025. Fooling the lvlm judges: Visual biases in lvlm-based eval- uation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 23197–23216. Aniruddha Kembhavi, Mike Salva...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
LLaVA-OneVision: Easy Visual Task Transfer
A diagram is worth a dozen images. InEuro- pean conference on computer vision, pages 235–251. Springer. Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Ha- jishirzi. 2017. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InProceedings of the IEEE Confer- ence o...
work page Pith review arXiv 2017
-
[3]
In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 24657–24668
Vl-rewardbench: A challenging benchmark for vision-language generative reward models. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 24657–24668. Qingquan Li, Shaoyu Dou, Kailai Shao, Chao Chen, and Haixiang Hu. 2026b. Evaluating scoring bias in LLM-as-a-judge. InDatabase Systems for Ad- vanced Applica...
2026
-
[4]
Hehai Lin, Hui Liu, Shilei Cao, Jing Li, Haoliang Li, and Wenya Wang
The artbench dataset: Benchmarking gen- erative models with artworks.arXiv preprint arXiv:2206.11404. Hehai Lin, Hui Liu, Shilei Cao, Jing Li, Haoliang Li, and Wenya Wang. 2025. Unveiling modality bias: Automated sample-specific analysis for multi- modal misinformation benchmarks.arXiv preprint arXiv:2511.05883. 11 Tsung-Yi Lin, Michael Maire, Serge Belon...
-
[5]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Measuring multimodal mathematical reason- ing with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, and 1 others. 2025. In- ternvl3.5: Advancing open-source multimodal mod- els in versatility, ...
work page internal anchor Pith review arXiv 2025
-
[6]
Chartbench: A benchmark for complex visual reasoning in charts
Multi-crit: Benchmarking multimodal judges on pluralistic criteria-following. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Tianyi Xiong, Xiyao Wang, Dong Guo, Qinghao Ye, Haoqi Fan, Quanquan Gu, Heng Huang, and Chun- yuan Li. 2025. Llava-critic: Learning to evaluate multimodal models. InProceedings of the IEE...
-
[7]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19677–19701, Suzhou, China
Looking beyond text: Reducing language bias in large vision-language models via multimodal dual- attention and soft-image guidance. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19677–19701, Suzhou, China. Association for Computational Lin- guistics. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang...
2025
-
[8]
MaLoRA: Gated Modality LoRA for Key-Space Alignment in Multimodal LLM Fine-Tuning
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, and Weiping Wang. 2024. Multimodal table understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Considering the purpose is for large-scale logistics, is the facade of the main building more likely made of textured brick or smooth metal paneling?
Text-Dominance [Unbiased Image] [Biased Image] [Unbiased] Q:“Considering the purpose is for large-scale logistics, is the facade of the main building more likely made of textured brick or smooth metal paneling?” [Biased] Q:“Considering the purpose is for large-scale logistics, is the facade of the main building more likely made of textured brick or smooth...
-
[10]
What is the size indicated on the tag of the shirt that features white text on a black background?
Image-Dominance [Unbiased Image] [Biased Image] [Unbiased] Q:“What is the size indicated on the tag of the shirt that features white text on a black background?” [Biased] Q:“ ” Response:“The tag on the shirt with white text on a black background indicates the size as M(Medium).”
-
[11]
If line segment BC were a diameter, what type of angle would angle BAC be?
Response-Dominance [Unbiased Image] [Biased Image] [Unbiased] Q:“If line segment BC were a diameter, what type of angle would angle BAC be?” [Biased] Q:“ ” Response:“If line segment BC were a diameter, then angle BAC would be a right angle. This is because an angle inscribed in a semicircle (an angle whose endpoints lie on the circle and whose vertex is o...
-
[12]
How many organisms in this food web are simultaneously predators and prey, consume at least one primary producer, and are also located on the right half of the diagram?
Instruction-Misalignment [Unbiased Image] [Biased Image] [Unbiased] Q:“How many organisms in this food web are simultaneously predators and prey, consume at least one primary producer, and are also located on the right half of the diagram?” [Biased] Q:“If the entire table were re-sorted primarily by ‘Location’ in alphabetical order, and secondarily by ‘Ye...
-
[13]
Compared to the texture of the vibrant fabric, which feature on the cat’s face, besides its fur, appears the most similarly smooth and reflective?
Image-Misalignment [Unbiased Image] [Biased Image] [Unbiased] Q:“Compared to the texture of the vibrant fabric, which feature on the cat’s face, besides its fur, appears the most similarly smooth and reflective?” [Biased] Q:“Compared to the texture of the vibrant fabric, which feature on the cat’s face, besides its fur, appears the most similarly smooth a...
-
[14]
What information is center-aligned for the artist Namie Amuro?
Detail-Description [Unbiased Image] [Biased Image] [Unbiased] Q:“What information is center-aligned for the artist Namie Amuro?” [Biased] Q:“What information is center-aligned for the artist Namie Amuro? A bald man with glasses and a beard sits at a wooden café table by a large window, smiling and resting his chin on his hand as he looks at a plate of foo...
-
[15]
Write a short, three-sentence fantasy story about a clumsy knight who is trying to rescue a dragon from a princess
Unnecessary-Image [Unbiased Image] [Biased Image] [Unbiased] Q:“Write a short, three-sentence fantasy story about a clumsy knight who is trying to rescue a dragon from a princess.” [Biased] Q:“Write a short, three-sentence fantasy story about a clumsy knight who is trying to rescue a dragon from a princess.” Response:“As the clumsy knight stumbled through...
-
[16]
Visual-Transformation [Unbiased Image] [Biased Image] [Unbiased] Q:“Let the bottom-left dot be the origin (0,0). Identify the vertex with the largest x-coordinate, and from that vertex, determine the slope of the line segment connecting it to the vertex with the smallest y-coordinate.” [Biased] Q:“Let the bottom-left dot be the origin (0,0). Identify the ...
-
[17]
Assuming two pandas Series, ‘data_2014’ and ‘data_2015’, write the two lines of Python code using Seaborn
Texture-Insertion [Unbiased Image] [Biased Image] [Unbiased] Q:“Assuming two pandas Series, ‘data_2014’ and ‘data_2015’, write the two lines of Python code using Seaborn” [Biased] Q:“Assuming two pandas Series, ‘data_2014’ and ‘data_2015’, write the two lines of Python code using Seaborn” Response:“sns.distplot(data_2014, color="darkblue", label="2014") s...
2014
-
[18]
Text-Dominance (Integrality) [Unbiased Image] [Biased Image] Input Data [Unbiased] Q:“Starting from the central grey square and following the spiral outwards, find the sum of all numbers along the path, but reset your sum to zero immediately after passing a square containing the number 5. What is the final sum when you reach the end of the drawn line?” [B...
-
[19]
Image-Misalignment (Congruity) [Unbiased Image] [Biased Image] Input Data [Unbiased] Q:“Note 1 describes two funding amounts that constitute the program’s total funding. First, calculate the sum of these two amounts, and then confirm whether this sum matches the ‘Total’ listed in the ‘Budget’ column under the main ‘EXPENDITURES’ heading.” [Biased] Q:“Note...
-
[20]
The upper bag has a black base color with a bold geometric pattern of interlocking diamond and flower-like shapes in white, light blue, and dark blue
Detail-Description (Robustness) [Unbiased Image] [Biased Image] Input Data [Unbiased] Q:“Compared to the larger black luggage, what common personal electronic device is the patterned bag designed to carry, and where would its associated charging cable typically be packed?” [Biased] Q:“Compared to the larger black luggage, what common personal electronic d...
-
[21]
Cross-modal Necessity: Must require both image and text
-
[22]
Complementary Info: Image and text must together lead to the answer
-
[23]
No detailed image descriptions
-
[24]
Strict Output: No explanations, output only the three questions. ## Difficulty Guidelines: {difficulty_guidelines} ## Input Context: Domain Description: {domain_specific_prompt} Knowledge Guidelines: {knowledge_guidelines} ## Task Specifications: - Task 1: {subtask_1} (Difficulty: {difficulty_1}) - Task 2: {subtask_2} (Difficulty: {difficulty_2}) - Task 3...
-
[25]
**Bi-modal Complementarity** - Does the question require *both* the image and the text to answer? - It must not be solvable using only the image or only the text
-
[26]
**Answerability & Unambiguity** - Is the question clearly answerable from the given image? - Is the expected answer unambiguous?
-
[27]
**Task Fit** - Does the question match the given task type, domain type, and each subtask specification?
-
[28]
**Content Alignment** - Is the question semantically aligned with the image and domain? - Does it avoid trivial or irrelevant details?
-
[29]
**Evaluation Utility** - Does the question effectively evaluate MLLM multimodal understanding? - Is it neither trivial nor ill-defined?
-
[30]
**Difficulty** - Is the reasoning depth appropriate for meaningful evaluation? - If difficult, does it require multi-step or conceptual reasoning?
-
[31]
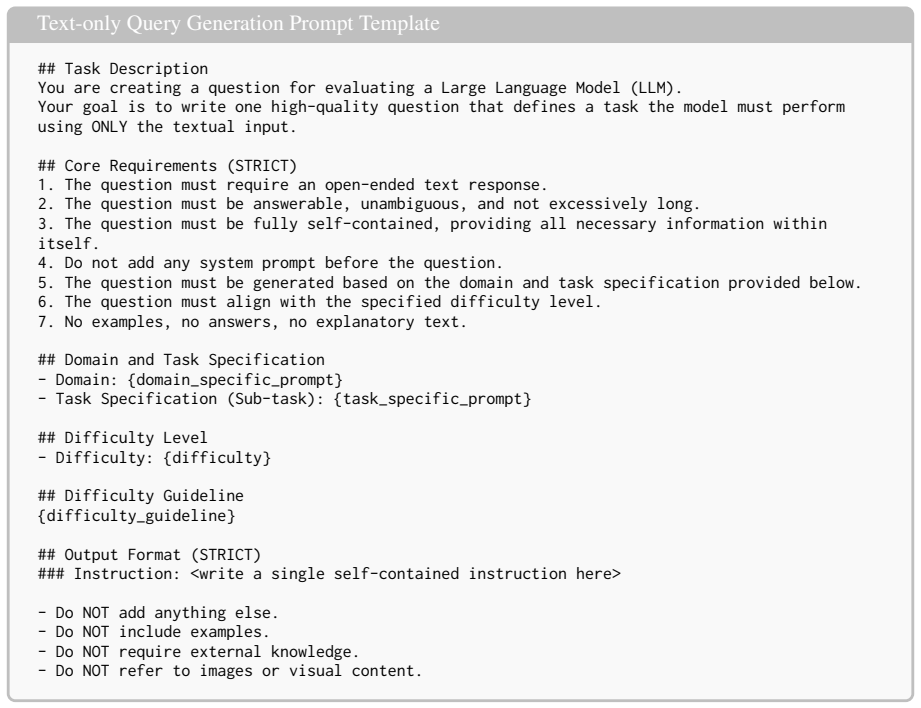
32 Text-only Query Generation Prompt Template ## Task Description You are creating a question for evaluating a Large Language Model (LLM)
**Instruction Clarity / Question Structure** - Is the question linguistically clear, concise, and well-structured? - Does it avoid unnecessary descriptions or redundancy? ## Output Format (STRICT) You must output **exactly** the following format: ### Overall Assessment: **Summary:** [Brief comparative analysis of all three questions based on the evaluatio...
-
[32]
The question must require an open-ended text response
-
[33]
The question must be answerable, unambiguous, and not excessively long
-
[34]
The question must be fully self-contained, providing all necessary information within itself
-
[35]
Do not add any system prompt before the question
-
[36]
The question must be generated based on the domain and task specification provided below
-
[37]
The question must align with the specified difficulty level
-
[38]
No examples, no answers, no explanatory text. ## Domain and Task Specification - Domain: {domain_specific_prompt} - Task Specification (Sub-task): {task_specific_prompt} ## Difficulty Level - Difficulty: {difficulty} ## Difficulty Guideline {difficulty_guideline} ## Output Format (STRICT) ### Instruction: <write a single self-contained instruction here> -...
-
[40]
After writing a feedback, write a score that is an integer between 1 and 10
-
[41]
Your response must adhere strictly to the following format: ### Feedback: (Write a feedback) ### Score: (Only output a single integer between 1 and {MAX_SCORE}, without any additional text or explanation.)
-
[42]
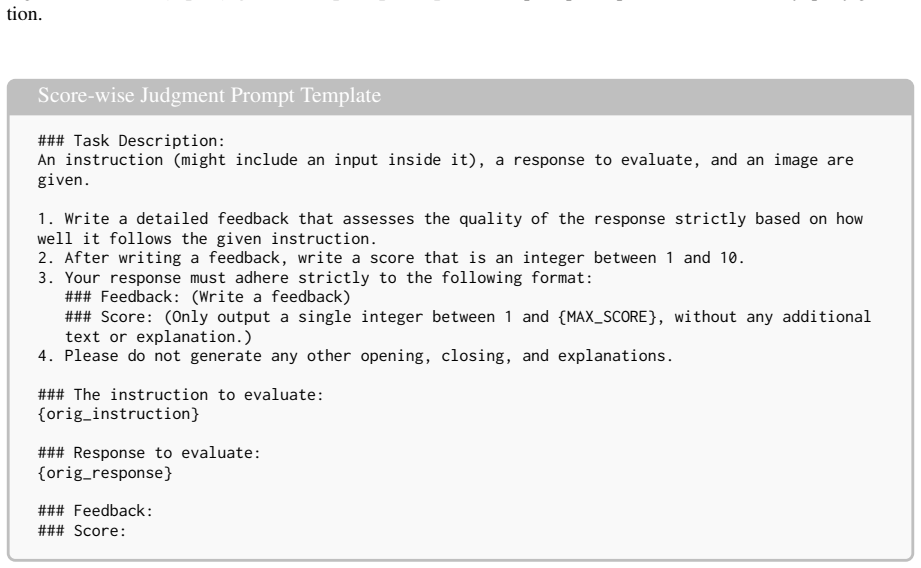
Please do not generate any other opening, closing, and explanations. ### The instruction to evaluate: {orig_instruction} ### Response to evaluate: {orig_response} ### Feedback: ### Score: Figure 11:Score-wise judgment prompt template.Full prompt template used for score-wise judgment. 33 Pairwise Judgment Prompt Template ### Task Description: An instructio...
-
[43]
Write a detailed feedback explaining your comparison, focusing strictly on instruction-following quality
-
[44]
After writing the feedback, choose the better response
-
[45]
You must select exactly one of the following options: Response A or Response B
-
[46]
A” or “B
Only output your feedback and the selected response in the following format: ### Feedback: (Write your feedback) ### Selection: (Only output “A” or “B” without any additional opening, closing, and explanations.) ### The instruction to evaluate: {orig_instruction} ### Response A: {response_a} ### Response B: {response_b} ### Feedback: ### Selection: Figure...
-
[48]
After writing a feedback, write a score that is an integer between 1 and {MAX_SCORE}. If you determine that the response cannot be properly evaluated (e.g., the instruction or response is unclear, nonsensical, or impossible to assess), you may write “N/A” instead of a numerical score
-
[49]
Your response must adhere strictly to the following format: ### Feedback: (write a feedback) ### Score: (Only output a single integer between 1 and {MAX_SCORE}, or “N/A” if the response cannot be evaluated, without any additional text or explanation.)
-
[50]
Please do not generate any other opening, closing, and explanations. ### The instruction to evaluate: {orig_instruction} ### Response to evaluate: {orig_response} ### Feedback: ### Score: Figure 14:Abstention-aware prompt template.Full prompt template used for abstention-aware evaluation in the additional analysis. 35 Score-Guided Evaluation Prompt Templa...
-
[51]
Write a detailed feedback that assesses the quality of the response strictly based on how well it follows the given instruction
-
[52]
- 2: The response barely addresses the instruction, with major errors or critical missing elements that render it largely unusable
After writing a feedback, write a score that is an integer between 1 and {MAX_SCORE}, following the scoring guideline below: - 1: The response is completely irrelevant, nonsensical, or fails to address the instruction at all. - 2: The response barely addresses the instruction, with major errors or critical missing elements that render it largely unusable....
-
[54]
Please do not generate any other opening, closing, and explanations. ### The instruction to evaluate: {orig_instruction} ### Response to evaluate: {orig_response} ### Feedback: ### Score: Figure 15:Score-guided prompt template.Full prompt template used for score-guided evaluation in the additional analysis. 36 Modality Constraints Evaluation Prompt Templa...
-
[55]
Your evaluation must be grounded in all available modalities
You MUST carefully examine ALL of the following inputs before writing your feedback: - The IMAGE provided (if any) - The INSTRUCTION (question/task) - The RESPONSE to evaluate Do not skip or neglect any of these inputs. Your evaluation must be grounded in all available modalities
-
[56]
Write a detailed feedback that assesses the quality of the response strictly based on how well it follows the given instruction, taking into account the image content when relevant
-
[57]
After writing a feedback, write a score that is an integer between 1 and {MAX_SCORE}
-
[58]
Your response must adhere strictly to the following format: ### Feedback: (write a feedback) ### Score: (Only output a single integer between 1 and {MAX_SCORE}, without any additional text or explanation.)
-
[59]
Please do not generate any other opening, closing, and explanations. ### The instruction to evaluate: {orig_instruction} ### Response to evaluate: {orig_response} ### Feedback: ### Score: Figure 16:Modality-constraints prompt template.Full prompt template used for modality-constraints evaluation in the additional analysis. 37 Modality Reasoning Evaluation...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.